C28x或C2000 — C28x 架构和加速器
C2000™ 系列实时控制微控制器基本架构概述
C28x 架构和加速器
下面是对 C2000™ 系列实时控制微控制器基本架构概述。C2000 实时控制 MCU 具有高度集成的模拟和控制外设,可为数字电源、工业驱动、变频器和电机控制等要求苛刻的实时高性能信号处理应用提供完整的解决方案。
C28x CPU
它是通用微控制器和数字信号处理器(DSP)的结合体,兼顾了 RISC 处理器的代码密度和 DSP 的执行速度,以及微控制器的架构、固件和开发工具。MCU 的功能包括改进的哈佛架构和循环寻址。RISC 的特点是单周期指令执行、寄存器到寄存器操作和改进的哈佛架构。微控制器的特点包括通过直观的指令集、字节打包和解包以及位操作实现易用性。
TMS320C28x CPU 和指令集参考指南介绍了中央处理器(CPU)和汇编语言指令。
CPU 的一些主要功能包括:
Protected pipeline: CPU 实现了一个 8 阶段流水线,可防止写入同一位置和从同一位置读取数据时出现顺序错误。
Independent register space: CPU 包含未映射到数据空间的寄存器。这些寄存器的功能包括系统控制寄存器、数学寄存器和数据指针。系统控制寄存器由特殊指令访问。其他寄存器通过特殊指令或特殊寻址模式(寄存器寻址模式)访问。
Arithmetic logic unit (ALU): 32 位 ALU 执行二进制算术和布尔逻辑运算。
Address register arithmetic unit (ARAU): AU 生成数据内存地址,并与 ALU 运算并行递增或递减指针。
Barrel shifter: 该移位器执行所有数据的左右移位。它可以将数据向左移动最多 16 位,向右移动最多 16 位。
Multiplier: 乘法器执行 32 位 × 32 位二进制乘法,结果为 64 位。乘法运算可以使用两个有符号数、两个无符号数或一个有符号数和一个无符号数。
C28x 设计支持高效的 C 引擎,其硬件允许 C 编译器生成简洁的代码。多总线和内部寄存器总线允许以高效灵活的方式对数据进行操作。该架构还支持强大的寻址模式,允许编译器和汇编程序员生成与 C 代码几乎一一对应的精简代码。
C28x Internal Bussing
在每个 C2000 设备的数据表中都有一个 CPU 系统和相关外设的 “功能框图”。请参考此图,了解设备内每个不同组件的总线结构。与许多高性能微控制器一样,多总线用于在内存块、外设和 CPU 之间移动数据。C28x 存储器总线结构包括六条总线(三条地址总线和三条数据总线):
- A program read bus (22-bit address line and 32-bit data line)
- A data read bus (32-bit address line and 32-bit data line)
- A data write bus (32-bit address line and 32-bit data line)
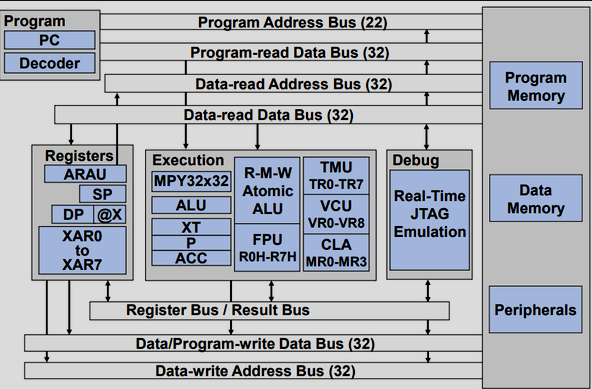
32 位宽数据总线提供单周期 32 位操作。这种多总线架构(哈佛总线架构)使 C28x 能够在一个周期内获取指令、读取数据值和写入数据值。所有外设和内存块都连接到内存总线上,内存访问具有优先级。
C28x Math Accelerators
C28x 还可通过数学加速器(如下所示)进行增强。请注意,并非所有加速器都适用于每个器件(更多信息请参阅 C2000 实时控制 MCU 外设参考指南)。有关具体实现,请参阅器件数据表。
Control Law Accelerator (CLA): 独立的 32 位浮点数学硬件加速器,可与主 C28x CPU 并行执行实时控制算法,有效地将计算性能提高一倍。通过直接访问各种控制和通信外设,CLA 最大限度地减少了延迟,实现了快速触发响应,并避免了 CPU 的开销。
Floating Point Unit (FPU): 定点 CPU 内核增加了浮点单元 (FPU),可支持硬件 IEEE-754 单精度浮点格式操作。FPU 在标准 C28x 架构中增加了一组扩展的浮点寄存器和指令,将浮点硬件无缝集成到 CPU 中。这种专用的硬件加速器可以更优化地使用浮点计算和库。使用 FPU 的库包括 DSP 库(FFT、滤波器、矢量)和 FPUfastRTS 库。
Trigonometric Math Unit (TMU): TMU 扩展了 CPU 的功能,可高效执行控制系统应用中常见的三角运算和算术运算。它还为 IEEE-754 单精度浮点运算提供硬件支持,从而加速三角数学函数。DSP FFT 库利用该加速器对某些功能进行优化。
Viterbi, Complex Math, and CRC Unit (VCU): VCU 进一步扩展了 CPU 的功能,支持各种基于通信的算法,对于滤波和频谱分析等通用信号处理应用非常有用。VCU 在 DSP VCU 库中的使用取决于设备可用的 VCU 类型。对于 VCU0(VCU0/VCU1),该库提供 FFT、CRC 和 Viterbi 解码器;对于 VCU2,该库提供 FFT、CRC、Viterbi 解码器、Reed Solomon 解码器和去交织器。
C28x CPU + Math Accelerators
下图说明了本模块中迄今讨论过的不同组件如何共同发挥作用。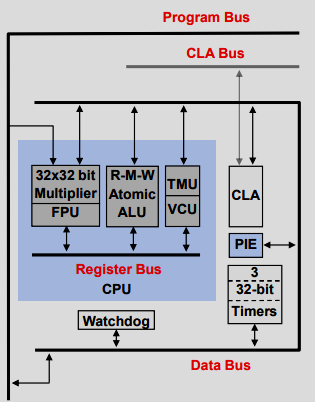
总结好处:
- MCU/DSP 兼顾代码密度和执行时间,16 位指令提高代码密度而32 位指令缩短执行时间。
- 32 位定点 CPU + FPU
- 32x32 定点乘积 (MAC),双通道 16x16 MAC
- IEEE 单精度浮点硬件和 MAC
- 浮点运算简化软件开发并提高性能
- Viterbi、复杂数学、CRC 单元 (VCU) 增加了对Viterbi解码、复杂数学和循环冗余校验 (CRC) 操作的支持
- 并行处理控制律加速器 (CLA) 增加了 IEEE 单精度 32 位浮点数学运算功能
- CLA 算法的执行独立于主 CPU
- TMU 支持的三角函数运算
- 快速中断服务时间
- 单周期读-修改-写指令
C28x 处理 DSP 数学任务和系统控制任务的效率一样高。这种效率使许多系统不再需要第二个处理器。32 x 32 位乘法累加 (MAC) 功能还可支持 64 位处理,使 C28x 能够高效地处理更高的数字分辨率计算,否则将需要更昂贵的解决方案。此外,它还能同时执行两条 16 x 16 位乘法累加指令或双 MAC (DMAC)。
Special Instructions
原子指令是一组不可中断的小型通用指令。原子 ALU 功能支持管理任务和进程的指令和代码。这些指令的执行速度通常比传统编码快几个周期。
原子指令好处:更简单的编程,更小、更快的代码,不间断(原子),更高效的编译器。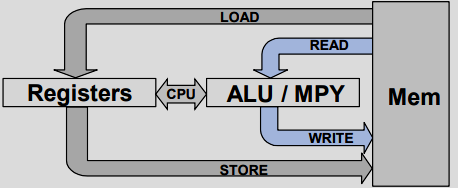
下面是比较: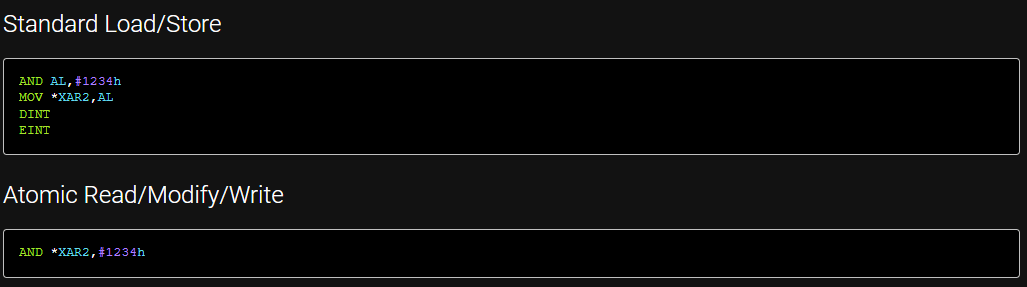
CPU Pipeline
C28x 采用特殊的 8 级保护流水线,以最大限度地提高吞吐量。该保护流水线可防止对同一位置的写入和读取发生顺序错误。这种流水线还能使 C28x CPU 高速运行,而无需使用昂贵的高速存储器。特殊的分支前瞻硬件最大限度地减少了条件中断的延迟。特殊的存储条件操作进一步提高了性能。有了 8 级流水线,大多数操作都可以在一个周期内完成。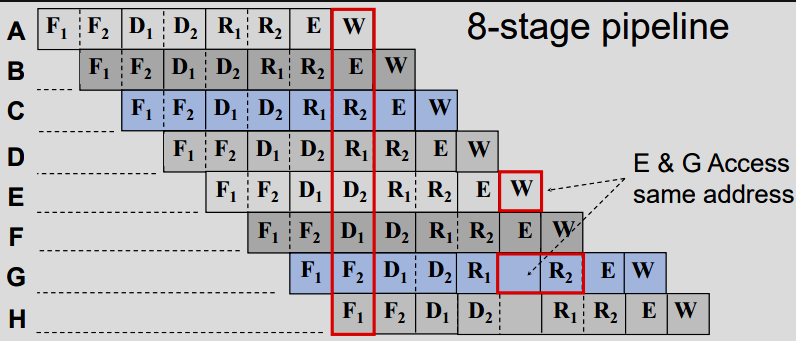
RISC机器的五层流水线示意图(IF:读取指令,ID:指令解码,EX:执行,MEM:存储器访问,WB:写回寄存器),与上图字母缩写对应。
Peripheral Write-Read Protection
外设写入-读取保护是一种保护不同地址外设写入-读取顺序的机制。其工作原理类似于中央处理器流水线对同一地址写入读取顺序的保护。假设您需要写入一个外设寄存器,然后读取同一外设的另一个寄存器(例如,写入控制寄存器,读取状态寄存器)?
CPU 流水线保护同一地址的 W-R 顺序,写入-读取保护机制保护不同地址的 W-R 顺序。
Memory
C2000 设备采用内存映射,统一内存块可在程序空间、数据空间或两个空间中访问。这种内存映射非常适合支持高级编程语言。内存映射结构包括 CPU 专用 RAM 块、CPU 和 CLA 可访问的 RAM 块、DMA 模块可访问的 RAM 块、CPU 和 CLA 之间的报文 RAM 块、CAN 报文 RAM 块、闪存和一次性可编程 (OTP) 内存。引导 ROM 出厂时已编程,包含引导软件例程和数学相关算法中使用的标准表。
Memory Map
C28x CPU 内核不包含内存,但可以访问片内和片外内存。C28x 使用 32 位数据地址和 22 位程序地址。这样,数据存储器的总寻址范围可达 4GB(4G 字,其中 1 字 = 16 位),程序存储器的总寻址范围可达 4MB(400 万字)。
设备的内存图可在设备数据表 “详细说明 ”一章的 “内存 ”部分找到。内存映射中包含专用 RAM (Mx RAM)、本地共享 RAM (LSx RAM) 和全局共享 RAM (GSx RAM) 的内容。
专用内存块与 CPU 紧密耦合,只有 CPU 可以访问这些内存块。CPU 和 CLA 可访问本地共享内存块。CPU 和 DMA 可访问四个全局共享内存块。
用户 OTP 是一次性可编程存储器块,除了闪存状态机用于擦除和编程操作的设置外,还包含 ADC、内部振荡器和缓冲 DAC 的设备特定校准数据。此外,它还包含用于编程安全设置的位置,例如用于选择性保护内存块的密码、配置独立启动过程以及在无法使用出厂默认引脚的情况下选择启动模式引脚。这些信息被编程到双代码安全模块(DCSM)中。闪存主要用于存储程序代码,但也可用于存储静态数据。启动 ROM 和启动 ROM 向量位于内存图的底部。
Multi Core Devices
C2000 产品组合提供单核和多核器件。包含多核的器件是 F2837xD 和 F2838xD 器件。每个 C28x 内核都是相同的,可以访问自己的本地 RAM 和闪存以及全局共享 RAM 内存。两个 CPU 内核之间的信息共享是通过一个处理器间通信(IPC)模块实现的。此外,每个内核还可共享一组高度集成的模拟和控制外设,为数字电源、工业驱动、变频器和电机控制等要求苛刻的实时高性能信号处理应用提供了完整的解决方案。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐


 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)