计算机体系结构——流水线及流水线中的冲突
发生了RAW(先写后读)冲突的周期:4、6、7、9、10、13、14、17、18、20、21、25、26、28、29、32、33、36、37、39、40、44、45、47、48、51、52、55、56、58、59。),然后分别以单步执行一个周期、执行多个周期、连续执行、设置断点等的方式运行程序,观察程序的执行情况,观察CPU中寄存器和存储器的内容的变化,特别是流水寄存器内容的变化。(5)记录数据冲
A.2.1 实验目的
- 加深对计算机流水线基本概念的理解。
- 理解MIPS结构如何用5段流水线来实现,理解各段的功能和基本操作。
- 加深对数据冲突、结构冲突的理解,理解这两类冲突对CPU性能的影响。
- 进一步理解解决数据冲突的方法,掌握如何应用定向技术来减少数据冲突引起的停顿。
A.2.2 实验平台
实验平台采用指令级和流水线操作级模拟器MIPSsim。
A.2.3 实验内容和步骤
首先要掌握MIPSsim模拟器的使用方法。详见附录B。
1. 启动MIPSsim。
2.根据预备知识中关于流水线各段操作的描述,进一步理解流水线窗口中各段的功能,掌握各流水寄存器的含义。(用鼠标双击各段,就可以看到各流水寄存器的内容)
3. 熟悉MIPSsim模拟器的操作和使用方法。
可以先载入一个样例程序(在本模拟器所在的文件夹下的“样例程序”文件夹中),然后分别以单步执行一个周期、执行多个周期、连续执行、设置断点等的方式运行程序,观察程序的执行情况,观察CPU中寄存器和存储器的内容的变化,特别是流水寄存器内容的变化。
4. 选择配置菜单中的“流水方式”,使模拟器工作于流水方式下。
5.观察程序在流水线中的执行情况,步骤如下:
(1)选择MIPSsim的“文件”→“载入程序”选项来加载pipeline.s(在模拟器所在文件夹下的“样例程序”文件夹中)。
(2)关闭定向功能。这是通过在“配置”→“定向”(使该项前面没有“√”号)来实现的。
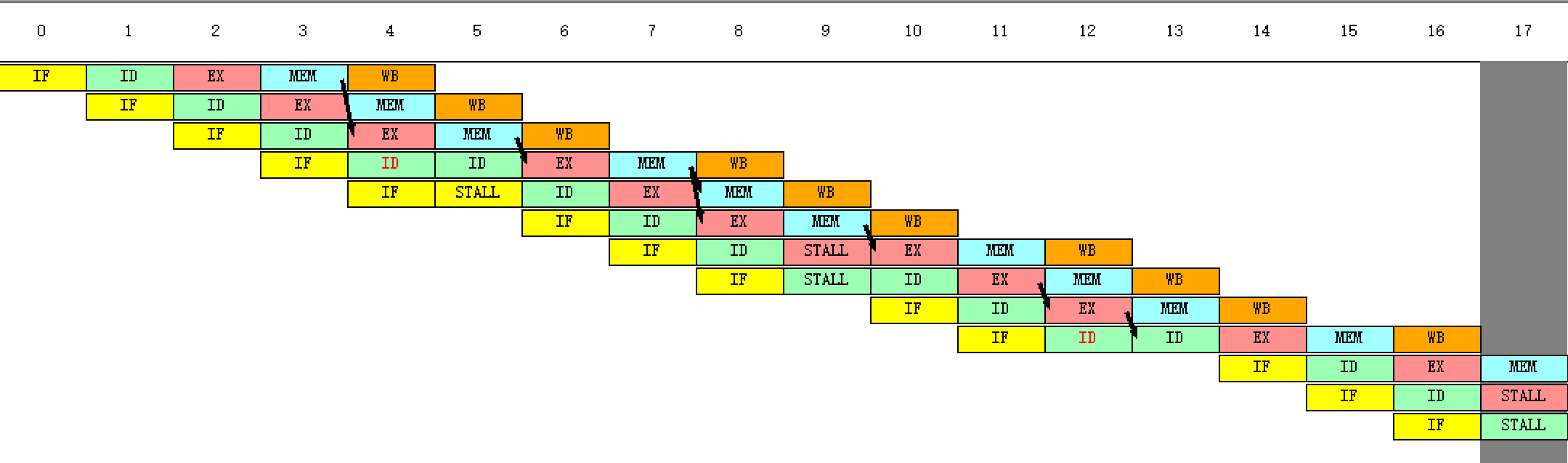
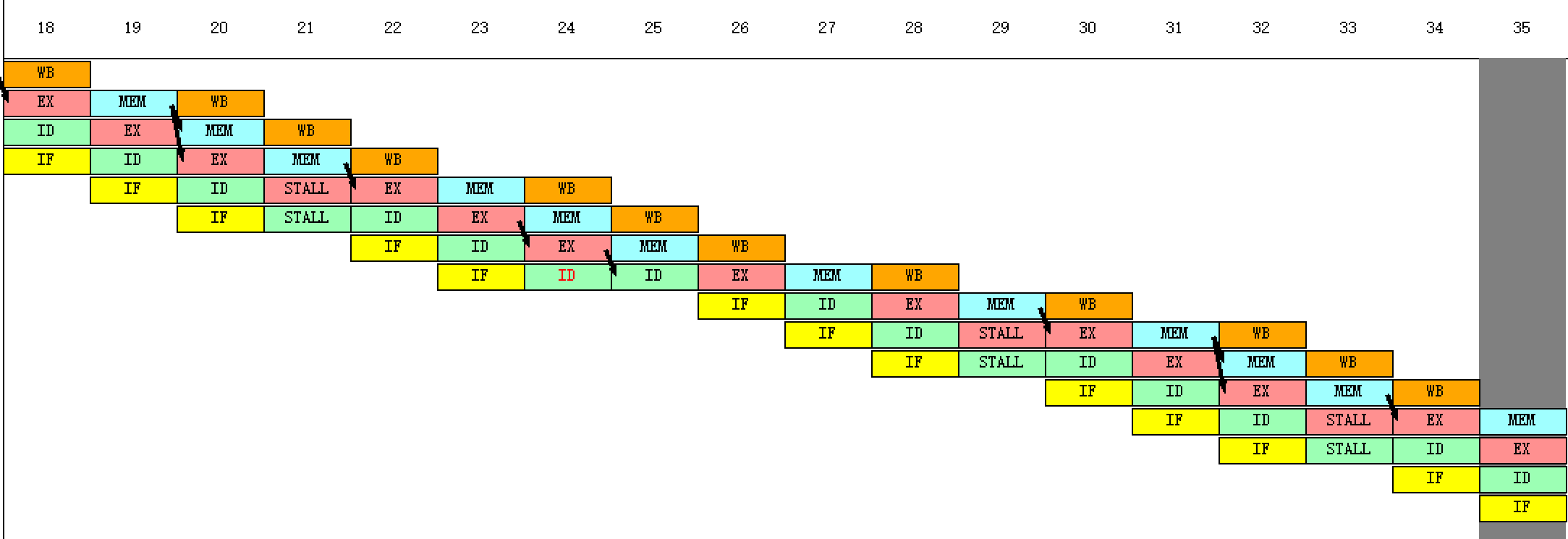
(3)用单步执行一周期的方式(“执行”菜单中)或用F7执行该程序,观察每一周期中,各段流水寄存器内容的变化、指令的执行情况(“代码”窗口)以及时钟周期图。
(4)当执行到第13个时钟周期时,各段分别正在处理的指令是:
(解释每条指令的含义)
IF: SUB $r5,$r4,$r3
从寄存器$r4的值中减去寄存器$r3的值,并将结果存储在寄存器$r5中
ID: ADDI $r3,$r3,4
将寄存器r3的值与立即数4相加,并将结果存回寄存器r3中
EX: ADDI $r2,$r2,4
将寄存器r2的值与立即数4相加,并将结果存回寄存器r2中
MEM: SW $r1,0($r2)
将寄存器$r1中的数据存储到由寄存器$r2指定的内存地址(偏移量为0)中
WB:
画出这时的时钟周期图。(解释插入几个暂停的原因)
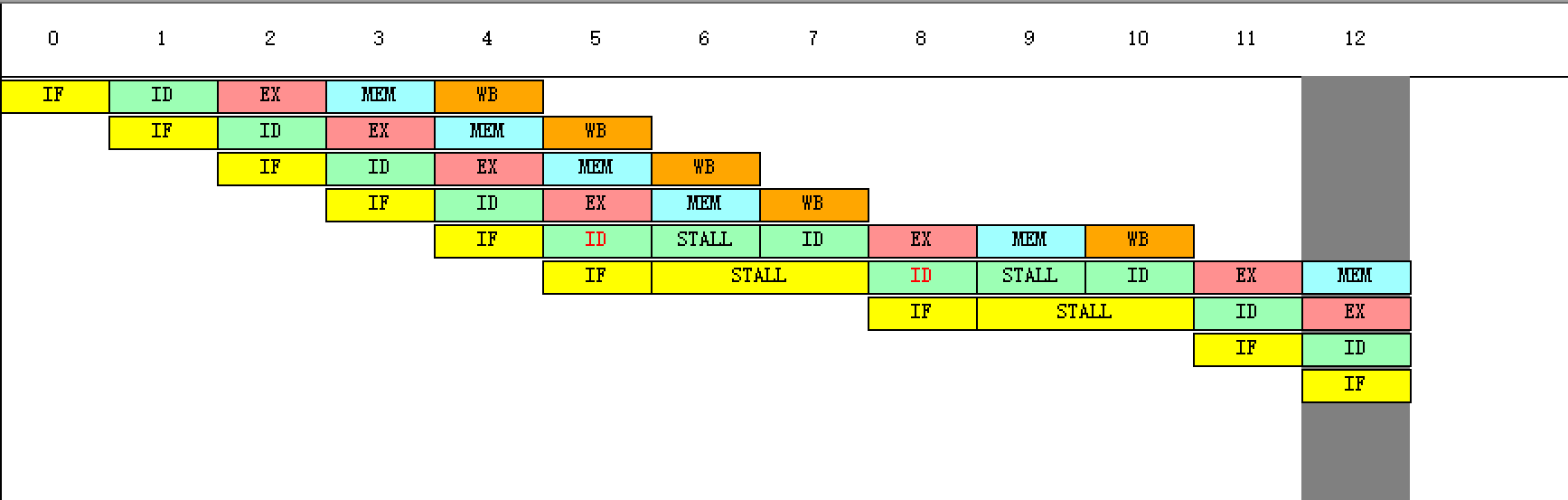
第6个周期ID的暂停:读后写冲突,读取r1的数据与r1的值和1相加冲突
第6个周期IF的暂停:读后写冲突,读取r1的数据与把r2的数据保存到r1冲突
第7个周期IF的暂停:写后写冲突,把r2的数据保存到r1与r1的值和1相加冲突
第9个周期ID的暂停:写后写冲突,把r2的数据保存到r1与r1的值和1相加冲突
第9个周期IF的暂停:写后写冲突,r2的值和4相加与把r2的数据保存到r1冲突
第10个周期IF的暂停:写后写冲突,r2的值和4相加与把r2的数据保存到r1冲突
6. 这时各流水寄存器中的内容为:
(解释下面几个流水寄存器的含义)
IF/ID.IR: 0x00832822
取指阶段/指令译码阶段的指令寄存器,存放当前指令的地址
IF/ID.NPC: 0x00000024
取指阶段/指令译码阶段的下一条程序计数器,存放下一条指令的地址
ID/EX.A: 0x0000000000000000
指令译码阶段/执行阶段的第一操作数寄存器,存放从通用寄存器读出来的操作数
ID/EX.B: 0x0000000000000001
指令译码阶段/执行阶段的第二操作数寄存器,存放从通用寄存器读出来的另一个操作数
ID/EX.Imm: 0x0000000000000004
指令译码阶段/执行阶段的存放符号扩展后的立即数操作数的寄存器
ID/EX.IR: 0x20630004
指令译码阶段/执行阶段的指令寄存器,存放当前指令的地址
EX/MEM.ALUo: 0x0000000000000068
执行阶段/存储器访问阶段的存放ALU的运算结果的寄存器
EX/MEM.IR: 0x20420004
执行阶段/存储器访问阶段的指令寄存器,存放当前指令的地址
MEM/WB.LMD: 0x0000000000000000
存储器访问阶段/写回阶段的存放load指令从存储器读出的数据的寄存器
MEM/WB.ALUo: 0x0000000000000064
存储器访问阶段/写回阶段的存放ALU的运算结果的寄存器
MEM/WB.IR: 0x20420004
存储器访问阶段/写回阶段的指令寄存器,存放当前指令的地址
7. 观察和分析结构冲突对CPU性能的影响,步骤如下:
(1)加载structure_hz.s(在模拟器所在文件夹下的“样例程序”文件夹中)。
(2)执行该程序,找出存在结构冲突的指令对以及导致结构冲突的部件。(写出存在结构冲突的指令并画出流水线的时空图)



存在结构冲突的指令是:fadd
导致结构冲突的部件是:浮点加法器
(3) 记录由结构冲突引起的停顿时钟周期数,计算停顿时钟周期数占总执行周期数的百分比;
总周期数52个,结构停顿周期数35个,占总执行周期数的67.30769%

(4)把浮点加法器的个数改为4个。
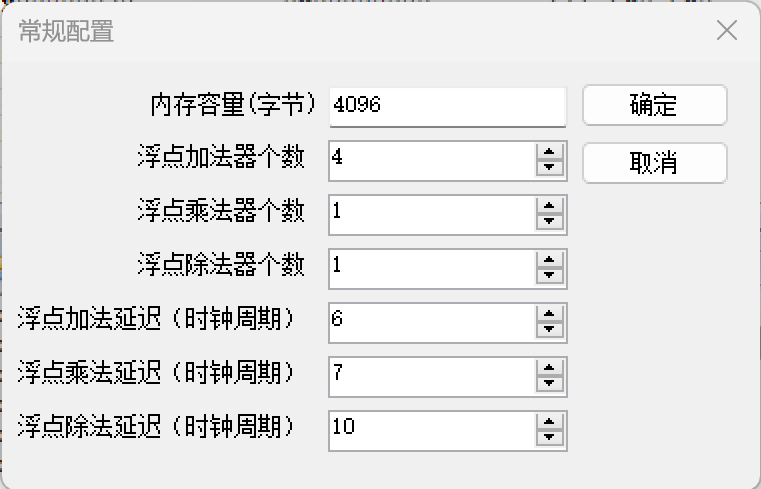 (5)再次重复上述(1)~(3)的工作。(画出改进后的流水线的时空图)
(5)再次重复上述(1)~(3)的工作。(画出改进后的流水线的时空图)
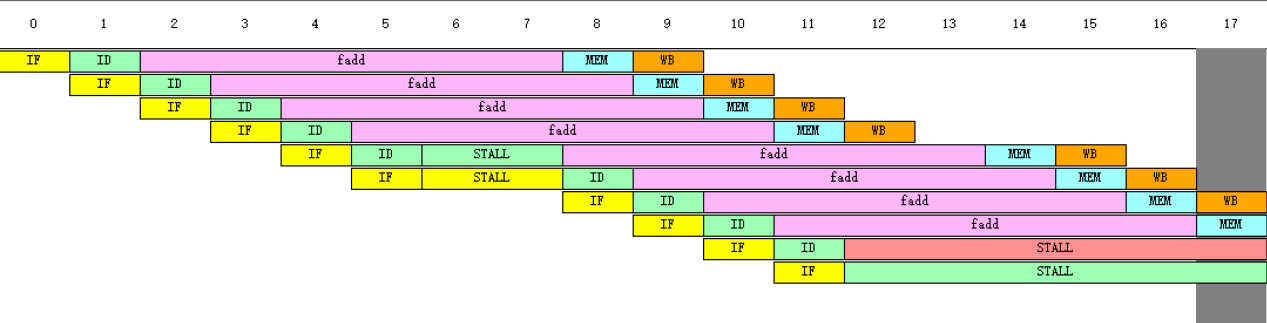

(6)分析结构冲突对CPU性能的影响,讨论解决结构冲突的方法。
结构冲突是指在CPU的指令执行过程中,由于有多个指令需要使用同一种硬件资源,导致某些指令无法按照预期时间执行,从而影响CPU的性能表现。结构冲突对CPU性能的影响可以表现为指令的延迟执行,执行时间变长等,这些都会导致CPU的时钟周期不能充分利用,从而降低CPU的性能表现。
解决结构冲突的方法:
1.提高CPU的运算速度和带宽,这样可以提升硬件资源的处理能力,从而降低结构冲突的发生率。
2.采用超标量技术,即在CPU内部增加多个硬件执行单元,这样可以使得多条指令可以同时执行,从而避免结构冲突的发生。
3.采用指令重排技术,即在编译器层面对指令进行重排,使得需要使用同一种硬件资源的指令不会同时出现在执行流水线上,从而避免结构冲突的发生。
4.采用分支预测技术,即在CPU内部对分支指令进行预测,提前加载分支指令的执行流水线,从而避免因分支指令的延迟执行而导致的结构冲突。
8. 观察数据冲突并用定向技术来减少停顿,步骤如下:
(1)全部复位。
(2)加载data_hz.s(在模拟器所在文件夹下的“样例程序”文件夹中)。
(3)关闭定向功能。这是通过在“配置”→“定向”(使该项前面没有“√”号)来实现的。
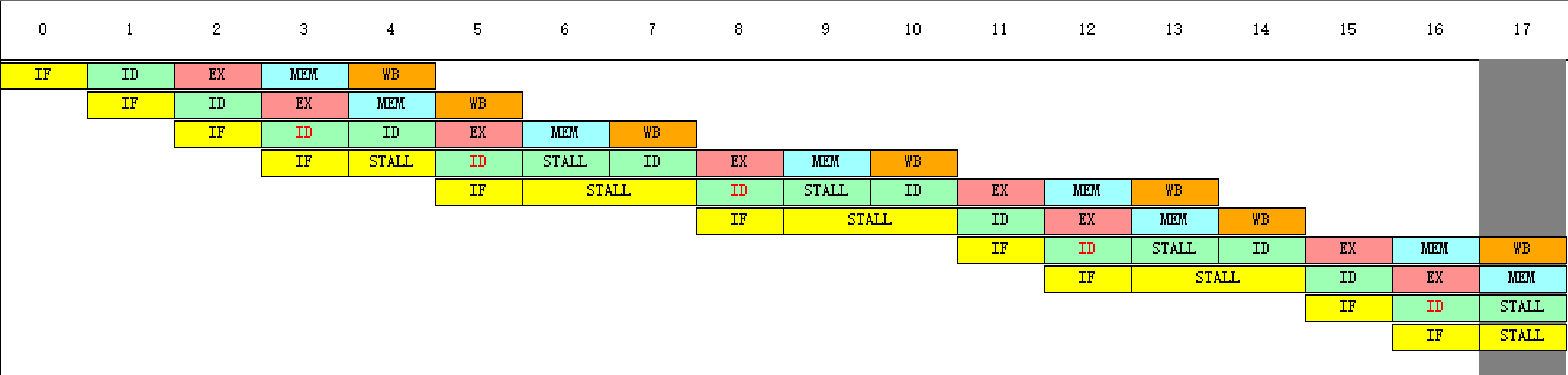
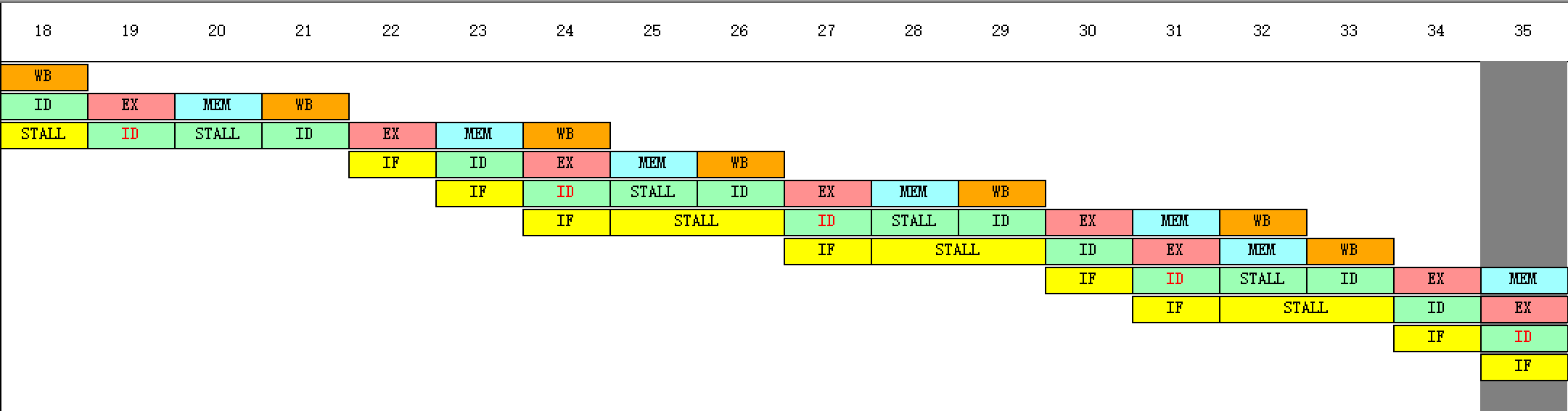
(4)用单步执行一个周期的方式(F7)执行该程序,同时查看时钟周期图,列出在什么时刻发生了RAW(先写后读)冲突。(解释前8条指令之间存在的相关性,画出流水线的时空图,解释其中暂停的含义)
发生了RAW(先写后读)冲突的周期:4、6、7、9、10、13、14、17、18、20、21、25、26、28、29、32、33、36、37、39、40、44、45、47、48、51、52、55、56、58、59

ADDIU $r2,$r0,56
ADDIU $r3,$r0,68
LW $r1,0($r2)
ADD $r1,$r1,$r3
SW $r1,0($r2)
LW $r5,0($r1)
ADDI $r5,$r5,10
ADDI $r2,$r2,4
指令1与指令2 名相关
指令3与指令4 数据相关
指令4与指令5 数据相关
指令5与指令6 数据相关
指令6与指令7 数据相关
第4个周期IF的暂停:读后写冲突,r3的值和r1的值相加与r0的值和68相加存到r3冲突
第6个周期ID的暂停:写后读冲突,r3的值和r1的值相加与把读r2的数据保存到r1冲突
第6个周期IF的暂停:写后读冲突,写r2的数据保存到r1与读r2的数据保存到r1冲突
第7个周期IF的暂停:写后写冲突,写r2的数据保存到r1与r3的值和r1的值相加冲突
第9个周期ID的暂停:写后写冲突,写r2的数据保存到r1与r3的值和r1的值相加冲突
第9个周期IF的暂停:读后写冲突,读r1的数据保存到r5与r3的值和r1的值相加冲突
第10个周期IF的暂停:读后写冲突,读r1的数据保存到r5与写r2的数据保存到r1冲突
第13个周期ID的暂停:写后读冲突,r5的值和10相加存到r5与读r1的数据保存到r5冲突
第13个周期IF的暂停:写后读冲突,r3的值和4相加存到r2与写r2的数据保存到r1冲突
第17个周期ID的暂停:读后写冲突,r3的值减r2的值存到r4与r2的值和4相加存到r2冲突
第17个周期IF的暂停:读后写冲突,判断r4是否大于0与r2的值和4相加存到r2冲突
第18个周期IF的暂停:读后写冲突,判断r4是否大于0与r3的值减r2的值存到r4冲突
(5)记录数据冲突引起的停顿时钟周期数以及程序执行的总时钟周期数,计算停顿时钟周期数占总执行周期数的百分比。
总周期数65个,结构停顿周期数31个,占总执行周期数的47.69231%

(6)复位CPU。
(7)打开定向功能。这是通过在“配置”→“定向”(使该项前面有一个“√”号)来实现的。
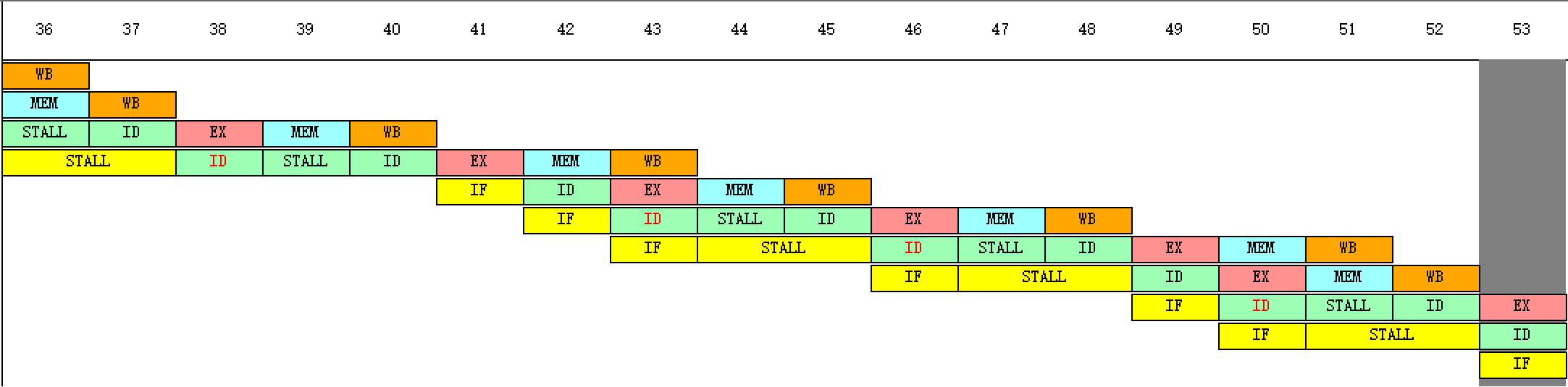
(8)用单步执行一周期的方式(F7)执行该程序,同时查看时钟周期图,列出在什么时刻发生了RAW(先写后读)冲突,并与(3)的结果进行比较;
发生了RAW(先写后读)冲突的周期:5、10、13、18、22、25、30、34、37

(9)记录数据冲突引起的停顿时钟周期数以及程序执行的总时钟周期数。计算采用定
(10)向技术后性能提高的倍数。
数据冲突引起的停顿时钟周期数:31/9=3.44倍
程序执行的总时钟周期数:65/43=1.51倍

总结:
1.加深了对流水线技术的理解:通过本次实验,加深了对计算机流水线基本概念的理解,特别是MIPS五段流水线的实现和各段的功能及基本操作。
2.掌握了解决数据冲突的方法:掌握了定向技术等解决数据冲突的方法,并理解了它们对减少流水线停顿、提高处理器性能的重要性。
3.对CPU性能优化的思考:实验中观察到了数据冲突和资源冲突对CPU性能的影响,这促使我思考如何通过优化指令调度、增加硬件资源等方法来进一步提高CPU的性能。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)