【SpeexDSP库 + WebRTC库】ANS参数优化,多方案对比,STM32H7地铁场景实测
简介
该项目主要对比SpeexDSP和WebRTC的单麦克风噪声抑制模块(NS)在STM32H743IIT6上的表现,同时尝试着优化SpeexDSP的噪声估计策略,根据个人理解调整个别参数,同时也在地铁场景下验证实际效果
特点与不足
特点
1、轻量化部署,实测不需要使用外部存储甚至切换方案时不用释放内存
2、处理速度快,实测降噪处理时间远小于录音时长,说明均可实时处理
3、SpeexDSP在优化噪声估计的算法后跟踪噪声速率明显加快
4、对于平稳或缓慢变化的噪声抑制效果比较明显
不足
1、频率分辨率不足,导致低频段对语音和噪声的分离度不够
2、突变噪声响应慢
详细介绍
1 2 3 4分别是调参后SpeexDSP、原版SpeexDSP、WebRTC和原始音频;
频谱图橙色原始音频,蓝色原版SpeexDSP,紫色WebRTC,绿色调参后SpeexDSP;
音频文件在本文结尾gitee仓库的Recorder文件夹中;
结尾视频对该处理结果做了一些个人解读,感兴趣的可以看看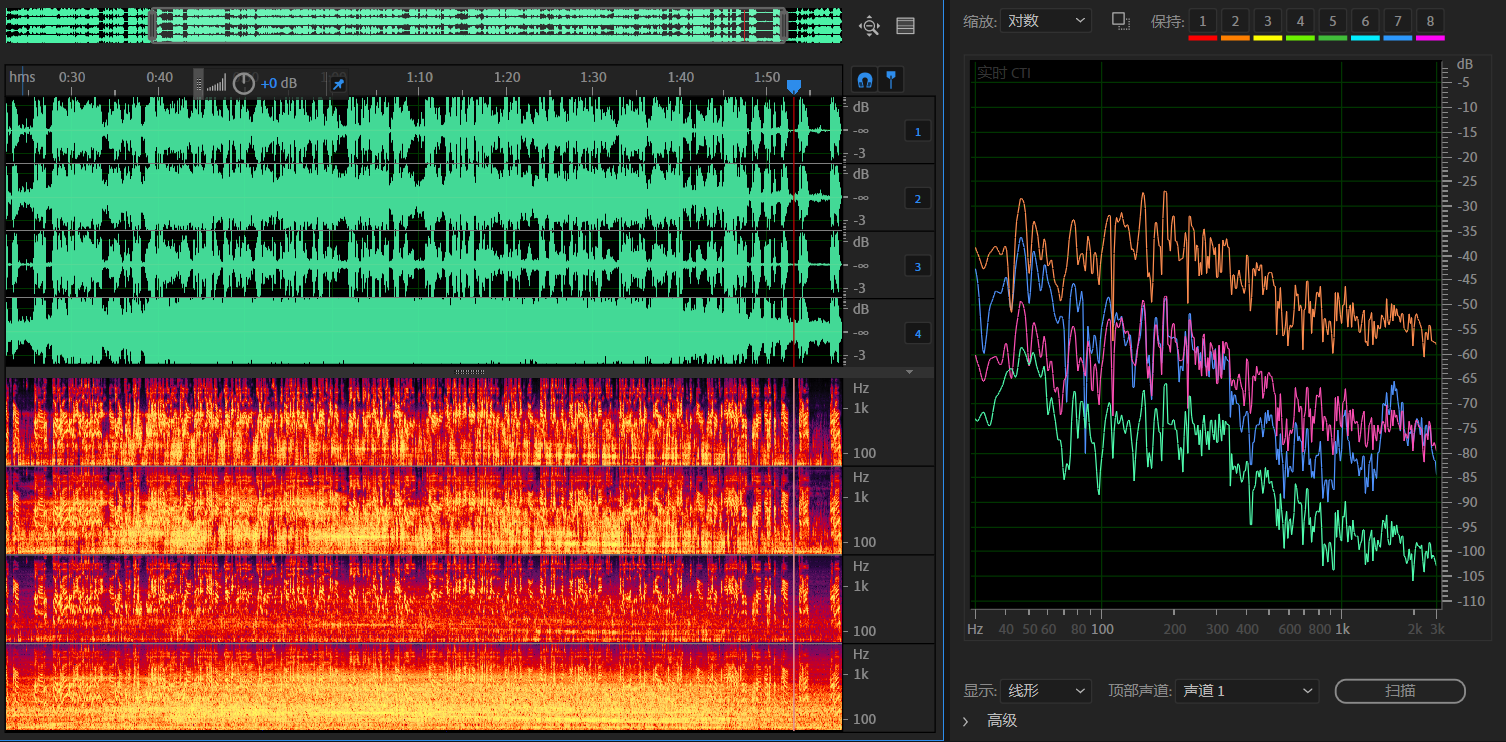
1、语音录制因为需要同时对比多个方案,因此这里将双声道数据复制2份为四通道数据存储
/**
* 将双声道数据转换为四声道数据(前后声道相同)
* @param rawbuf 输入的双声道数据缓冲区(uint8_t* 类型)
* @param changebuf 输出的四声道数据缓冲区(uint8_t* 类型)
* @param num_samples 样本数量(单个声道的样本数)
* @param bytes_per_sample 每个样本占用的字节数(例如:16位=2字节,24位=3字节)
*/
void two2FourChannel(uint8_t *rawbuf, uint8_t *changebuf, uint32_t num_samples, uint8_t bytes_per_sample) {
uint32_t src_offset, dst_offset;
for (uint32_t i = 0; i < num_samples; i++)
{
src_offset = i * 2 * bytes_per_sample; // 计算当前样本在原缓冲区的偏移量(双声道)
dst_offset = i * 4 * bytes_per_sample; // 计算当前样本在目标缓冲区的偏移量(四声道)
// 复制左声道到前左(FL)和后左(RL)
memcpy(&changebuf[dst_offset], &rawbuf[src_offset], bytes_per_sample); // 前左(FL)
memcpy(&changebuf[dst_offset + bytes_per_sample], &rawbuf[src_offset], bytes_per_sample); // 后左(RL)
// 复制右声道到前右(FR)和后右(RR)
memcpy(&changebuf[dst_offset + 2*bytes_per_sample], &rawbuf[src_offset + bytes_per_sample], bytes_per_sample); // 前右(FR)
memcpy(&changebuf[dst_offset + 3*bytes_per_sample], &rawbuf[src_offset + bytes_per_sample], bytes_per_sample); // 后右(RR)
}
}
2、噪声抑制模块初始化
其中webrtcAnsInit_self的实现在【WebRTC库】ANS算法移植stm32单麦克风降噪
/*Speex初始化*/
SpeexPreprocessState *st;
st = speex_preprocess_state_init(REC_SAI_RX_DMA_BUF_SIZE / 20, REC_SAMPLERATE);
i=1;
speex_preprocess_ctl(st, SPEEX_PREPROCESS_SET_DENOISE, &i);
i=-60;
speex_preprocess_ctl(st, SPEEX_PREPROCESS_SET_NOISE_SUPPRESS, &i);
/*WebRTC ANS初始化*/
uint16_t samples = MIN(160, REC_SAMPLERATE / 100);
int16_t *frameBuffer = (int16_t *) mymalloc(SRAMIN, sizeof(*frameBuffer) * samples);
NoiseSuppressionC *NsHandles = (NoiseSuppressionC *) mymalloc(SRAMIN, sizeof(NoiseSuppressionC));
webrtcAnsInit_self(NsHandles, REC_SAMPLERATE, kVeryHigh);
/*启动定时器以记录降噪运行所用的时间,一个计数值=100us*/
HAL_TIM_Base_Start(&htim5);
3、SpeexDSP语音存在判别update_noise_prob(st)该函数主要用来判断当前帧每个频段是否存在语音
注释掉的为原始代码,st->nb_adapt表示为已经处理多少帧数据,min_range大概表示的是每过多少帧更新一次最小功率
// if (st->nb_adapt < 100)
// min_range = 15;
// else if (st->nb_adapt < 1000)
// min_range = 50;
// else if (st->nb_adapt < 10000)
// min_range = 150;
// else
// min_range = 300;
if(st->nb_adapt < 100)
min_range = 15;
else
min_range = 50;
else if里面的内容为博主新增,为了能让高频部分更频繁的更新噪声以适应可能随时到来的高频噪声;st->Smin[i]会一直获取最小的功率,但假如噪声缓慢变大,st->Smin[i]对最小功率的获取会滞后min_range帧,这就会导致后面判断是否包含语音的准确度下降
if (st->min_count >= min_range){
st->min_count = 0;
for (i=0;i<N;i++){
st->Smin[i] = MIN32(st->Stmp[i], st->S[i]);
st->Stmp[i] = st->S[i];
}
}
else if ((st->min_count == min_range*1/5) || //每过10帧更新一次高频噪声估计
(st->min_count == min_range*2/5) || //能让高频更快响应噪声变化
(st->min_count == min_range*3/5) || //低频对噪声变化响应缓慢,相对保护语言完整性
(st->min_count == min_range*4/5))
{
for (i=0;i<16;i++){ //低频(<800Hz)继续获取噪声
st->Smin[i] = MIN32(st->Smin[i], st->S[i]);
st->Stmp[i] = MIN32(st->Stmp[i], st->S[i]);
}
for (i=16;i<N;i++){ //高频(>800Hz)更新噪声
st->Smin[i] = MIN32(st->Stmp[i], st->S[i]);
st->Stmp[i] = st->S[i];
}
}
else {
for (i=0;i<N;i++){
st->Smin[i] = MIN32(st->Smin[i], st->S[i]);
st->Stmp[i] = MIN32(st->Stmp[i], st->S[i]);
}
}
而判断是否包含语音就只是用当前的功率*0.4是否大于st->Smin[i]来判断。你要是噪声变化的真的缓慢还好,万一变化快点把噪声误判成语音就比较难受了
for (i=0;i<N;i++){
if (MULT16_32_Q15(QCONST16(.4f,15),st->S[i]) > st->Smin[i])
st->update_prob[i] = 1;
else
st->update_prob[i] = 0;
}
所以我们可以看到,min_range太大会导致更新不及时可能导致较为严重的噪声残留,太小又可能导致将语音误判为噪声,出现“你~在~干~什~么~”变成“你!在!干!什!么!”这种情况
4、SpeexDSP噪声估计更新
原始代码为注释掉的那一行;当我们判断当前频点没有语音,或者当前的功率小于我上一帧的噪声估计时,则会更新噪声估计st->noise[i];如果有语音则不更新噪声估计;
通过计算st->noise[i]的公式可以发现,其噪声估计实际就是以每帧0.03的比例去逼近当前帧的功率;
因此对于高频部分我选择以更快的速率去逼近;
beta = MAX16(QCONST16(.03,15),DIV32_16(Q15_ONE,st->nb_adapt));
beta_1 = Q15_ONE-beta;
for (i=0;i<N;i++)
{
if (!st->update_prob[i] || st->ps[i] < PSHR32(st->noise[i], NOISE_SHIFT)){
// st->noise[i] = MAX32(EXTEND32(0),MULT16_32_Q15(beta_1,st->noise[i]) + MULT16_32_Q15(beta,SHL32(st->ps[i],NOISE_SHIFT)));
if(i<16) //低频高度信任上一帧噪声
st->noise[i] = MAX32(0, MULT16_32_Q15(beta_1, st->noise[i]) + MULT16_32_Q15(beta, st->ps[i]));
else //高频加快噪声更新
st->noise[i] = MAX32(0, MULT16_32_Q15(beta_1-beta*9, st->noise[i]) + MULT16_32_Q15(beta*10, st->ps[i]));
}
}
比较直观的结果就是这种高频的警报声会比较快的识别并衰减,从 “哔~” 变成 “哔!”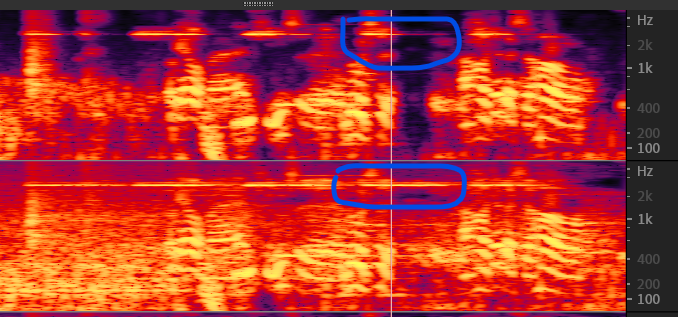
5、WebRTC的调用也是上一篇博客实现过了
6、wav音频文件数据排序格式重组,并修改wav头信息
/**
* @brief 转换音频数据排序方式(支持双声道和四声道)
* @param mode : 转换模式
* @arg 0, 声道分组排列 -> 交叉排列(如:左左左...右右右... -> 左右左右)
* @arg 1, 交叉排列 -> 声道分组排列(如:左右左右 -> 左左左...右右右...)
* @param buffer : 音频数据缓冲区
* @param buf_size : 音频数据缓冲区大小(字节)
* @param num_channels : 声道数(2或4)
* @param bytes_per_sample : 每个样本的字节数(如:16位=2字节,24位=3字节)
*/
void wav_data_transfer(uint8_t mode, void *buffer, uint32_t buf_size, uint8_t num_channels, uint8_t bytes_per_sample) {
uint8_t* samples = (uint8_t*)buffer;
uint32_t total_samples = buf_size / bytes_per_sample; // 总样本数
uint32_t samples_per_channel = total_samples / num_channels; // 每声道样本数
// 分配临时缓冲区
uint8_t* temp_buffer = (uint8_t*)mymalloc(SRAMIN, buf_size);
if (temp_buffer == NULL) return; // 内存分配失败
if (mode) { // 模式1: 交叉排列 -> 声道分组排列
for (uint32_t ch = 0; ch < num_channels; ch++) { // 遍历每个声道
for (uint32_t i = 0; i < samples_per_channel; i++) { // 遍历每个声道的样本
uint32_t src_offset = (i * num_channels + ch) * bytes_per_sample; // 交叉排列源位置
uint32_t dst_offset = (i + ch * samples_per_channel) * bytes_per_sample; // 分组排列目标位置
// 复制整个样本(处理多字节样本)
memcpy(&temp_buffer[dst_offset], &samples[src_offset], bytes_per_sample);
}
}
} else { // 模式0: 声道分组排列 -> 交叉排列
for (uint32_t ch = 0; ch < num_channels; ch++) { // 遍历每个声道
for (uint32_t i = 0; i < samples_per_channel; i++) { // 遍历每个声道的样本
uint32_t src_offset = (i + ch * samples_per_channel) * bytes_per_sample; // 分组排列源位置
uint32_t dst_offset = (i * num_channels + ch) * bytes_per_sample; // 交叉排列目标位置
// 复制整个样本(处理多字节样本)
memcpy(&temp_buffer[dst_offset], &samples[src_offset], bytes_per_sample);
}
}
}
// 将临时缓冲区内容复制回原缓冲区
memcpy(buffer, temp_buffer, buf_size);
myfree(SRAMIN, temp_buffer);
}
总结
总的来说还是WebRTC的NS算法发挥比较稳定,WebRTC对于平稳噪声最高能达到-20dB的噪声抑制,听感上也是最良好的;
SpeexDSP本身的参数可能需要些调整以适应不同开发者所应用的场景,但本身算法原理上比较糙,要想达到能用的地步还是得调参;
运算速度方面,如果有FPU加持WebRTC处理速度甚至快过SpeexDSP,但它基本做不了浮点转定点的操作;如果没有FPU,SpeexDSP原生支持定点操作,在低端的嵌入式设备上运行压力会小一点
资源共享
代码 https://gitee.com/creator-len/study-ans
效果展示
开源噪声抑制ANS方案横评,SpeexDSP调优+WebRTC的STM32地铁场景实录与分析

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)