ARM 学习笔记——内存类型
参考文献:《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
参考文献:《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
《ARM Cortex-A (ARMv7-A) Series Programmer’s Guide》
1、内存类型
ARMv7-A 处理器中,将 Memory 定义为几种类型(Memory Type):
- Strongly-ordered
- Normal
- Device
2、Normal memory
2.1 Non-shareable
Normal memory must also be designated either as Shareable or Non-Shareable. A region of Normal memory with the Non-Shareable attribute is one that is used only by this core. There is no requirement for the core to make accesses to this location coherent with other cores. If other cores do share this memory, any coherency issues must be handled in software. For example, this can be done by having individual cores perform cache maintenance and barrier operations.
——————《ARM Cortex-A (ARMv7-A) Series Programmer’s Guide》
对于 Normal memory 类型的内存区域:
-
必须指定为 Shareable 或 Non-Shareable
-
如果它被标记为 Non-Shareable:
- 硬件不会保证这块内存在多个核心之间的数据一致性
- 默认认为只有当前核心在使用这块内存
- 如果实际上多个核心访问这块内存,那就必须靠软件来保证一致性,比如通过缓存管理(清除/失效)、内存屏障(DMB/DSB/ISB)、通信协议等手段来同步数据
简单来说,就是 Non-Shareable = 禁用硬件缓存一致性协议(MESI/MOESI)等
既然 Non-Shareable 需要手动维护一致性,那它存在的意义和优势是什么?
实际上,Non-Shareable 并不是没有用,而是出于以下几个考虑,它在某些场景下非常有意义:
✅ 一、性能更高
在多核系统中,如果你使用 Shareable memory(尤其是 SMP 系统中的 Inner Shareable):
- 每次访问缓存行都可能触发硬件级的 cache coherency 协议(如 MESI、MOESI 等);
- 这会引入额外的 总线/互联传输负担 和 延迟;
- 也可能导致 cache line bouncing,尤其当多个核频繁修改同一个变量时。
而使用 Non-Shareable memory:
- 硬件默认只在当前核心访问,不涉及其它核;
- 避免了不必要的 cache coherency 操作;
- 访问更快,cache 命中率更高,延迟更低;
- 适合性能敏感、访问频繁、无需共享的私有数据。
✅ 二、明确分工与控制
Non-Shareable 强制开发者:
- 明确哪些内存区域是只在本核使用的;
- 哪些区域需要小心处理共享和同步;
- 有助于提升系统结构的清晰度和可维护性;
- 对一些实时性要求高的系统(RTOS)非常有用,避免因不必要的一致性导致时间不确定性。
2.2 Inner Shareable, and Outer Shareable
A region of Normal memory with the Shareable attribute is one for which data accesses to memory by different observers within the same shareability domain are coherent
——————《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
具有 Shareable 属性的 Normal memory 区域,其特点是:在同一共享域内的不同观察者对该内存的数据访问是一致的。
在 ARMv7 架构中,可共享属性(Shareability Attributes)用于定义一组观察者(Observers),使得 data or unified caches 对特定访问透明化。这些观察者的集合被称为可共享域(Shareability Domains),其具体行为由系统实现决定。以下通过示例说明其应用场景:
举一个案例:
某虚拟内存系统架构(VMSA)的实现包含 two clusters of processors,需满足以下要求:
- 对于每个 clusters :若数据访问标记为 Inner Shareable,则集群内所有处理器的 data or unified caches 对该访问透明(即缓存一致性自动维护)
- 两个 cluster 之间:
- 仅标记为 Inner Shareable 的访问无法跨集群维护缓存透明性
- 标记为 Outer Shareable 的访问则能在两个集群间实现缓存透明。此时,每个集群构成独立的 Inner Shareable 域,而整个子系统属于同一个 Outer Shareable 域。
若系统包含多个此类子系统,且子系统间的缓存互不透明,则每个子系统将形成独立的 Outer Shareable 域。
为什么需要分层设计?
设置两个层次的可共享性属性(Inner Shareable 和 Outer Shareable)意味着系统设计者可以减少对于不需要参与 Outer Shareable 域的共享内存区域的性能与功耗开销。
- 多级共享域的设计允许系统更灵活地控制共享粒度;
- 如果某块内存只在一个 CPU cluster 内共享,就设置为 Inner Shareable,避免跨 cluster 的 coherency 同步开销;
- 避免不必要的 Outer Shareable 标记 → 减少 coherency 机制触发 → 更高效、节能。
In a VMSA implementation, for Shareable Normal memory, whether there is a distinction between Inner Shareable and Outer Shareable is IMPLEMENTATION DEFINED
——————《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
需要注意的是,在 VMSA(虚拟内存系统架构)的实现中,对于 Shareable 类型的 Normal memory,是否区分 Inner Shareable 和 Outer Shareable 是由具体实现决定的(实现自定义)。
对于 Shareable 类型的 Normal memory,Load-Exclusive 和 Store-Exclusive(即 LDREX/STREX)同步原语会考虑到同一 shareability 域内多个观察者可能同时访问该地址的情况
- ARM 的原子指令(如 LDREX/STREX)依赖于共享域概念;
- 若两个核在同一 Inner Shareable 域内,它们的原子操作会被视为相关;
- 如果不在同一共享域中,它们可能不会观察到彼此的修改 → 可能导致同步失败。
系统设计者可以使用 Shareable 属性来指定哪些 Normal memory 区域需要具备缓存一致性的要求。但为了便于软件移植,软件开发人员不能因为某块内存被标记为 Non-shareable,就假设多个处理器之间访问该内存一定是非一致性的。
- 也就是说,Non-shareable ≠ 一定不一致;
- 有些系统中,Non-shareable 的内存可能也通过某种方式被多个核缓存一致;
- 所以不能依赖 Non-shareable 来推导“多个核访问时不一致”的行为;
This architecture is written with an expectation that all processors using the same operating system or hypervisor are in the same Inner Shareable shareability domain
——————《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
本架构(ARMv7-A)假设:所有运行在同一操作系统或同一 hypervisor 下的处理器,属于同一个 Inner Shareable 共享域。
2.3 Write-Through、Write-Back、Non-cacheable
在 ARMv7 架构中,除了 Shareability(可共享性)(Outer Shareable / Inner Shareable / Non-shareable)之外,Normal Memory(普通内存) 还需要设置 Cacheability(缓存属性),以决定 CPU 如何缓存该内存区域。
缓存属性主要分为以下三种:
- Write-Through Cacheable.
- A cache in which when a cache hit occurs on a store access, the data is written both to the cache and to main memory.
This is normally done via a write buffer, to avoid slowing down the processor
- A cache in which when a cache hit occurs on a store access, the data is written both to the cache and to main memory.
- Write-Back Cacheable.
- A cache in which when a cache hit occurs on a store access, the data is only written to the cache. Data in the cache
can therefore be more up-to-date than data in main memory. Any such data is written back to main memory when
the cache line is cleaned or reallocated. Another common term for a write-back cache is a copy-back cache
- A cache in which when a cache hit occurs on a store access, the data is only written to the cache. Data in the cache
- Non-cacheable
- 这个比较好理解,就是内存不带 cache,即对这块内存的访问,不会经过 cache
In some cases, the use of Write-Through Cacheable or Non-cacheable regions of memory might provide a better mechanism for controlling coherency than the use of hardware coherency mechanisms or the use of cache maintenance routines
——————《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
在某些情况下,使用 Write-Through 缓存策略或 Non-cacheable 的内存区域,可能比依赖硬件缓存一致性机制或缓存维护指令,更适合作为控制一致性的一种机制。用合理的缓存策略(Memory Attributes)来“避免麻烦”,可能比“处理麻烦”更好。
3、 Device and Strongly-ordered memory
3.1 概念
在 ARMv7 架构中,设备内存(Device Memory) 和 强序内存(Strongly-ordered Memory) 通常用于映射内存映射外设(Memory-mapped Peripherals) 和 I/O 地址空间(I/O Locations)。
System peripherals will almost always be mapped as Device memory.
——————《ARM Cortex-A (ARMv7-A) Series Programmer’s Guide》
对于处理器显式访问标记为 Device 或 Strongly-ordered 的内存区域,需遵循以下规则:
- 访问大小严格匹配程序定义:所有访问必须按照程序中指定的数据宽度(如 8 位、16 位、32 位)执行,不可拆分或合并。
- 对 Device/Strongly-ordered 内存的每次访问(如 STR/LDR)必须作为一个完整单元执行。例如,32 位寄存器写入不可拆分为两个 16 位写入。
- 访问次数严格匹配程序定义:访问次数必须与程序指定的次数一致,不可因优化而增减。
- 编译器/硬件不得对这类内存进行访问合并(如合并相邻写操作)或冗余访问消除(如省略重复读操作)
硬件实现限制:
除非由于异常(Exception)(如中断、缺页)导致额外访问,否则处理器不得对 Device 或 Strongly-ordered 内存执行比程序顺序执行所规定的更多访问。本节将讨论异常对访问行为的允许影响。
从上面这些分析可以看出,ARMv7 对 Device/Strongly-ordered 内存的严格访问规则,确保了硬件寄存器和关键 I/O 操作的可预测性
下面再总结下,Device and Strongly-ordered memory 的一些特性:
- The architecture does not permit speculative data accesses to memory marked as Device or Strongly-ordered
- The architecture does not permit unaligned accesses to Strongly-ordered or Device memory
- Address locations marked as Device or Strongly-ordered are never held in a cache
- In the ARMv7 architecture, the core can re-order Normal memory accesses around Strongly-ordered or Device memory accesses
3.2 Device and Strongly-ordered 区别
第一个区别就是共享域的区别:
- a region of Device memory can be described as one of
- Outer Shareable Device memory.
- Inner Shareable Device memory.
- Non-shareable Device memory
- Strongly ordered memory regions are always shareable
关于 shareable,ARMv7 手册中有这样一段描述:
ARM deprecates the marking of Device memory with a shareability attribute other than Outer Shareable or Shareable. This means ARM strongly recommends that Device memory is never assigned a shareability attribute of Non-shareable or Inner Shareable
——————《ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition》
ARM 不建议你对 Device memory 设置为除了 “Outer Shareable” 或早期架构中通用的 “Shareable” 之外的任何 shareability 属性。尤其要避免使用 “Inner Shareable” 或 “Non-shareable”。
第二个区别就是完成时的区别:
The only architecturally-required difference between Device and
Strongly-ordered memory is that:
- A write to Strongly-ordered memory can complete only when it reaches the peripheral or memory component accessed by the write.
- A write to Device memory is permitted to complete before it reaches the peripheral or memory component accessed by the write.
上面这个说法是官方的意思,我理解一下,应该是 Strongly-ordered 不惜牺牲性能,去做保序的要求,一定要实际访问到外设,而 Device 类型的访问指令,可能还在路上(流水线中);
4、ARMv8 中的内存类型
与 ARMv7 不同的是,ARMv8 中将 Memory 定义为 2 种类型(Memory Type):
- Device
- Normal
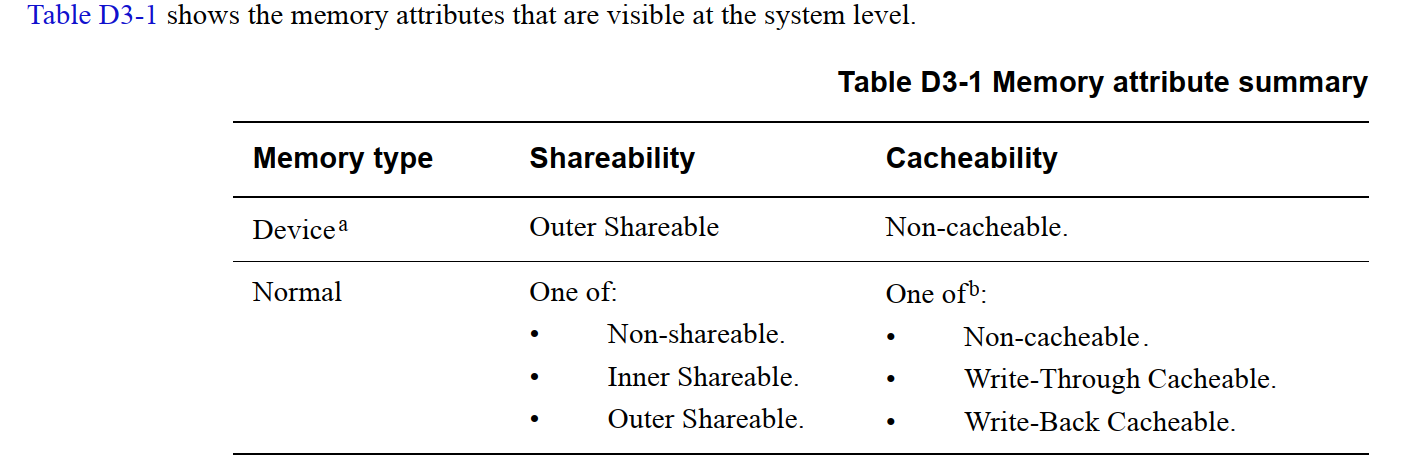
4.1 Normal
和 ARMv7 架构类似,这里不再赘述。
4.2 Device
ARMv8 中的 Device 内存属性,又可以细分:
- Gathering
- Reordering
- Early Write Acknowledgement hint

早期版本的 ARM 架构(ARMv7)定义了以下内存类型:
— Strongly-ordered memory(强序内存):这等同于 ARMv8 中的 Device-nGnRnE 内存类型。
— Device memory(设备内存):这等同于 ARMv8 中的 Device-nGnRE 内存类型。
4.2.1 Gathering
在设备(Device)内存类型中,内存属性字段包含以下两种取值:
- G:表示该内存位置具有 Gathering(聚集)属性。
- nG:表示该内存位置不具有 Gathering 属性,即为 non-Gathering(非聚集)。
什么是 Gathering 属性?
Gathering 属性决定了是否允许以下两类内存访问行为被合并(merge)为单次事务:
- 对同一内存地址的多个同类型访问(均为读或均为写)可被合并为一次事务;
- 对不同内存地址的多个同类型访问可被合并为一次总线或互连(interconnect)事务。
注意:上述规则同样适用于缓存写回(writeback)操作——无论是由自然驱逐(Natural eviction)触发,还是由缓存维护指令(如 DC CVAC)显式引发。
对于具有 Gathering 属性的内存类型:
- 上述两种合并行为是允许的,前提是必须遵守该内存区域所规定的访问顺序性(ordering)和一致性(coherency)规则。
- 换言之,只要程序无法观测到合并前后的行为差异(即符合 ARM 架构定义的“程序员可见行为”),硬件就可以自由进行聚集优化。
ARM 架构仅定义 程序员可见的行为(programmer-visible behavior)。因此,只要最终结果在程序视角下与未聚集的情况一致,硬件就可以自由实施 Gathering 优化。
对于 non-Gathering(nG)内存类型:
- 严格禁止上述任何一种合并行为。这意味着:
- 实际发生的内存访问次数必须与程序按顺序执行时产生的访问次数完全一致;
- 每次访问的大小必须与程序指定的访问大小一致(例如,一次 32 位 load 必须表现为一次 32 位访问)。
- 例外情况:对于多寄存器加载/存储指令(如 LDM/STM),内存系统无需识别具体访问了哪些寄存器对应的内存元素
关键限制条件(即使对于 G 属性也适用):
- 内存屏障(Memory Barrier)会阻止 Gathering
如果两个内存访问被一个对其生效的内存屏障(如 DMB 或 DSB)分隔(例如一个属于 Group A,另一个属于 Group B),则不允许在这两个访问之间进行 Gathering。 - Load-Acquire / Store-Release 指令禁止跨指令 Gathering
由 Load-Acquire 或 Store-Release 生成的访问,不能与其他访问进行 Gathering,即使它们类型相同、地址相近。 - non-Gathering 内存的读取必须直达终点设备
对 nG 属性内存的读操作 不能从缓存或中间缓冲区(如写合并缓冲区)返回数据,而必须直接从该地址对应的物理端点(如外设寄存器或物理内存)获取。这是为了确保 I/O 寄存器等关键设备状态的实时性和准确性。
4.2.2 Reordering
在 Device 内存类型中,内存属性字段包含以下两种取值:
- R:表示该内存位置具有 Reordering(重排序)属性。
- nR:表示该内存位置 不具有 Reordering 属性,即为 non-Reordering(非重排序)。
✅ 具有 Reordering 属性(R)的内存:
- 对该内存的访问 可以按照与 Normal Non-cacheable 内存相同的规则进行重排序。
- 换言之,其内存排序行为 等同于普通非缓存内存(Normal Non-cacheable),遵循 ARM 架构定义的弱序模型(参见手册 B2-84 页 “Memory ordering”)。
这意味着:在不违反数据依赖和显式内存屏障的前提下,硬件可对访问顺序进行优化调整。
❌ 具有 non-Reordering 属性(nR)的内存:
- 禁止重排序:所有访问到同一个外设(peripheral)的内存操作,必须严格按照程序顺序(program order)到达该外设。
- 此“外设”的范围由实现定义(IMPLEMENTATION DEFINED),通常指一个地址连续的设备功能块(例如一个 UART 控制器或 GPIO 控制器)。
- 关键要求:即使混合使用不同 Device 属性(如 Device-nGnRE 和 Device-nGnRnE)访问同一外设,这些访问也必须按程序顺序抵达。
📌 注意:如果访问的目标不是 peripheral(例如普通 RAM 区域被错误标记为 Device-nR),则此属性不施加任何排序约束
non-Reordering 属性的作用边界:
non-Reordering 仅保证对同一外设的访问顺序,不提供以下额外排序保证:
- Accesses with the non-Reordering attribute and accesses with the Reordering attribute
- Accesses with the non-Reordering attribute and accesses to Normal memory.
- Accesses with the non-Reordering attribute and accesses to different peripherals of IMPLEMENTATION DEFINED size
- The non-Reordering attribute has no effect on the ordering of cache maintenance instructions, even if the memory location specified in the instruction has the non-Reordering attribute
这意味着:若需跨内存类型或跨设备保序,必须显式插入内存屏障(如 DMB)。
4.2.3 Early Write Acknowledgement hint
在 Device 内存类型中,内存属性字段包含以下两种取值:
- E:表示该内存位置具有 Early Write Acknowledgement(提前写应答)属性。
- nE:表示该内存位置具有 No Early Write Acknowledgement(禁止提前写应答)属性。
📌 注意:这里只是一个提示(hint)的作用,而非强制性语义约束——ARM 架构将其定义为对平台内存系统的建议行为。
✅ No Early Write Acknowledgement(nE)
- 推荐行为:只有写操作的最终端点(endpoint)——通常是外设寄存器或物理内存——才能返回写完成应答(write acknowledgement)。
- 中间组件(如互连、写缓冲区、桥接器等)不得提前应答该写操作。
- 关键影响:当执行 DSB(Data Synchronization Barrier)指令时,必须等待该写操作真正抵达终点后才解除阻塞。
💡 典型场景:向一个 UART 的发送寄存器写入数据。若使用 nE,DSB 可确保数据已送达 UART 控制器(而非仅进入 SoC
内部缓冲区),这对时序敏感的硬件交互至关重要。
⚪ Early Write Acknowledgement(E)
- 无特殊要求:平台可自由选择在任意层级(如 L2 缓存旁路缓冲区、互连节点)提前返回写应答。
- 这是默认更宽松、更高性能的模式,适用于对写完成时机不敏感的场景。
5、总结
5.1 关于 Inner Shareable, and Outer Shareable 的疑惑
关于 Inner Shareable, and Outer Shareable 属性,初学者经常会疑惑,这两个属性是从什么角度去定义的?从上面的分析来看,是从 cahce 一致性角度来定义的?直接上结论:
Shareable 确实和 cache 一致性密切相关。但 Shareable 的概念并不仅限于 Normal memory,它是一种通信语义或访问语义的定义,用来告诉处理器系统(包括缓存子系统、互联、总线和外设)这个区域是否可能被多个观察者访问。
例如,Device 类型的 memory,虽然不带 cache,但是也有 Inner Shareable, and Outer Shareable 属性。
- Device memory 是不能被缓存的,所以 Shareable 与否不会影响缓存行为。
- 但是在 Barrier(内存屏障)语义中,Shareable 的 Device memory 和 Non-shareable 的 Device memory 是不一样的:
DMB等指令中的 Shareable,就是在说:“这个屏障要作用于 Shareable 范围内所有可能看到这个地址空间的主体。”- 比如 CPU 和 DMA 共享一个外设寄存器区,这个区域应该标记为 Device + Shareable,这样
DMB可以保证这些外设访问的顺序一致性。
ARM 中的内存屏障指令 DMB
#define dma_wmb() dmb(oshst)
#define __smp_wmb() dmb(ishst)
- ISHST
DMB operation that waits only for stores to complete, and only to the inner shareable domain - OSHST
DMB operation that waits only for stores to complete, and only to the outer shareable domain
我们要明白,Shareable 并不等于“能被多个主体访问”,而是告诉系统:这个 memory 区域的访问顺序、一致性、barrier 等行为可能涉及多个 observer,系统必须尊重这点。
5.2 注意项
有一点非常重要:内存类型(如 Normal、Device、Strongly-Ordered)并不会对整个指令流的执行顺序产生可靠影响,它们只对内存访问的顺序产生影响。
- 指令的执行顺序 ≠ 内存访问的顺序
- 内存类型(如 Device、Normal)只能控制 load/store 的顺序
- 想要确保 某个写操作之后再执行某条指令 → 你得用 DMB, DSB, ISB 这类内存屏障指令
- 千万不要以为 “把内存设成 Strongly-Ordered,就等于所有指令顺序都被保留了” ——这只是内存访问顺序的保证,不是执行语义的全局保证

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)