计算机组成原理(4) - 定点数的编码表示
计算机中数值的表示主要分为定点数和浮点数两种形式。定点数的小数点位置固定,分为定点整数和定点小数,具有运算简单、硬件成本低的优点,但表示范围和精度有限,适用于嵌入式系统等场景。浮点数采用科学计数法思想,通过阶码和尾数动态调整小数点位置,能表示极大或极小的数,精度较高但运算复杂,广泛应用于科学计算等领域。有符号数的表示经历了从原码、反码到补码的演变过程,补码因统一了0的表示、简化了运算而成为现代计算
一 定点数和浮点数
在计算机中,数值的存储和表示方式分为定点数和浮点数,两者的核心区别在于小数点的位置是否固定。这一差异直接影响了它们的表示范围、精度及适用场景。
1、定点数(Fixed-Point Number)
定义:定点数是指小数点位置固定不变的机器数,通过预设小数点的位置来表示整数或小数。
由于计算机中没有实际的 “小数点” 符号,小数点的位置是人为约定的(仅在计算时逻辑上存在)。
定点数的两种约定形式
-
定点整数:约定小数点在数值的最右端,即所有位均表示整数部分。
例:8 位定点整数的格式为符号位 整数位 整数位 ... 整数位 .(小数点隐含在最后)。
如机器数01001001表示真值+73(1001001₂=73₁₀)。 -
定点小数:约定小数点在符号位与数值位之间,即所有位均表示小数部分。
例:8 位定点小数的格式为符号位 . 小数位 小数位 ... 小数位。
如机器数10110000表示真值-0.375(0110000₂=24/64=0.375,符号位 1 表示负)。
特点
- 优点:运算规则简单,硬件实现成本低。
- 缺点:表示范围有限(受字长限制,整数部分位数固定),精度较低(小数部分位数固定)。
- 适用场景:早期计算机、嵌入式系统等对精度要求不高,且数值范围较固定的场景。
2、浮点数(Floating-Point Number)
定义:浮点数是指小数点位置不固定的机器数,通过 “科学计数法” 的思想表示数值,可灵活表示极大或极小的数。
其核心是将数值拆分为阶码(表示小数点的偏移量)和尾数(表示有效数字),类似十进制的 N = M × 10^E(如 123.45 = 1.2345 × 10²)。
浮点数的格式(以 IEEE 754 标准为例)
计算机中浮点数通常遵循IEEE 754 标准,分为单精度(32 位)和双精度(64 位):
-
单精度(32 位):1 位符号位 + 8 位阶码 + 23 位尾数
-
双精度(64 位):1 位符号位 + 11 位阶码 + 52 位尾数
- 符号位:0 表示正,1 表示负(与定点数一致)。
- 阶码:表示指数部分,通常用移码(偏移量)表示(避免正负阶码的处理问题)。
- 尾数:表示有效数字,通常为规范化形式(整数位为 1,隐含不存储,节省 1 位精度)。
例:单精度浮点数
0 10000001 01000000000000000000000表示:- 符号位 0(正),阶码 10000001(对应十进制 129,偏移量 127,实际阶码 = 129-127=2),尾数 010...(隐含整数位 1,即 1.01₂=1.25₁₀),因此真值 = 1.25×2²=5.0。
特点
- 优点:表示范围极大(阶码决定范围),精度较高(尾数位数多),能同时表示很大和很小的数。
- 缺点:运算规则复杂(需对齐阶码),硬件实现成本高,存在精度损失(部分小数无法精确表示,如 0.1)。
- 适用场景:科学计算、工程模拟等需要处理大范围数值或高精度小数的场景(如 PC、服务器)。
定点数与浮点数的对比
| 对比维度 | 定点数 | 浮点数 |
|---|---|---|
| 小数点位置 | 固定(整数末尾或符号位后) | 不固定(由阶码动态调整) |
| 表示范围 | 小(受字长和小数点位置限制) | 大(阶码扩展了范围) |
| 精度 | 低(小数位数固定) | 高(尾数位数多,支持规范化) |
| 运算复杂度 | 简单(直接加减乘除) | 复杂(需先对齐阶码) |
| 硬件成本 | 低 | 高 |
| 典型应用 | 嵌入式系统、整数运算 | 科学计算、图形处理、通用计算机 |
总结
- 定点数适合范围固定、精度要求低的场景,实现简单;
- 浮点数适合范围广、精度要求高的场景,灵活性强但实现复杂;
- 两者本质是通过不同的小数点处理方式,平衡计算机的存储效率、运算能力和应用需求。
理解定点数与浮点数,是掌握计算机数值运算和存储原理的基础,尤其在底层编程、硬件设计中至关重要。
二 定点数的表示
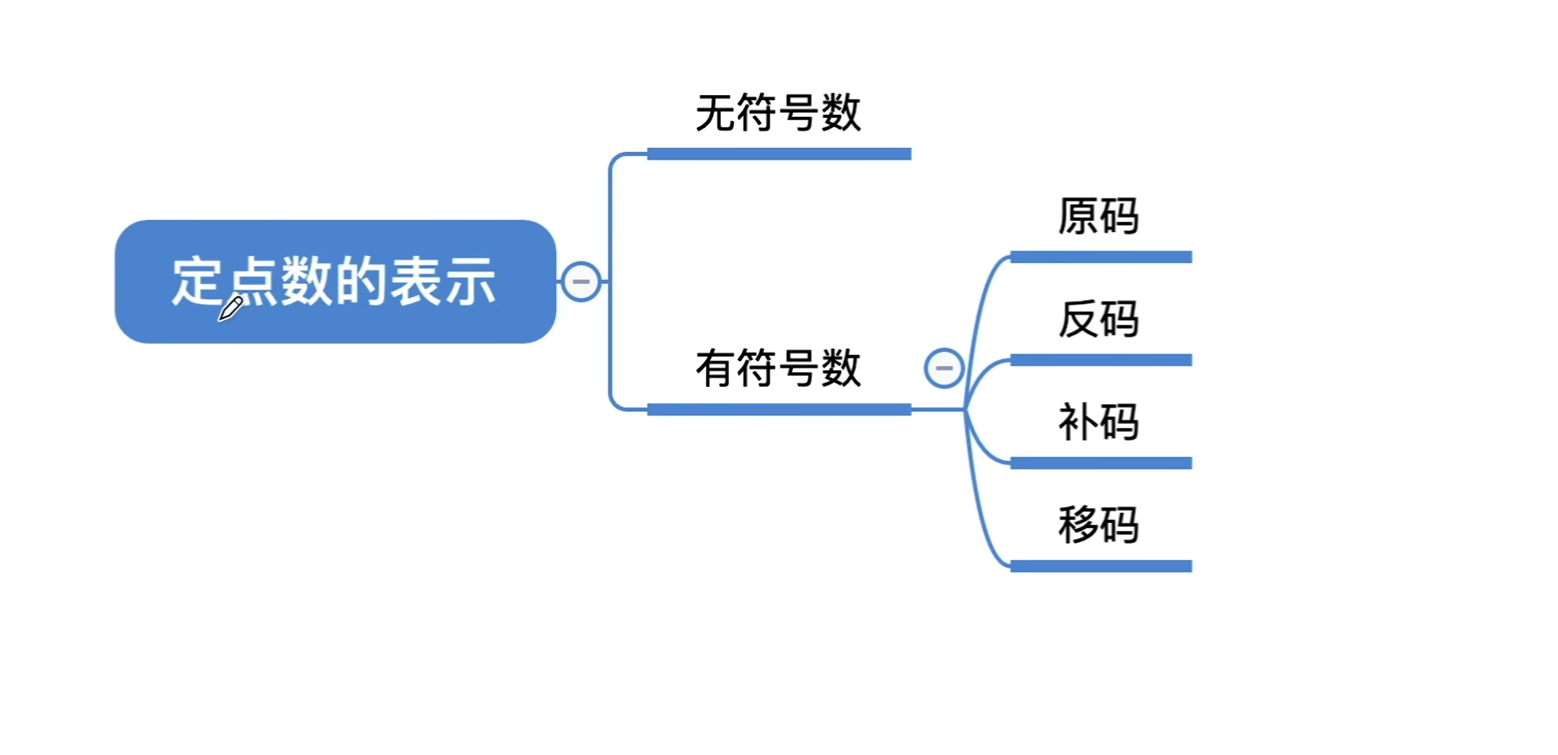
1. 无符号数
表示
无符号数是计算机中数值表示的一种基础形式,其核心特点是没有符号位,所有位均用于表示数值的大小,因此只能表示非负整数(0 及正整数)。这种表示方式简单直接,广泛应用于计数、地址编码、数据存储等场景。
-
定义:无符号数仅包含数值部分,不区分正负,所有二进制位均为 “数值位”,用于表示数值的绝对值。
-
格式:假设机器字长为
n位(如 8 位、16 位、32 位等),则无符号数的每一位(从最低位b₀到最高位bₙ₋₁)均参与数值计算,遵循二进制计数规则(每位的权值为2ⁱ,i为位序号,从 0 开始)。例如,8 位无符号数的格式为:
b₇ b₆ b₅ b₄ b₃ b₂ b₁ b₀,其中每一位bᵢ的权值为2ⁱ(b₀权值为2⁰=1,b₇权值为2⁷=128)。
表示范围
无符号数的表示范围由机器字长 n 决定,其最小值为 0(所有位均为 0),最大值为 2ⁿ - 1(所有位均为 1)。
机器字长指的是计算机 CPU 一次能直接处理的二进制数据的位数,单位为 “位(bit)”。它由 CPU 内部寄存器(如通用寄存器、累加器)的位数、运算器(ALU)的运算位数决定,是 CPU 硬件设计时固定的参数。
例如:
- 8 位微处理器(如早期的 Intel 8080)的机器字长为 8 位;
- 32 位 CPU(如 Intel Pentium III)的机器字长为 32 位;
- 现代主流 CPU(如 Intel Core i7、AMD Ryzen)多为 64 位机器字长。
不同字长的无符号数表示范围如下表:
| 机器字长(n 位) | 最小值 | 最大值(2ⁿ - 1) |
可表示的数值总数 |
|---|---|---|---|
| 8 位 | 0 | 255 | 256 |
| 16 位 | 0 | 65535 | 65536 |
| 32 位 | 0 | 4294967295 | 4294967296 |
| 64 位 | 0 | 18446744073709551615 | 18446744073709551616 |
2. 有符号数
在计算机中,有符号数是指需要表示正负的数据(如整数、定点小数等)。由于计算机只能处理二进制,需要通过特定的编码规则将符号(正 / 负)与数值部分结合,形成有符号数的机器表示。常见的编码方式包括原码、反码、补码、移码 其中补码是现代计算机中最常用的形式。
一、有符号数的符号表示
无论采用哪种编码,有符号数的最高位(最左边的位)均被规定为符号位:
- 符号位为
0时,表示正数; - 符号位为
1时,表示负数。
符号位之外的其他位称为数值位,用于表示数据的绝对值大小。
例如,在 8 位有符号数中:
- 最高位(第 7 位)为符号位,第 0-6 位为数值位;
- 32 位有符号数中,第 31 位为符号位,第 0-30 位为数值位。
二、三种编码方式的规则(以 n 位有符号数为例)
1. 原码(True Form)
原码是最直观的编码方式,直接将符号位与数值的二进制绝对值结合。
- 正数原码:符号位为
0,数值位为该数绝对值的二进制表示; - 负数原码:符号位为
1,数值位为该数绝对值的二进制表示。
示例(8 位有符号数):
| 十进制数 | 二进制真值 | 原码表示 |
|---|---|---|
| +5 | +0000101 | 00000101 |
| -5 | -0000101 | 10000101 |
| +0 | +0000000 | 00000000 |
| -0 | -0000000 | 10000000 |
特点:
- 直观易懂,与人类对正负的认知一致;
- 存在缺陷:
+0和-0有两种不同表示(浪费一个编码),且直接进行减法运算时需额外处理符号(如比较大小、确定结果符号),运算电路复杂。
2. 反码(One's Complement)
反码是原码的一种 “变形”,主要用于辅助补码的计算,实际应用较少。
- 正数反码:与原码相同(符号位为 0,数值位不变);
- 负数反码:符号位不变(仍为 1),数值位按位取反(0 变 1,1 变 0)。
示例(8 位有符号数):
| 十进制数 | 原码 | 反码 |
|---|---|---|
| +5 | 00000101 | 00000101 |
| -5 | 10000101 | 11111010 |
| +0 | 00000000 | 00000000 |
| -0 | 10000000 | 11111111 |
特点:
- 解决了原码减法运算的部分问题(可通过 “负数反码” 将减法转为加法),但仍存在
+0和-0两种表示,且运算后可能需要 “循环进位” 修正结果,效率较低。
3. 补码(Two's Complement)
补码是现代计算机中表示有符号数的标准方式,彻底解决了原码和反码的缺陷,能统一处理加法和减法运算。
- 正数补码:与原码、反码相同(符号位为 0,数值位不变);
- 负数补码:符号位为 1,数值位为其绝对值的原码 “按位取反后加 1”(即 “反码 + 1”)。
示例(8 位有符号数):
| 十进制数 | 原码 | 反码 | 补码 | |
|---|---|---|---|---|
| +5 | 00000101 | 00000101 | 00000101 | |
| -5 | 10000101 | 11111010 | 11111011 | |
| +0 | 00000000 | 00000000 | 00000000 | |
| -0 | 10000000 | 11111111 | 00000000 | (补码中 + 0 和 - 0 统一为 00000000) |
补码的核心优势:
- 统一 0 的表示:补码中
+0和-0只有一种表示(全 0),节省了一个编码空间(如 8 位补码中,10000000可表示-128,扩大了表示范围)。 - 减法转加法:对于任意两个数
a和b,a - b可等价为a + (-b)的补码运算,无需额外设计减法电路,简化了 CPU 硬件。
例如:5 - 3 = 5 + (-3),用补码计算:5的补码:00000101-3的补码:11111101(计算过程:3的原码00000011→ 反码11111100→ 加 1 得11111101)- 相加:
00000101 + 11111101 = 100000010(8 位截断后为00000010,即2,结果正确)。
三 编码的演变过程
大家可能疑惑,为什么会有这么多码,这也是随着时代的发展,逐步演变进化来的,这一发展路径与早期计算机硬件技术的限制、运算需求的提升密切相关,反映了工程师对 “如何用最简单的硬件实现高效符号数运算” 的持续探索。
一、早期:原码的天然选择(1940-1950 年代)
计算机诞生初期(如 1946 年的 ENIAC),符号数的表示直接采用了原码,原因有二:
- 直观性:原码的逻辑与人类对 “正负” 的认知一致(符号位 + 绝对值),早期程序员和硬件设计师更容易理解和实现。
- 硬件限制:早期计算机的运算器(ALU)非常简单,主要针对无符号数设计。若要处理有符号数,原码的实现最直接 —— 只需在无符号数的基础上增加一个符号位,运算时单独处理符号即可。
但原码的缺陷很快暴露:减法运算需要复杂的逻辑(判断符号、比较绝对值、单独处理结果符号),导致硬件电路庞大且运算速度慢。例如,ENIAC 处理一次减法的时间是加法的数倍,严重影响效率。
二、过渡:反码的尝试(1950 年代中期)
为解决原码减法的复杂性,工程师提出了反码(也称为 “对 1 的补码”)。其核心思路是:
- 负数的反码是 “原码符号位不变,数值位取反”,通过这种转换,可将减法运算转化为加法(
a - b = a + (-b的反码))。
这在一定程度上简化了硬件设计(无需单独的减法电路),但反码的缺陷依然明显:
- 0 的双重表示(
+0和-0)导致编码浪费,且可能引发运算歧义; - 循环进位问题:反码加法可能产生最高位进位,这个进位必须 “循环” 加到结果的最低位才能得到正确值,增加了硬件逻辑和运算延迟。
因此,反码仅在部分早期计算机(如 1950 年代的 UNIVAC I)中短暂使用,未成为主流。
三、成熟:补码的最终确立(1950 年代末至今)
补码(也称为 “对 2 的补码”)的概念并非凭空出现,其数学原理(模运算)早已存在,但直到 1950 年代末才被广泛应用于计算机设计。
关键转折点是 1955 年 IBM 工程师Andrew Donald Booth提出的 “补码乘法算法”,以及 1959 年 IBM 7090 计算机的成功应用 —— 这是第一台大规模采用补码的商用计算机。补码的优势彻底解决了前两种编码的痛点:
- 0 的唯一表示:消除了编码浪费,扩大了表示范围;
- 减法完全转化为加法:无需循环进位,硬件逻辑极简;
- 符号位自然参与运算:结果的符号位自动生成,无需额外处理。
这些优势使得补码在 1960 年代后逐渐成为行业标准,至今所有主流计算机(从微型机到超级计算机)均采用补码表示有符号数。
四、总结:演进的核心驱动力
从原码到反码再到补码的演进,本质是 **“硬件简化” 与 “运算效率” 的平衡过程 **:
- 原码:最直观,但硬件复杂、效率低;
- 反码:尝试简化减法,但仍有缺陷;
- 补码:牺牲了部分直观性,却实现了 “硬件最简单、运算最高效”,最终成为最优解。
这一过程也体现了计算机技术的发展逻辑 —— 不是 “最直观的方案” 获胜,而是 “最适合硬件实现、最高效” 的方案最终被广泛采用。补码的普及,为后续计算机运算能力的飞跃奠定了基础。
在实际计算机运算中,有符号数的确是以补码形式参与运算的,这是由计算机的硬件设计决定的。而负责 “转换” 和 “运算” 的核心部件,是 CPU 内部的运算器(ALU,算术逻辑单元) 以及相关的电路逻辑。下面详细解释这个过程:
五、计算机中 “补码运算” 的实际流程
当你在程序中写下类似 a + b 或 a - b 的运算时(其中 a、b 是有符号数),计算机的处理步骤大致如下:
-
数据的存储形式:补码
首先,程序中的有符号数(如int类型的-3、5等)在内存中存储时,就已经是补码形式了。- 例如,32 位
int类型的5在内存中是00000000 00000000 00000000 00000101(补码,与原码相同); -3的补码是11111111 11111111 11111111 11111101(通过原码取反加 1 得到)。
- 例如,32 位
-
运算时的处理:补码直接参与计算
当 CPU 执行运算时,会从内存中读取这些补码形式的数据,送入运算器(ALU)。- 对于加法:直接将两个数的补码相加(符号位也参与运算);
- 对于减法:将 “减数的补码” 转换为 “其相反数的补码”(即取反加 1),然后与被减数的补码相加(本质是
a - b = a + (-b)的补码运算)。
运算完成后,ALU 输出的结果依然是补码形式,再存入寄存器或内存。
-
结果的 “还原”:仅在需要人类阅读时
补码的结果对计算机而言可以直接使用(如继续参与下一次运算),但当需要将结果展示给人类(如打印到屏幕)时,程序会将补码转换为十进制(或其他人类可读形式)。这个转换由软件(如编程语言的运行时库)完成,而非硬件。
六、谁负责 “补码的转换与运算”?
核心角色是硬件电路,具体包括:
-
CPU 的运算器(ALU)
ALU 是执行算术运算(加减乘除)和逻辑运算(与或非)的核心部件,其内部电路直接设计为对补码进行运算。- 加法电路:接收两个补码,输出它们的和(补码形式);
- 减法电路:本质是 “加法电路 + 取反加 1 电路”—— 先将减数的补码取反加 1(得到
-b的补码),再送入加法电路与被减数相加。
这些电路是硬件层面固化的逻辑,不需要 “软件干预”,速度极快(纳秒级)。
-
数据通路与寄存器
寄存器是 CPU 内部的高速存储单元,用于临时存放运算数据。有符号数在寄存器中也以补码形式存储,确保送入 ALU 的数据始终是补码。 -
编译器的辅助
当你用高级语言(如 C、Python)编写代码时,不需要手动处理补码 —— 编译器会自动将源代码中的有符号数(如-5)转换为补码形式的机器码,存入内存。例如:- 写
int a = -3;时,编译器会生成指令,将-3的补码写入内存的a地址。
- 写
七、为什么我们感知不到补码的存在?
因为补码的转换和运算完全由硬件和编译器在底层完成,对程序员和用户是 “透明” 的:
- 你输入的是十进制数(如
-3 + 5),编译器负责转为补码; - CPU 用补码运算,得到的结果仍是补码;
- 当需要输出时(如
printf("%d", result)),运行时库会将补码转回十进制,展示给你。
整个过程中,补码就像 “计算机的秘密语言”,默默完成运算,却不需要你直接打交道。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)