Spring AI入门及浅实践,实战 Spring AI 调用大模型、提示词工程、对话记忆、Advisor 的使用
本文摘要: 文章系统介绍了Spring AI中关于提示词工程(Prompt)与对话记忆的核心知识点。提示词工程部分详解了提示词的基本概念与分类(基于角色/功能),并总结了14条优化技巧,强调清晰指令、结构化输出和任务拆解等关键点。对话记忆部分展示了通过ChatClient实现多轮对话的多种方式,包括构造器注入、建造者模式、不同响应格式(ChatResponse/实体对象/流式返回)以及动态提示词模
上一次写AI学习笔记已经好久之前了,温习温习,这一章讲讲关于Spring AI 调用大模型、对话记忆、Advisor、结构化输出、自定义对话记忆、Prompt 模板的相关知识点。
这一节并不是从零开始的实战,有好多的细节没有写到,当然我会陆续的补充一些必要的细节,至于项目的创建以及项目文件的架构,这篇文章不作为重点。这里会在此处写上需要的依赖,以及一个必要的配置,以便在大家观看并想要实践一些会话记忆的过程中不会太过吃力
Todo jdbc实现会话记忆,可能会单出一片博客介绍
快速跳转到你感兴趣的地方
实战必看(知识点学习选看)
这篇博客不是从零开始的博客,我把他看做我的学习笔记,但既然我写成了博客,就一定要保证我所学习的内容具有正确性和分享性质,所以虽然没有对项目进行展开介绍,但这里我列出需要的依赖和配置文件,看着这篇博客实战是不会有太大的问题的。
1. 本篇博客需要用到的依赖
| Group ID / Artifact ID | 用途 | 官方文档链接 |
|---|---|---|
org.springframework.boot:spring-boot-starter-web |
提供Spring Boot Web开发基础支持(如MVC、Tomcat内嵌服务器) | Spring Boot Web Starter |
org.springframework.boot:spring-boot-starter-test |
提供测试支持(JUnit、Mockito、Spring Test等) | Spring Boot Test Starter |
cn.hutool:hutool-all |
Java工具库(包含HTTP、加密、日期处理等工具) | Hutool Docs |
org.projectlombok:lombok |
通过注解简化Java代码(如自动生成Getter/Setter) | Lombok Project |
com.github.xiaoymin:knife4j-openapi3-jakarta-spring-boot-starter |
Swagger增强工具(生成API文档) | Knife4j Docs |
com.alibaba:dashscope-sdk-java |
阿里云灵积模型服务SDK(调用通义千问等AI模型) | DashScope SDK |
com.alibaba.cloud.ai:spring-ai-alibaba-starter |
Spring AI与阿里云AI服务的集成组件 | Spring AI Alibaba |
com.esotericsoftware:kryo |
高性能Java序列化库 | Kryo GitHub |
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.37</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.36</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.xiaoymin/knife4j-openapi3-jakarta-spring-boot-starter -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/dashscope-sdk-java -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>dashscope-sdk-java</artifactId>
<version>2.19.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba.cloud.ai/spring-ai-alibaba-starter -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.esotericsoftware/kryo -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>
</dependencies>
2. 本篇博客的所需要的配置文件
application.yml
spring:
application:
name: ${your_project_name}
profiles:
active: local
server:
port: 8123
servlet:
context-path: /api
# springdoc-openapi
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: 'default'
paths-to-match: '/**'
packages-to-scan: com.pigwantofly.myaiagent.controller
# knife4j
knife4j:
enable: true
setting:
language: zh_cn
application-local.yml
spring:
ai:
dashscope:
api-key: ${your_api_key}
chat:
options:
model: qwen-plus
3. 需要开通的AI平台
这里使用的是 阿里云百炼
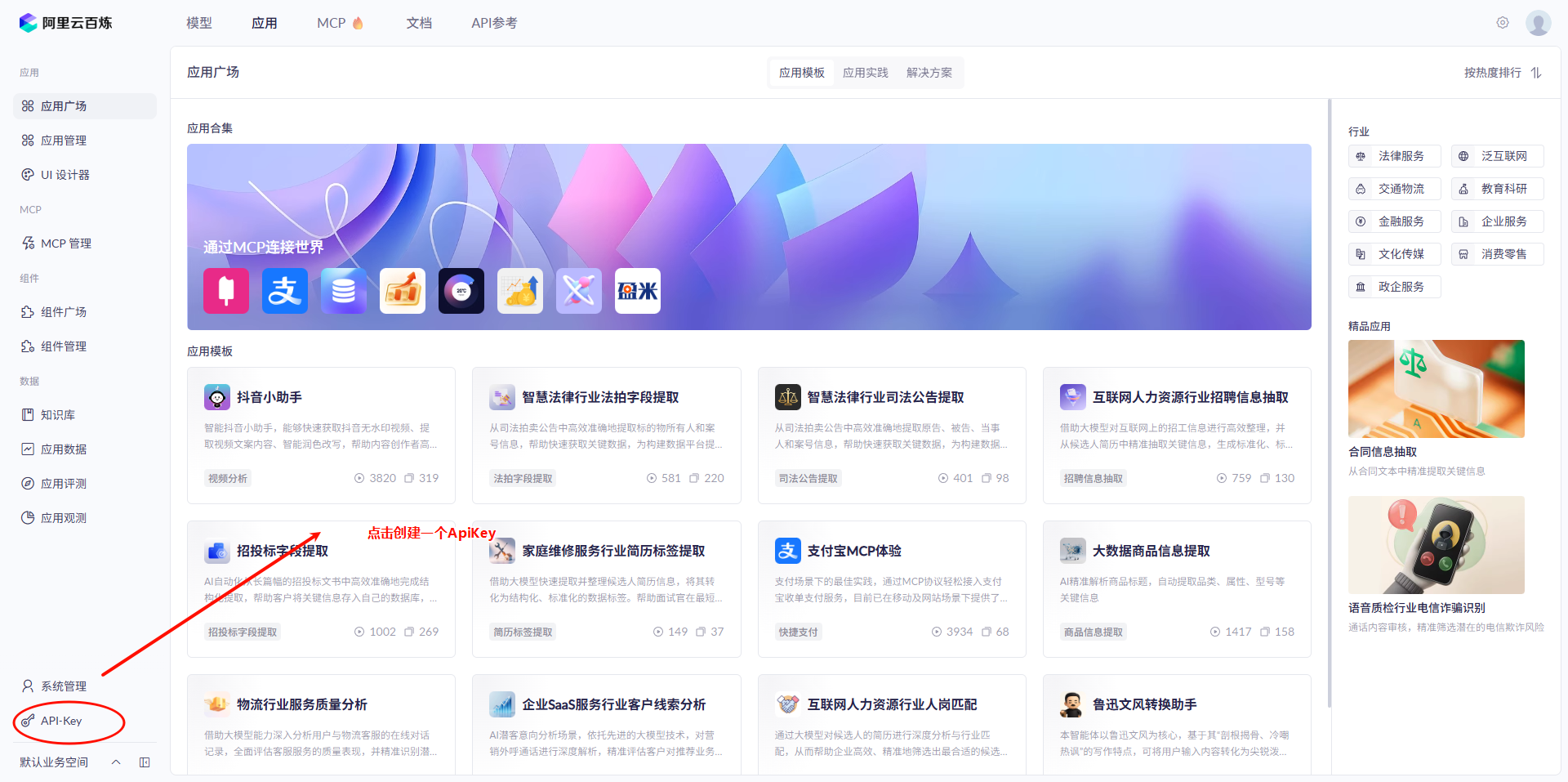
将自己的API_KEY替换到配置文件中,即可使用
一、提示词工程(Prompt)
1. 基本概念 (提示词、提示词工程)
提示词就是用户输入给AI的指令,但是写好提示词,是一件十分不容易的事情。准确的提示词能够让AI清楚的明白你所要达到的目的,从而生成满意的内容。
而提示词工程就是通过优化输入给AI模型的指令或问题(即“提示词”),以提升模型输出的准确性和相关性。其核心在于理解模型的行为模式,并通过结构化语言引导模型生成更符合预期的结果。
2. 分类 (基于角色、功能)
按照角色来分类可以分为如下三类:
- 用户 Prompt
是用户直接向 AI 提出的具体需求或问题,例如请求写诗、解答问题或生成代码。其核心是传递用户的具体意图,要求 AI 执行明确的任务。 - 系统 Prompt
是开发者或平台设定的隐藏指令,用于定义 AI 的角色、行为边界和回答风格。它不直接面向用户,但决定了 AI 如何响应用户 Prompt。例如,设定 AI 为“专业诗人”或“情感顾问”会直接影响生成内容的专业性、语气和结构。 - 助手 Prompt
在多轮对话中,助手 Prompt(即 AI 的历史回复)会成为后续交互的上下文。预设的助手消息能引导对话方向,例如在客服场景中提前声明服务范围。这种机制增强了对话连贯性,但也需注意避免因历史信息导致回答偏差。
按照功能来分可以分为:
- 指令型提示词: 明确告诉 AI 模型需要执行的任务,通常以命令式语句开头。
将上述中文文本翻译为英文
- 对话型提示词: 模拟自然对话,以问答形式与 AI 模型交互。
你认为AI会在取代人类吗?
- 创意型提示词 引导 AI 模型进行创意内容生成,如故事、诗歌、广告文案等。
写一首描写爱情的诗歌,赞美矢志不渝伟大的爱情
- 角色扮演提示词 让 AI 扮演特定角色或人物进行回答。
你是一位使用Java的程序员,使用java编写一个贪吃蛇游戏
- 少样本学习提示词 提供一些示例,引导 AI 理解所需的输出格式和风格。
将以下句子改写为正式商务语言:
示例1:
原句:这个想法不错。
改写:该提案展现了相当的潜力和创新性。
示例2:
原句:我们明天见。
改写:期待明日与您会面,继续我们的商务讨论。
现在请改写:这个价格太高了。
3. Prompt 优化技巧
网上和 Prompt 优化相关的资源非常丰富,几乎各大主流 AI 大模型和 AI 开发框架官方文档都有相关的介绍。Spring AI 提示工程指南,智谱 AI Prompt 设计指南等等
这里讲讲我学习整理后的一些心得
这是springAI的提示词编写教程中的重点,其实重点在三个方面:
在开发提示时,重要的是要集成几个关键组件,以确保清晰度和有效性:
- 指令:向AI提供清晰而直接的指令,类似于你与人沟通的方式。这种清晰度对于帮助AI“理解”预期内容至关重要。
- 外部环境:在必要时,为人工智能的反应提供相关的背景信息或具体指导。这种“外部环境”构成了提示,并帮助AI掌握整个场景。
- 用户输入:这是最直接的部分——用户的直接请求或问题
只要说明白这三点,就算是一个合适的提示词,但是是远远不够的,这里我用AI整理出了优化的重点,感兴趣的可以看一下。
清晰具体地定义需求,避免模糊指令,确保模型准确理解任务目标
明确指定输出格式,如JSON或特定结构,便于后续处理或解析
将复杂任务拆解为多个简单子任务,逐步递进完成,提高准确率
使用分隔符区分不同输入部分,避免混淆,如"""文本内容"""
在需要推理的问题中要求展示思维链,分步骤呈现推导过程
通过少样本示例引导模型模仿特定风格或行为模式
控制输出长度,设定字数限制或篇幅要求,确保简洁性
对长文本采用分段归纳再整合的方法,突破上下文限制
在技术性任务中先让模型自主生成答案,再进行评估验证
必要时隐藏详细推理过程,直接输出最终结果或结构化数据
利用外部工具增强能力,如API查询实时数据或访问知识库
在长对话中定期总结关键信息,保持上下文连贯性
角色扮演方式可提升专业领域回答的准确性
为系统提示设定明确的行为模式和任务规范### 优化Prompt的技巧
清晰具体地定义需求,避免模糊指令,确保模型准确理解任务目标
明确指定输出格式,如JSON或特定结构,便于后续处理或解析
将复杂任务拆解为多个简单子任务,逐步递进完成,提高准确率
使用分隔符区分不同输入部分,避免混淆,如"""文本内容"""
在需要推理的问题中要求展示思维链,分步骤呈现推导过程
通过少样本示例引导模型模仿特定风格或行为模式
控制输出长度,设定字数限制或篇幅要求,确保简洁性
对长文本采用分段归纳再整合的方法,突破上下文限制
在技术性任务中先让模型自主生成答案,再进行评估验证
必要时隐藏详细推理过程,直接输出最终结果或结构化数据
利用外部工具增强能力,如API查询实时数据或访问知识库
在长对话中定期总结关键信息,保持上下文连贯性
角色扮演方式可提升专业领域回答的准确性
为系统提示设定明确的行为模式和任务规范### 优化Prompt的技巧
清晰具体地定义需求,避免模糊指令,确保模型准确理解任务目标
明确指定输出格式,如JSON或特定结构,便于后续处理或解析
将复杂任务拆解为多个简单子任务,逐步递进完成,提高准确率
使用分隔符区分不同输入部分,避免混淆,如"""文本内容"""
在需要推理的问题中要求展示思维链,分步骤呈现推导过程
通过少样本示例引导模型模仿特定风格或行为模式
控制输出长度,设定字数限制或篇幅要求,确保简洁性
对长文本采用分段归纳再整合的方法,突破上下文限制
在技术性任务中先让模型自主生成答案,再进行评估验证
必要时隐藏详细推理过程,直接输出最终结果或结构化数据
利用外部工具增强能力,如API查询实时数据或访问知识库
在长对话中定期总结关键信息,保持上下文连贯性
角色扮演方式可提升专业领域回答的准确性
为系统提示设定明确的行为模式和任务规范
二、对话记忆(多轮对话实现)
1. 使用 Chat Client 实现基础对话功能
参考 Spring AI 的官方文档,了解到 Spring AI 提供了 ChatClient API 来和 AI 大模型交互。
ChatClient 是使用 ChatClient.Builder 对象创建的。您可以为任何 ChatModel Spring Boot 自动配置获取一个自动配置的 ChatClient.Builder 实例,也可以通过编程方式创建一个
这是官方提供的通过构造器注入的事例:
// 方式1:使用构造器注入
@RestController
class MyController {
private final ChatClient chatClient;
public MyController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/ai")
String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call()
.content();
}
}
使用建造者模式
// 方式2:使用建造者模式
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("you are a helpful AI")
.build();
ChatClient 支持多种响应格式,比如返回 ChatResponse 对象、返回实体对象、流式返回:
// ChatClient支持多种响应格式
// 1. 返回 ChatResponse 对象(包含元数据如 token 使用量)
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();
// 2. 返回实体对象(自动将 AI 输出映射为 Java 对象)
// 2.1 返回单个实体
record ActorFilms(String actor, List<String> movies) {}
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);
// 2.2 返回泛型集合
List<ActorFilms> multipleActors = chatClient.prompt()
.user("Generate filmography for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {});
// 3. 流式返回(适用于打字机效果)
Flux<String> streamResponse = chatClient.prompt()
.user("Tell me a story")
.stream()
.content();
// 也可以流式返回ChatResponse
Flux<ChatResponse> streamWithMetadata = chatClient.prompt()
.user("Tell me a story")
.stream()
.chatResponse();
可以给 ChatClient 设置默认参数,比如系统提示词,还可以在对话时动态更改系统提示词的变量,类似模板的概念:
// 定义默认系统提示词
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
// 对话时动态更改系统提示词的变量
chatClient.prompt()
.system(sp -> sp.param("voice", voice))
.user(message)
.call()
.content());
2. Advisor 顾问的使用
Advisor在Spring AI中扮演着类似AOP(面向切面编程)中顾问的角色,用于在 AI 模型调用前后添加逻辑以增强 AI 的能力。它允许开发者在不修改核心代码的情况下,对AI请求进行预处理或后处理,例如日志记录、对话记忆、RAG等。
- 前置增强:调用 AI 前改写一下 Prompt 提示词、检查一下提示词是否安全
- 后置增强:调用 AI 后记录一下日志、处理一下返回的结果
比如对话记忆顾问 MessageChatMemoryAdvisor 可以帮助我们实现多轮对话能力,省去了自己维护对话列表的麻烦。
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // 对话记忆 advisor
new QuestionAnswerAdvisor(vectorStore) // RAG 检索增强 advisor
)
.build();
String response = this.chatClient.prompt()
// 对话时动态设定拦截器参数,比如指定对话记忆的 id 和长度
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(userText)
.call()
.content();
Advisors 的原理图如下: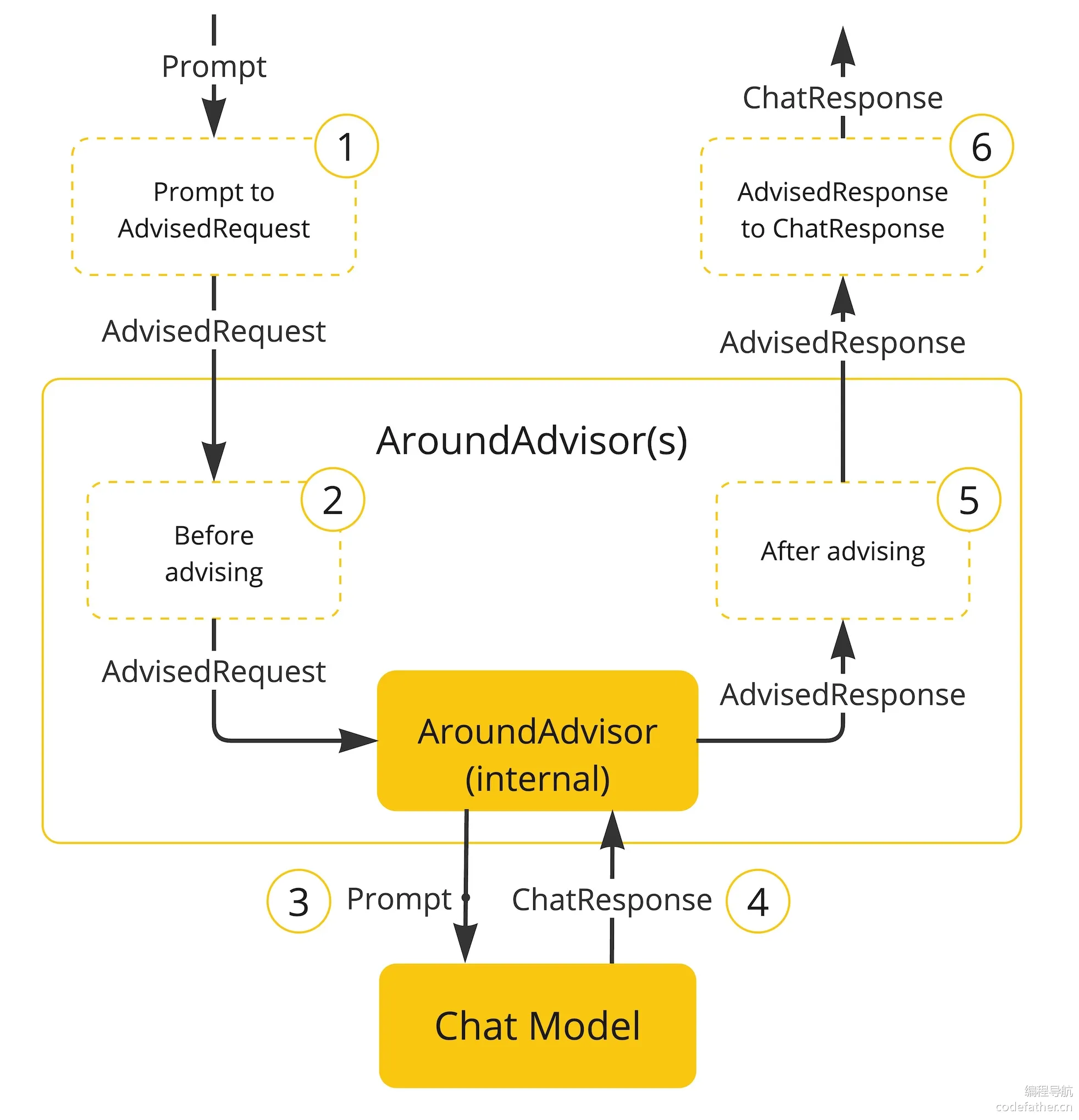

实际开发中,往往我们会用到多个拦截器,组合在一起相当于一条拦截器链条(责任链模式的设计思想)。每个拦截器是有顺序的,通过 getOrder() 方法获取到顺序,得到的值越低,越优先执行。
想要实现对话记忆功能,可以使用 Spring AI 的 ChatMemoryAdvisor,它主要有几种内置的实现方式:
- MessageChatMemoryAdvisor:从记忆中检索历史对话,并将其作为消息集合添加到提示词中
- PromptChatMemoryAdvisor:从记忆中检索历史对话,并将其添加到提示词的系统文本中
- VectorStoreChatMemoryAdvisor:可以用向量数据库来存储检索历史对话
MessageChatMemoryAdvisor 和 PromptChatMemoryAdvisor 用法类似,但是略有一些区别:
MessageChatMemoryAdvisor将对话历史作为一系列独立的消息添加到提示中,保留原始对话的完整结构,包括每条消息的角色标识(用户、助手、系统)
[
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么我能帮助你的吗?"},
{"role": "user", "content": "讲个笑话"}
]
PromptChatMemoryAdvisor将对话历史添加到提示词的系统文本部分,因此可能会失去原始的消息边界。
以下是之前的对话历史:
用户: 你好
助手: 你好!有什么我能帮助你的吗?
用户: 讲个笑话
现在请继续回答用户的问题。
一般情况下,更建议使用 MessageChatMemoryAdvisor 更符合大多数现代 LLM 的对话模型设计,能更好地保持上下文连贯性。
使用 Chat Memory构造ChatMemoryAdvisor
上述 ChatMemoryAdvisor 都依赖 Chat Memory 进行构造,Chat Memory 负责历史对话的存储,定义了保存消息、查询消息、清空消息历史的方法。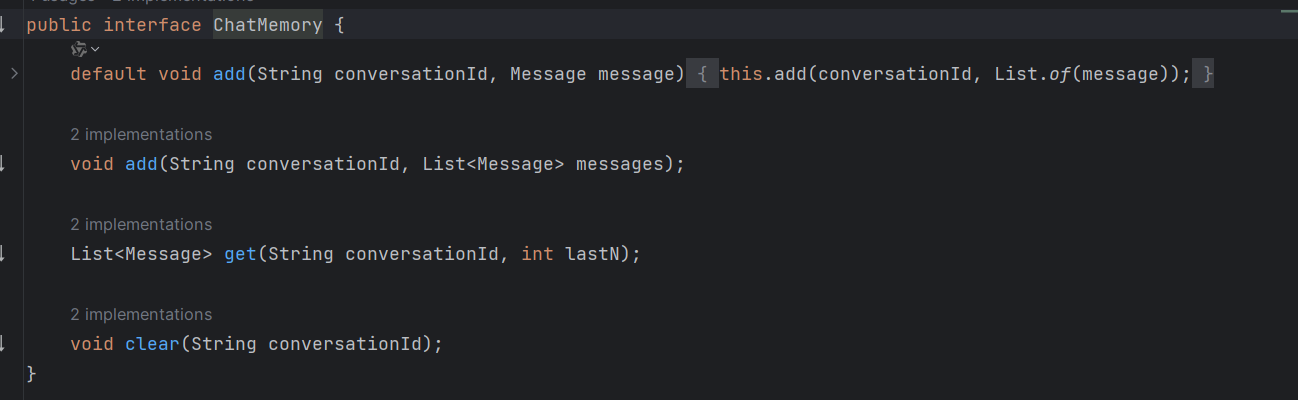
Spring AI 内置了几种 Chat Memory,可以将对话保存到不同的数据源中,比如:
- InMemoryChatMemory:内存存储
- CassandraChatMemory:在 Cassandra 中带有过期时间的持久化存储
- Neo4jChatMemory:在 Neo4j 中没有过期时间限制的持久化存储
- JdbcChatMemory:在 JDBC 中没有过期时间限制的持久化存储
- 自定义数据源存储
三、SpringAI会话记忆、Advisor实战
1. 使用 InMemoryChatMemory:内存存储 实现对话记忆
- 首先初始化 ChatClient 对象。使用 Spring 的构造器注入方式来注入阿里大模型dashscopeChatModel 对象,并使用该对象来初始化 ChatClient。初始化时指定默认的系统 Prompt 和基于内存的对话记忆 Advisor。代码如下:
@Component
@Slf4j
public class App {
private final ChatClient chatClient;
private static final String SYSTEM_PROMPT = "your system prompt";
public App(ChatModel dashscopeChatModel) {
// 初始化基于内存的对话记忆
ChatMemory chatMemory = new InMemoryChatMemory();
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory)
)
.build();
}
}
- 编写对话方法,调用 chatClient 对象,传入用户 Prompt,并且给 advisor 指定对话 id 和对话记忆大小。代码如下:
public String doChat(String message, String chatId) {
ChatResponse response = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
.call()
.chatResponse();
String content = response.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
- 编写单元测试,测试多轮对话:
@SpringBootTest
class AppTest {
@Resource
private App app;
@Test
void testChat() {
String chatId = UUID.randomUUID().toString();
// 第一轮
String message = "你好,我是wangdong.";
String answer = app.doChat(message, chatId);
Assertions.assertNotNull(answer);
// 第二轮
message = "我想学习springAI!!!";
answer = app.doChat(message, chatId);
Assertions.assertNotNull(answer);
// 第三轮
message = "你记得我叫啥吗?";
answer = app.doChat(message, chatId);
Assertions.assertNotNull(answer);
}
}
第一轮:
第二轮:
第三轮:
这样我们就完成了基于内存的会话记忆,但是这样还是有弊端,一旦程序重启,我们的会话还是会丢失,还需要别的方法来优化会话记忆
2. 使用自定义 ChatMemory 实现自定义数据源 本地存储实现对话记忆
之前我们使用了基于内存的对话记忆来保存对话上下文,但是服务器一旦重启了,对话记忆就会丢失。有时,我们可能希望将对话记忆持久化,保存到文件、数据库、Redis 或者其他对象存储中,怎么实现呢?
Spring AI 提供了 2 种方式:
利用现有依赖实现
前面提到,官方提供 了一些第三方数据库的整合支持,可以将对话保存到不同的数据源中。比如:
- InMemoryChatMemory:内存存储
- CassandraChatMemory:在 Cassandra 中带有过期时间的持久化存储-
- Neo4jChatMemory:在 Neo4j 中没有过期时间限制的持久化存储
- JdbcChatMemory:在 JDBC 中没有过期时间限制的持久化存储
自定义实现
Spring AI 的对话记忆实现非常巧妙,解耦了“存储” 和 “记忆算法”,使得我们可以单独修改 ChatMemory 存储来改变对话记忆的保存位置,而无需修改保存对话记忆的流程。
我们先看一看ChatMemory的接口方法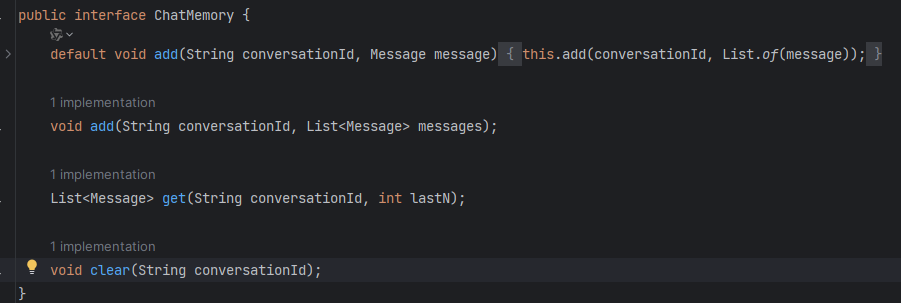
我们只要实现接口中的增、查、删就可以了
如果我们要使用文件来保存会话,一定会涉及到消息和文本的转换,我们需要在获取到消息会话时将消息转化为文本存储起来,同样在我们读取查询消息会话时需要把文本转化为消息会话 Message 提供给AI。涉及到了对对象的序列化和反序列化。
我们本能地会想到通过 JSON 进行序列化,但实际操作中,我们发现这并不容易。原因是:
要持久化的 Message 是一个接口,有很多种不同的子类实现(比如 UserMessage、SystemMessage 等)
每种子类所拥有的字段都不一样,结构不统一
子类没有无参构造函数,而且没有实现 Serializable 序列化接口
如果使用 JSON 来序列化会存在很多报错。所以此处我们选择高性能的 Kryo 序列化库。
引入依赖:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>
在根包下新建 chatmemory 包,编写基于文件持久化的对话记忆 FileBasedChatMemory,代码如下:
/**
* 基于文件持久化的对话记忆
*/
public class FileBasedChatMemory implements ChatMemory {
private final String BASE_DIR;
private static final Kryo kryo = new Kryo();
static {
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
// 构造对象时,指定文件保存目录
public FileBasedChatMemory(String dir) {
this.BASE_DIR = dir;
File baseDir = new File(dir);
if (!baseDir.exists()) {
baseDir.mkdirs();
}
}
@Override
public void add(String conversationId, List<Message> messages) {
// 将文件中的列表反序列化出来存储在一个列表中
List<Message> conversationMessages = getOrCreateConversation(conversationId);
// 将新的message对象也存储到列表中
conversationMessages.addAll(messages);
// 将列表序列化写到文件,这里的id用来区分是否是同一个会话
saveConversation(conversationId, conversationMessages);
}
@Override
public List<Message> get(String conversationId, int lastN) {
//这里也是把文件反序列化
List<Message> allMessages = getOrCreateConversation(conversationId);
//然后通过流处理,提供获取几条的功能
return allMessages.stream()
.skip(Math.max(0, allMessages.size() - lastN))
.toList();
}
@Override
public void clear(String conversationId) {
File file = getConversationFile(conversationId);
if (file.exists()) {
file.delete();
}
}
// 用来创建文件||读取文件中的内容反序列化为一个Message对象的list
private List<Message> getOrCreateConversation(String conversationId) {
File file = getConversationFile(conversationId);
List<Message> messages = new ArrayList<>();
if (file.exists()) {
try (Input input = new Input(new FileInputStream(file))) {
messages = kryo.readObject(input, ArrayList.class);
} catch (IOException e) {
e.printStackTrace();
}
}
return messages;
}
// 读取Message列表序列化为一个文件存储在本地文件中
private void saveConversation(String conversationId, List<Message> messages) {
File file = getConversationFile(conversationId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (IOException e) {
e.printStackTrace();
}
}
//获取或者构建一个文件
private File getConversationFile(String conversationId) {
return new File(BASE_DIR, conversationId + ".kryo");
}
}
接下来我们就可以使用自定义的ChatMemory了,让我们找到我们自己写的app,并且编写测试用例
public App(ChatModel dashscopeChatModel) {
//初始化基于内存的对话记忆
//ChatMemory chatMemory = new InMemoryChatMemory();
//基于文件的对话记忆
String fileDir = System.getProperty("user.dir") + "/tmp/chat-memory";
ChatMemory chatMemory = new FileBasedChatMemory(fileDir);
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
//基于内存的对话记忆
new MessageChatMemoryAdvisor(chatMemory),
new MyLoggerAdvisor(),
// 自定义推理增强 Advisor,可按需开启
new ReReadingAdvisor()
)
.build();
}



3. 自定义Advisor的使用
自定义Adcisor 和 Spring AOP 比较相似,我们可以通过编写拦截器或切面对请求和响应进行处理,比如记录请求响应日志、鉴权等。
Spring AI 的 Advisor 就可以理解为拦截器,可以对调用 AI 的请求进行增强,比如调用 AI 前鉴权、调用 AI 后记录日志。
官方已经提供了一些 Advisor,但可能无法满足我们实际的业务需求,这时我们可以使用官方提供的 自定义 Advisor 功能。按照下列步骤操作即可。
- 自定义的Advisor要实现这两个接口
CallAroundAdvisorStreamAroundAdvisor
public class CustomAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
//实现方法...
}
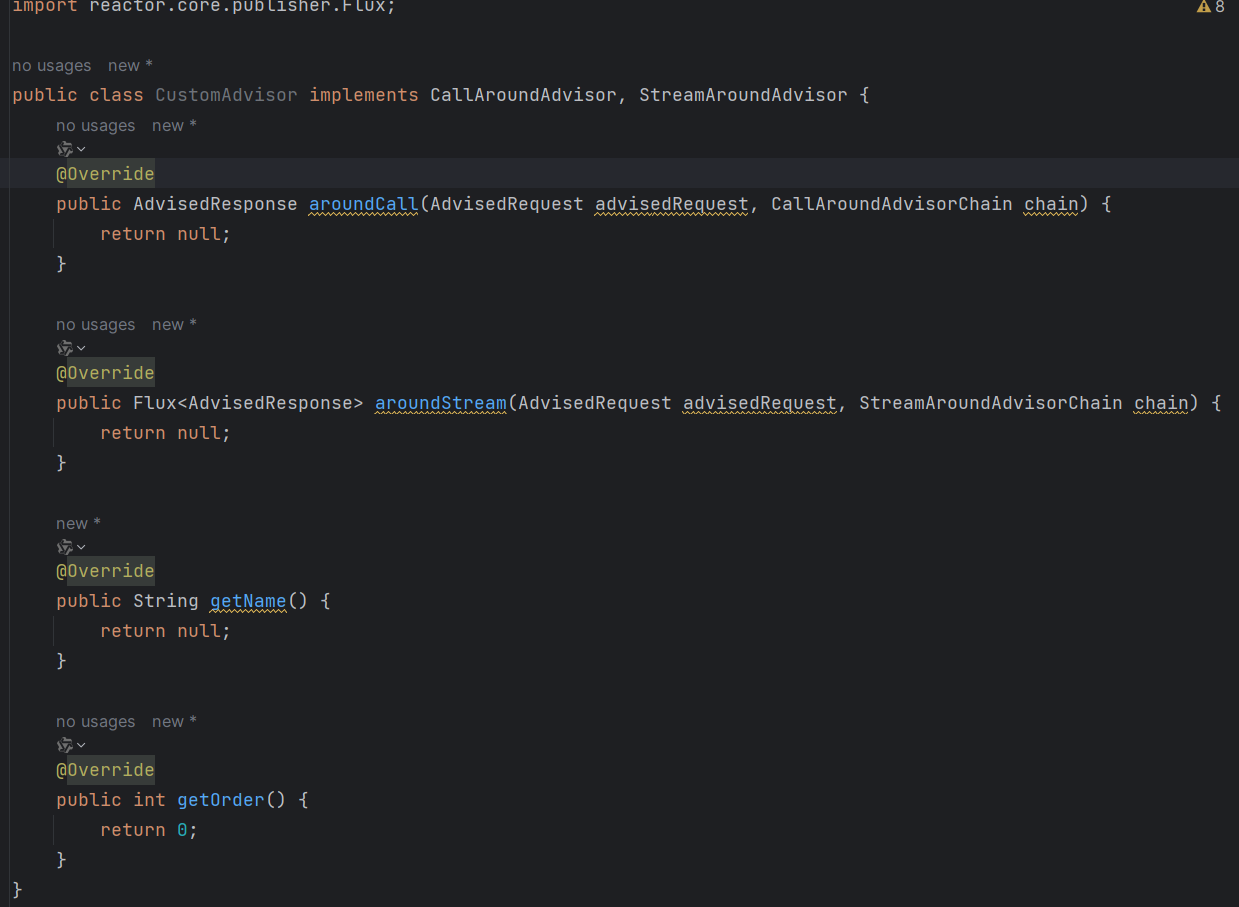
- 实现核心方法
对于非流式处理 (CallAroundAdvisor),实现 aroundCall 方法:
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
// 1. 处理请求(前置处理)
AdvisedRequest modifiedRequest = processRequest(advisedRequest);
// 2. 调用链中的下一个Advisor
AdvisedResponse response = chain.nextAroundCall(modifiedRequest);
// 3. 处理响应(后置处理)
return processResponse(response);
}
对于流式处理 (StreamAroundAdvisor),实现 aroundStream 方法:
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
// 1. 处理请求
AdvisedRequest modifiedRequest = processRequest(advisedRequest);
// 2. 调用链中的下一个Advisor并处理流式响应
return chain.nextAroundStream(modifiedRequest)
.map(response -> processResponse(response));
}
- 设置执行顺序
通过实现getOrder()方法指定 Advisor 在链中的执行顺序。值越小优先级越高,越先执行:
@Override
public int getOrder() {
// 值越小优先级越高,越先执行
return 100;
}
- 提供唯一名称
为每个 Advisor 提供一个唯一标识符:
@Override
public String getName() {
return "鱼皮自定义的 Advisor";
}
4. 使用自定义 Advisor 实现自定义日志 Advisor
虽然 Spring AI 已经内置了 SimpleLoggerAdvisor 日志拦截器,但是以 Debug 级别输出日志,而默认 Spring Boot 项目的日志级别是 Info,所以看不到打印的日志信息。
虽然上述方式可行,但如果为了更灵活地打印指定的日志,建议自己实现一个日志 Advisor。
我们可以同时参考 官方文档 和内置的 SimpleLoggerAdvisor 源码,结合 2 者并略做修改,开发一个更精简的、可自定义级别的日志记录器。默认打印 info 级别日志、并且只输出单次用户提示词和 AI 回复的文本。
/**
* 自定义日志 Advisor
* 打印 info 级别日志、只输出单次用户提示词和 AI 回复的文本
*/
@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
private AdvisedRequest before(AdvisedRequest request) {
log.info("AI Request: {}", request.userText());
return request;
}
private void observeAfter(AdvisedResponse advisedResponse) {
log.info("AI Response: {}", advisedResponse.response().getResult().getOutput().getText());
}
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
advisedRequest = this.before(advisedRequest);
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
this.observeAfter(advisedResponse);
return advisedResponse;
}
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
advisedRequest = this.before(advisedRequest);
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);
}
}
上述代码中值得关注的是 aroundStream 方法的返回,通过 MessageAggregator 工具类将 Flux 响应聚合成单个 AdvisedResponse。这对于日志记录或其他需要观察整个响应而非流中各个独立项的处理非常有用。注意,不能在 MessageAggregator 中修改响应,因为它是一个只读操作。
在 App 中应用自定义的日志 Advisor:
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
// 自定义日志 Advisor,可按需开启
new MyLoggerAdvisor(),
)
.build();
5. 使用自定义Advisor实现 Re-Reading Advisor
我们在这里会通过使用自定义Advisor来实现一个 Re-Reading(重读)Advisor,又称 Re2。该技术通过让模型重新阅读问题来提高推理能力
注意,虽然该技术可提高大语言模型的推理能力,不过成本会加倍!所以如果 AI 应用要面向 C 端开放,不建议使用。
Re2 的实现原理很简单,改写用户 Prompt 为下列格式,也就是让 AI 重复阅读用户的输入
{Input_Query}
Read the question again: {Input_Query}
/**
* 自定义 Re2 Advisor
* 可提高大型语言模型的推理能力
*/
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
//这里自己实现了一个before功能,对请求进行拦截并改写 userText
private AdvisedRequest before(AdvisedRequest advisedRequest) {
//通过一个map映射将原请求的用户参数映射表完整复制到新的map中,为后续修改参数做准备,避免直接修改原始参数。
Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());
advisedUserParams.put("re2_input_query", advisedRequest.userText());
// 构建新的AdvisedRequest,修改用户文本模板并更新用户参数
return AdvisedRequest.from(advisedRequest)
.userText("""
{re2_input_query}
Read the question again: {re2_input_query}
""")
.userParams(advisedUserParams)
.build();
}
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
//这里直接调用before
return chain.nextAroundCall(this.before(advisedRequest));
}
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
//这里直接调用before
return chain.nextAroundStream(this.before(advisedRequest));
}
@Override
public int getOrder() {
return 0;
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
}
可以在app中使用该Advisor,并进行测试,查看请求是否被改写
chatClient = ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
// 自定义推理增强 Advisor,可按需开启
new ReReadingAdvisor()
)
.build();
在我们测试的时候可以看到
我们re2顾问生效了。
四、结语(会不断补充,可以收藏一下)
本章介绍了 Spring AI 调用大模型、提示词工程、对话记忆、Advisor 的基本使用,对于对话记忆的自定义和jdbc存储,也会在这段时间加入,我会在学习中不断整理笔记,巩固自己学到的东西,这里后面还会加会话记忆的其他实现方式,目前先这样,对于顾问的高阶使用在RAG的文章介绍中也会介绍。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)