[TCG] 01.QEMU TCG 概览
QEMU TCG 概览
目录
2.5.当前正在翻译的指令块 - DisasContextBase
3.2.开发板创建时绑定 TCG 加速器 - tcg_init_machine()
3.4.内存页初始化 - tcg_region_init()
3.5.翻译准备 - tcg_prologue_init()
4.1.TCG 线程启动 - mttcg_cpu_thread_fn()
4.2.虚拟 CPU 运行 - cpu_exec_loop()
4.2.2.指令翻译 - translator_loop() & disas_insn()
1.基本概念
QEMU 作为设备模拟器可以模拟多种处理器架构,待模拟的架构称为 Target,QEMU 运行的系统环境称为 Host
QEMU 的 TCG (Tiny Code Generator) 模块负责将 Target Code 动态的翻译为 Host Code,即 TCG Target,因此,将在模拟处理器上运行的代码(如 RISC-V 指令)称为 Guest Code
TCG 提取 Guest Code (例如 RISC-V 指令) 并将其转换为 Host Code(例如 x86 指令),如下图所示:
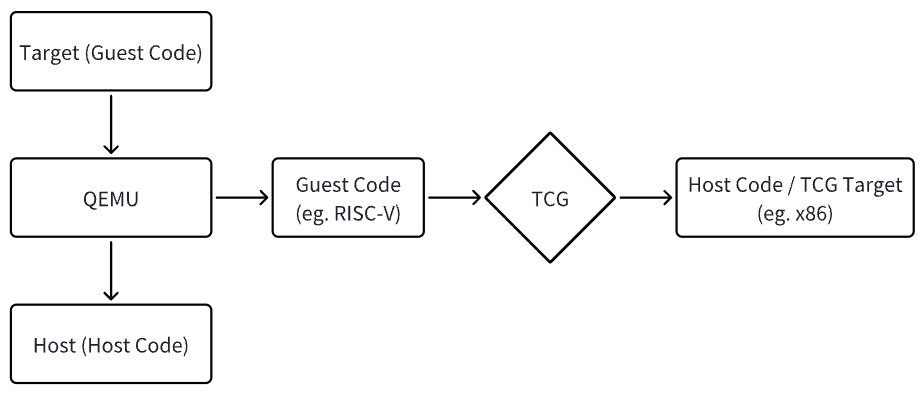
TCG 使用基本块 Translation Block (TB) 作为翻译单元,缓存翻译和优化的结果,再次执行该基本块时就可以直接执行对应缓存中的代码
基本块是以控制转移指令结尾的指令序列,是只有一个入口和一个出口的程序段
相较于以单条指令为单位的翻译,选择基本块作为翻译单元,可以节省很多有关翻译块调用的操作,同时可以充分挖掘基本块内指令的并行性,给动态翻译提供更多的优化空间
QEMU 提取 Guest Code 后,TCG 将其转换为 Host Code,TCG 的整个转换过程由两部分组成:
-
第一部分由前端完成,Target Code 的代码块 TB 被转换成 TinyCode(独立于机器的中间代码 IR);
-
第二部分由后端完成,利用 Host 架构对应的 TCG,将由 TB 生成的 TinyCode 转换成 Host Code;
注意事项
-
TCG 翻译的目标架构是 Host,因此 TCG Target 表示的是 Host 架构,而不是待模拟的架构;
-
Guest Code 中的 Code,虽然含义是代码但其真正表示的是指令,使用 Guest Instruction 更贴切,需要区分;
-
基本块指 Target 中以分支指令为结尾的指令序列,翻译块(Translation Block)为基本块翻译为 Host 架构后的一段指令;
中间码 IR 不仅定义了对应的指令,也定义了寄存器,从而形成一个独立的逻辑空间,在 IR 转换这一层可以认为所有的操作都是在相关寄存器上进行指令的转换
2.基本数据结构
2.1.指令缓冲区 - TranslationBlock
Guest Code 翻译为 Host Code 的缓冲区 Buffer,用于保存当前翻译的指令、CPU 状态等信息
// include/exec/translation-block.h
struct TranslationBlock {
/*
* Guest PC corresponding to this block. This must be the true
* virtual address. Therefore e.g. x86 stores EIP + CS_BASE, and
* targets like Arm, MIPS, HP-PA, which reuse low bits for ISA or
* privilege, must store those bits elsewhere.
*
* If CF_PCREL, the opcodes for the TranslationBlock are written
* such that the TB is associated only with the physical page and
* may be run in any virtual address context. In this case, PC
* must always be taken from ENV in a target-specific manner.
* Unwind information is taken as offsets from the page, to be
* deposited into the "current" PC.
*/
vaddr pc;
/*
* Target-specific data associated with the TranslationBlock, e.g.:
* x86: the original user, the Code Segment virtual base,
* arm: an extension of tb->flags,
* s390x: instruction data for EXECUTE,
* sparc: the next pc of the instruction queue (for delay slots).
*/
uint64_t cs_base;
uint32_t flags; /* flags defining in which context the code was generated */
uint32_t cflags; /* compile flags */
/* Note that TCG_MAX_INSNS is 512; we validate this match elsewhere. */
#define CF_COUNT_MASK 0x000001ff
#define CF_NO_GOTO_TB 0x00000200 /* Do not chain with goto_tb */
#define CF_NO_GOTO_PTR 0x00000400 /* Do not chain with goto_ptr */
#define CF_SINGLE_STEP 0x00000800 /* gdbstub single-step in effect */
#define CF_MEMI_ONLY 0x00001000 /* Only instrument memory ops */
#define CF_USE_ICOUNT 0x00002000
#define CF_INVALID 0x00004000 /* TB is stale. Set with @jmp_lock held */
#define CF_PARALLEL 0x00008000 /* Generate code for a parallel context */
#define CF_NOIRQ 0x00010000 /* Generate an uninterruptible TB */
#define CF_PCREL 0x00020000 /* Opcodes in TB are PC-relative */
#define CF_CLUSTER_MASK 0xff000000 /* Top 8 bits are cluster ID */
#define CF_CLUSTER_SHIFT 24
/*
* Above fields used for comparing
*/
/* size of target code for this block (1 <= size <= TARGET_PAGE_SIZE) */
uint16_t size;
uint16_t icount;
struct tb_tc tc;
/*
* Track tb_page_addr_t intervals that intersect this TB.
* For user-only, the virtual addresses are always contiguous,
* and we use a unified interval tree. For system, we use a
* linked list headed in each PageDesc. Within the list, the lsb
* of the previous pointer tells the index of page_next[], and the
* list is protected by the PageDesc lock(s).
*/
#ifdef CONFIG_USER_ONLY
IntervalTreeNode itree;
#else
uintptr_t page_next[2];
tb_page_addr_t page_addr[2];
#endif
/* jmp_lock placed here to fill a 4-byte hole. Its documentation is below */
QemuSpin jmp_lock;
/* The following data are used to directly call another TB from
* the code of this one. This can be done either by emitting direct or
* indirect native jump instructions. These jumps are reset so that the TB
* just continues its execution. The TB can be linked to another one by
* setting one of the jump targets (or patching the jump instruction). Only
* two of such jumps are supported.
*/
#define TB_JMP_OFFSET_INVALID 0xffff /* indicates no jump generated */
uint16_t jmp_reset_offset[2]; /* offset of original jump target */
uint16_t jmp_insn_offset[2]; /* offset of direct jump insn */
uintptr_t jmp_target_addr[2]; /* target address */
/*
* Each TB has a NULL-terminated list (jmp_list_head) of incoming jumps.
* Each TB can have two outgoing jumps, and therefore can participate
* in two lists. The list entries are kept in jmp_list_next[2]. The least
* significant bit (LSB) of the pointers in these lists is used to encode
* which of the two list entries is to be used in the pointed TB.
*
* List traversals are protected by jmp_lock. The destination TB of each
* outgoing jump is kept in jmp_dest[] so that the appropriate jmp_lock
* can be acquired from any origin TB.
*
* jmp_dest[] are tagged pointers as well. The LSB is set when the TB is
* being invalidated, so that no further outgoing jumps from it can be set.
*
* jmp_lock also protects the CF_INVALID cflag; a jump must not be chained
* to a destination TB that has CF_INVALID set.
*/
uintptr_t jmp_list_head;
uintptr_t jmp_list_next[2];
uintptr_t jmp_dest[2];
};2.2.加速器 - AccelClass
AccelClass 是指令翻译的加速器,例如 KVM、XEN 等加速器
// include/qemu/accel.h
typedef struct AccelClass {
/*< private >*/
ObjectClass parent_class;
/*< public >*/
const char *name;
int (*init_machine)(MachineState *ms);
#ifndef CONFIG_USER_ONLY
void (*setup_post)(MachineState *ms, AccelState *accel);
bool (*has_memory)(MachineState *ms, AddressSpace *as,
hwaddr start_addr, hwaddr size);
#endif
bool (*cpu_common_realize)(CPUState *cpu, Error **errp);
void (*cpu_common_unrealize)(CPUState *cpu);
/* gdbstub related hooks */
int (*gdbstub_supported_sstep_flags)(void);
bool *allowed;
/*
* Array of global properties that would be applied when specific
* accelerator is chosen. It works like MachineClass.compat_props
* but it's for accelerators not machines. Accelerator-provided
* global properties may be overridden by machine-type
* compat_props or user-provided global properties.
*/
GPtrArray *compat_props;
} AccelClass;2.3.虚拟 CPU - TCGContext
TCGContext 保存指令翻译时的上下文信息,包括 CPU、当前指令块的指针、指令缓冲区等,指令块翻译时 CPU 被抽象为 TCGContext
// include/tcg/tcg.h
struct TCGContext {
uint8_t *pool_cur, *pool_end;
TCGPool *pool_first, *pool_current, *pool_first_large;
int nb_labels;
int nb_globals;
int nb_temps;
int nb_indirects;
int nb_ops;
TCGType addr_type; /* TCG_TYPE_I32 or TCG_TYPE_I64 */
int page_mask;
uint8_t page_bits;
uint8_t tlb_dyn_max_bits;
uint8_t insn_start_words;
TCGBar guest_mo;
TCGRegSet reserved_regs;
intptr_t current_frame_offset;
intptr_t frame_start;
intptr_t frame_end;
TCGTemp *frame_temp;
TranslationBlock *gen_tb; /* tb for which code is being generated */
tcg_insn_unit *code_buf; /* pointer for start of tb */
tcg_insn_unit *code_ptr; /* pointer for running end of tb */
#ifdef CONFIG_DEBUG_TCG
int goto_tb_issue_mask;
const TCGOpcode *vecop_list;
#endif
/* Code generation. Note that we specifically do not use tcg_insn_unit
here, because there's too much arithmetic throughout that relies
on addition and subtraction working on bytes. Rely on the GCC
extension that allows arithmetic on void*. */
void *code_gen_buffer;
size_t code_gen_buffer_size;
void *code_gen_ptr;
void *data_gen_ptr;
/* Threshold to flush the translated code buffer. */
void *code_gen_highwater;
/* Track which vCPU triggers events */
CPUState *cpu; /* *_trans */
/* These structures are private to tcg-target.c.inc. */
#ifdef TCG_TARGET_NEED_LDST_LABELS
QSIMPLEQ_HEAD(, TCGLabelQemuLdst) ldst_labels;
#endif
#ifdef TCG_TARGET_NEED_POOL_LABELS
struct TCGLabelPoolData *pool_labels;
#endif
TCGLabel *exitreq_label;
#ifdef CONFIG_PLUGIN
/*
* We keep one plugin_tb struct per TCGContext. Note that on every TB
* translation we clear but do not free its contents; this way we
* avoid a lot of malloc/free churn, since after a few TB's it's
* unlikely that we'll need to allocate either more instructions or more
* space for instructions (for variable-instruction-length ISAs).
*/
struct qemu_plugin_tb *plugin_tb;
/* descriptor of the instruction being translated */
struct qemu_plugin_insn *plugin_insn;
#endif
GHashTable *const_table[TCG_TYPE_COUNT];
TCGTempSet free_temps[TCG_TYPE_COUNT];
TCGTemp temps[TCG_MAX_TEMPS]; /* globals first, temps after */
QTAILQ_HEAD(, TCGOp) ops, free_ops;
QSIMPLEQ_HEAD(, TCGLabel) labels;
/*
* When clear, new ops are added to the tail of @ops.
* When set, new ops are added in front of @emit_before_op.
*/
TCGOp *emit_before_op;
/* Tells which temporary holds a given register.
It does not take into account fixed registers */
TCGTemp *reg_to_temp[TCG_TARGET_NB_REGS];
uint16_t gen_insn_end_off[TCG_MAX_INSNS];
uint64_t *gen_insn_data;
/* Exit to translator on overflow. */
sigjmp_buf jmp_trans;
};2.4.临时变量类型 - TCGTempKind
一般 Guest 的通用寄存器(General Purpose Register,GPR)被定义为 IR 这一层的 Global 寄存器
中间码计算时会用到一些临时变量,这些临时变量保存在 Local Temp 或 Normal Temp 这样的寄存器里,计算要用到一些常量时需要定义一个 TCG 寄存器,然后创建一个常量并将它赋给 TCG 寄存器,Global、Local Temp、Normal Temp 和 Const 这些类型的 TCG 寄存器在前端翻译时经常用到,Fixed 和 EBB 直接使用的情况不多
// include/tcg/tcg.h
typedef enum TCGTempKind {
/*
* Temp is dead at the end of the extended basic block (EBB),
* the single-entry multiple-exit region that falls through
* conditional branches.
*/
TEMP_EBB,
/* Temp is live across the entire translation block, but dead at end. */
TEMP_TB,
/* Temp is live across the entire translation block, and between them. */
TEMP_GLOBAL,
/* Temp is in a fixed register. */
TEMP_FIXED,
/* Temp is a fixed constant. */
TEMP_CONST,
} TCGTempKind;2.5.当前正在翻译的指令块 - DisasContextBase
DisasContextBase 保存当前正在翻译的指令块的相关信息,包括 Guest 的 PC 指针、Host 的地址等
// include/exec/translator.h
/**
* DisasContextBase:
* @tb: Translation block for this disassembly.
* @pc_first: Address of first guest instruction in this TB.
* @pc_next: Address of next guest instruction in this TB (current during
* disassembly).
* @is_jmp: What instruction to disassemble next.
* @num_insns: Number of translated instructions (including current).
* @max_insns: Maximum number of instructions to be translated in this TB.
* @singlestep_enabled: "Hardware" single stepping enabled.
* @saved_can_do_io: Known value of cpu->neg.can_do_io, or -1 for unknown.
* @plugin_enabled: TCG plugin enabled in this TB.
* @insn_start: The last op emitted by the insn_start hook,
* which is expected to be INDEX_op_insn_start.
*
* Architecture-agnostic disassembly context.
*/
typedef struct DisasContextBase {
TranslationBlock *tb;
vaddr pc_first;
vaddr pc_next;
DisasJumpType is_jmp;
int num_insns;
int max_insns;
bool singlestep_enabled;
bool plugin_enabled;
struct TCGOp *insn_start;
void *host_addr[2];
} DisasContextBase;2.6.翻译块的上下文 - DisasContext
DisasContext 保存指令块翻译时的上下文信息,包括寄存器和临时变量,类似于一个包含所有寄存器的虚拟 CPU
// target/i386/tcg/translate.c
typedef struct DisasContext {
DisasContextBase base;
target_ulong pc; /* pc = eip + cs_base */
target_ulong cs_base; /* base of CS segment */
target_ulong pc_save;
...
/* TCG local temps */
TCGv cc_srcT;
TCGv A0;
TCGv T0;
TCGv T1;
/* TCG local register indexes (only used inside old micro ops) */
TCGv tmp0;
TCGv tmp4;
TCGv_i32 tmp2_i32;
...
sigjmp_buf jmpbuf;
TCGOp *prev_insn_start;
TCGOp *prev_insn_end;
} DisasContext;3.TCG 初始化
对全局 TCG 模块初始化,函数入口为 configure_accelerators(),其将 CPU 抽象为 TCGContext,定义翻译块的拆分方法和保存方式(树状保存各个 TCG 输出的翻译块),最后注册 JIT,组织 ELF 结构并构建 ELF
3.1.实例化 TCG 对象
instance_init() 为 TCG 对象的实例化方法
// accel/tcg/tcg-all.c
static const TypeInfo tcg_accel_type = {
.name = TYPE_TCG_ACCEL,
.parent = TYPE_ACCEL,
.instance_init = tcg_accel_instance_init,
.class_init = tcg_accel_class_init,
.instance_size = sizeof(TCGState),
};
module_obj(TYPE_TCG_ACCEL);
-------------------------------------------------------
// accel/tcg/tcg-all.c
static void tcg_accel_class_init(ObjectClass *oc, void *data)
{
AccelClass *ac = ACCEL_CLASS(oc);
ac->name = "tcg";
ac->init_machine = tcg_init_machine;
ac->cpu_common_realize = tcg_exec_realizefn;
ac->cpu_common_unrealize = tcg_exec_unrealizefn;
ac->allowed = &tcg_allowed;
ac->gdbstub_supported_sstep_flags = tcg_gdbstub_supported_sstep_flags;
object_class_property_add_str(oc, "thread",
tcg_get_thread,
tcg_set_thread);
object_class_property_add(oc, "tb-size", "int",
tcg_get_tb_size, tcg_set_tb_size,
NULL, NULL);
object_class_property_set_description(oc, "tb-size",
"TCG translation block cache size");
object_class_property_add_bool(oc, "split-wx",
tcg_get_splitwx, tcg_set_splitwx);
object_class_property_set_description(oc, "split-wx",
"Map jit pages into separate RW and RX regions");
object_class_property_add_bool(oc, "one-insn-per-tb",
tcg_get_one_insn_per_tb,
tcg_set_one_insn_per_tb);
object_class_property_set_description(oc, "one-insn-per-tb",
"Only put one guest insn in each translation block");
}QEMU 初始化时为虚拟机创建加速器 Accelerator,同时执行 Accelerator 的初始化方法
// system/vl.c
qemu_init()
|--> configure_accelerators(argv[0]);
|--> // 查找accelerate:accelerators = "tcg:kvm";
|--> do_configure_accelerator() // 初始化
|--> const char *acc = qemu_opt_get(opts, "accel"); // acc = tcg
|--> AccelClass *ac = accel_find(acc);
|--> AccelState *accel; // Object accel: Class ac --> Object accel
|--> accel = ACCEL(object_new_with_class(OBJECT_CLASS(ac))); // 创建Object accel
|--> // properties setting
|--> ret = accel_init_machine(accel, current_machine);
|--> ms->accelerator = accel;
|--> ret = acc->init_machine(ms);
|--> tcg_init_machine()
|--> object_set_accelerator_compat_props(acc->compat_props);
|--> object_compat_props[0] = compat_props; // 设置accel全局properties3.2.开发板创建时绑定 TCG 加速器 - tcg_init_machine()
tcg_init_machine() 初始化翻译块使用的内存页、哈希表和上下文
// accel/tcg/tcg-all.c
static int tcg_init_machine(MachineState *ms)
{
TCGState *s = TCG_STATE(current_accel());
...
unsigned max_cpus = ms->smp.max_cpus; // 可以通过-smp指定,默认为1
...
page_init(); // 翻译块页表初始化
|--> page_table_config_init();
tb_htable_init(); // 翻译块哈希表初始化,用于搜索翻译块
|--> qht_init(&tb_ctx.htable, tb_cmp, CODE_GEN_HTABLE_SIZE, mode);
tcg_init(s->tb_size * MiB, s->splitwx_enabled, max_cpus); // 上下文初始化
|--> tcg_context_init(max_cpus);
|--> tcg_region_init(tb_size, splitwx, max_cpus);3.3.虚拟 CPU 初始化
每个虚拟的 CPU 对应一个 TCGContext,即在 IR 层 CPU 被抽象为 TCGContext
// tcg/tcg.c
static void tcg_context_init(unsigned max_cpus)
{
TCGContext *s = &tcg_init_ctx;
int op, total_args, n, i;
TCGOpDef *def;
TCGArgConstraint *args_ct;
TCGTemp *ts;
// 基本初始化
memset(s, 0, sizeof(*s));
...
init_call_layout(&info_helper_ld32_mmu);
...
// 初始化IR转换所使用的寄存器
tcg_target_init(s);
// 操作码定义
process_op_defs(s);
/* Reverse the order of the saved registers, assuming they're all at
the start of tcg_target_reg_alloc_order. */
for (n = 0; n < ARRAY_SIZE(tcg_target_reg_alloc_order); ++n) {
int r = tcg_target_reg_alloc_order[n];
if (tcg_regset_test_reg(tcg_target_call_clobber_regs, r)) {
break;
}
}
for (i = 0; i < n; ++i) {
indirect_reg_alloc_order[i] = tcg_target_reg_alloc_order[n - 1 - i];
}
for (; i < ARRAY_SIZE(tcg_target_reg_alloc_order); ++i) {
indirect_reg_alloc_order[i] = tcg_target_reg_alloc_order[i];
}
alloc_tcg_plugin_context(s);
tcg_ctx = s;
/*
* In user-mode we simply share the init context among threads, since we
* use a single region. See the documentation tcg_region_init() for the
* reasoning behind this.
* In system-mode we will have at most max_cpus TCG threads.
*/
#ifdef CONFIG_USER_ONLY
tcg_ctxs = &tcg_ctx;
tcg_cur_ctxs = 1;
tcg_max_ctxs = 1;
#else
tcg_max_ctxs = max_cpus; // 每个虚拟的CPU对应一个TCG Context
tcg_ctxs = g_new0(TCGContext *, max_cpus); // 为TCG Context分配内存
#endif
tcg_debug_assert(!tcg_regset_test_reg(s->reserved_regs, TCG_AREG0));
ts = tcg_global_reg_new_internal(s, TCG_TYPE_PTR, TCG_AREG0, "env");
tcg_env = temp_tcgv_ptr(ts);
}3.4.内存页初始化 - tcg_region_init()
将 code_gen_buffer() 输出的 Buffer 拆分成多块,使 CPU 可以并行处理,同时,创建一个最初始的 TCGContext tcg_init_ctx,user-mode 中 tcg_init_ctx 即为唯一的 TCGContext,system-mode 中 TCGContext 的数量与 vCPU 的个数相关
// tcg/region.c
void tcg_region_init(size_t tb_size, int splitwx, unsigned max_cpus)
{
const size_t page_size = qemu_real_host_page_size();
size_t region_size;
int have_prot, need_prot;
/* Size the buffer. */
if (tb_size == 0) { // 获取内存页大小,宿主机为Linux,一个内存页大小为4KB
...
// 分配实际的内存空间
have_prot = alloc_code_gen_buffer(tb_size, splitwx, &error_fatal);
|--> alloc_code_gen_buffer_anon()
|--> buf = mmap(NULL, size, prot, flags, -1, 0);
|--> region.start_aligned = buf;
|--> region.total_size = size;
...
// 为该内存页分配更大的页表,减少查找未命中时继续加载页表的操作
/* Request large pages for the buffer and the splitwx. */
qemu_madvise(region.start_aligned, region.total_size, QEMU_MADV_HUGEPAGE);
...
/* A region must have at least 2 pages; one code, one guard */
g_assert(region_size >= 2 * page_size);
region.stride = region_size;
// 为页表预留空间
/* Reserve space for guard pages. */
region.size = region_size - page_size;
region.total_size -= page_size;
/*
* The first region will be smaller than the others, via the prologue,
* which has yet to be allocated. For now, the first region begins at
* the page boundary.
*/
region.after_prologue = region.start_aligned;
/* init the region struct */
qemu_mutex_init(®ion.lock);
/*
* Set guard pages in the rw buffer, as that's the one into which
* buffer overruns could occur. Do not set guard pages in the rx
* buffer -- let that one use hugepages throughout.
* Work with the page protections set up with the initial mapping.
*/
need_prot = PROT_READ | PROT_WRITE;
...
// 将TCG Region Memory以树状保存,同时定义了释放每个Region Memory的方法
tcg_region_trees_init();
/*
* Leave the initial context initialized to the first region.
* This will be the context into which we generate the prologue.
* It is also the only context for CONFIG_USER_ONLY.
*/
tcg_region_initial_alloc__locked(&tcg_init_ctx);
|--> bool err = tcg_region_alloc__locked(s);
|--> tcg_region_assign(s, region.current);
|--> tcg_region_bounds(curr_region, &start, &end);
|--> s->code_gen_buffer = start;
|--> s->code_gen_ptr = start;
|--> s->code_gen_buffer_size = end - start;
|--> s->code_gen_highwater = end - TCG_HIGHWATER;
}3.5.翻译准备 - tcg_prologue_init()
Prologue 保存主函数的 Frame Pointer,用于在子函数调用结束后恢复主函数的栈帧,同时为子函数准备栈帧,其主要操作包括:
-
保存主函数的 Frame Pointer,将保存在 ebp 寄存器的 Frame Pointer 压栈,退出子函数时可以从栈中恢复主函数的 Frame Pointer;
-
将 esp 赋值给 ebp,即将子函数的 Frame Pointer 指向主函数的栈顶;
-
修改栈顶指针 esp,为子函数的本地变量分配栈空间;
main 函数并不是程序第一个调用的函数,main 函数也是一个被调用的函数,其也有栈帧,程序第一个被调用的函数 _start 也会模拟一个栈帧
// tcg/tcg.c
__thread TCGContext *tcg_ctx; // 每个线程中都有一个tcg_ctx实例,且互不干扰
----------------------------------------------------------
// tcg/tcg.c
void tcg_prologue_init(void)
{
TCGContext *s = tcg_ctx;
size_t prologue_size;
s->code_ptr = s->code_gen_ptr;
s->code_buf = s->code_gen_ptr;
s->data_gen_ptr = NULL;
...
/* Generate the prologue. */
tcg_target_qemu_prologue(s); // 需要区分平台(i386、ARM、MIPS等)
...
// 注册JIT(即时翻译/动态翻译)
tcg_region_prologue_set(s);
|--> tcg_register_jit()
|--> tcg_register_jit_int()
|--> tcg_register_jit_int()
}
----------------------------------------------------------
// tcg/tcg.c
static void tcg_register_jit_int(const void *buf_ptr, size_t buf_size,
const void *debug_frame,
size_t debug_frame_size)
{
...
struct ElfImage {
ElfW(Ehdr) ehdr; // ELF Header
ElfW(Phdr) phdr; // Program Header
ElfW(Shdr) shdr[7]; // Section Header
ElfW(Sym) sym[2]; // String and Symbol Tables
struct DebugInfo di;
uint8_t da[24];
char str[80];
};
struct ElfImage *img;
// 创建ELF模板
static const struct ElfImage img_template = {
.ehdr = {
.e_ident[EI_MAG0] = ELFMAG0,
...
.shdr = {
...
.sym = {
[1] = { /* code_gen_buffer */
.st_info = ELF_ST_INFO(STB_GLOBAL, STT_FUNC),
.st_shndx = 1,
}
},
...
.str = "\0" ".text\0" ".debug_info\0" ".debug_abbrev\0"
".debug_frame\0" ".symtab\0" ".strtab\0" "code_gen_buffer",
};
/* We only need a single jit entry; statically allocate it. */
static struct jit_code_entry one_entry;
uintptr_t buf = (uintptr_t)buf_ptr;
size_t img_size = sizeof(struct ElfImage) + debug_frame_size;
...
img = g_malloc(img_size);
*img = img_template;
img->phdr.p_vaddr = buf;
...3.6.虚拟 CPU 操作函数 - TCGCPUOps
TCGCPUOps 保存虚拟 CPU 的相关接口,包括中断入口、指令块同步、虚拟 CPU 退出等接口
// target/i386/tcg/tcg-cpu.c
static const TCGCPUOps x86_tcg_ops = {
.initialize = tcg_x86_init,
.synchronize_from_tb = x86_cpu_synchronize_from_tb,
.restore_state_to_opc = x86_restore_state_to_opc,
.cpu_exec_enter = x86_cpu_exec_enter,
.cpu_exec_exit = x86_cpu_exec_exit,
...
.tlb_fill = x86_cpu_tlb_fill,
.do_interrupt = x86_cpu_do_interrupt,
.cpu_exec_halt = x86_cpu_exec_halt,
.cpu_exec_interrupt = x86_cpu_exec_interrupt,
.do_unaligned_access = x86_cpu_do_unaligned_access,
.debug_excp_handler = breakpoint_handler,
.debug_check_breakpoint = x86_debug_check_breakpoint,
.need_replay_interrupt = x86_need_replay_interrupt,
};主板初始化时会绑定 CPU Class 和 TCG 的 tcg_ops
// system/vl.c
qemu_init()
|--> configure_accelerators() // TCG初始化
|--> ...
|--> machine_run_board_init()
|--> accel_init_interfaces(ACCEL_GET_CLASS(machine->accelerator));
|--> accel_system_init_ops_interfaces(ac); // ac.name = tcg
|--> AccelOpsClass *ops;
|--> ops->ops_init(ops);
|--> tcg_accel_ops_init() // TCG Operation相关方法绑定
|--> ops->create_vcpu_thread = mttcg_start_vcpu_thread;
|--> ...
|--> cpus_register_accel(ops);
|--> cpus_accel = ops;
|--> accel_init_cpu_interfaces(ac);
|--> acc = object_class_by_name(acc_name); // ac_name = tcg-accel
|--> accel_init_cpu_int_aux()
|--> accel_cpu->cpu_class_init(cc);
|--> x86_tcg_cpu_class_init()
|--> acc->cpu_target_realize = tcg_cpu_realizefn;
|--> ...
|--> cc->init_accel_cpu(accel_cpu, cc);
|--> x86_tcg_cpu_class_init()
|--> cc->init_accel_cpu = x86_tcg_cpu_init_ops;4.TCG 线程
x86_cpu_new() 创建 CPU 并执行 realize 方法,对于 i386 平台,Object CPU 的 name 为 qemu64-x86_64-cpu,其 Parent 为 Class CPU,对应的 realize 方法为 x86_cpu_realizefn(),执行该方法时初始化 vCPU 线程
// target/i386/cpu.c
static const TypeInfo x86_cpu_type_info = {
.name = TYPE_X86_CPU,
.parent = TYPE_CPU,
...
.class_init = x86_cpu_common_class_init,
|--> device_class_set_parent_realize(dc, x86_cpu_realizefn, &xcc->parent_realize);
|--> ...
};
---------------------------------------------------------------------------
// hw/core/machine.c
machine_run_board_init()
|--> machine_class->init(machine);
|--> pc_init1()
|--> x86_cpus_init(x86ms, pcmc->default_cpu_version);
|--> x86_cpu_new(x86ms, possible_cpus->cpus[i].arch_id, &error_fatal);
|--> Object *cpu = object_new(MACHINE(x86ms)->cpu_type); // name = qemu64-x86_64-cpu
|--> qdev_realize(DEVICE(cpu), NULL, errp);
|--> x86_cpu_realizefn()
|--> qemu_init_vcpu(cs);
|--> cpus_accel->create_vcpu_thread(cpu);CPU Accelerator 调用 create_vcpu_thread() 方法创建线程,在 TCG 初始化时绑定对应的 Operation
// accel/tcg/tcg-accel-ops.c
static void tcg_accel_ops_init(AccelOpsClass *ops)
{
if (qemu_tcg_mttcg_enabled()) {
ops->create_vcpu_thread = mttcg_start_vcpu_thread;
...
---------------------------------------------------------------------------
// accel/tcg/tcg-accel-ops-mttcg.c
void mttcg_start_vcpu_thread(CPUState *cpu)
{
char thread_name[VCPU_THREAD_NAME_SIZE];
g_assert(tcg_enabled());
tcg_cpu_init_cflags(cpu, current_machine->smp.max_cpus > 1);
cpu->thread = g_new0(QemuThread, 1);
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
/* create a thread per vCPU with TCG (MTTCG) */
snprintf(thread_name, VCPU_THREAD_NAME_SIZE, "CPU %d/TCG",
cpu->cpu_index);
qemu_thread_create(cpu->thread, thread_name, mttcg_cpu_thread_fn,
cpu, QEMU_THREAD_JOINABLE);
}TCG 线程创建后运行该线程,线程自身执行的函数为 mttcg_cpu_thread_fn()
// util/qemu-thread-posix.c
qemu_thread_create()
|--> err = pthread_create(&thread->thread, &attr, qemu_thread_start, qemu_thread_args);
|--> void *(*start_routine)(void *) = qemu_thread_args->start_routine;
|--> r = start_routine(arg); // start_routine --> mttcg_cpu_thread_fn
|--> mttcg_cpu_thread_fn()4.1.TCG 线程启动 - mttcg_cpu_thread_fn()
tcg_region_init() 为最初始的 TCGContext tcg_init_ctx 分配空间,user-mode 使用这唯一的一个,system-mode 中会重新创建新的 ctx
由于使用了直接赋值 *s = tcg_init_ctx,因此新创建的 ctx 和 tcg_init_ctx 的 mem_base 指针指向同一块内存,因此需要将 ctx 自身的 mem_base 指针指向自身所属的内存
CPU 线程执行是在一个循环中,如果没有中断/调试等信号,则会持续不断地执行,qemu_wait_io_event() 会响应一些外部中断
// accel/tcg/tcg-accel-ops-mttcg.c
static void *mttcg_cpu_thread_fn(void *arg)
{
MttcgForceRcuNotifier force_rcu;
CPUState *cpu = arg;
...
// RCU Config
rcu_register_thread();
...
tcg_register_thread();
|--> TCGContext *s = g_malloc(sizeof(*s));
|--> *s = tcg_init_ctx;
|--> /* Relink mem_base. */
|--> tcg_ctx = s;
...
// CPU Thread Run
do {
if (cpu_can_run(cpu)) {
...
r = tcg_cpu_exec(cpu);
|--> ret = cpu_exec(cpu);
|--> ret = cpu_exec_setjmp(cpu, &sc);
|--> return cpu_exec_loop(cpu, sc);
...
switch (r) {
case EXCP_DEBUG:
cpu_handle_guest_debug(cpu);
break;
case EXCP_HALTED:
...
break;
case EXCP_ATOMIC:
...
cpu_exec_step_atomic(cpu);
...
}
...
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));4.2.虚拟 CPU 运行 - cpu_exec_loop()
EIP (Extended Instruction Pointer) 寄存器始终指向 CPU 中的下一条指令,当 CPU 执行完当前指令后,EIP 将自动递增,指向下一条待执行的指令
PC (Program Counter) 与 IP/EIP 寄存器的区别在于,PC 寄存器指向 CPU 中当前正在执行的指令,而 IP 寄存器指向 CPU 即将执行的下一条指令
cpu_exec_loop() 循环获取当前的 PC 指针,翻译该 PC 指向的 Guest Code,同时检测是否有中断或异常产生
// accel/tcg/cpu-exec.c
/* main execution loop */
static int __attribute__((noinline))
cpu_exec_loop(CPUState *cpu, SyncClocks *sc)
{
...
/* if an exception is pending, we execute it here */
while (!cpu_handle_exception(cpu, &ret)) { // 异常处理
TranslationBlock *last_tb = NULL;
...
while (!cpu_handle_interrupt(cpu, &last_tb)) { // 中断处理
TranslationBlock *tb;
vaddr pc;
uint64_t cs_base;
uint32_t flags, cflags;
// 获取cs_base指针和pc指针
cpu_get_tb_cpu_state(cpu_env(cpu), &pc, &cs_base, &flags);
// Code Segment Base:0xffff0000
|--> *cs_base = env->segs[R_CS].base;
// Program Counter:pc = cs_base + eip
|--> *pc = (uint32_t)(*cs_base + env->eip);
// #define CF_PCREL 0x00020000 /* Opcodes in TB are PC-relative */
// #define CF_PARALLEL 0x00008000 /* Generate code for a parallel context */
cflags = cpu->cflags_next_tb;
if (cflags == -1) {
cflags = curr_cflags(cpu);
...
// CPU线程刚开始运行时还不存在TranslationBlock,因此需要重新创建
tb = tb_lookup(cpu, pc, cs_base, flags, cflags);
if (tb == NULL) {
...
tb = tb_gen_code(cpu, pc, cs_base, flags, cflags);
...
// 运行翻译块
cpu_loop_exec_tb(cpu, tb, pc, &last_tb, &tb_exit);
...
align_clocks(sc, cpu);
}
}
return ret;
}4.2.1.指令翻译准备 - tb_gen_code()
tb_gen_code() 为后续指令翻译准备内存页,并分配 TB 块
// accel/tcg/translate-all.c
TranslationBlock *tb_gen_code(CPUState *cpu,
vaddr pc, uint64_t cs_base,
uint32_t flags, int cflags)
{
CPUArchState *env = cpu_env(cpu);
TranslationBlock *tb, *existing_tb;
tb_page_addr_t phys_pc, phys_p2;
tcg_insn_unit *gen_code_buf;
...
void *host_pc;
...
// 从Host中获取内存页
phys_pc = get_page_addr_code_hostp(env, pc, &host_pc);
...
// 计算每个TB块中存储多少条翻译指令:max instruction = 512
max_insns = cflags & CF_COUNT_MASK;
if (max_insns == 0) {
max_insns = TCG_MAX_INSNS;
}
tb = tcg_tb_alloc(tcg_ctx);
|--> tb = (void *)ROUND_UP((uintptr_t)s->code_gen_ptr, align);
...
gen_code_buf = tcg_ctx->code_gen_ptr;
...
tcg_ctx->gen_tb = tb;
...
// 循环逐条翻译指令
gen_code_size = setjmp_gen_code(env, tb, pc, host_pc, &max_insns, &ti);
|--> int ret = sigsetjmp(tcg_ctx->jmp_trans, 0); // 保存当前堆栈环境
|--> gen_intermediate_code(env_cpu(env), tb, max_insns, pc, host_pc);
|--> translator_loop(cpu, tb, max_insns, pc, host_pc, &i386_tr_ops, &dc.base);
|--> return tcg_gen_code(tcg_ctx, tb, pc);
...
search_size = encode_search(tb, (void *)gen_code_buf + gen_code_size);
...
/*
* Insert TB into the corresponding region tree before publishing it
* through QHT. Otherwise rewinding happened in the TB might fail to
* lookup itself using host PC.
*/
tcg_tb_insert(tb); // 将TB插入TCG Region Tree
...
// 关联TB和虚拟机的物理内存页(GPA)
existing_tb = tb_link_page(tb);
...
return tb;
}4.2.2.指令翻译 - translator_loop() & disas_insn()
translator_loop() 调用架构对应的指令翻译接口 disas_insn(),将 Guest Code 翻译为中间码
// accel/tcg/translator.c
void translator_loop(CPUState *cpu, TranslationBlock *tb, int *max_insns,
vaddr pc, void *host_pc, const TranslatorOps *ops,
DisasContextBase *db)
{
...
/* Initialize DisasContext */
db->tb = tb;
...
/* Start translating. */
icount_start_insn = gen_tb_start(db, cflags);
...
while (true) {
...
ops->insn_start(db, cpu);
|--> i386_tr_insn_start()
|--> tcg_gen_insn_start(pc_arg, dc->cc_op);
|--> TCGOp *op = tcg_emit_op(INDEX_op_insn_start, 64 / TCG_TARGET_REG_BITS);
|--> TCGOp *op = tcg_op_alloc(opc, nargs);
|--> tcg_set_insn_start_param(op, 0, pc); // op->args[0] = pc
|--> tcg_set_insn_start_param(op, 1, a1); // op->args[1] = a1
...
ops->translate_insn(db, cpu);
|--> i386_tr_translate_insn()
|--> DisasContext *dc = container_of(dcbase, DisasContext, base);
|--> disas_insn(dc, cpu) // 逐条翻译指令,保存在DisasContext的临时变量中
...
}
/* Emit code to exit the TB, as indicated by db->is_jmp. */
ops->tb_stop(db, cpu);
|--> i386_tr_tb_stop()
gen_tb_end(tb, cflags, icount_start_insn, db->num_insns);
...
/* The disas_log hook may use these values rather than recompute. */
tb->size = db->pc_next - db->pc_first;
tb->icount = db->num_insns;
...
}
----------------------------------------------------------------------------------
// target/i386/tcg/translate.c
/* convert one instruction. s->base.is_jmp is set if the translation must
be stopped. Return the next pc value */
static bool disas_insn(DisasContext *s, CPUState *cpu)
{
CPUX86State *env = cpu_env(cpu);
int b, prefixes;
int shift;
MemOp ot, aflag, dflag;
int modrm, reg, rm, mod, op, opreg, val;
bool orig_cc_op_dirty = s->cc_op_dirty;
CCOp orig_cc_op = s->cc_op;
target_ulong orig_pc_save = s->pc_save;
s->pc = s->base.pc_next;
s->override = -1;
...
next_byte:
s->prefix = prefixes;
b = x86_ldub_code(env, s);
/* Collect prefixes. */
switch (b) {
default:
break;
case 0x0f:
b = x86_ldub_code(env, s) + 0x100;
...4.3.指令执行 - cpu_loop_exec_tb()
TCG 中定义了全局的函数指针 tcg_qemu_tb_exec,该函数指针指向翻译块中保存的代码,调用该函数指针将代码段由可写改为可读,从而自动执行内存中保存的指令
// include/tcg/tcg.h
typedef uintptr_t tcg_prologue_fn(CPUArchState *env, const void *tb_ptr);
extern tcg_prologue_fn *tcg_qemu_tb_exec;
----------------------------------------------------------------------
// tcg/tcg.c
void tcg_prologue_init(void)
{
TCGContext *s = tcg_ctx;
...
tcg_qemu_tb_exec = (tcg_prologue_fn *)tcg_splitwx_to_rx(s->code_ptr);
...
// accel/tcg/cpu-exec.c
static inline void cpu_loop_exec_tb(CPUState *cpu, TranslationBlock *tb,
vaddr pc, TranslationBlock **last_tb,
int *tb_exit)
{
...
// 函数指针ptr指向一块内存,当该函数指针被调用时将该块内存有可写变为可读
// CPU将会自动执行该块内存中保存的指令
tb = cpu_tb_exec(cpu, tb, tb_exit);
|--> ret = tcg_qemu_tb_exec(cpu_env(cpu), tb_ptr);
|--> tcg_splitwx_to_rx()
|--> return rw ? rw + tcg_splitwx_diff : NULL;
...
/* Ensure global icount has gone forward */
icount_update(cpu);
...
智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 29
29 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)