Box64 架构浅析
原生库集成 (Native Library Integration): 通过精巧的函数封装系统 (Function Wrapping System),Box64 允许被模拟的 x86_64 程序直接调用宿主系统上已有的、经过硬件加速的原生函数库(如 OpenGL, Vulkan, 音频库等)。需要指出的是,指令翻译并非简单的逐条映射。它的根本目标是将 x86_64 指令实时(On-the-fly)
目前,国产操作系统在推广过程中最大瓶颈在于生态,尤其是在拥有完全自主指令集的龙芯(LoongArch64)与 RISC-V 平台上。若说 Linux 生态较 Windows 短板一个数量级,那么与 x86 相比,龙芯与 RISC-V 的软件生态又再少一个数量级。其实,龙芯平台上的操作系统、编译器、C++ 库等关键组件已较为完善,但各类应用软件仍然匮乏。就连常用开发工具如 Visual Studio Code、Qt、JetBrains 系列在龙芯平台上尚无对应版本。
为什么应用软件厂商对国产系统的适配意愿不高?归根结底是投入产出不成正比:用户基数有限导致厂商不愿投入,而应用不足又会令用户流失。要打破这一恶性循环,不能等靠要。一群务实的工程师采取了行动,积极研究各种过渡方案,采取拿来主义。例如,借助 WINE 可在国产 Linux 系统上运行大多数 Windows 应用,虽不完美,但能显著丰富软件生态。比如,我日常使用的企业微信即通过此方式运行,完全没感觉它是一个 Windows 程序。
WINE 可使 Windows 应用在同架构的 Linux 系统上运行,然而 Windows 软件几乎皆为 x86 架构,因此只能在 x86 架构的国产系统上稳定运行。对于 ARM64、LoongArch64 和 RISC-V,因指令集差异,无法直接执行。
事实上,苹果 macOS 曾经历两次架构迁移(PowerPC→Intel、Intel→ARM),其策略是指令翻译加速过渡,同时敦促开发者发布原生应用。从 Intel 迁向自研 ARM 芯片时,苹果采用 Rosetta 技术将 x86 指令动态翻译为 ARM 指令,成功缓解了迁移期的用户顾虑。虽然 Rosetta 并未开源,但这一思路早为芯片厂商采用。早在进军移动市场时,Intel 即开发过将 ARM 指令翻译为 x86 的软硬件方案;龙芯也发布了硬件辅助的指令翻译技术。在开源领域,Box64 是最受欢迎的项目之一,它支持将 x86 指令翻译成 ARM64、LoongArch 和 RISC-V 指令。
Box64 项目主页对其核心优势的介绍:
• 在非 x86_64 的 Linux 系统(如 Arm,需 64 位小端主机)上运行 x86_64 应用(包括游戏)成为可能
• 利用本地系统库(libc、libm、SDL、OpenGL),轻松集成且性能表现出色
• 在 ARM64、RV64 与 LA64 平台上,凭借 DynaRec 动态重编译,速度较仅用解释器提升 5–10 倍
需要指出的是,指令翻译并非简单的逐条映射。Box64 结合解释执行与动态重编译(Dynarec)技术,在兼顾兼容性的同时追求高性能。这种 JIT(即时编译)技术亦广泛应用于 Java、JavaScript 等领域,Box64 的实现原理与之类似。
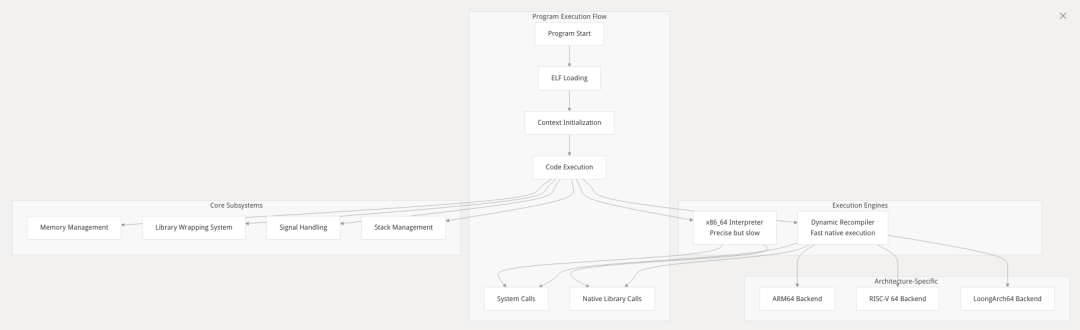
Box64 如何同时支持多种架构翻译,又在兼容性与性能间取得平衡?这得益于其模块化设计与灵活的执行引擎。
-
多层次执行引擎Box64 在最外层负责 ELF 可执行文件与库的加载与管理;中间层提供环境与内存映射抽象;最核心层则由解释器与 Dynarec 组成,分别用于逐指令执行与块级 JIT 编译。
-
模块化设计通过将平台无关的核心逻辑与各目标架构(ARM64、RISC‑V、LoongArch)专有的 Dynarec 后端分离,Box64 能在编译时根据目标平台选用适当的实现,提高可维护性与扩展性。
核心组件(Core Components)
模拟核心(Emulation Core)
这是 Box64 的核心。其中 x64emu_t 结构体(定义在 src/emu/x64emu_private.h 文件)维护着被仿真 CPU 的完整状态,这是一个比较大的结构体,内容如下:
typedef struct x64emu_s {
// cpu
reg64_t regs[16];
x64flags_t eflags;
reg64_t ip;
// sse
sse_regs_t xmm[16];
sse_regs_t ymm[16];
// fpu / mmx
mmx87_regs_t x87[8];
mmx87_regs_t mmx[8];
x87flags_t sw;
uint32_t top; // top is part of sw, but it's faster to have it separately
int fpu_stack;
x87control_t cw;
uint16_t dummy_cw; // align...
mmxcontrol_t mxcsr;
#ifdef RV64 // it would be better to use a dedicated register for this like arm64 xSavedSP, but we're running of of free registers.
uintptr_t xSPSave; // sp base value of current dynarec frame, used by call/ret optimization to reset stack when unmatch.
#endif
fpu_ld_t fpu_ld[8]; // for long double emulation / 80bits fld fst
fpu_ll_t fpu_ll[8]; // for 64bits fild / fist sequence
uint64_t fpu_tags; // tags for the x87 regs, stacked, only on a 16bits anyway
// old ip
uintptr_t old_ip;
// deferred flags
int dummy1; // to align on 64bits with df
deferred_flags_t df;
multiuint_t op1;
multiuint_t op2;
multiuint_t res;
uint32_t *x64emu_parity_tab; // helper
// segments
uint16_t segs[6]; // only 32bits value?
uint16_t dummy_seg6, dummy_seg7; // to stay aligned
uintptr_t segs_offs[6]; // computed offset associate with segment
uint32_t segs_serial[6]; // are seg offset clean (not 0) or does they need to be re-computed (0)? For GS, serial need to be the same as context->sel_serial
// parent context
box64context_t *context;
// cpu helpers
reg64_t zero;
reg64_t *sbiidx[16];
// emu control
int quit;
int error;
int fork; // quit because need to fork
int exit;
forkpty_t* forkpty_info;
emu_flags_t flags;
x64test_t test; // used for dynarec testing
// scratch stack, used for alignment of double and 64bits ints on arm. 200 elements should be enough
__int128_t dummy_align; // here to have scratch 128bits aligned
uint64_t scratch[N_SCRATCH];
// Warning, offsetof(x64emu_t, xxx) will be too big for fields below.
#ifdef HAVE_TRACE
sse_regs_t old_xmm[16];
sse_regs_t old_ymm[16];
reg64_t oldregs[16];
uintptr_t prev2_ip;
#endif
// local stack, do be deleted when emu is freed
void* stack2free; // this is the stack to free (can be NULL)
void* init_stack; // initial stack (owned or not)
uint32_t size_stack; // stack size (owned or not)
JUMPBUFF* jmpbuf;
#ifdef RV64
uintptr_t old_savedsp;
#endif
#ifdef _WIN32
uint64_t win64_teb;
#endif
int type; // EMUTYPE_xxx define
#ifdef BOX32
int libc_err; // copy of errno from libc
int libc_herr; // copy of h_errno from libc
unsigned short libctype[384]; // copy from __ctype_b address might be too high
const unsigned short* ref_ctype;
const unsigned short* ctype;
int libctolower[384]; // copy from __ctype_b_tolower address might be too high
const int* ref_tolower;
const int* tolower;
int libctoupper[384]; // copy from __ctype_b_toupper address might be too high
const int* ref_toupper;
const int* toupper;
void* res_state_32; //32bits version of res_state
void* res_state_64;
#endif
} x64emu_t;该结构体完整地定义了一个 x86_64 CPU 的状态,以及模拟器运行所需的上下文和控制信息。可以把它理解为在 ARM64 内存中构建的一个虚拟 x86_64 CPU 核心。
-
程序计数器 (Program Counter / Instruction Pointer)
reg64_t ip;
这是 x86_64 的 RIP 它保存着当前模拟执行流的指令地址。Dynarec 或解释器会从这个地址读取 x86_64 指令并执行。
-
通用寄存器 (General-Purpose Registers - GPRs)
reg64_t regs[16];
x86_64 架构共有 16 个 64 位通用寄存器。所以定义了这个数组,用于存放全部 16 个 x86_64 通用寄存器的值。它们通常按以下顺序存储:RAX, RCX, RDX, RBX, RSP, RBP, RSI, RDI, R8 到 R15。
-
标志寄存器 (Flags Register)
x64flags_t eflags;
标志寄存器(EFLAGS/RFLAGS)保存着最近一次算术或逻辑运算的状态,用于条件判断和控制流程。eflags 保存了完整的 RFLAGS 寄存器的状态,包括进位(CF)、零(ZF)、符号(SF)、溢出(OF)等标志位。
deferred_flags_t df;
延迟标志位(Deferred Flags)。这是一种常见的模拟器性能优化技术。不是每次算术运算后都立即计算并更新 eflags,而是只在需要用到标志位时(如条件跳转指令 Jcc)才根据 op1, op2, res 的值来计算。这避免了不必要的计算开销。
multiuint_t op1; multiuint_t op2; multiuint_t res;
这三个字段与 df 配合使用,分别存储上一次算术运算的操作数1、操作数2和结果,以便在需要时计算延迟标志位。
-
SIMD 寄存器状态 (SSE/AVX/MMX)
SIMD (Single Instruction, Multiple Data) 寄存器用于并行处理数据,在多媒体、科学计算和游戏中至关重要。
sse_regs_t xmm[16];
保存 16 个 128 位的 SSE 寄存器(XMM0 - XMM15)的状态。
sse_regs_t ymm[16];
保存 16 个 256 位的 AVX 寄存器(YMM0 - YMM15)的状态。值得注意的是,YMM 寄存器的低 128 位与对应的 XMM 寄存器是共享的。在这个结构中,YMM 寄存器的高 128 位可能被独立存储在这里。
mmx87_regs_t mmx[8];
保存 8 个 64 位的 MMX 寄存器(MM0 - MM7)的状态。在物理上,MMX 寄存器是 FPU 寄存器的别名,但在这里被分开模拟。
mmxcontrol_t mxcsr;
这是 MXCSR 控制/状态寄存器。它包含了用于 SSE 浮点运算的标志位(如无效操作、除零等)和控制位(如舍入模式)。
-
段寄存器 (Segment Registers) 在 64 位模式下,段寄存器的主要作用减弱,但 FS 和 GS 仍然被广泛用于访问线程局部存储(Thread-Local Storage, TLS)。
uint16_t segs[6];
存储 6 个段选择子(Segment Selectors):ES, CS, SS, DS, FS, GS。 uintptr_t segs_offs[6];
缓存计算出的段基地址(Segment Base Address)。为了提高效率,Box64 会计算出 FS 和 GS 的基地址并缓存在这里,这样在访问 TLS 时就无需重复进行复杂的计算。
uint32_t segs_serial[6];
一个序列号或版本号,用于判断 segs_offs 中缓存的基地址是否仍然有效。当线程上下文切换时,GS 基地址可能会改变,这个序列号会随之更新,从而触发 segs_offs 的重新计算。
该结构体还包含其他对模拟器至关重要的字段,比如FPU 状态、模拟器控制等。
仿真核心提供两种执行方式:
-
解释模式(Interpreter Mode):逐条执行 x86_64 指令(在各个
x64run*.c文件中实现) -
动态重编译模式(Dynarec Mode):将 x86_64 代码块翻译为本地代码,以实现更快的执行速度
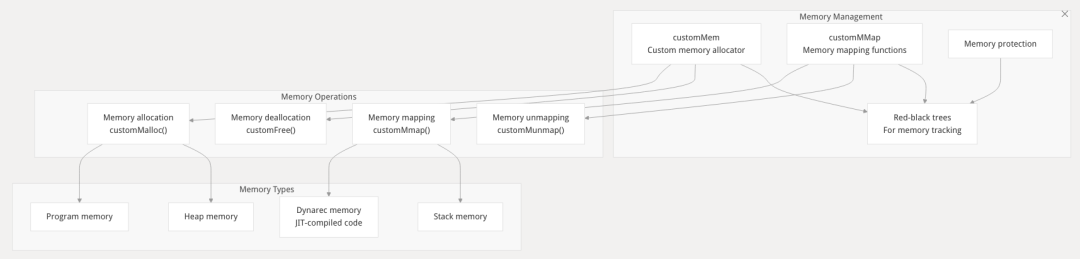
内存管理系统(Memory Management)
Box64 的内存管理系统是其高效运行的关键之一。与 QEMU 等全系统模拟器不同,Box64 并不模拟一个独立的、完整的 x86_64 内存管理单元(MMU)。相反,它采用了一种更轻量、更高效的策略,在宿主(ARM64)进程的同一个虚拟地址空间内工作。
1. 统一地址空间管理与映射跟踪
核心原则: x86_64 程序看到的虚拟地址就是它在 ARM64 宿主进程中实际获得的虚拟地址。
Box64 启动一个 x86_64 程序时,该程序的所有内存(代码、数据、栈、堆)都存在于运行 Box64 的那个 ARM64 进程的虚拟地址空间内。这种设计的巨大优势是零拷贝:当调用一个原生 ARM64 库时,可以直接传递内存地址指针,因为双方都在同一个地址空间内,无需进行任何数据复制。
Box64 的内存管理器必须:
-
跟踪所有内存映射: 它维护一个内部数据结构(如链表或树),记录由被模拟程序请求的每一块内存区域。这包括内存的起始地址、大小、权限(读/写/执行)以及来源(匿名内存、文件映射等)。
-
解决地址空间冲突: Box64 自身、其动态重编译器(Dynarec)的 JIT 缓存、以及被模拟的程序都共享同一个地址空间。内存管理器需要巧妙地为被模拟程序分配地址,以避免与 Box64 自身所需的内存区域(如 Dynarec 缓存)发生冲突。它通常会尝试在 32 位地址空间(低于 4GB)内为 x86_64 程序分配内存,将高地址空间留给自己使用。
2. 系统调用拦截与翻译 (Syscall Interception)
这是 Box64 内存管理的实现核心。当 x86_64 程序需要向内核申请或修改内存时,它会发起系统调用。Box64 会拦截这些调用并代表其执行。
主要拦截的内存相关系统调用包括:
-
mmap: 这是最重要的内存分配 syscall。当 x86_64 程序调用 mmap 时,Box64 捕获该调用及其参数。然后,Box64 调用宿主 ARM64 内核的 mmap 系统调用。内核分配内存后返回一个原生的 ARM64 指针。因为地址空间是统一的,这个指针对于 x86_64 程序来说也是有效的。最后,Box64 将这个指针返回给模拟的程序,并在自己的内部映射表中记录下这块新分配的区域。
-
munmap: 当程序释放内存时,Box64 拦截 munmap 调用,调用宿主的 munmap 来真正释放内存,并从其内部映射表中移除该记录。
-
mprotect: 当程序改变内存区域的权限(例如,JIT 编译器需要将数据内存变为可执行内存)时,Box64 拦截该调用,并调用宿主的 mprotect 来实现权限变更,同时更新内部映射表中的权限信息。
-
mremap, brk, sbrk: 对于调整内存区域大小或管理程序数据段(堆)的调用,Box64 同样进行拦截和处理。
3. 栈 (Stack) 管理
每个线程都需要自己的栈空间。当 x86_64 程序通过 clone 系统调用创建新线程时:
-
Box64 拦截 clone 调用。
-
它使用 mmap 为新线程分配一块内存作为其栈。
-
然后,它调用宿主的 clone 系统调用,并传递这个新分配的栈的地址。
-
在新创建的模拟线程的 CPU 上下文 (x64emu_t) 中,它会将栈指针寄存器 (RSP) 初始化为指向这块新分配的内存区域的顶部。
4. 函数指针包装与回调生成 (Thunking)
这是内存管理中一个非常精妙的部分,对于与原生库交互至关重要。
比如,当一个 x86_64 程序将一个函数指针(例如一个回调函数)传递给一个原生 ARM64 库(如 GTK+ 的按钮点击事件处理函数)时,原生库无法直接执行 x86_64 代码。这个时候,Box64 的内存管理器会动态地在一块可执行内存(通过 mmap 分配,并用 mprotect 设为 PROT_EXEC)中生成一小段原生的 ARM64 代码。这个小代码片段被称为“Thunk”或“跳板”。
这个 Thunk 的作用是:当原生库调用它时,它会执行必要的上下文切换操作(如加载正确的 x64emu_t 状态),然后跳转到 Box64 的模拟器主循环,并开始执行原始的 x86_64 回调函数。
Box64 会将这个原生 Thunk 的地址返回给原生库,而不是原始的 x86_64 函数指针。
所以,内存管理器在这里负责动态分配、生成和管理这些用于跨架构函数调用的可执行代码片段。
5. 线程局部存储 (Thread-Local Storage - TLS) 处理
x86_64 和 AArch64 使用不同的机制访问 TLS。
-
x86_64: 通常使用 FS 或 GS 段寄存器作为基址来访问。
-
AArch64: 使用专用的系统寄存器 TPIDR_EL0 来存储 TLS 指针。
Box64 的内存管理器负责桥接这个差异:
-
当程序通过 arch_prctl 或 set_thread_area 等方式设置 TLS 时,Box64 拦截调用。
-
它在宿主环境中为该线程设置好 TLS(通常是调用宿主 libc 的函数或直接发起 syscall)。
-
它将获取到的 TLS 基地址缓存在模拟的 CPU 上下文 x64emu_t 结构体中与 FS/GS 段寄存器关联的位置 (segs_offs)。
-
当 Dynarec 遇到访问 FS 或 GS 的指令时,它会生成直接从缓存中读取基地址的原生 ARM64 代码,从而高效地模拟了 TLS 访问。
函数封装系统(Function Wrapping)
Box64 的函数封装系统是其架构中的关键支柱,其核心目标是搭建一座桥梁,让运行在模拟环境下的 x86_64 程序能够无缝地调用宿主系统(如 ARM64)上的原生函数库。
这个系统通过拦截 x86_64 程序对外部库函数的调用,将其转换为对原生库函数的调用,从而实现了以下几个关键优势:
-
性能最大化: 允许程序直接利用硬件加速的原生库(如 OpenGL, Vulkan, ALSA),而不是去模拟它们,性能远超完全模拟的方案。
-
高兼容性: 无需为每个 x86_64 程序提供全套的 x86_64 库依赖,可以直接复用宿主系统已有的、功能完备的原生库。
-
无缝体验: 对 x86_64 程序而言,调用过程是透明的,它感知不到自己实际上在与一个不同架构的库进行交互。
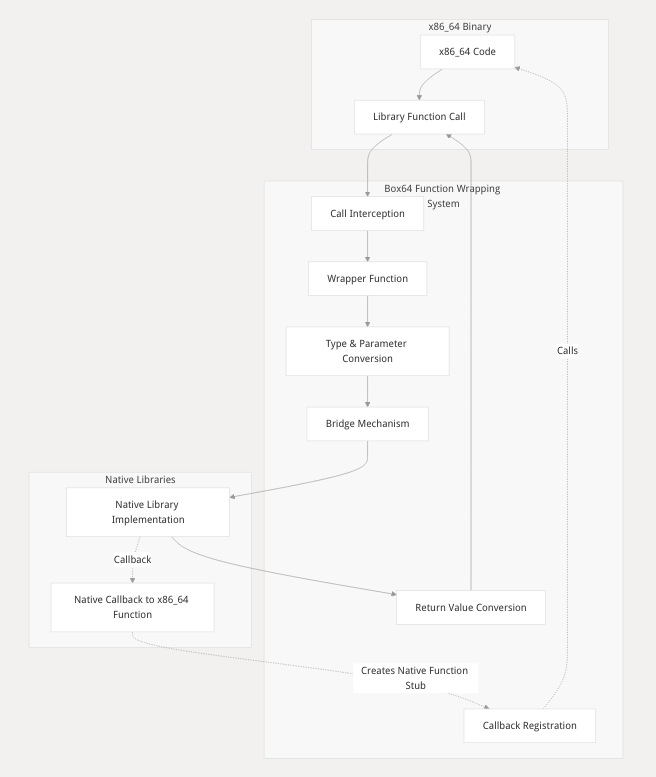
该系统的工作流程可以概括为以下几个步骤:
-
调用拦截: 当 x86_64 程序调用一个外部函数(如 printf)时,Box64 的 ELF 加载器将这个调用重定向到 Box64 内部。
-
查找封装器 (Wrapper): Box64 在其注册的封装库列表中查找对应的封装函数。
-
执行封装器: 找到的封装器函数被执行,它负责整个“翻译”过程:
-
-
参数提取与转换: 从模拟的 x86_64 CPU 上下文(x64emu_t 结构体)中提取参数。这包括从寄存器(如 RDI, RSI)和栈(RSP)中读取数据,并将其从 x86_64 的调用约定转换为宿主架构(如 ARM64)的调用约定。
-
调用原生函数: 使用转换后的参数,调用真正的原生库函数。
-
返回值转换: 接收原生函数的返回值,并将其转换为 x86_64 期望的格式,然后存入相应的返回寄存器(如 RAX)或栈中。
-
-
返回控制权: 将执行控制权交还给 x86_64 程序,程序继续执行,仿佛调用了一个普通的 x86_64 函数。
Box64 的函数封装系统是一个设计精良、高度自动化且可扩展的工程典范。它通过拦截、翻译、再调用的核心模式,以及巧妙的命名约定、自动化代码生成和回调处理机制,成功地解决了跨架构函数调用的难题。正是这个系统,使得 Box64 能够以接近原生的性能运行依赖大量系统库的复杂应用程序和游戏,是其实现高性能和高兼容性的关键所在。
动态重编译器(Dynarec)
Box64 的动态重编译器(Dynarec)是其实现高性能的核心引擎。它的根本目标是将 x86_64 指令实时(On-the-fly)翻译成宿主架构(如 ARM64, RISC-V 64)的原生机器码,从而避免逐条指令解释执行的巨大开销。
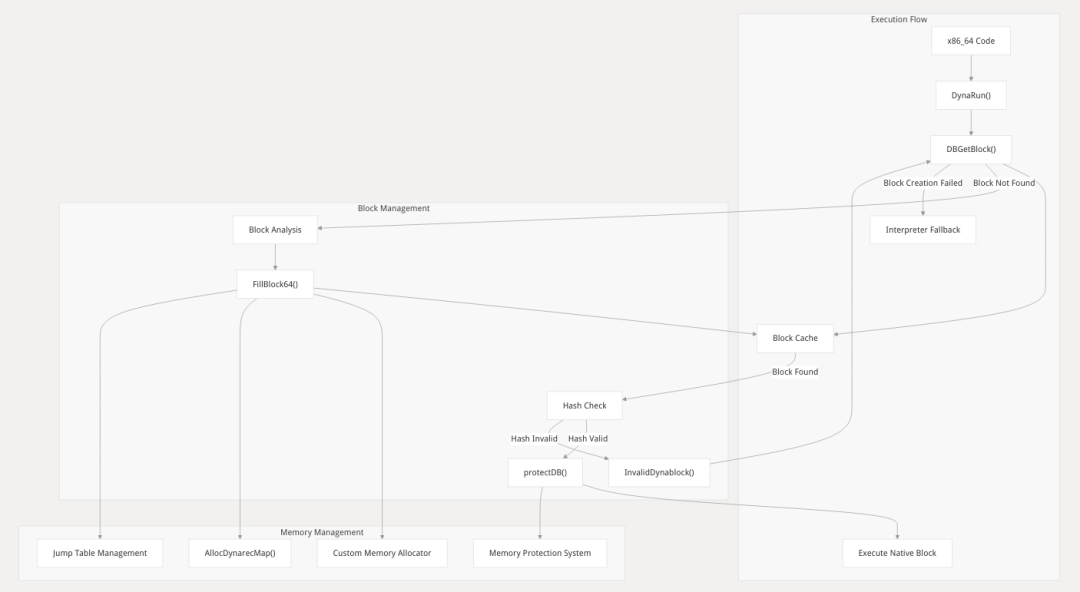
该系统通过将 x86_64 代码块一次性翻译、缓存并重复执行,实现了接近原生的运行速度,是 Box64 能够高效运行计算密集型应用和游戏的关键。
Dynarec 的工作流程围绕着一个基本单元——动态块(dynablock)——展开。一个 dynablock 包含了翻译后的原生代码以及管理其生命周期的元数据。
整个执行流程由 DynaRun() 函数协调,具体如下:
1. 启动与检查: 当需要执行一段 x86_64 代码时,DynaRun() 函数被调用。
2. 块查找与验证 (DBGetBlock):
-
系统首先在缓存(Cache)中查找是否已存在对应 x86_64 地址的 dynablock。
-
如果找到,会检查其哈希值(Hash),以验证原始的 x86_64 代码自上次翻译以来是否被修改。
-
如果块存在且哈希有效,则直接跳转执行缓存中的原生代码,流程结束。这是最快路径。
3. 块创建与翻译 (FillBlock64):
-
如果找不到块,或者块因代码被修改而失效,系统将进入创建流程。
-
FillBlock64() 函数(具体实现因架构而异)开始分析从当前指令指针(RIP)开始的 x86_64 代码。
-
它会分析指令流,直到遇到一个控制流改变指令(如 JMP, RET, CALL)或其他块结束条件,以此确定块的边界。
-
接着,它为原生代码分配内存,并逐条将 x86_64 指令翻译成功能等价的宿主架构原生指令。
4. 执行与后备:
-
新创建的 dynablock 被缓存起来,然后立即执行。
-
如果在翻译过程中遇到无法处理的复杂或未知指令,Dynarec 会失败。此时,系统会优雅地回退到解释器(Interpreter)模式,逐条模拟执行这些指令,以保证兼容性。
小结
Box64 是一个为 ARM64、RISC-V 64 等非 x86_64 平台设计的高性能、高兼容性的 x86_64 用户空间模拟器。它并非一个完整的虚拟机,而是一个专注于在宿主操作系统上直接运行 x86_64 Linux 程序的智能翻译层。
其卓越性能与高兼容性的核心在于两大关键技术:
-
动态重编译 (Dynamic Recompilation - Dynarec): 实时地将 x86_64 的 CPU 指令翻译为宿主平台(如 ARM64)的原生机器码。通过缓存和复用已翻译的代码块,它避免了低效的逐条解释执行,从而使计算密集型任务能以接近原生的速度运行。
-
原生库集成 (Native Library Integration): 通过精巧的函数封装系统 (Function Wrapping System),Box64 允许被模拟的 x86_64 程序直接调用宿主系统上已有的、经过硬件加速的原生函数库(如 OpenGL, Vulkan, 音频库等)。这极大地提升了图形、游戏和多媒体应用的性能与兼容性。
这种架构使得 Box64 不仅能高效运行各类 Linux 桌面应用,更关键的是,它能够与 Wine 协同工作,成功地在 ARM64 等设备上运行大量 Windows 应用和游戏,极大地扩展了这些平台的软件生态。此外,它还通过实验性的 32 位兼容层,具备了运行 32 位程序的能力。
当然,Box64 并非完美无缺。它尚未实现所有的 x86_64 CPU 特性,部分特定应用可能需要手动配置以达到最佳性能,并且最终的运行效果依然受限于宿主系统的硬件能力。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)