【算法解析4/5】降维任务深度解析:常用算法、评估指标及主流算法 | 特征选择、特征提取/投影 | 相关性分析、Lasso、嵌入式方法 | PCA、LDA、t-SNE、UMAP、Autoencoder
大家好,我是爱酱。继前几篇系统探讨了分类、回归、聚类等机器学习核心任务,本篇我们聚焦于降维(Dimensionality Reduction)。降维属于无监督学习(Unsupervised Learning)的一类典型任务。它是数据分析和机器学习中极为重要的预处理与探索工具,能够在保留数据主要结构和信息的同时,降低特征维度,提升计算效率、可视化能力和模型泛化性能。本文将系统梳理降维的动机、主流方法
注:本系列将有五部分,分别对应五大机器学习任务类型,包括:
1. 分类(Classification)、2. 回归(Regression)、3. 聚类(Clustering)、4. 降维(Dimensionality Reduction)以及 5. 强化学习(Reinforcement Learning)
此文含大量干货,建议收藏方便以后再读!
大家好,我是爱酱。继前几篇系统探讨了分类、回归、聚类等机器学习核心任务,本篇我们聚焦于降维(Dimensionality Reduction)。降维属于无监督学习(Unsupervised Learning)的一类典型任务。它是数据分析和机器学习中极为重要的预处理与探索工具,能够在保留数据主要结构和信息的同时,降低特征维度,提升计算效率、可视化能力和模型泛化性能。本文将系统梳理降维的动机、主流方法、数学原理、典型流程与代码实现,便于你直接用于技术文档和学习。
注:本文章颇长近3500字,建议先收藏再慢慢观看。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、什么是降维?为什么要降维?
降维指的是将高维数据映射到低维空间,同时尽量保留原始数据的关键信息和结构。
常见动机包括:
-
可视化:高维数据(如100维)无法直接画图,降到2~3维便于可视化聚类、分布等结构。
-
降噪与压缩:去除冗余或无关特征,减少噪声影响。
-
提升效率:降低计算和存储压力,减少“维度灾难”带来的模型性能下降。
-
特征工程:为后续分类、聚类、回归等任务提取更有代表性的新特征。
二、降维的主要方法体系
降维方法大致分为**特征选择(Feature Selection)和特征提取/投影(Feature Extraction/Projection)**两类:
-
特征选择:直接从原始特征中筛选最有用的子集(如相关性分析、Lasso、嵌入式方法等)。
-
特征提取/投影:将原始特征通过线性或非线性变换,组合成新的低维特征(如PCA、LDA、t-SNE、UMAP、Autoencoder等)。
-
常见的无监督降维方法包括PCA(主成分分析)、t-SNE、LLE、UMAP、Autoencoder等,这些方法都不依赖于标签,只利用输入数据本身。
本篇重点介绍主流特征提取方法。
三、主流降维方法与数学原理
1. 主成分分析(PCA, Principal Component Analysis)
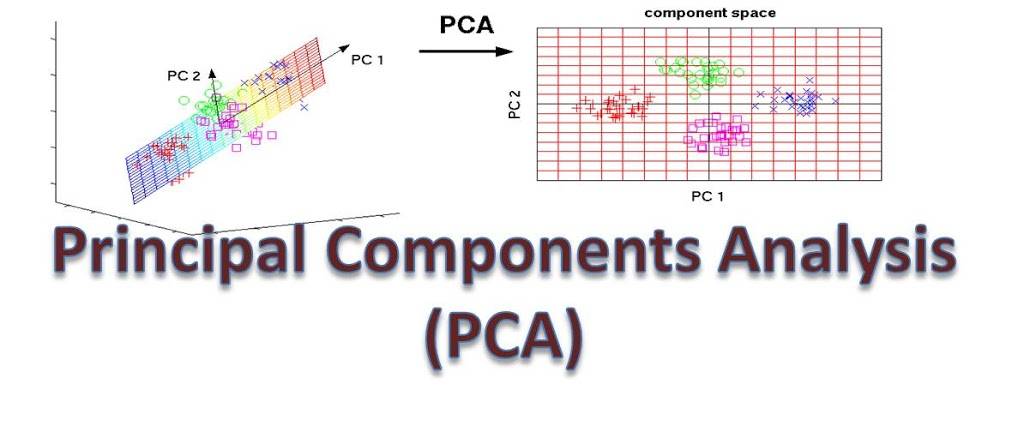
核心思想:线性变换,将数据投影到方差(Variance)最大的方向,找到最能表达数据分布的低维子空间。
数学目标:最大化投影后数据的方差。
公式:
等价于:求数据协方差矩阵的前个最大特征值对应的特征向量。
主成分分解步骤:
-
对数据去均值,计算协方差矩阵
-
求
的特征值和特征向量
-
取前
个最大特征值对应的特征向量,组成投影矩阵
-
低维表示
2. 线性判别分析(LDA, Linear Discriminant Analysis)
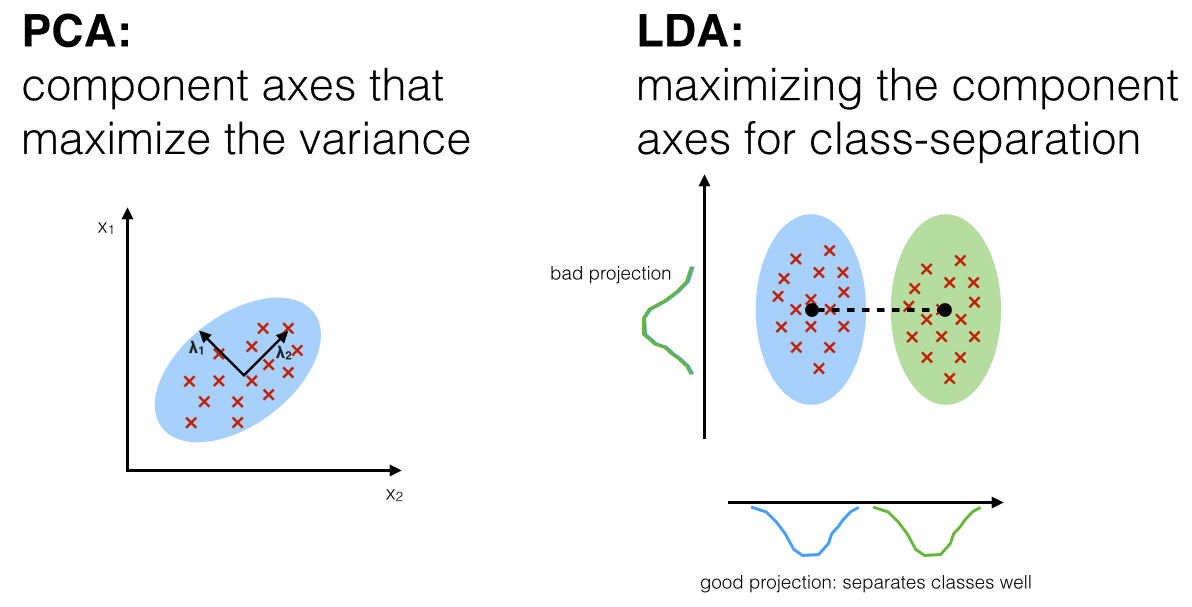
核心思想:有监督降维,找到能最大化类间距离、最小化类内距离的投影方向。
数学目标:
-
:类间散度矩阵
-
:类内散度矩阵
LDA常用于多类别分类的特征压缩与可视化。
3. 奇异值分解(SVD, Singular Value Decomposition)
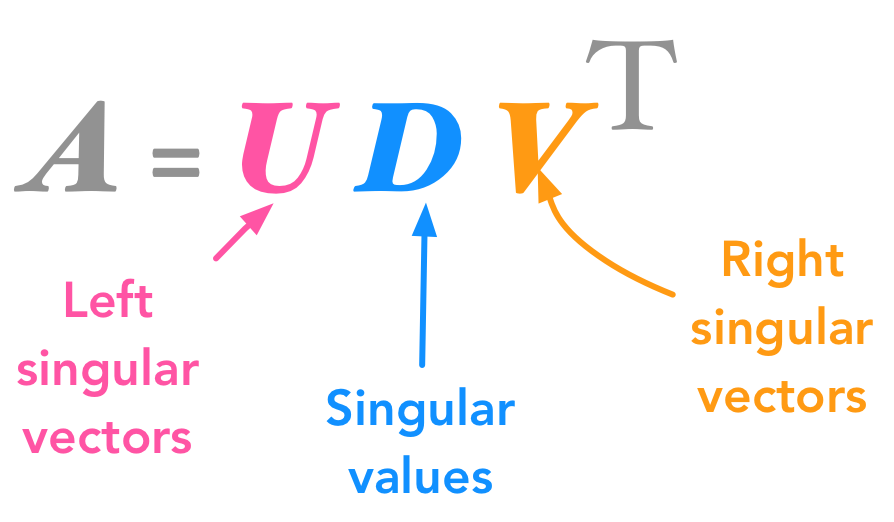
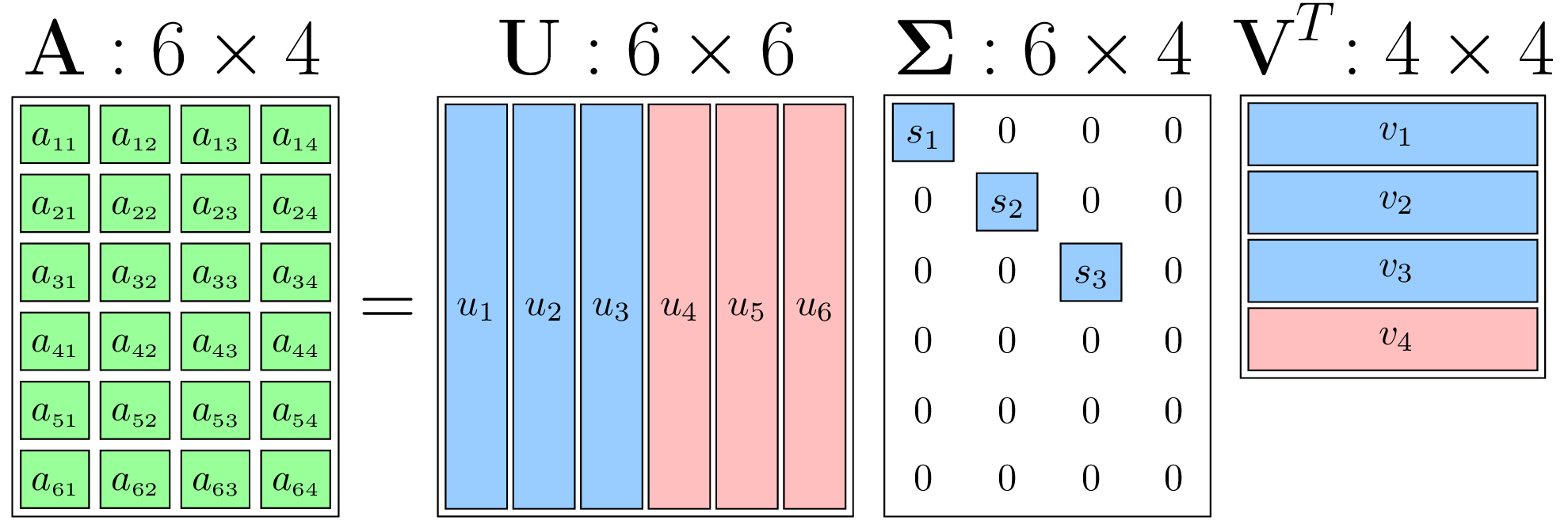
核心思想:将原始矩阵分解为三个矩阵的乘积,截断保留前个奇异值实现降维。
公式:
-
、
为正交矩阵,
为对角矩阵,保留前
SVD常用于文本挖掘(LSA)、图像压缩等。
注:这部分涉及颇复杂的数学、矩阵概念。之后有时间我会单独出一集【AI深究】去进一步解析。有兴趣的同学记得先关注一下喔!
4. 非线性降维方法
a) t-SNE(t-Distributed Stochastic Neighbor Embedding)
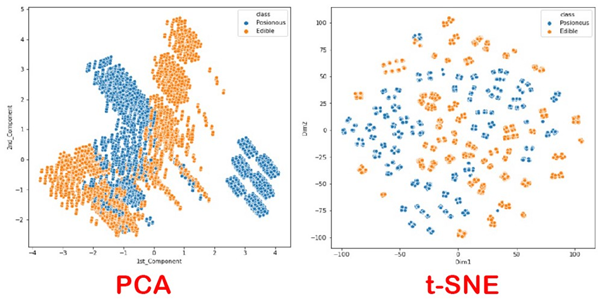
核心思想:保持高维空间中相邻点的概率分布关系,将数据映射到2/3维便于可视化。
流程简述:
-
计算高维空间中点对的相似度概率分布
-
在低维空间中寻找点的位置,使得分布差异(KL散度(KL Divergence))最小
公式(KL散度最小化):
b) UMAP(Uniform Manifold Approximation and Projection)
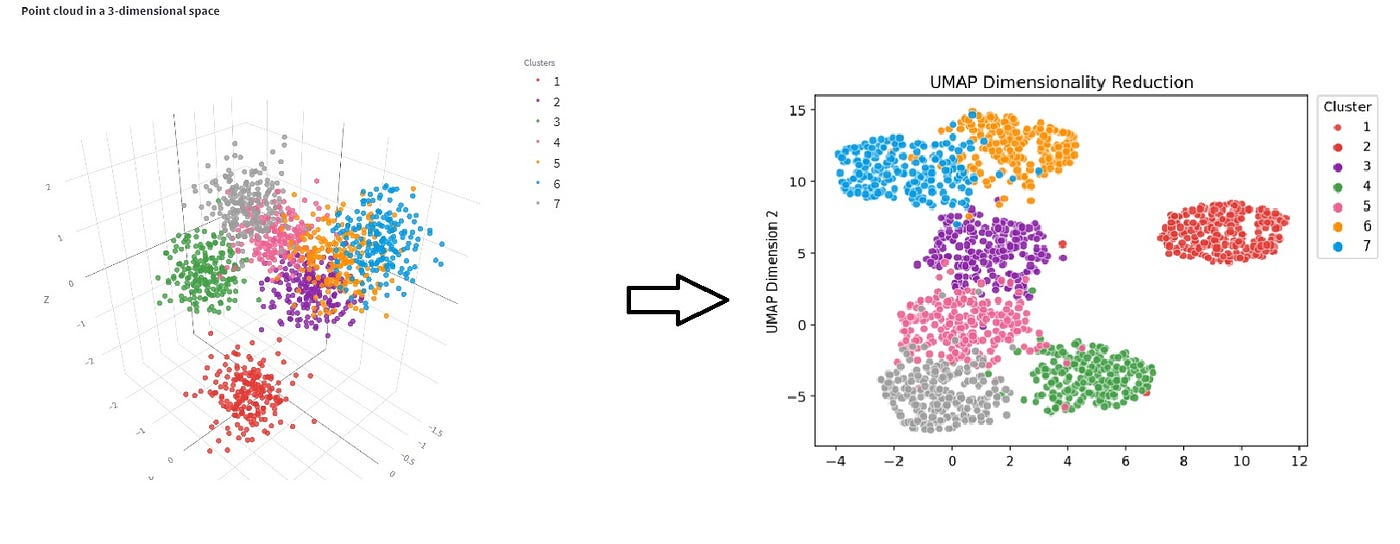
核心思想:假设数据在局部流形上分布,通过保持邻域结构实现高效降维,适合大数据集。
c) Autoencoder(自编码器)
核心思想:用神经网络编码器将高维输入压缩为低维潜变量,再用解码器还原,训练目标是重构误差最小。
公式(重构损失):
-
为编码器,
为解码器
四、降维案例流程与代码演示
案例:鸢尾花(Iris)数据集二维可视化
1. 数据准备与标准化
-
选用Iris数据集(4维),目标是降到2维便于可视化。
2. PCA降维
-
用PCA将4维特征降到2维,画出不同类别的分布。
3. t-SNE降维
-
用t-SNE进一步探索非线性结构,观察可视化效果。
4. 代码示例
注:记得要先 pip install scikit-learn Library喔~还有请大家复制并在本地执行喔~
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names
# 标准化
X_std = StandardScaler().fit_transform(X)
# 1. PCA降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
plt.figure(figsize=(7,5))
for i, label in enumerate(target_names):
plt.scatter(X_pca[y==i,0], X_pca[y==i,1], label=label)
plt.title('PCA 2D Visualization')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
# 2. t-SNE降维
tsne = TSNE(n_components=2, random_state=0)
X_tsne = tsne.fit_transform(X_std)
plt.figure(figsize=(7,5))
for i, label in enumerate(target_names):
plt.scatter(X_tsne[y==i,0], X_tsne[y==i,1], label=label)
plt.title('t-SNE 2D Visualization')
plt.xlabel('Dim1')
plt.ylabel('Dim2')
plt.legend()
plt.show()
五、降维的工程建议与常见问题
-
PCA适合线性结构、数据预处理和压缩,计算高效,解释性强。
-
LDA适合有监督任务,提升分类性能,但只适用于有标签数据。
-
t-SNE/UMAP适合探索高维数据的复杂结构和可视化,但不适合做后续建模特征。
-
Autoencoder适合大规模、非线性、端到端特征学习,但训练和解释较复杂。
-
降维前应标准化/归一化特征,避免尺度影响。
-
降维后应评估信息损失,结合可视化和业务需求选择合适方法和维度数。
六、总结
降维是高维数据分析、可视化和建模的重要基础。理解PCA、LDA、t-SNE、UMAP、Autoencoder等主流方法的原理和适用场景,能帮助你在实际业务和科研中高效处理、探索和利用高维数据。建议结合可视化、特征工程和模型评估,灵活选择降维策略,提升数据分析和机器学习的效果与效率。之后,我会把复杂的主流方法分开解析,有兴趣的伙伴请关注我!
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)