图像超分辨率模型记录(一)
图像超分辨率模型:SRCNN、FSRCNN、ESPCN、VDSR、DRCN、DRRN、EDSR、MDSR,自用学习笔记,包含模型结构、模型解释和模型实现代码
1. SRCNN
论文出处:Image Super-Resolution Using Deep Convolutional Networks(SRCNN)
模型结构: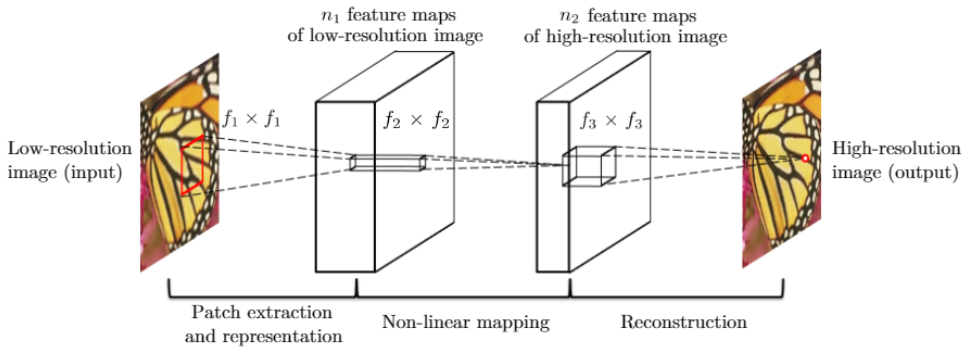
模型步骤:
- 图像预处理:考虑一个低分辨率图像,使用双三次插值(BiCubic插值)将其升级到所需的大小,我们将插值后的图像表示为Y,目标是从Y中恢复与真实高分辨率图像X尽可能相似的图像。为了便于表示,我们仍然将Y成为“低分辨率图像”(其实经过双三次插值处理后已经不算是低分辨率),且Y的大小和X的大小相同。
- 补丁提取和表示(低分辨率图像特征提取):从低分辨率图像Y中提取(重叠)补丁,并将每个补丁表示为一个高维向量。这些向量包含一组特征图,其中数字等于向量的维数。
- 非线性映射:将每个高维向量非线性映射到另一个高维向量上。每个映射向量在概念上都是高分辨率补丁的表示。这些向量包含另一组特征图。
- 重建:整合第3步的所有特征,生成最终的高分辨率图像。
模型代码实现:
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
# 第一层卷积:
# 输入通道数由num_channels指定(默认为1),单通道图像
# 输出通道数64,卷积核9x9,填充为9//2=4(保持输入输出尺寸相同)
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
# 第二层卷积:
# 输入通道数64,输出通道数32,卷积核5x5,填充为5//2=2
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
# 第三层卷积:
# 输入通道数32,输出通道数与输入相同(由num_channels指定)
# 卷积核5x5,填充为5//2=2
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
# ReLU激活函数(inplace=True表示直接修改输入,节省内存)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
"""
前向传播过程
参数:
x (Tensor): 输入张量,形状为(batch_size, num_channels, H, W)
返回:
Tensor: 输出张量,形状与输入相同(batch_size, num_channels, H, W)
"""
# 第一层卷积 + ReLU激活
x = self.relu(self.conv1(x))
# 第二层卷积 + ReLU激活
x = self.relu(self.conv2(x))
# 第三层卷积(不接激活函数,直接输出)
x = self.conv3(x)
return x
根据论文中第4节实验部分开头所述,RGB颜色模式色调、色度、饱和度三者混在一起难以分开,超分只用于YCbCr的Y通道,即亮度分量。因此,需要将图像数据由RGB模型转换为YCbCr颜色模式,其中Y是指亮度分量,Cb表示RGB输入信号蓝色部分与RGB信号亮度值之间的差异,Cr表示RGB输入信号红色部分与RGB信号亮度值之间的差异。所以SRCNN的输入是单通道图像。
2. FSRCNN
论文出处:Accelerating the Super-Resolution Convolutional Neural Network(FSRCNN)
模型结构:
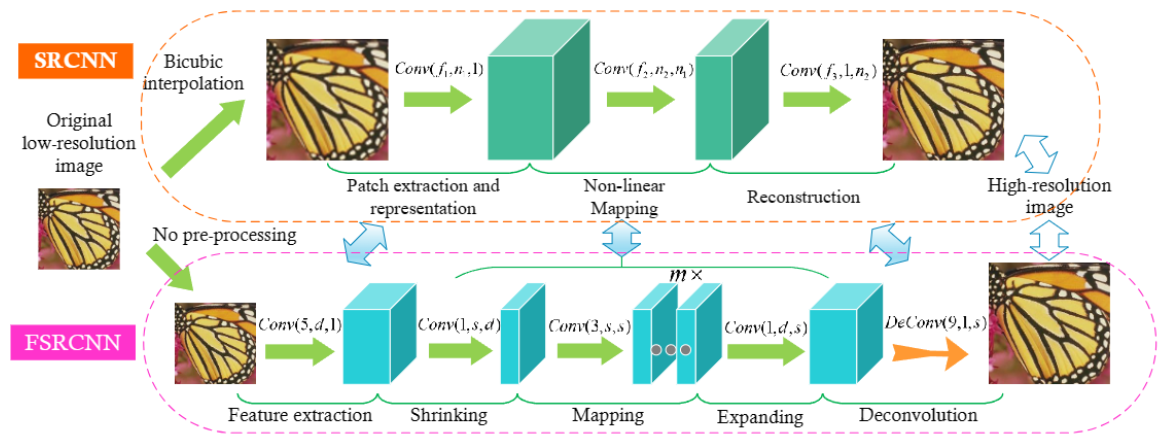
该模型的目的是为了提升SRCNN模型的速度。首先,在网络末端加入反卷积层,映射之间学习的是从原始分辨率到高分辨率图像(而不是插值);其次,改变了映射层的结构,在映射层开头和结尾各添加一个收缩层和扩展层(映射前输入维度变小);最后,卷积核变小了,映射层更多了。速度提高40倍。
模型步骤:
- 特征提取:与SRCNN第二步类似,但在输入图像上不同,FSRCNN在原始低分辨率图像上执行特征提取,无需进行插值。
- 收缩:由于从低分辨率图像提取的特征维度通常非常大,映射步骤的计算复杂度非常高,所以在特征提取层之后添加一个收缩层,以减少特征维度。
- 非线性映射:该步骤是影响SR性能的最重要部分,影响因素是映射层的宽度(即层中的过滤器数量)和深度(即层数)。
- 扩展: 扩展层就是收缩层的逆过程。如果直接从低维特征生成高分辨图像,最终的恢复质量将很差,因此在映射部分之后添加了一个扩展层来扩展特征维度。
- 反卷积:使用一组反卷积滤波器对先前的特征进行上采样和聚合。反卷积可以看作是卷积的逆运算。
模型代码实现:
class FSRCNN(nn.Module):
def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):
# d为特征维度,s为通道数,m为映射层数
super(FSRCNN, self).__init__()
# 特征提取部分
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2),
nn.PReLU(d) # 激活函数PReLU性能更加稳定
)
# 收缩层
self.mid_part = [nn.Conv2d(d, s, kernel_size=1), nn.PReLU(s)]
# m个映射层
for _ in range(m):
self.mid_part.extend([nn.Conv2d(s, s, kernel_size=3, padding=3//2), nn.PReLU(s)])
# 扩展层
self.mid_part.extend([nn.Conv2d(s, d, kernel_size=1), nn.PReLU(d)])
# 上面三个层构成中间层
self.mid_part = nn.Sequential(*self.mid_part)
# 反卷积nn.ConvTranspose2d,输入输出与特征提取层相同,output_padding防止输入输入图像大小不匹配
self.last_part = nn.ConvTranspose2d(d, num_channels, kernel_size=9, stride=scale_factor, padding=9//2,
output_padding=scale_factor-1)
self._initialize_weights()
# 初始权重都是均值为0标准差为0.001的高斯分布
def _initialize_weights(self):
for m in self.first_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
for m in self.mid_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.last_part.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.mid_part(x)
x = self.last_part(x)
return x
3. ESPCN
论文出处:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(ESPCN)
模型结构:
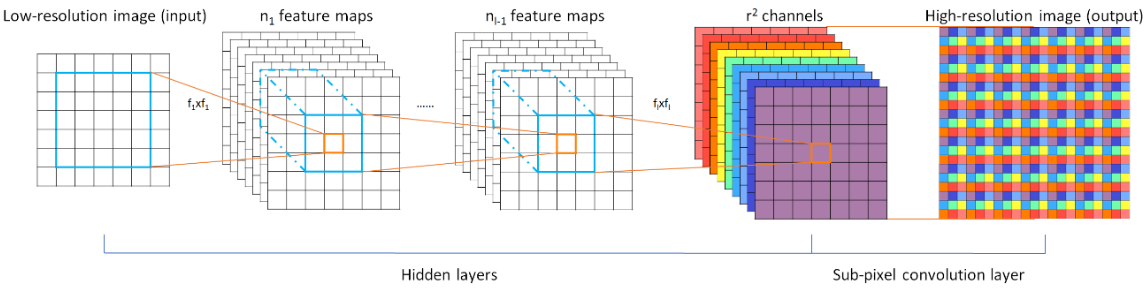
原文中作者将网络模型定义为3层,前两层为普通卷积,且都是使用低分辨率图像进行处理,这样可以使用更小的卷积核以保证信息的联系。最后的亚像素卷积层包括两个部分:卷积+像素排列。
即通过三个卷积层,得到与输入图像尺寸一致、通道数为 r 2 ^2 2 的特征图像。再将特征图像的每个像素的 r 2 ^2 2 个通道重新排列成一个 r × \times × r 的区域,对应高分辨图像中一个 r × \times × r 大小的子块,从而大小为 H × \times × W × \times × r 2 ^2 2 的特征图像被重新排列成 rH × \times × rW × \times × 1的高分辨率图像。激活函数选择的是 TanH,损失函数同样为MSE。
模型代码实现:
class ESPCN(nn.Module):
def __init__(self, upscale_factor): # upscale_factor (int): 上采样比例因子(如2, 3, 4等)
super(ESPCN, self).__init__()
# 第一层卷积:输入通道1(灰度图像),输出通道64,卷积核5x5,步长1,填充2
# 填充2是为了保持输入输出尺寸相同(当stride=1时,padding=(k-1)/2保持尺寸不变)
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
# 第二层卷积:输入通道64,输出通道32,卷积核3x3,步长1,填充1
self.conv2 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
# 第三层卷积:输入通道32,输出通道1*(upscale_factor^2),卷积核3x3,步长1,填充1
# 输出通道数为1*(上采样因子的平方),因为后面要进行pixel shuffle操作
self.conv3 = nn.Conv2d(32, 1 * (upscale_factor ** 2), (3, 3), (1, 1), (1, 1))
# Pixel Shuffle层:将通道维度的数据重新排列到空间维度,实现上采样
self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
# Tanh激活函数:将输出压缩到[-1, 1]范围
self.tanh = nn.Tanh()
def forward(self, x):
"""
前向传播过程
参数:
x (Tensor): 输入张量,形状为(batch_size, 1, H, W)
返回:
Tensor: 输出张量,形状为(batch_size, 1, H*upscale_factor, W*upscale_factor)
"""
# 第一层卷积 + Tanh激活
x = self.conv1(x)
x = self.tanh(x)
# 第二层卷积 + Tanh激活
x = self.conv2(x)
x = self.tanh(x)
# 第三层卷积(不接激活函数,因为PixelShuffle后接Tanh)
x = self.conv3(x)
# Pixel Shuffle上采样操作
x = self.pixel_shuffle(x)
# 最终Tanh激活(有些实现可能使用其他激活函数或不加)
x = self.tanh(x)
return x
4. VDSR
论文出处:Accurate Image Super-Resolution Using Very Deep Convolutional Networks (VDSR)
VDSR与SRCNN的比较:
VDSR提出的起源主要是由于SRCNN的局限性,主要表现在以下三个方面:1. 依赖于低分辨率图像的上下文信息;2. 训练收敛慢;3. 网络只适用于单个尺度因子。
VDSR对其进行的改进如下:1. 增大了网络的感受野,将SRCNN的感受野由13 × \times × 13增加到VDSR的41 × \times × 41,充分利用了非常大的图像区域的上下文信息;2. 使用了残差学习和极高的学习率,加速了网络的训练;3. 单一的网络有效的处理多尺度的SR问题。
极高的学习率可以促进训练,但简单地将学习率设置的很高也会导致梯度消失/爆炸,该论文通过可调的梯度裁剪,以最大限度地提高速度,同时抑制梯度爆炸。
模型结构:
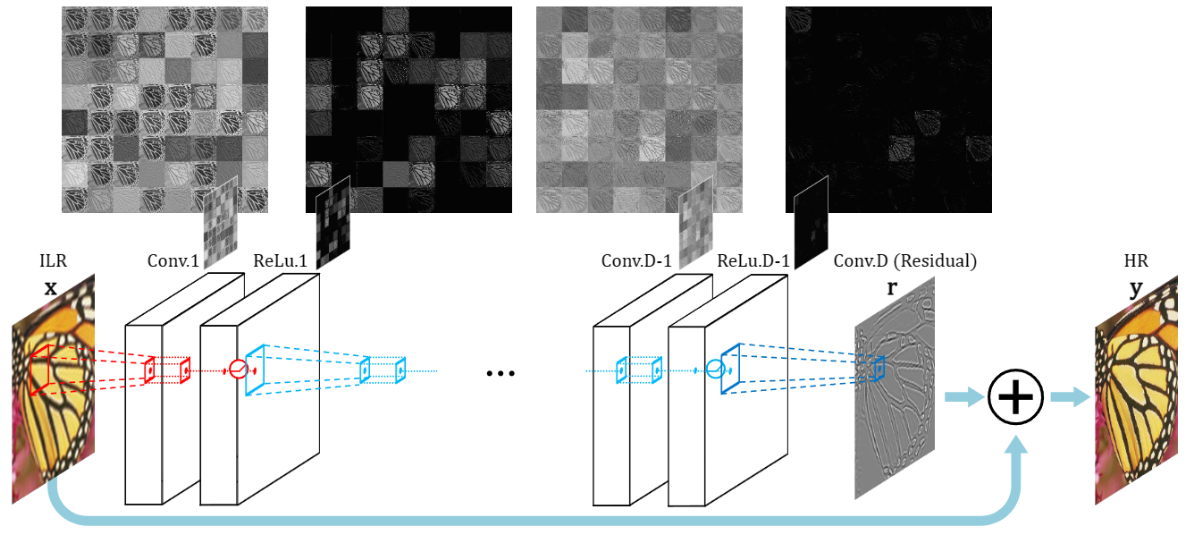
除了第一层用于输入,最后一层用于上采样为高分辨率图像,中间是d层3 × \times × 3大小的64通道卷积层,每个卷积层后跟Relu激活函数。卷积层中最后一层预测残差图像,与输入的低分辨率图像相加得到输出高分辨率图像。由于卷积后特征图会变小,为了保留边界像素信息,卷积前采用零填充的方法,效果非常好。
简单补充一下残差连接:残差连接(Residual Connection)是一种常用于深度学习模型中的技术,旨在帮助解决随着网络深度增加而出现的梯度消失或梯度爆炸问题。残差连接的核心思想是在网络的一层或多层之间引入直接连接,使得这些层的输出不仅包括经过非线性变换的特征,还包括未经处理的输入特征。这样做的目的是允许网络学习到的是输入和输出之间的残差(即差异),而不是直接学习一个完整的映射。这种方式有助于梯度在训练过程中更有效地回流,减轻深度网络中梯度消失的问题。具体链接 残差连接理解
模型代码实现:
class Conv_ReLU_Block(nn.Module):
"""
卷积 + ReLU激活块
包含一个卷积层和一个ReLU激活函数
"""
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
# 卷积层:输入64通道,输出64通道,3x3卷积核,步长1,填充1,无偏置
self.conv = nn.Conv2d(in_channels=64, out_channels=64,
kernel_size=3, stride=1, padding=1, bias=False)
# ReLU激活函数(inplace=True表示直接修改输入,节省内存)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
"""前向传播:卷积 + ReLU激活"""
return self.relu(self.conv(x))
class Net(nn.Module):
"""
一个基于残差学习的深度卷积神经网络
包含输入层、多个残差块和输出层
"""
def __init__(self):
super(Net, self).__init__()
# 创建由18个Conv_ReLU_Block组成的残差层
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
# 输入层:1通道输入转为64通道输出
self.input = nn.Conv2d(in_channels=1, out_channels=64,
kernel_size=3, stride=1, padding=1, bias=False)
# 输出层:64通道输入转为1通道输出
self.output = nn.Conv2d(in_channels=64, out_channels=1,
kernel_size=3, stride=1, padding=1, bias=False)
# ReLU激活函数(用于输入层后的激活)
self.relu = nn.ReLU(inplace=True)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 计算卷积核参数数量:kernel_size[0]*kernel_size[1]*out_channels
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# 使用He初始化(针对ReLU的改进初始化方法)
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
"""
创建由多个相同块组成的层
参数:
block: 要重复的模块类
num_of_layer: 重复次数
返回:
nn.Sequential: 包含多个块的序列
"""
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
"""
前向传播过程
参数:
x (Tensor): 输入张量,形状为(batch_size, 1, H, W)
返回:
Tensor: 输出张量,形状与输入相同(batch_size, 1, H, W)
"""
# 保存残差连接(输入)
residual = x
# 输入处理:卷积 + ReLU激活
out = self.relu(self.input(x))
# 通过残差层
out = self.residual_layer(out)
# 输出处理:卷积(无激活函数)
out = self.output(out)
# 残差连接:将原始输入加到输出上
out = torch.add(out, residual)
return out
5. DRCN
论文出处:Deeply-Recursive Convolutional Network for Image Super-Resolution (DRCN)
模型结构:
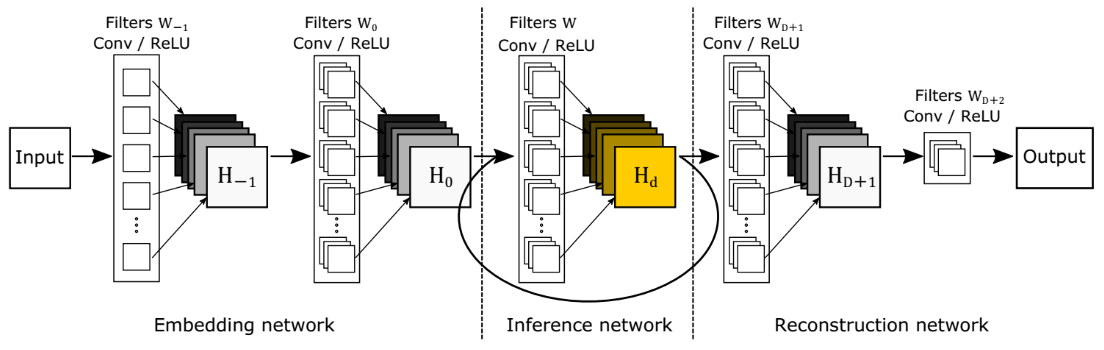
模型由3个子网络组成:嵌入、推理和重建网络。
模型步骤:
- 嵌入网络:嵌入网络获取输入图像(灰度或 RGB),并将其表示为一组特征图。用于传递信息到推理网络的中间表示在很大程度上取决于推理网络在其隐藏层内部如何表示其特征图。学习这种表示是端到端学习其他子网络来完成的。
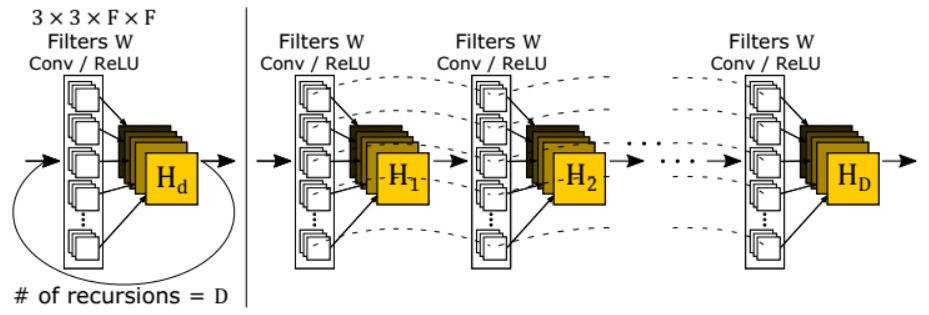
- 推理网络:推理网络是解决超分辨率任务的主要组成部分。分析大型图像区域由单个递归层完成。每个递归应用相同的卷积,后跟一个整流线性单元(如下图)。使用大于1 × \times × 1的卷积滤波器,每个递归都扩大了感受野。
- 重建网络:虽然递归层最终应用的特征图代表高分辨率图像,但有必要将它们(多通道)转换回原始图像空间(1或3通道)。这是通过重建网络完成的。
6. DRRN
论文出处:Image Super-Resolution via Deep Recursive Residual Network (DRRN)
模型结构:
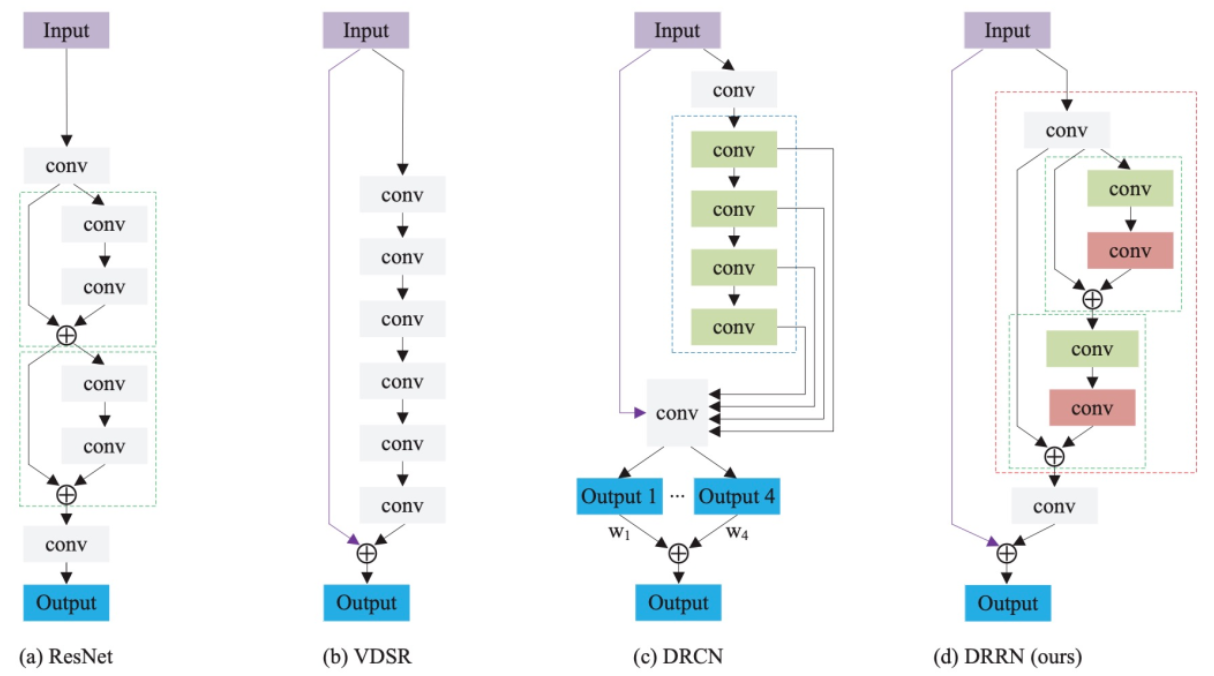
这里为了清楚省略了激活函数、批量归一化(BN)和ReLU。ResNet+VDSR+DRCN+改进思路=DRRN
DRRN算法有两个主要的算法新颖性:
- DRRN中引入了全局和局部残差学习。在VDSR和DRCN中,残差图像是从网络的输入和输出估计的,称为全局残差学习(GRL)。此外,引入了一种增强的残差单元结构,称为多路径模式局部残差学习(LRL),其中身份分支不仅对后期层携带丰富的图像细节,而且有助于梯度流。GRL和LRL的主要区别在于LRL是在每隔几个堆叠的层中执行的,而GRL在输入和输出图像之间执行,即DRRN有许多LRL,只有1个GRL。简单来说,GRL缓解学习难度,LRL丰富图像细节。
- DRRN中提出了残差单元的递归学习,以保持模型紧凑。与DRCN有两个主要的区别:1. DRCN在卷积层之间共享权重,而DRRN则在残差单元之间共享权重;2. 为了解决非常深的模型的消失/爆炸梯度问题,DRCN监督每个递归,DRRN则通过设计具有多路径结构的递归块来减轻这种负担。通过递归学习,DRRN可以通过增加深度而不添加任何权重参数来提高准确性。
模型代码实现:
class DRRN(nn.Module):
def __init__(self):
super(DRRN, self).__init__()
# 输入层: 1通道(灰度图) -> 128通道
self.input = nn.Conv2d(in_channels=1, out_channels=128,
kernel_size=3, stride=1, padding=1, bias=False)
# 两个连续的卷积层,用于特征提取
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128,
kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128,
kernel_size=3, stride=1, padding=1, bias=False)
# 输出层: 128通道 -> 1通道(重建图像)
self.output = nn.Conv2d(in_channels=128, out_channels=1,
kernel_size=3, stride=1, padding=1, bias=False)
# ReLU激活函数(inplace=True节省内存)
self.relu = nn.ReLU(inplace=True)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 计算fan_in(输入神经元数量)
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
# 使用He初始化(针对ReLU)
m.weight.data.normal_(0, sqrt(2. / n))
def forward(self, x):
# 保存输入图像作为残差连接
residual = x
# 初始特征提取
inputs = self.input(self.relu(x)) # 输入层 + ReLU
out = inputs
# 递归块: 重复25次相同的操作(权重共享)
for _ in range(25):
# 每个递归单元包含: ReLU -> conv1 -> ReLU -> conv2
# 然后与初始特征(inputs)进行残差连接
out = self.conv2(self.relu(self.conv1(self.relu(out))))
out = torch.add(out, inputs) # 残差连接
# 输出层处理
out = self.output(self.relu(out))
# 最终残差连接: 输出 + 原始输入
out = torch.add(out, residual)
return out
25个残差块,1个递归块,卷积核均为3 × \times × 3,数量为128。激活函数都为ReLU。因为要实现多路残差块,所以在前向传播的时候用循环形式表示多路进程。权重初始化使用He等人的方法适配ReLU,即标准差为sqrt(2/n)的高斯分布。
7. EDSR
论文出处:Enhanced Deep Residual Networks for Single Image Super-Resolution(EDSR)
改进残差块:
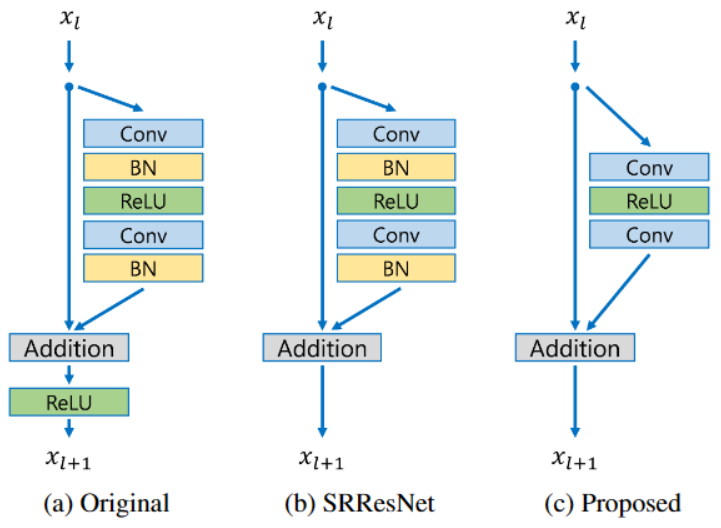
本文方法删除了BN层,性能更好,显存使用更少。至于为什么删除BN层,作者说的比较模糊。除了实验能证明效果好了之外,超分问题没有必要特征归一化(归一化限制了网络的灵活性)。其他视觉任务可能归一化效果更好,但是超分是病态问题。作者想表达的可能是这个意思。
模型结构:
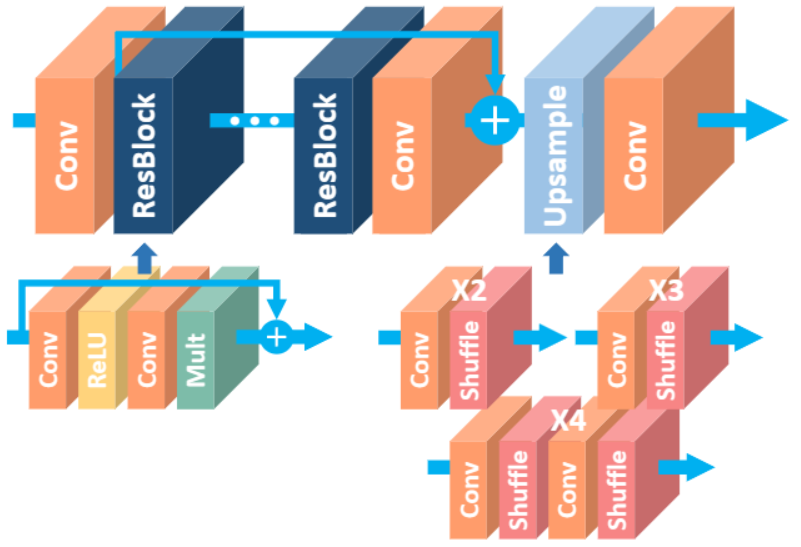
模型代码实现:
残差块结构:Conv — ReLU — Conv
根据论文所述,EDSR的残差块32个,通道数为256,缩放因子为0.1
EDSR网络结构:输入 — Conv — 32个残差块 — Conv — add操作 — 上采样(x2、x3和x4有区别,分别为 Conv — Shuffle 和 Conv — Shuffle — Conv — Shuffle) — Conv — 输出
# 图像均值偏移类,用于预处理和后处理
class MeanShift(nn.Conv2d):
"""
实现图像通道均值的加减操作
参数:
rgb_mean: RGB三通道的均值
sign: 1表示加均值(后处理), -1表示减均值(预处理)
"""
def __init__(self, rgb_mean, sign):
super(MeanShift, self).__init__(3, 3, kernel_size=1) # 1x1卷积实现通道操作
# 初始化权重为单位矩阵(保持通道不变)
self.weight.data = torch.eye(3).view(3, 3, 1, 1)
# 设置偏置为带符号的通道均值
self.bias.data = float(sign) * torch.Tensor(rgb_mean)
# 冻结该层参数(不参与训练)
for params in self.parameters():
params.requires_grad = False
# 残差块定义
class _Residual_Block(nn.Module):
"""
结构: Conv(256)->ReLU->Conv(256) + 输入(残差连接)
F=256表示特征通道数
"""
def __init__(self):
super(_Residual_Block, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True) # ReLU激活
# 第二个卷积层
self.conv2 = nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False)
def forward(self, x):
identity_data = x # 保存输入用于残差连接
output = self.relu(self.conv1(x)) # 第一层卷积+ReLU
output = self.conv2(output) # 第二层卷积
output *= 0.1 # 论文提到的缩放因子(0.1)
output = torch.add(output, identity_data) # 残差连接
return output
# 主网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# DIV2K数据集的RGB均值(可能需要根据实际数据集调整)
rgb_mean = (0.4488, 0.4371, 0.4040)
# 预处理: 减去通道均值
self.sub_mean = MeanShift(rgb_mean, -1)
# 输入卷积层: 3通道(RGB) -> 256通道
self.conv_input = nn.Conv2d(in_channels=3, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False)
# 构建32个残差块组成的层
self.residual = self.make_layer(_Residual_Block, 32) # B = 32
# 中间卷积层
self.conv_mid = nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False)
# 4倍上采样模块(根据论文图3)
# 使用PixelShuffle实现上采样
self.upscale4x = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256*4, # 输出通道数=256*4
kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2), # 上采样2倍
nn.Conv2d(in_channels=256, out_channels=256*4,
kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2), # 再次上采样2倍(总计4倍)
)
# 输出卷积层: 256通道 -> 3通道(RGB)
self.conv_output = nn.Conv2d(in_channels=256, out_channels=3,
kernel_size=3, stride=1, padding=1, bias=False)
# 后处理: 加回通道均值
self.add_mean = MeanShift(rgb_mean, 1)
# 参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
# He初始化(针对ReLU)
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
# BN层初始化: 权重=1, 偏置=0
m.weight.data.fill_(1)
if m.bias is not None:
m.bias.data.zero_()
# 构建相同层的辅助函数
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
# 前向传播
def forward(self, x):
# 预处理: 减去通道均值
out = self.sub_mean(x)
# 初始特征提取
out = self.conv_input(out)
# 保存残差
residual = out
# 通过残差块
out = self.conv_mid(self.residual(out))
# 残差连接
out = torch.add(out, residual)
# 4倍上采样
out = self.upscale4x(out)
# 输出卷积
out = self.conv_output(out)
# 后处理: 加回通道均值
out = self.add_mean(out)
return out
8. MDSR
与EDSR出自同一篇论文,是论文作者根据EDSR提出的一种新的多尺度深度超分辨率方法,这边不再详细解释,只给出该模型结构: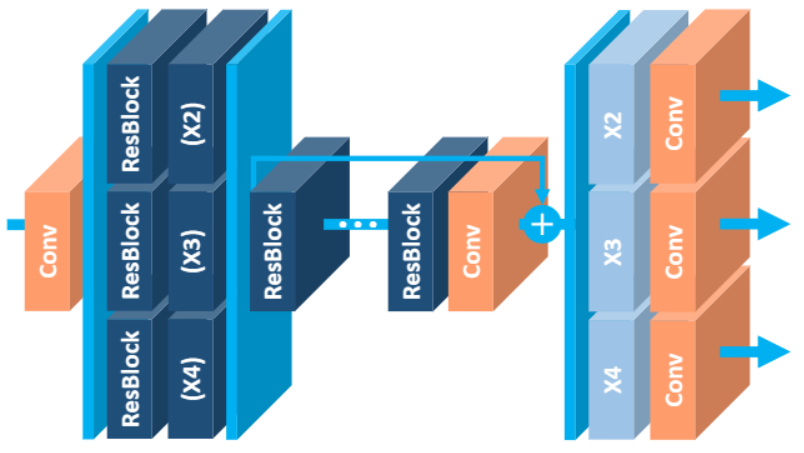

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)