Linux内核模块
Linux 内核模块
一. 内核模块概述
1. 内核的概念
内核,是一个操作系统的核心。是基于硬件的第一层软件扩展,提供操作系统的最基本的功能, 是操作系统工作的基础,决定着整个操作系统的性能和稳定性。
内核按照体系结构可分为 微内核(Micro Kernel)、宏内核(Monolithic Kernel) 和 混合内核(Hybrid Kernel) 等类型。
-
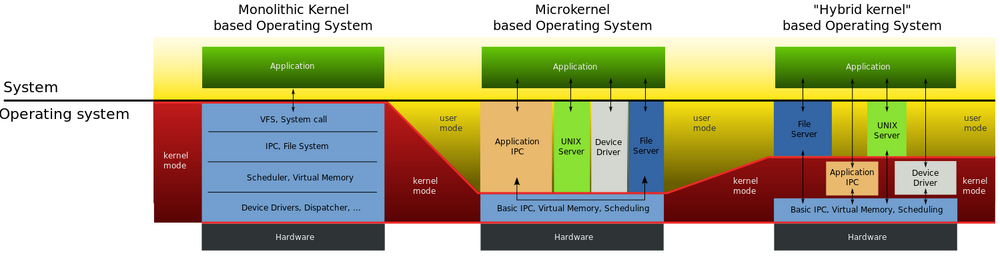
微内核架构:内核仅实现核心功能,如进程管理、内存管理、进程间通信和 I/O 设备管理等。而文件系统、设备驱动等上层服务则以独立的模块形式运行在内核之外。这种设计使得修改或扩展这些模块不会影响内核核心,具有良好的动态扩展性。典型代表包括 Windows 操作系统和华为的鸿蒙操作系统。
-
宏内核架构:将上述包括微内核以及微内核之外的应用层 IPC、文件系统功能和设备驱动模块等全部编译成一个整体。该架构执行效率高,但扩展性差:修改或增加任何功能(如添加设备驱动)都需要重新编译整个内核。
Linux 操作系统采用宏内核架构。为解决宏内核扩展性不足的问题,Linux 引入了内核模块机制。两种体系结构的对比如下图所示:
2. 内核模块的引入
Linux 是一个跨平台操作系统,支持大量硬件设备,在内核源码中设备驱动相关代码占比超过 50%。由于采用宏内核,若启用所有功能,内核将变得异常庞大。
内核模块(Loadable Kernel Module,LKM)是一段实现特定功能的内核代码,可在内核运行时动态加载到内核中,从而按需扩展内核功能。这一机制为设备驱动开发提供了极大便利:开发者只需以模块形式编写驱动代码,单独编译,而无需重新编译整个内核。此外,模块支持动态加载和卸载,便于调试和更新,且无需重启系统。
在嵌入式开发中,内核模块还可以存放在网络文件系统(如 NFS)中,按需加载到目标板,从而节省本地存储空间。在某些应用场景下,可根据当前环境动态加载或卸载模块,优化系统资源利用。
3. 内核模块的定义
内核模块是一段实现特定功能的内核代码,具有独立功能的程序,可单独编译,但不可独立运行。模块在加载后成为内核的一部分,运行于内核空间,与运行在用户空间的普通进程有本质区别。
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不一样的。 模块由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序和其他内核上层功能。 因此内核模块具备如下特点:
-
模块本身不被编译入内核映像,这控制了内核的大小。
-
模块一旦被加载,它就和内核中的其它部分完全一样。
有了内核模块的概念,下面我们一起深入了解内核模块的工作机制吧。
4. 内核模块的分类
根据模块在内核中实现的功能,可将内核模块分为以下几种主要类型:
-
设备驱动模块 这是最常见的一类模块,用于驱动硬件设备。可进一步细分为:
-
字符设备驱动:以字节流方式访问的设备,如串口、键盘、触摸屏等。
-
块设备驱动:以数据块方式访问的设备,如硬盘、U 盘、SD 卡等。
-
网络设备驱动:负责网络数据包的收发,如以太网卡、无线网卡驱动。
-
-
文件系统模块 实现特定文件系统格式的支持,如 ext4、FAT、NTFS、NFS 等。这些模块负责将存储设备上的原始数据组织成文件系统结构。
-
网络协议模块 实现特定的网络协议栈,如 IPv4、IPv6、ARP、TCP 拥塞控制算法、Netfilter 防火墙框架等。
-
内核其他功能模块 包括但不限于:
-
系统调用模块:添加新的系统调用(较少见)。
-
安全模块:如 SELinux、AppArmor 等 LSM(Linux Security Module)模块。
-
内核辅助模块:提供通用功能供其他模块使用,例如加密算法库、压缩库等。
-
5. 内核模块的工作机制
内核模块经过编译后生成以 .ko 为后缀的 ELF 文件。可以使用 file 命令查看其文件类型:

那么,这样一个文件是如何被内核加载并正常工作的呢?为了更好地理解内核模块的加载与卸载过程,我们首先需要了解 ELF 文件格式,弄清楚 .ko 文件的内部结构,然后再深入内核源码,探究模块加载、卸载以及符号导出的具体实现。
5.1 .ko 文件结构
.ko 文件在数据组织形式上采用的是 ELF(Executable and Linking Format,可执行与可链接格式)格式,是一种可重定位目标文件。 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类。
ELF 文件格式的可能布局如下图:
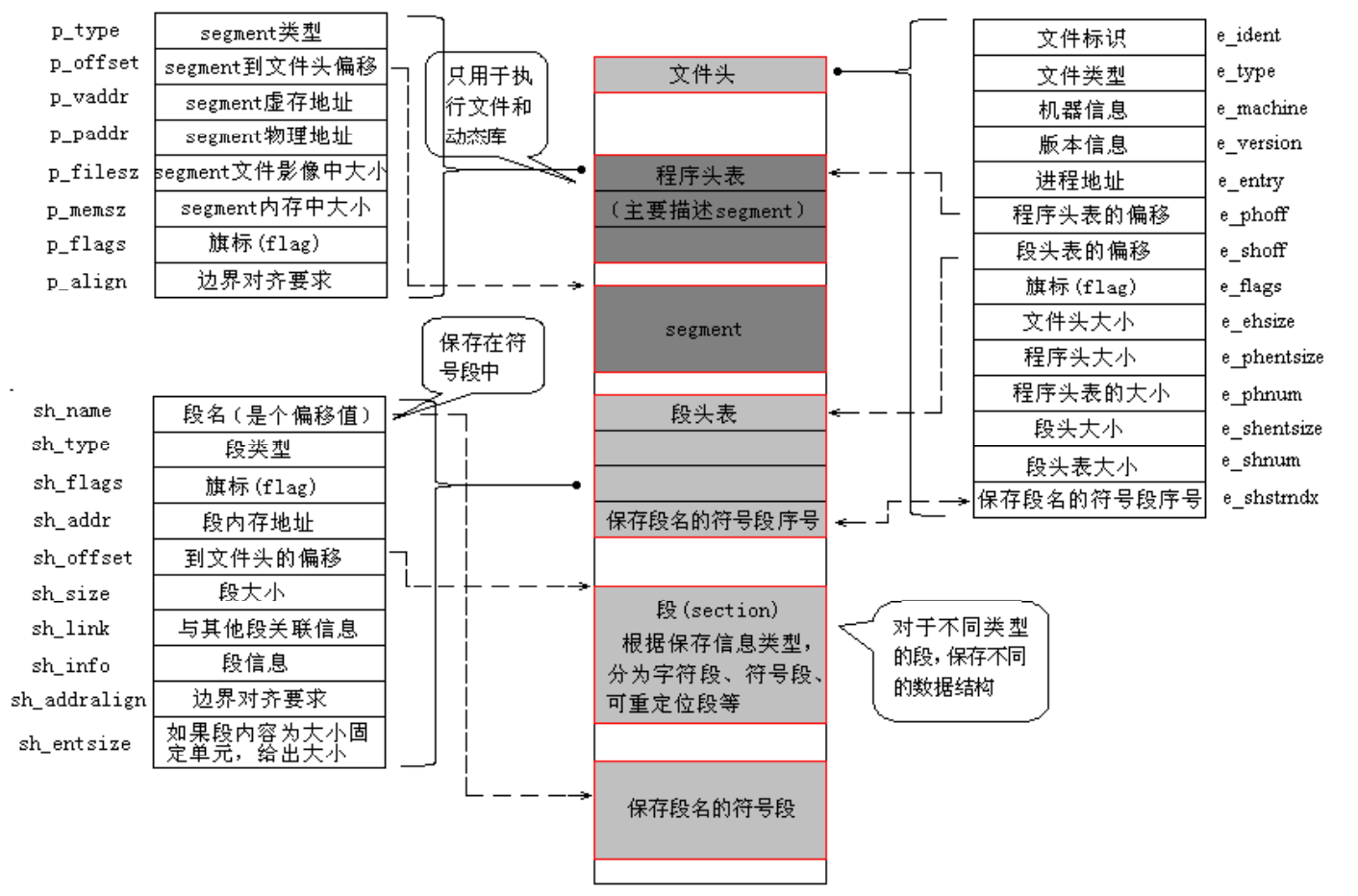
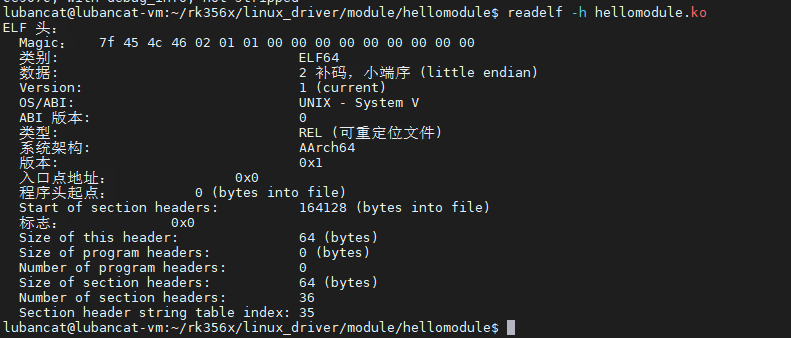
文件开头是一个 ELF 头部(ELF Header),用于描述整个文件的组织信息。这些信息与处理器无关, 也独立于文件中的其余内容。我们可以使用 readelf 工具查看 ELF 文件的头部详细信息。指令如下:
readelf -h hellomodule.ko
ELF 头部之后是 程序头部表(Program Header Table),它是一个数组结构,每个元素描述一个“段(Segment)”或系统执行程序所需的其他信息。程序头部表仅对可执行文件和共享目标文件有意义。
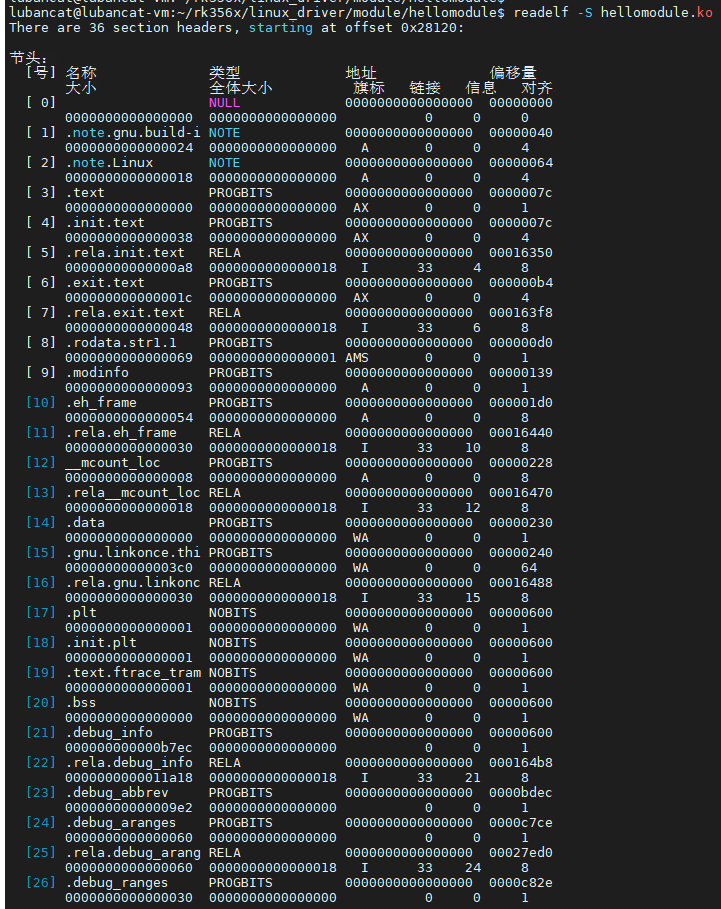
接着是 节区头部表(Section Header Table),ELF文件中有很多各种各样的段,它记录了文件中各个端(Section)的基本属性,是编译器、链接器和加载器定位和访问节区的关键。ELF 头部中的 e_shoff、e_shnum 和 e_shentsize 字段分别给出节区头部表在文件中的偏移、条目数以及每个条目的大小。使用 readelf -S 可以查看节区头部表的详细信息:
节区头部表中包含多个子表,常见的有:
-
重定位表(Relocation Table) 通常以
.rel.text等名称存在,类型(sh_type)为SHT_REL。重定位表记录了代码段或数据段中需要重定位的位置,链接器在处理目标文件时会根据这些信息修正绝对地址引用。可以使用readelf -r查看重定位表:
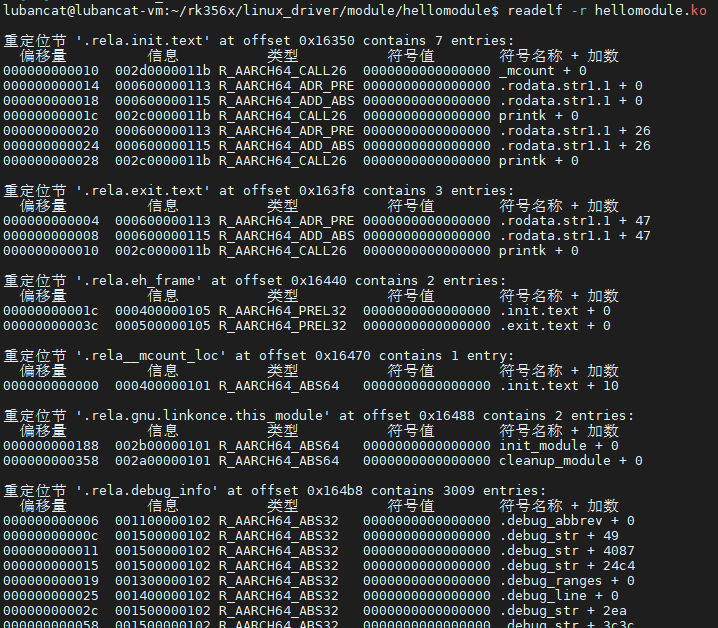
-
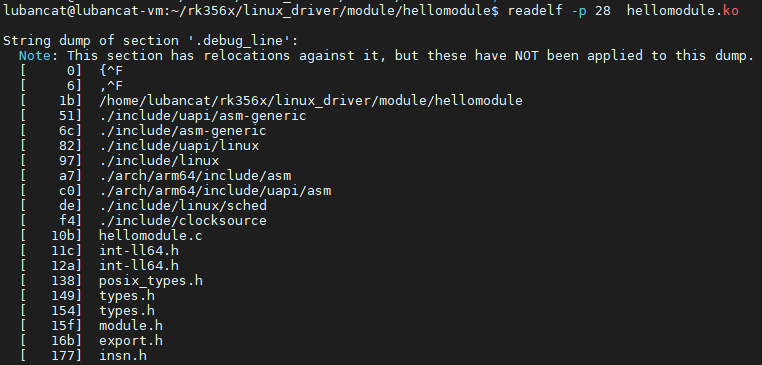
字符串表(String Table) ELF 文件中使用了大量字符串(如节名、变量名等)。为了便于管理,这些字符串被集中存放在字符串表中,通过偏移量引用。常见的字符串表节有
.strtab(字符串表)和.shstrtab(节区头部字符串表)。使用readelf -p .shstrtab可以查看节区字符串表内容:
ELF 文件格式的知识较为底层,理解其基本结构有助于后续学习内核模块的加载、卸载以及符号导出机制。在后续内容中,我们将基于这些概念,深入分析内核模块的运行原理。
5.2 内核模块加载过程
在前面我们了解了 .ko 内核模块文件的一些格式内容之后, 我们可以知道内核模块其实也是一段经过特殊加工的代码, 那么既然是加工过的代码,内核就可以利用到加工时留在内核模块里的信息, 对内核模块进行利用,实现对模块的动态加载与链接。
接下来我们详细分析内核模块的加载过程:
-
用户态准备与系统调用
用户态工具(如
insmod或modprobe)通过文件系统将.ko内核模块读取到用户空间的一块内存中, 然后执行系统调用sys_init_module(),由内核接管后续的加载工作。 -
临时空间分配与拷贝
内核进入
sys_init_module()后,首先在 vmalloc 区域 分配一块与模块文件大小相等的临时缓冲区,通过copy_module_from_user()将模块文件从用户空间拷贝至内核空间,用于暂存.ko模块文件。 -
ELF 解析与段(Section)分类
内核解析 ELF 格式的模块文件,读取各个段(section)的信息。根据段的属性(如
SHF_ALLOC等),将段划分为两大类:-
Init 段:包含初始化代码和数据(如
__init修饰的函数),这些内容在模块初始化完成后可以释放。 -
Core 段:包含模块运行期间常驻的代码和数据,如驱动主体、导出的符号表等。
这一分类由
layout_sections()函数完成,为后续的内存布局做准备。 -
-
目标内存分配与最终拷贝
内核在专门的 Module 内存区 为 Init 和 Core 段分别分配最终的运行内存。并把对应的 section copy 到 modules 区最终的运行地址。
-
符号解析与重定位
是模块融入内核的关键步骤:
-
外部符号解析: 内核扫描模块需要引用的外部符号(如内核导出的
printk、kmalloc等),在内核符号表(ksymtab)中查找这些符号的运行时地址。 -
地址重定位: 根据重定位表(
.rel.text等)中的信息,修改代码段和数据段中的指令或数据,将占位符地址替换为真实的符号地址。经过重定位,模块内部的所有地址引用都变为有效。
-
-
权限设置与初始化
在调用模块初始化函数之前,内核会根据各段的内存属性设置相应的访问权限:
-
代码段通常设置为只读(RO)且不可执行(NX 相关权限已由硬件管理)。
-
数据段设置为可读写(RW)但不可执行。
随后,内核调用模块的入口函数(由
module_init宏指定的函数),执行模块的初始化逻辑。 -
-
清理与常驻
初始化函数执行完毕后,内核会立即释放 Init 段占用的内存空间,因为这些代码和数据不再需要。此时,模块仅保留 Core 段在后台运行,其状态变为
MODULE_STATE_LIVE,表示模块已成功加载并处于活动状态。
整个加载流程的核心实现在内核源码 kernel/module.c 中,系统调用入口如下:
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
-
copy_module_from_user():通过 vmalloc 分配临时内存,将用户空间的模块文件复制到内核空间,并将info.hdr指向该内存起始位置(即 ELF 文件头)。 -
load_module():执行模块加载的核心处理,包括段分类、内存分配、重定位和初始化等。
load_module() 函数的部分简化代码如下:
/* 分配并加载模块 */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
err = setup_load_info(info, flags);
...
mod = layout_and_allocate(info, flags);
...
}
-
setup_load_info():初始化load_info结构,并重写各段的sh_addr字段,将其修正为当前镜像所在内存地址。同时,通过 ELF 头中的e_shstrndx找到节区头部字符串表,确定各段名称在内存中的位置。 -
layout_and_allocate():-
layout_sections():将模块的各个段归类为 init 段和 core 段,为最终的内存布局做准备。 -
move_module():将段内容从临时缓冲区复制到最终运行地址,完成模块的第二次搬移。
-
至此,模块代码和数据已就位。但要使模块正常工作,还需要进行符号解析和导出,这部分内容将在后续小节详细讲解。
5.3 内核模块卸载过程
模块卸载过程相对简单。用户态工具 rmmod 通过系统调用 delete_module() 触发内核卸载操作。其核心流程为:
根据用户传入的模块名称找到目标模块,检查是否有其他模块依赖该模块,确认无依赖后调用模块的退出函数(由 module_exit 宏指定),最后释放模块占用的内存。
系统调用 sys_delete_module() 的实现如下(代码经过简化):
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN - 1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN - 1] = '\0';
if (mutex_lock_interruptible(&module_mutex))
return -EINTR;
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
/* 检查是否有其他模块依赖本模块 */
if (!list_empty(&mod->source_list)) {
ret = -EWOULDBLOCK;
goto out;
}
/* 模块必须处于活动状态才能卸载 */
if (mod->state != MODULE_STATE_LIVE) {
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
/* 如果模块定义了 init 但没有定义 exit,则除非强制卸载,否则无法卸载 */
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
ret = -EBUSY;
goto out;
}
}
/* 停止模块,使其不再被使用 */
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* 调用模块的退出函数 */
if (mod->exit != NULL)
mod->exit();
/* 通知监听模块状态变化的链 */
blocking_notifier_call_chain(&module_notify_list,
MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
/* 等待所有异步操作完成 */
async_synchronize_full();
/* 记录最后卸载的模块名,用于诊断 */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
/* 释放模块占用的所有资源 */
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}
关键步骤说明:
-
权限检查(第8行):调用者需具备
CAP_SYS_MODULE能力,且内核未禁止模块操作(modules_disabled为假)。 -
获取模块名(第11行):从用户空间拷贝模块名称。
-
查找模块(第20行):在内核模块链表中根据名称查找目标模块。
-
依赖检查(第26行):若
mod->source_list非空,表示有其他模块依赖本模块,需先卸载依赖模块。 -
状态检查(第33行):模块必须处于
MODULE_STATE_LIVE(活动)状态才能卸载。 -
退出函数存在性检查(第39行):若模块定义了
init但未定义exit,则除非指定强制卸载(如rmmod -f),否则不允许卸载。 -
停止模块(第48行):通过
try_stop_module()确保模块不再被使用,并禁止新的引用。 -
执行退出函数(第56行):调用模块的
exit函数,执行清理操作。 -
通知链回调(第58行):通知注册了模块状态变化的监听者,模块正在退出。
-
资源释放(第66行):调用
free_module()释放模块占用的内存及其他资源。
卸载完成后,模块从内核中完全移除。
5.4 内核导出符号
在内核模块开发中,符号是指模块中定义的全局函数或变量。通过 EXPORT_SYMBOL 或 EXPORT_SYMBOL_GPL 宏,可以将这些符号导出,使得这些符号被记录在公共内核符号表中,从而让其他模块或内核本身可以访问它们。
符号的导出是实现模块层叠的关键技术——通过将复杂功能分层,分为多层模块实现,上层模块可以依赖下层模块导出的符号,从而构建复杂功能。例如,msdos 文件系统依赖于 fat 模块导出的符号;USB 输入设备驱动则层叠在 usbcore 和 input 模块之上。
5.4.1 导出符号的方法
在模块源码的全局作用域(不能在函数内部)使用以下宏导出符号:
EXPORT_SYMBOL(name); EXPORT_SYMBOL_GPL(name); /* 仅允许 GPL 许可的模块使用 */
编译时,这些宏会被展开并生成相应的 ELF 信息,最终存放在模块文件的特定节区中(如 __ksymtab 节区)。导出的符号在 ELF 符号表中包含以下关键属性:
-
st_name:符号名称在字符串表中的索引; -
st_value:符号的虚拟地址(初始为偏移量); -
st_size:符号大小; -
st_info:类型和绑定信息; -
st_shndx:所在节区的索引。
当 ELF 的符号表被加载到内核后,会执行 simplify_symbols 来遍历整个 ELF 文件符号表。 根据 st_shndx 找到符号所在的 section 和 st_value 中符号在 section 中的偏移得到真正的内存地址。 并最终将符号内存地址,符号名称指针存储到内核符号表中。
5.4.2 模块加载时的符号处理
当模块被加载时,内核通过 simplify_symbols() 函数遍历模块的 ELF 符号表,对导出的符号进行解析和重定位:
static int simplify_symbols(struct module *mod, const struct load_info *info)
-
功能:遍历符号表,根据
st_shndx定位符号所在节区,结合st_value计算出符号在内存中的实际地址,并将该地址写入符号表中。 -
参数:
-
mod: struct module 类型结构体指针,为目标模块。 -
info: const struct load_info结构体指针,包含模块的加载信息。
-
-
返回值:错误码(成功返回 0)。
导出的符号最终被整理成内核符号表,其表项结构为:
struct kernel_symbol {
unsigned long value; /* 符号在内存中的实际地址 */
const char *name; /* 符号名称字符串指针 */
};
-
value: 符号在内存中的地址
-
name: 符号名称
这些表项被存放在专门的节区(如 __ksymtab)中,而符号名称则存储在 __ksymtab_strings 节区。需要注意的是,kernel_symbol 构成的表是导出符号表,而非普通的 ELF 符号表。
5.4.3 其他模块对导出符号的查找
const struct kernel_symbol *find_symbol(const char *name, struct module **owner, const s32 **crc, bool gplok, bool warn);
-
查找范围:首先在内核自身的导出符号表中查找,然后遍历所有已加载模块的导出符号表。
-
查找逻辑:
each_symbol_section()配合find_symbol_in_section()遍历所有符号表,若找到则返回对应的kernel_symbol结构,并可通过owner返回所属模块。 -
参数说明:
gplok指示是否允许使用 GPL 符号,warn控制未找到时是否打印警告。
查找成功后,将符号的实际地址赋值给当前模块符号表中的 st_value,然后通过重定位表修正模块内对该符号的所有引用。至此,模块间的符号依赖得以满足。
find_symbol 本身也通过 EXPORT_SYMBOL_GPL 导出,供内核其他部分使用。
通过符号导出机制,Linux 内核在保持宏内核高效性的同时,实现了灵活的模块化扩展。关于内核模块加载与符号处理的完整实现,可参阅内核源码 kernel/module.c。
二. 内核模块代码框架
1. 代码框架分析
Linux 内核模块的代码框架通常由下面几个部分组成:
-
模块加载函数(必须): 当通过
insmod或modprobe命令加载内核模块时,模块的加载函数就会自动被内核执行,完成本模块相关的初始化工作。加载函数通常以__init属性修饰,在内核模块加载完成后,其所占内存可以被回收。 -
模块卸载函数(必须): 当执行
rmmod命令卸载模块时,模块卸载函数就会自动被内核自动执行,完成相关清理工作。卸载函数通常以__exit属性修饰,如果模块被编译进内核(而非动态加载),该函数将被忽略。 -
模块许可证声明(必须): 许可证声明描述内核模块的许可权限,常用声明为
GPL或GPL v2。如果不声明,内核在加载模块时会提示“kernel tainted”(内核被污染),影响部分内核功能的使用。 -
模块参数(可选): 允许在加载模块时向模块传递参数,通过
module_param()宏定义。参数可用于控制模块行为,实现灵活的配置。 -
模块导出符号(可选): 通过
EXPORT_SYMBOL()或EXPORT_SYMBOL_GPL()将模块内的全局函数或变量导出,供其他模块调用。这是实现模块间依赖和模块层叠的基础。 -
模块的其他相关信息(可选): 可以声明模块的作者、描述和版本号等信息。
编写内核模块必须包含两个基本头文件:
#include <linux/init.h> /* 包含模块初始化和清理相关的宏 */ #include <linux/module.h> /* 包含模块相关的宏和定义 */
2. 输出调试日志
内核程序运行在内核态,无法链接和使用处于用户空间的 C 标准库(如 glibc)。因此,我们熟知的 printf 函数在驱动代码中是不可用的。为此,Linux 内核提供了一套专用的日志打印机制。
2.1 日志宏定义
在现代 Linux 内核开发中,官方强烈推荐使用 pr_* 系列宏来输出调试信息。它们不仅书写更简洁,还能配合 pr_fmt 宏自动为日志添加模块名前缀,极大地提升了日志的可读性。使用前需包含头文件:
#include <linux/kernel.h>
/* 建议在 .c 文件最开头定义 pr_fmt,自动加上模块名前缀 */
#define pr_fmt(fmt) KBUILD_MODNAME ": " fmt
// 常用打印宏示例:
pr_info("Device initialized successfully.\n"); // 普通提示信息
pr_err("Failed to allocate memory!\n"); // 错误信息
pr_debug("Read count: %d\n", count); // 调试信息(开启 DEBUG 时生效)
2.2 日志级别
上述 pr_* 宏的底层实际上是对内核核心打印函数 printk 的封装(例如 pr_info 等同于 printk(KERN_INFO ...))。
printk 的用法与 printf 非常相似,但它最大的特点是引入了日志级别的概念。内核定义了 8 个级别的日志宏(数值越小,优先级越高):
| 宏定义 | 等级前缀 | 含义说明 |
|---|---|---|
KERN_EMERG |
"<0>" |
紧急情况:通常是系统崩溃前的信息 |
KERN_ALERT |
"<1>" |
警报情况:需要立即采取动作处理 |
KERN_CRIT |
"<2>" |
严重情况:如硬件故障 |
KERN_ERR |
"<3>" |
错误情况:驱动程序报错,但不影响整个系统 |
KERN_WARNING |
"<4>" |
警告情况:可能存在问题,但系统仍可运行 |
KERN_NOTICE |
"<5>" |
注意情况:正常但具有重要意义的信息 |
KERN_INFO |
"<6>" |
普通消息:信息性提示(最常用) |
KERN_DEBUG |
"<7>" |
调试信息:开发阶段使用的诊断信息 |
2.3 查看与控制内核日志
查看当前系统 printk 打印等级:cat /proc/sys/kernel/printk, 从左到右依次对应当前控制台日志级别、默认消息日志级别、 最小的控制台级别、默认控制台日志级别。
panpanki@LAPTOP-C1VFTALA:~$ cat /proc/sys/kernel/printk 4 4 1 7 panpanki@LAPTOP-C1VFTALA:~$
打印内核所有打印信息:dmesg,注意内核log缓冲区大小有限制,缓冲区数据可能被覆盖掉。
无论日志是否被打印到了控制台屏幕上,所有通过 printk 或 pr_* 输出的日志都会被记录在内核内存的一块环形缓冲区 (Ring Buffer) 中。我们可以使用 dmesg 命令将其完整打印出来。
注意: 由于内核的 Ring Buffer 大小是固定的(通常为几百 KB 到几 MB 不等),当日志产生过多时,最旧的日志数据会被新的数据循环覆盖掉。可以使用 dmesg -c 在查看后清空缓冲区,或者使用 dmesg -w 实时滚动查看新日志。
3. 模块加载/卸载函数
在 Linux 驱动开发中,每个内核模块都必须包含两个核心函数:模块加载函数 和 模块卸载函数。它们的作用类似于面向对象编程中的构造函数和析构函数,分别由内核在模块加载和卸载时自动调用,用于完成内核模块所需的初始化和清理工作。
在驱动模块中,模块加载函数,也称为驱动入口函数;模块卸载函数,也称为驱动出口函数。
3.1 驱动模块加载函数
当使用 insmod 或 modprobe 命令加载驱动模块时,内核会通过 module_init 宏注册的函数自动调用它。在此函数中,开发者需要完成驱动的初始化工作,例如:
-
硬件初始化:设置寄存器、使能时钟、复位设备等。
-
系统资源分配:申请内存、分配中断号、映射 I/O 端口等。
-
字符设备注册:分配设备号、初始化并注册
cdev结构体、创建设备类和设备节点。 -
内部数据结构初始化:初始化互斥锁、等待队列、定时器等。
3.2 驱动模块卸载函数
当使用 rmmod 命令卸载驱动模块时,内核会通过 module_exit 宏注册的函数自动调用它。在此函数中,开发者必须执行与加载函数相反的操作,以释放所有已占用的资源,例如:
-
释放硬件资源:关闭时钟、复位或关闭设备。
-
释放系统资源:释放申请的内存、注销中断、释放 I/O 端口。
-
注销字符设备:删除
cdev结构体、释放设备号、销毁设备类和设备节点。
没有提供这两个函数,内核将无法正确初始化或清理驱动,可能导致资源泄漏、设备无法使用,甚至引发系统崩溃。
3.3 注册加载/卸载函数
Linux 内核提供了两个宏,用于向内核注册模块的加载函数和卸载函数:
/* * module_init 宏用于向 Linux 内核注册模块的加载函数。 * 当使用 insmod 命令加载模块时,内核会调用注册的函数完成初始化工作。 * * module_exit 宏用于向 Linux 内核注册模块的卸载函数。 * 当使用 rmmod 命令卸载模块时,内核会调用注册的函数完成资源释放等清理工作。 */ module_init(xxx_init); // 注册模块加载函数 module_exit(xxx_exit); // 注册模块卸载函数
这两个宏定义在 <linux/module.h> 中。它们将函数的地址放入内核特殊的 ELF 段(.initcall 和 .exitcall),使得内核在模块插入(insmod)时自动调用加载函数,在模块移除(rmmod)时自动调用卸载函数。
驱动加载函数和卸载函数的原型如下:
/* 模块加载函数 */ static int __init chrdevbase_init(void); /* 模块卸载函数 */ static void __exit chrdevbase_exit(void)
-
加载函数:返回
0表示初始化成功;返回负的错误码(如-ENOMEM、-EIO)表示失败,模块加载会中止。 -
卸载函数:无返回值,应执行与加载相反的操作,释放所有已申请的资源。
重要说明:
-
__init和__exit修饰符的作用-
__init提示内核该函数仅在初始化阶段使用。如果驱动被静态编译进内核,内核在驱动加载完成后可以回收这些函数占用的内存。 -
__exit提示内核该函数仅用于模块卸载。若驱动被静态编译进内核,卸载函数永远不会被调用,编译器会将其优化掉,从而减小内核镜像体积。 -
对于可加载模块(
.ko),这两个修饰符没有实质的内存回收效果,但保留它们是一种良好的编程习惯。
-
-
驱动函数必须声明为
static-
内核是一个庞大的全局命名空间,使用
static可以避免函数名与其他驱动或内核核心函数冲突,保证符号的局部性。
-
-
必须提供这两个函数
-
没有提供这两个函数,内核将无法正确初始化或清理驱动,可能导致资源泄漏、设备无法使用,甚至引发系统崩溃。
-
4. 模块信息声明
在内核模块开发中,除了实现加载/卸载函数外,通常还会添加一些描述性信息,用于标识模块的许可证(LICENSE)、作者(AUTHOR)、功能描述(DESCRIPTION)和别名(ALIAS)。这些信息不参与模块的运行逻辑,但可以通过 modinfo 命令查看,便于模块的管理和维护。
4.1 常用信息宏
Linux 内核提供了以下几个宏,用于声明模块的元信息:
MODULE_LICENSE("GPL"); /* 必须:声明模块许可证 */
MODULE_AUTHOR("Your Name"); /* 可选:声明模块作者 */
MODULE_DESCRIPTION("A simple module"); /* 可选:描述模块功能 */
MODULE_ALIAS("alias_name"); /* 可选:为模块设置别名 */
这些宏定义在 <linux/module.h> 中,本质上是将信息写入模块的 ELF 特殊节区(如 .modinfo),供用户空间工具读取。
4.2 许可证声明(必须)
MODULE_LICENSE() 是每个内核模块必须包含的宏,用于声明模块遵循的开源许可证。内核在加载模块时会检查该声明,若未声明或声明了非 GPL 兼容的许可证,内核会标记为“污染”(tainted),并可能限制某些内核功能的使用(如导出符号仅对 GPL 模块可见)。
常用的许可证参数包括:
-
"GPL"、"GPL v2":GNU 通用公共许可证 -
"GPL and additional rights":GPL 附加权利 -
"Dual BSD/GPL"、"Dual MPL/GPL":双重许可证 -
"Proprietary":专有许可证(会导致内核污染)
由于 Linux 内核本身采用 GPL V2 协议,建议内核模块也声明为 "GPL" 或 "GPL v2"。
4.3 作者信息
MODULE_AUTHOR() 用于声明模块的作者或维护者信息,通常包含姓名和联系方式(如邮箱)。该信息有助于用户了解模块来源,并在出现问题时联系作者。示例:
MODULE_AUTHOR("John Doe <john.doe@example.com>");
4.4 模块描述
MODULE_DESCRIPTION() 用于简要描述模块的功能,方便用户快速了解模块用途。示例:
MODULE_DESCRIPTION("Driver for XYZ USB device");
4.5 模块别名
MODULE_ALIAS() 可以为模块设置一个别名,便于用户或工具(如 modprobe)通过别名加载模块。例如,设备驱动可以通过别名匹配特定硬件 ID。需要注意的是,设置别名后,必须将模块安装到标准路径(如 /lib/modules/$(uname -r)/)并运行 depmod 命令更新模块依赖关系,内核才能识别该别名。示例:
MODULE_ALIAS("my-driver");
之后可使用 modprobe my-driver 加载该模块(前提是 depmod 已更新)。
4.6 查看模块信息
使用 modinfo 命令可以查看模块文件中的这些信息:
modinfo mymodule.ko
输出示例:
filename: mymodule.ko license: GPL author: John Doe <john.doe@example.com> description: Driver for XYZ USB device alias: my-driver depends: name: mymodule
这些声明虽非功能必需,但它们是模块的“身份证”,有助于模块的传播、维护和自动化管理,建议在开发中养成良好的信息标注习惯。
5. 内核模块传参
Linux 允许在加载模块时向模块传递参数,通过参数可以动态改变模块的行为,例如开启调试模式、设置缓冲区大小、指定设备编号等。模块参数通过特定的宏定义,加载时由 insmod 或 modprobe 传入。
5.1 参数定义
内核提供了两个核心宏用于定义模块参数:
#include <linux/stat.h> #define module_param(name, type, perm)
-
功能:用于定义一个指定的类型的模块参数。
-
参数:
-
name:参数名。同时需要模块内定义一个名字相同的全局或静态变量,该变量将接收参数值,且必须在使用此宏之前定义。 -
type:参数的数据类型,必须与变量的C类型严格对应 -
perm:参数在 sysfs 中的访问权限(见下文权限说明),如果为0则表示该参数不会出现在 sysfs 中。
-
#include <linux/stat.h> #define module_param_array(name, type, nump, perm)
-
功能:用于定义一个数组类型的模块参数。
-
参数:
-
name:参数名。同时需要模块内定义一个名字相同的全局或静态数组,该数组将接收参数值,且必须在使用此宏之前定义。 -
type:参数的数据类型。 -
nump:指向一个整型变量的指针,传入整形变量的地址,用于接收实际传入的数组元素个数。 -
perm:参数在 sysfs 中的访问权限(见下文权限说明)。
-
5.2 参数类型
目前内核支持以下参数类型,使用时需与变量类型匹配:
| 类型 | 说明 |
|---|---|
byte |
单字节(unsigned char) |
short |
短整型 |
ushort |
无符号短整型 |
int |
整型 |
uint |
无符号整型 |
long |
长整型 |
ulong |
无符号长整型 |
charp |
字符指针(字符串),模块应将其视为只读 |
bool |
布尔型,取值 0 或 1 |
invbool |
反布尔型,true 表示 0,false 表示 1 |
注意:变量类型与参数类型必须严格对应,例如 char 类型变量应使用 byte,char * 变量应使用 charp。
5.3 文件权限
perm 参数用于设置该参数在 sysfs 中的访问权限(定义在 linux/stat.h)。常用权限宏如下:
| 宏 | 值 | 说明 |
|---|---|---|
S_IRUSR |
0400 | 用户读 |
S_IWUSR |
0200 | 用户写 |
S_IRGRP |
0040 | 用户组读 |
S_IWGRP |
0020 | 用户组写 |
S_IROTH |
0004 | 其他用户读 |
S_IWOTH |
0002 | 其他用户写 |
S_IRUGO |
0444 | 所有用户读(常用) |
S_IWUGO |
0222 | 所有用户写(极少使用) |
重要限制:参数文件 不能 具有可执行权限。如果错误地加入了执行权限(如 S_IXUGO),加载模块时将会失败,提示类似“Invalid permissions”的错误。
上述文件权限唯独没有关于可执行权限的设置,请注意, 该文件不允许它具有可执行权限。如果强行给该参数赋予表示可执行权限的参数值S_IXUGO, 那么最终生成的内核模块在加载时会提示错误,见下图。

以下是一个完整的模块参数示例,演示了普通参数、数组参数以及字符串参数的定义和使用:
#include <linux/module.h>
#include <linux/init.h>
// 普通参数
static int debug = 0;
module_param(debug, int, S_IRUGO | S_IWUSR); // 所有用户可读,仅root可写
MODULE_PARM_DESC(debug, "Enable debug output (0=off, 1=on)");
// 字符串参数
static char *name = "default";
module_param(name, charp, S_IRUGO);
MODULE_PARM_DESC(name, "Device name");
// 数组参数
static int arr[5];
static int count;
module_param_array(arr, int, &count, S_IRUGO);
MODULE_PARM_DESC(arr, "An array of up to 5 integers");
static int __init my_init(void)
{
int i;
printk(KERN_INFO "Module loaded: debug=%d, name=%s\n", debug, name);
printk(KERN_INFO "Array elements (%d): ", count);
for (i = 0; i < count; i++)
printk("%d ", arr[i]);
printk("\n");
return 0;
}
static void __exit my_exit(void)
{
printk(KERN_INFO "Module unloaded\n");
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Module parameter example");
编译并加载该模块时,可以传入参数:
# 加载模块并传递参数 sudo insmod mymodule.ko debug=1 name="mydev" arr=10,20,30 # 查看已加载模块的参数值(位于 /sys/module/<模块名>/parameters/) cat /sys/module/mymodule/parameters/debug cat /sys/module/mymodule/parameters/name cat /sys/module/mymodule/parameters/arr
-
数组参数使用逗号分隔的值列表,最多传入定义的数组长度个元素。
-
若
perm允许写权限(如S_IWUSR),则可以通过 sysfs 文件动态修改参数值(需模块内部支持实时响应变化)。
5.4 注意事项
-
参数名与模块内全局变量名一致,类型必须匹配。
-
字符串参数(
charp)指向的内核内存应视为只读,切勿修改。 -
数组参数需要提供一个
int变量来接收实际元素个数。 -
权限设置应遵循最小权限原则,通常只读(
S_IRUGO)即可满足多数需求。
6. 符号的导出与使用
符号的导出,也一般直接说导出变量或导出函数。
如果需要导出变量或函数,一定不能加
static限制作用域。
在前面我们已经详细的分析了关于导出符号的内核源码,符号指的就是在内核模块中导出函数和变量, 在加载模块时被记录在公共内核符号表中,以供其他模块调用。 这个机制,允许我们使用分层的思想解决一些复杂的模块设计。我们在编写一个驱动的时候, 可以把驱动按照功能分成几个内核模块,借助符号共享去实现模块与模块之间的接口调用,变量共享。
导出符号的宏定义:
#include <linux/moduleparam.h> #define EXPORT_SYMBOL(sym) \\ __EXPORT_SYMBOL(sym, "")
EXPORT_SYMBOL宏用于向内核导出符号,这样的话,其他模块也可以使用我们导出的符号了。 下面通过一段代码,介绍如何使用某个模块导出符号。
以下是parameter_module.c:
//...省略代码...
static int itype=0;
module_param(itype,int,0);
EXPORT_SYMBOL(itype);
int my_add(int a, int b)
{
return a+b;
}
EXPORT_SYMBOL(my_add);
int my_sub(int a, int b)
{
return a-b;
}
EXPORT_SYMBOL(my_sub);
//...省略代码...
-
第2-3行:定义了模块参数 itype,并通过 EXPORT_SYMBOL 宏导出
-
第7-12行:和my_add,并通过EXPORT_SYMBOL宏导出
-
第14-21行:my_sub函数,并通过EXPORT_SYMBOL宏导出
以上代码中,省略了内核模块程序的其他内容,如头文件,加载/卸载函数等。
然后在需要使用该符号时,在模块的 .h 文件中包含声明:
// calculate.h #ifndef __CALCULATION_H__ #define __CALCULATION_H__ extern int itype; int my_add(int a, int b); int my_sub(int a, int b); #endif
声明额外的变量itype,my_add和my_sub函数。然后calculation.c:
//...省略代码...
#include "calculation.h"
//...省略代码...
static int __init calculation_init(void)
{
printk(KERN_ALERT "calculation init!\n");
printk(KERN_ALERT "itype+1 = %d, itype-1 = %d\n", my_add(itype,1), my_sub(itype,1));
return 0;
}
//...省略代码...
calculation.c 中使用 extern 关键字声明的参数 itype,调用 my_add()、my_sub() 函数进行计算。
三. 内核模块的调试
1. 模块编译方式选择
在 Linux 内核开发中,模块源码(包括驱动程序)有两种编译方式:
-
编译进内核(built-in)
-
将模块代码直接编译进 Linux 内核镜像(如 zImage)中。
-
内核启动时,这些模块会自动完成初始化并运行,无需人工加载。
-
适合最终稳定版驱动,但调试不方便,修改驱动需重新编译整个内核。
-
-
编译为模块(loadable module)
-
将模块代码编译成独立的
.ko文件,不集成进内核镜像。 -
系统启动后,可使用
insmod或modprobe命令手动加载内核模块,也可用rmmod卸载。 -
调试阶段推荐此方式,修改驱动后只需重新编译模块并加载,无需重启整个系统,待驱动稳定后再考虑编译进内核。
-
在调试驱动的时候一般都选择将其编译为模块,这样我们修改驱动以后只需要编译一下驱动代码即可,不需要编译整个 Linux 内核代码。在调试的时候只需要加载或卸载驱动模块即可,不需要重启整个系统,当驱动开发完成,确定没有问题以后就可以将驱动编译进 Linux 内核中。
Linux 可以编译到内核 kernel 里面,也就是 zImage,也可以编译为模块 .ko。测试的时候只需要加载 .ko 模块就可以。
2. 编写 Makefile 并编译
2.1 Makefile 编写
编写 Makefile 文件用于编译内核模块,其内容如下:
-
KERNELDIR:变量,用于保存 Linux 内核源码路径,使用绝对路径,需根据实际环境修改。 -
CURRENT_PATH:当前路径,可以通过运行$(shell pwd)命令来获取当前所处路径。 -
obj-m:指定要编译成模块的目标文件。这里chrdevbase.o表示将chrdevbase.c编译成内核模块,最终生成chrdevbase.ko。 -
build: kernel_modules 是规则,默认执行第一个规则下的命令
KERNELDIR := /root/linux/IMX6ULL/linux/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek CURRENT_PATH := $(shell pwd) obj-m := chrdevbase.o build: kernel_modules kernel_modules: $(MAKE) -C $(KERNELDIR) M=$(CURRENT_PATH) modules clean: $(MAKE) -C $(KERNELDIR) M=$(CURRENT_PATH) clean
Makefile 编写好以后输入make命令编译驱动模块。
2.2 中间文件
在 Linux 内核模块编译过程中,.mod.c 是一个由构建系统自动生成的中间文件,用于存储模块的元数据和必要的内核模块信息。它通常在编译的最后阶段由 modpost 工具生成,并被编译成 .mod.o 目标文件,最终链接到生成的 .ko 模块文件中。
.mod.c 该文件包含了以下关键信息:
-
模块许可证(
MODULE_LICENSE) -
作者(
MODULE_AUTHOR) -
描述(
MODULE_DESCRIPTION) -
版本(
MODULE_VERSION) -
设备表(如
MODULE_DEVICE_TABLE,用于热插拔和设备别名) -
模块依赖关系(通过
__module_depends或类似机制) -
内核版本校验信息(确保模块与当前运行的内核兼容)
-
模块参数的描述(如果使用了
module_param) -
指向模块初始化与清理函数的指针(
init_module和cleanup_module)
此外,.mod.c 还定义了 struct module __this_module 结构体实例,该结构体填充了上述元数据,供内核在加载模块时使用。
当执行 make 编译内核模块时,构建系统会执行以下步骤:
-
编译每个
.c源文件,生成对应的.o目标文件。 -
运行
modpost工具对生成的.o文件进行分析,提取符号和元数据,生成.mod.c文件。 -
编译
.mod.c为.mod.o目标文件。 -
将原始的
.o文件和.mod.o链接在一起,形成最终的.ko模块文件。
3. 加载和卸载驱动模块
我们如愿编译了自己的内核模块,接下来就该了解如何使用这个内核模块了。 将hellomodule.ko通过scp或NFS拷贝到开发板中,我们来逐一讲解这些工具。要使用模块,需要将其加载到内核中;不再使用时,则应从内核卸载。本节介绍常用的模块管理命令及其用法。
3.1 模块的存放位置
在 Linux 系统中,模块通常集中存放在 /lib/modules/$(uname -r)/ 目录下,该目录包含了与当前内核版本相关的模块及配置文件。其典型目录结构如下:
-
kernel:包含编译后的内核模块文件(.ko)
-
modules.dep:列出了模块之间的依赖关系
-
modules.symbols:保存导出的符号信息
-
modules.order:定义模块加载顺序的文件
我们最关心的配置文件是modules.dep,该文件列出了模块之间的依赖关系,当我们执行depmod -a建立模块之间的依赖关系时,就会把依赖关系写入到modules.dep当中。
其中,我们最关心的配置文件是modules.dep,该文件记录了模块间的依赖关系。当我们执行 depmod -a 命令建立模块之间的依赖关系时,系统会扫描所有可用模块,把依赖关系写入到modules.dep当中。
3.2 模块的加载
Linux 提供了两种主要的模块加载命令:insmod 和 modprobe:
如果要将一个模块加载到内核中,insmod是最简单的办法, insmod+模块完整路径就能达到目的,前提是你的模块不依赖其他模块,还要注意需要sudo权限。 如果你不确定是否使用到其他模块的符号,你也可以尝试modprobe,后面会有它的详细用法。
通过insmod命令加载hellomodule.ko内存模块加载该内存模块的时候, 该内存模块会自动执行module_init()函数,进行初始化操作,该函数打印了 ‘hello module init’。 再次查看已载入系统的内核模块,我们就会在列表中发现hellomodule.ko的身影。
但是有些内核模块有依赖关系,不能直接用insmod加载,需要“前置”依赖模块加载后才能加载,在我们后续实验——内核模块传参与符号共享实验这一小节中,calculation.ko和parametermodule.ko有依赖关系。 其中calculation.ko依赖parametermodule.ko中的参数和函数, 所以先手动加载parametermodule.ko,然后再加载calculation.ko。
同样卸载的时,parametermodule.ko中的参数和函数被calculation.ko调用,必须先卸载calculation.ko 再卸载parametermodule.ko,否则会报错”ERROR: Module parametermodule is in use by: calculation”
modprobe和insmod具备同样的功能,同样可以将模块加载到内核中,除此以外modprobe还能检查模块之间的依赖关系, 并且按照顺序加载这些依赖,可以理解为按照顺序多次执行insmod。
在我们后续实验——内核模块传参与符号共享实验中,calculation.ko和parametermodule.ko需要按照先后次序依次加载,而使用modprobe工具, 可以直接加载parametermodule.ko,当然modprobe之前需要先用depmod -a建立模块之间的依赖关系,但值得注意的是使用depmod -a必须要将驱动模块放入系统驱动模块存放和配置的文件夹,否者无法管理依赖关系。
3.3 模块的卸载
rmmod
rmod工具仅仅是将内核中运行的模块删除,只需要传给它路径就能实现。
rmmod命令卸载某个内存模块时,内存模块会自动执行_exit()函数,进行清理操作, 我们的hellomodule中的_exit()函数打印了一行内容,但是控制台并没有显示,可以使用dmesg查看, 之所以没有显示是与printk的打印等级有关,前面有关于printk函数有详细讲解。 rmmod不会卸载一个模块所依赖的模块,需要依次卸载,当然是用modprobe -r 可以一键卸载。
3.4 查看模块信息
lsmod 命令可以列出当前内核中已加载的所有模块,格式化显示在终端,其原理就是将/proc/modules中的信息调整一下格式输出,包含模块名称、大小、被使用次数和依赖关系等信息。 输出列表有一列Used by, 它表明此模块正在被其他模块使用,显示了模块之间的依赖关系。
lsmod
modinfo 命令用来查看模块的详细信息,包括许可证、作者、描述、依赖以及编译信息等。这些信息由模块源码中的 MODULE_* 宏定义。
modinfo hellomodule.ko # 或查询已安装模块 modinfo hellomodule
输出示例:
filename: hellomodule.ko license: GPL author: embedfire description: A simple hello module depends: parammodule vermagic: 5.10.0 SMP mod_unload
3.5 模块依赖管理
modprobe是怎么知道一个给定模块所依赖的其他的模块呢?在这个过程中,depend起到了决定性作用,当执行modprobe时, 它会在模块的安装目录下搜索module.dep文件,这是depmod创建的模块依赖关系的文件。
insmod 命令不能解决模块的依赖关系,比如 drv.ko 依赖 first.ko 这个模块,就必须先使用 insmod 命令加载 first.ko 这个模块,然后再加载 drv.ko 这个模块。但是 modprobe 就不会存在这个问题,modprobe 会分析模块的依赖关系,然后会将所有的依赖模块都加载到内核中,因此modprobe 命令相比 insmod 要智能一些。
modprobe 命令主要智能在提供了模块的依赖性分析、错误检查、错误报告等功能,推荐使用 modprobe 命令来加载驱动。modprobe 命令默认会去 /lib/modules/<kernel-version>目录中查找模块,比如 Linux kernel 的版本号为 4.1.15,因此 modprobe 命令默认到 /lib/modules/4.1.15 这个目录中查找相应的驱动模块,所以编译好的驱动模块需要放到这个目录下才能使用该命令加载。
modprobe drv.ko
注意:加载和卸载模块通常需要超级用户权限(root),因此命令前可能需要加上
sudo,或者以 root 身份执行。在嵌入式开发板中,通常直接使用 root 账户操作。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)