极海芯得EP.39 | 无FPU也能飞: G32R430实测ATAN2硬件加速有多快
本文探讨了电机控制中角度解算的关键问题,介绍了G32R430芯片通过CDE协处理器和ATAN2硬件加速的创新解决方案。在无FPU的情况下,该方案将atan2运算时间从软件实现的5000+周期压缩至300周期左右,大幅提升了实时性。文章详细分析了测试数据,对比了不同平台和实现方式的性能差异,指出专用硬件路径在保证计算精度的同时,显著改善了高频控制环的响应速度。测试结果表明,G32R430的定点+CD
1 开场白: 咱们先聊一个灵魂问题
咱们做电机控制时,最怕什么?
不是算法不会写,而是算得不够快。
尤其在单轴伺服、磁编码器、旋变这些场景里,角度解算是每个控制周期的“必修课”。
最经典一步就是把 (sin, cos) 或 (x, y) 算成 atan2,再喂给位置环、速度环、电流环。
问题来了:没有 FPU 怎么办?
纯软件 atan2 常常慢得让中断服务程序“压力山大”,20kHz 甚至 40kHz 一上来,时间预算直接告急。
所以这次咱们不空谈,直接看 G32R430 的做法:
不用通用浮点硬刚,走 CDE 协处理器 + ATAN2 硬件加速。
这篇文章我们一起来看看这三件事:
- 为什么
atan2在编码器场景里是刚需; - G32R430 的
CDE + ATAN2具体怎么干活; - 实测周期到底差多少,值不值得咱们上车。
2 测试前提: 先把口径说清楚
咱们先把“实验台参数”摆出来,避免后面各说各话:
- 芯片/内核:G32R430(基于 Arm Cortex-M52 定制版本,含 CDE,无 FPU/DSP/MVE)。
- SDK:G32R430 DDL SDK V1.0.2(ATAN2 例程路径
Examples/Board_G32R430_Tiny/ATAN2/ATAN2_Math/)。 - 关键头文件版本:
Libraries/ATAN2/MathLib.h。 - 示例工程版本:
ATAN2_Math/Source/main.c。 - 关键 API:
int32_t ATAN2(int32_t nX, int32_t nY, int32_t nPrecisionLevel); - 编译配置:与官方工程一致,如
-mcpu=cortex-m52+nomve+nofp+cdecp3。 - 主频/测量:示例工程系统时钟
120 MHz,使用 DWT cycle counter。
3 为什么我们总离不开ATAN2
旋变、磁编码器常吐出 sinθ、cosθ 这对“好兄弟”,咱们要拿到角度,核心就一句:
θ = atan2(sinθ, cosθ)
在 FOC 链路里,这一步还是“常驻嘉宾”。
Clarke/Park、反变换这些环节都盯着当前电角度,atan2 基本常年在实时路径加班。
所以我们知道,atan2 不是锦上添花,而是主食。
它快不快、稳不稳,直接影响闭环是否丝滑。
4 G32R430的思路: 不求全能,但求对症下药
很多 MCU 是“全家桶”,G32R430 更像“偏科天才”:
- 不带 FPU/DSP/MVE;
- 引入 CDE 协处理器;
- 重点照顾角度解算这类高频定点任务。
说白了就是一句:
把晶体管预算花在咱们最常跑、最该快的路径上。
5 CDE+ATAN2怎么用: 接口不难,坑点要记住
SDK 接口如下:
/**
* [url=/u/brief]@brief[/url] Computes the angle of a point (nX, nY) on a two-dimensional plane in Q32 format.
* @param: nX X-axis coordinate
* @param: nY Y-axis coordinate
* @param: nPrecisionLevel Specifies the precision level from 1 to 8;
* higher precision increases accuracy but slows computation.
* Recommended values: 6, 7, 8
* [url=/u/return]@return[/url] The angle value in the range (-1, 1], Q31 format, corresponding to (-π, π].
*/
int32_t ATAN2(int32_t nX, int32_t nY, int32_t nPrecisionLevel);
nX/nY:Q 格式定点输入坐标;nPrecisionLevel:1~8 档,官方建议常用 6/7/8;- 返回值:Q31,范围对应
(-π, π](接口文档中写作(-1, 1]归一化表示)。
这里我重点提醒一个巨容易踩的坑:
标准数学库是 atan2(y, x),SDK 接口是 ATAN2(x, y, level)。(请注意是大写哦)
示例代码也是这个顺序:x=cos(theta)、y=sin(theta),调用 ATAN2(x, y, level)。
这个顺序写反,角度就可能“人还在家,坐标先飞了”。
6 工程落地: 咱们让关键代码跑在ITCM
极海官方提供的.sct链接脚本把ATAN2 函数默认放到了 ITCM,目的是减少取指等待和周期抖动。
程序启动后从 Flash 拷到 ITCM,运行阶段零等待取指。
所以即使你切“Flash 工程”或“ITCM/RAM 工程”,
CDE 这段关键角度解算代码依然在 ITCM 跑,花费的时间便是“稳稳的幸福~”。
7 实测数据: 这波到底快了多少
先补一句对照平台说明,避免“拿不同选手硬比”:
咱们这里引入的 G32R501,也是 Arm Cortex-M52 架构平台,但定位更偏“全功能性能型”:
- 双核 Cortex-M52,主频最高
250 MHz; - 内置自研紫电数学指令扩展单元;
- 支持 Arm Helium 技术;
- 支持单精度/双精度 FPU;
- 支持 DSP。
一句话理解:G32R430 是专精取舍路线,G32R501 是功能更完整路线。
所以这组图和表主要用于看“工程实现路径与周期数量级差异”。
下面开始看图(来自 图片材料):
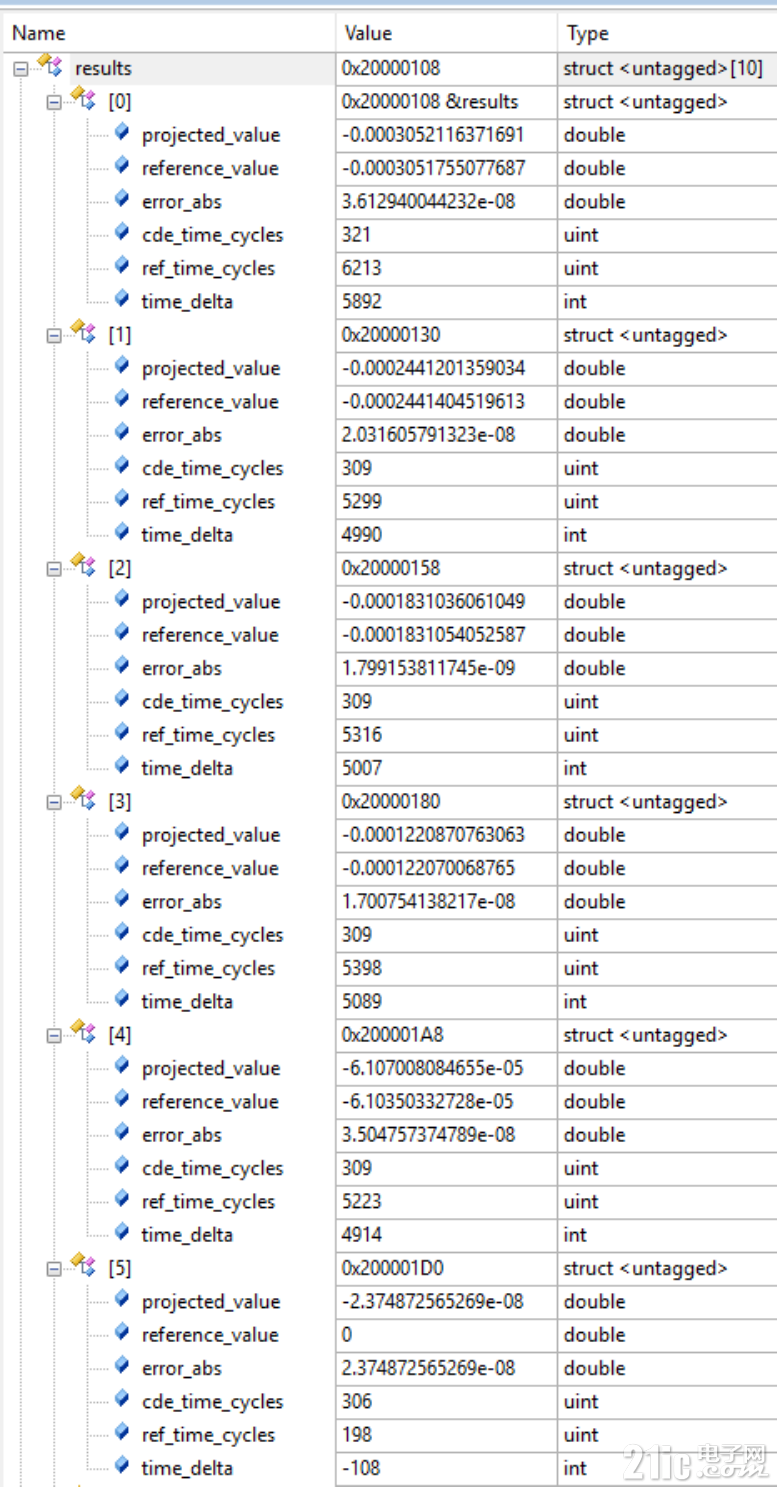
这张是 G32R430 平台、Flash 工程、-O3 配置 下的测试数据。
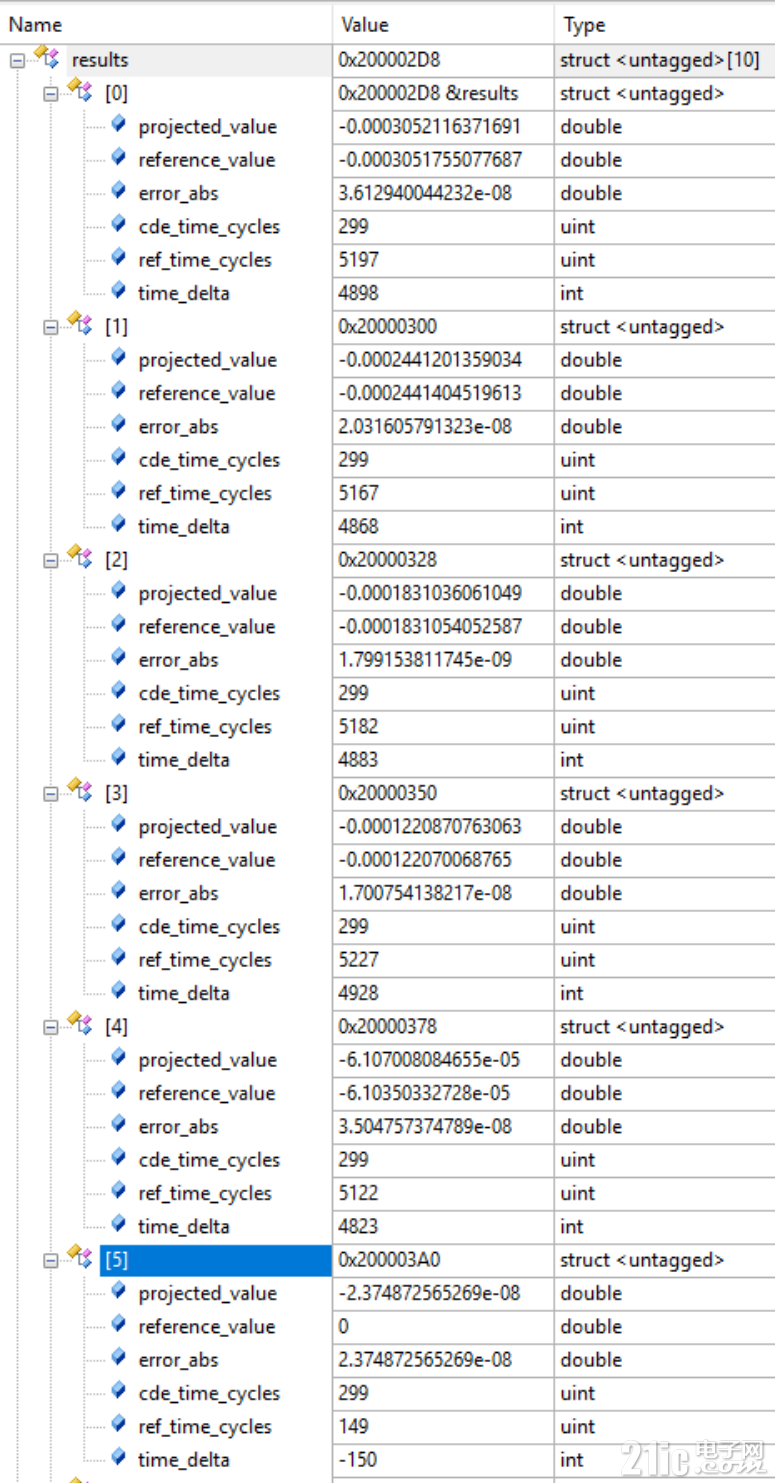
这张是 G32R430 平台、ITCM/RAM 工程、-O3 配置 下的测试数据。
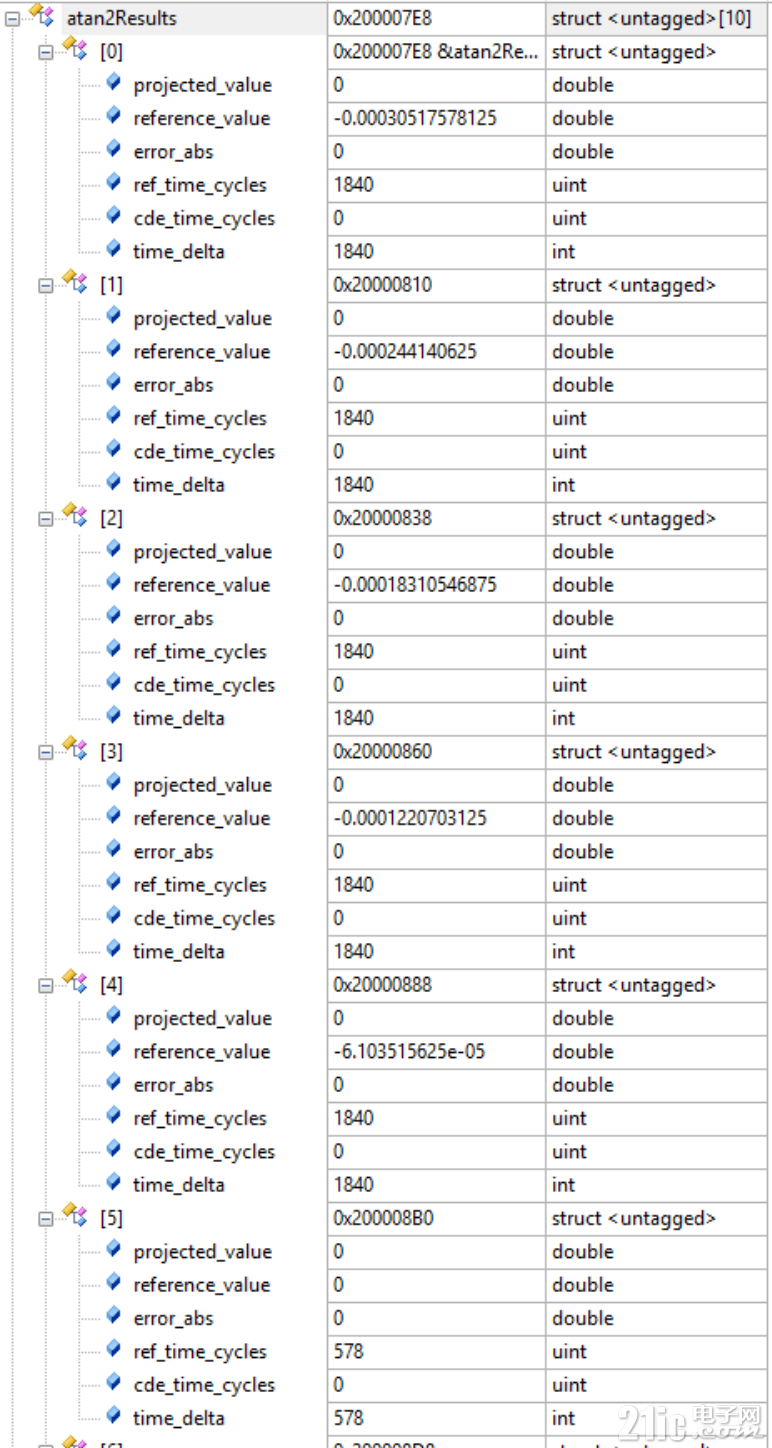
这张是 G32R501 平台、CBUS Flash 工程、-O3 配置(DP FPU路径) 下的测试数据。
这张是 G32R501 平台、ITCM/RAM 工程、-O3 配置(DP FPU路径) 下的测试数据。
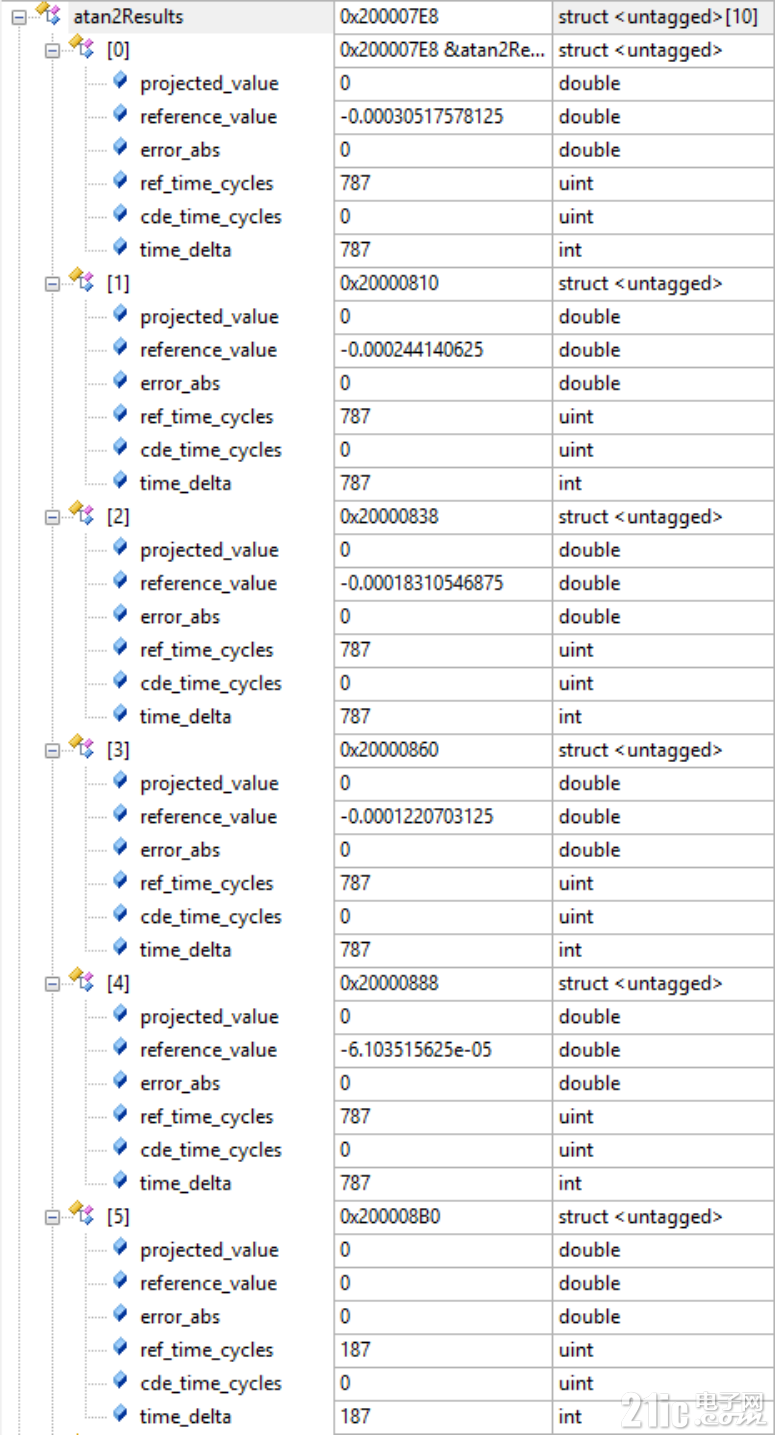
先说清口径,咱们避免“苹果橘子一起比”:
- 两平台均用各自官方示例工程,优化等级按工程配置为
-O3; - 周期统计统一看 DWT cycle;
- G32R430 数据来源为
ATAN2(..., 6)+ 软件参考atan2对照; - 跨平台对比用于看数量级,不代表完全同软件栈下的绝对横评。
测试点:angle_param = PI/65536.0 * idx * 4.0,idx=-5~0。
其中 G32R430 使用 ATAN2 精度档位 6。
| 序号 | angle_param(idx) | G32R430 Flash CDE (cyc) | G32R430 Flash ref (cyc) | G32R430 ITCM CDE (cyc) | G32R430 ITCM ref (cyc) | G32R501 Flash (cyc) | G32R501 ITCM (cyc) |
|---|---|---|---|---|---|---|---|
| 1 | PI/65536×(-5)×4 | 321 | 6213 | 299 | 5197 | 1840 | 787 |
| 2 | PI/65536×(-4)×4 | 309 | 5299 | 299 | 5167 | 1840 | 787 |
| 3 | PI/65536×(-3)×4 | 309 | 5316 | 299 | 5182 | 1840 | 787 |
| 4 | PI/65536×(-2)×4 | 309 | 5398 | 299 | 5227 | 1840 | 787 |
| 5 | PI/65536×(-1)×4 | 309 | 5223 | 299 | 5122 | 1840 | 787 |
| 6 | idx=0(角度≈0) | 306 | 198 | 299 | 149 | 578 | 187 |
为了让比较更直观,我们把同一组数据画成了相对倍数柱状图:
以每个测试点的 G32R430 Flash CDE 为 1.0x 基准,其他路径都按相对倍数计算。
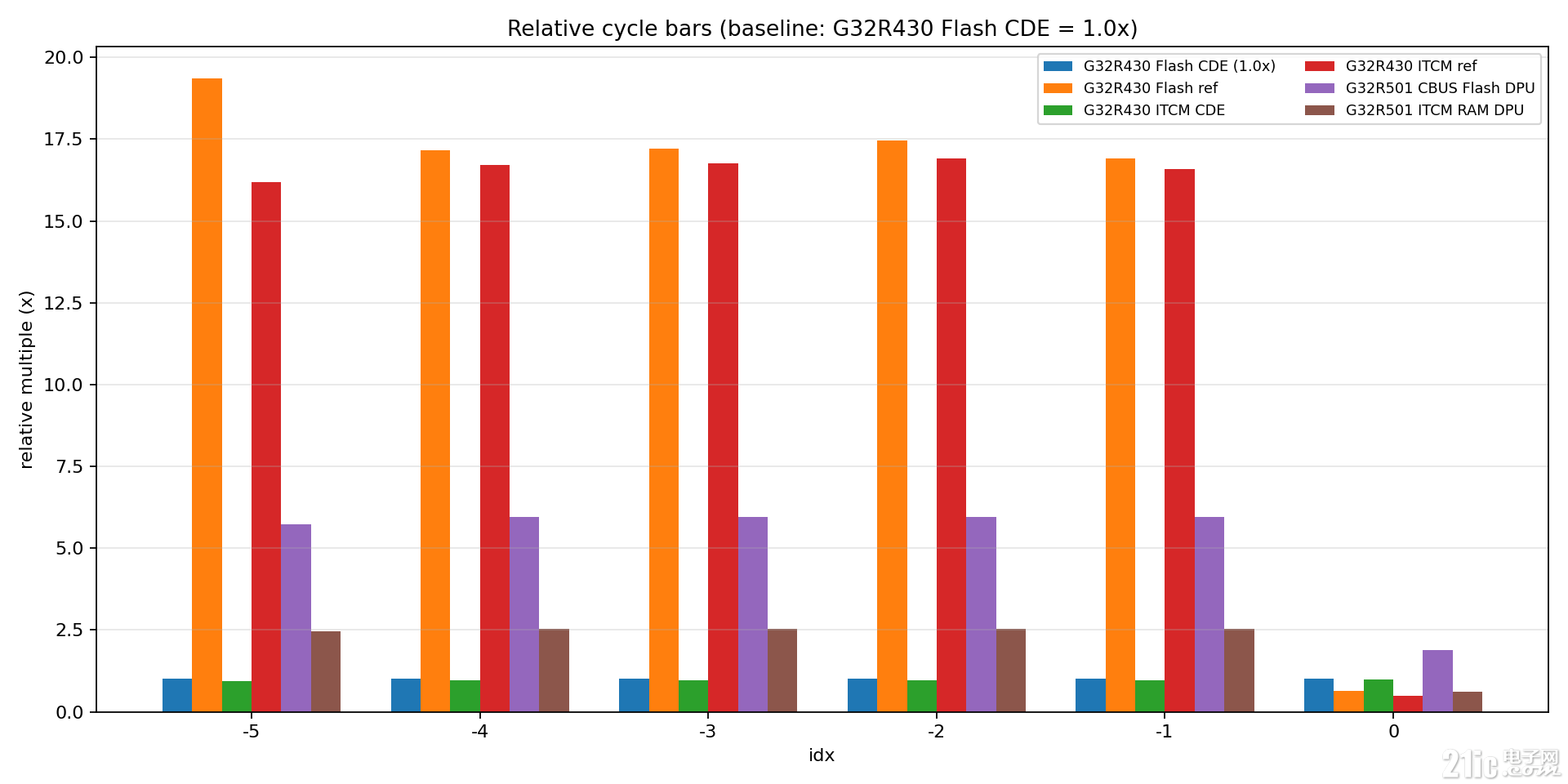
G32R430 Flash CDE全程是1.0x(基准线);- 常规角度点(idx=-5~-1)里,
G32R430 Flash ref大约在16x~19x,和 CDE 路径差距非常直观; G32R430 ITCM CDE基本贴近1.0x,说明 CDE 路径在不同工程放置下都很稳;idx=0时,软件路径倍数明显回落(快速路径触发)。
7.1 咱们怎么读这组表
- 常规角度点(序号 1~5)里,G32R430 CDE 大约
299~321 cyc; - 同平台软件参考
atan2在5k~6k cyc,差距是数量级的; - Flash CDE 和 ITCM CDE 接近,核心原因就是 ATAN2 关键路径本来就在 ITCM;
idx=0时软件突然变快,通常是atan2(0,1)=0的快速路径触发;- 对高频 中断服务 来说,我们更看重“稳定快”,而不是“偶尔飞快”。
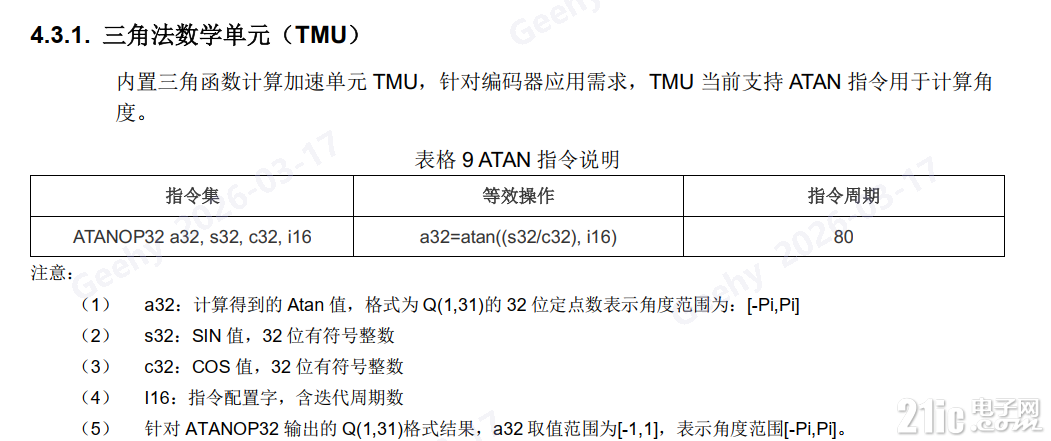
7.2 手册写80cycles,为什么上面的是300多的cycles?
咱们先回到上面的对比表:G32R430 Flash CDE/G32R430 ITCM CDE 大多落在 300+ cycles。
很多读者看到这里会问:手册写 80 cycles,怎么实测会到 300+?
这时候我们就需要把“统计口径”拆开看。
先看手册(TMU/ATAN 指令说明),它给的是指令级口径:
接着,我们单独做一次“单次 ATAN2 调用”测试,尽量压缩外围流程,看看函数级口径。
单次测量代码(ATAN2_Math/Source/main.c):
SECTION_DTCM_DATA uint32_t single_atan2_cycles = 0U;
SECTION_DTCM_DATA int32_t single_theta_q31 = 0;
SECTION_DTCM_DATA int32_t single_x_q30 = double_to_q30(0.8660254037844386); /* cos(30deg) */
SECTION_DTCM_DATA int32_t single_y_q30 = double_to_q30(0.5); /* sin(30deg) */
/**
* @brief Standalone benchmark for one ATAN2 execution.
*
* @param None
*
* @retval None
*/
void RunSingleAtan2Benchmark(void)
{
GET_DWT_CYCLE_COUNT(single_atan2_cycles,
single_theta_q31 = ATAN2(single_x_q30, single_y_q30, 8);
);
printf("Single ATAN2 benchmark:\n");
printf(" Input (Q30): x=%d, y=%d\n", single_x_q30, single_y_q30);
printf(" Output (Q31 norm): %.10f\n", q31_to_double(single_theta_q31));
printf(" ATAN2 cycles: %lu\n\n", (unsigned long)single_atan2_cycles);
}
串口输出如下:
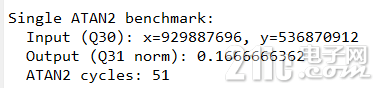
这时就能把三个数字串起来了:
- 手册口径(指令级):
80 cycles,对应 TMUATANOP32指令说明; - 单测口径(函数级):约
51 cycles,对应一次ATAN2(...)的最小调用路径; - 表格口径(示例对齐级):约
300+ cycles,这是示例里为与软件参考结果对齐而做的整套计算路径,包含参数准备、测量宏开销以及结果换算(例如q31_to_double)等步骤。
所以“80 / 51 / 300+”并不冲突,而是三个不同视角:
- 手册告诉我们“硬件指令大概多快”;
- 单测告诉我们“函数本体大概多快”;
- 表格告诉我们“示例对齐比较时的整链路大概多快”。
最终结论一句话:
做本体性能判断看函数级,做指令上限判断看指令级;示例对齐数据用于横向比较更合适。
8 精度档位怎么挑: 先6,再7/8
nPrecisionLevel 可调 1~8,咱们实操建议:
- 先从 6 档起步(速度和精度通常更均衡);
- 误差预算更紧时,再试 7/8;
- 每升一档会有额外开销,建议结合编码器分辨率和环路带宽做闭环验证。
一句话:
先把实时性保住,再慢慢榨精度。
9 收个尾: 咱们最后记住三件事
这次实测我认为最关键的结论有三条:
- G32R430 用专用硬件路径替代通用浮点大件;
- 定点 + CDE 能把
atan2压到约300 cycles量级; - 在高频控制环里,能同时拿到实时性、确定性和功耗收益。
对编码器和单轴伺服场景来说,这种思路很对路:
没有 FPU,也能把角度算得又快又稳。
10 参考
G32R430_DDL_SDK_V1.0.2/Libraries/ATAN2/MathLib.hG32R430_DDL_SDK_V1.0.2/Examples/Board_G32R430_Tiny/ATAN2/ATAN2_Math/

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐


 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)