freeRTOS教程
摘要:RTOS中的堆管理是动态内存分配的关键机制,与通用系统相比更注重实时性和确定性。堆需手动管理(malloc/free),具有动态大小但效率较低,主要用于存储动态数据。RTOS为每个任务分配独立栈空间,通过上下文切换保护寄存器状态。FreeRTOS提供pvPortMalloc/vPortFree等专用内存管理接口,支持静态/动态任务创建。任务调度基于优先级,使用队列、信号量等机制实现同步互斥通
RTOS实时操作系统入门学习
堆的概念
堆是一种动态分配的内存区域,需要程序员手动管理。
-
手动管理:必须通过
malloc()、calloc()等函数手动分配内存,使用完后需通过free()函数释放,否则会造成内存泄漏。 -
动态大小:堆的大小不固定,通常远大于栈(可达 GB 级别),受限于系统内存。
-
效率较低:堆的分配和释放需要维护内存链表,操作效率比栈低,且内存可能碎片化。
-
存储内容:主要用于存储程序运行时动态创建的数据,如动态数组、结构体实例等,其生命周期不受函数调用范围限制。
在实时操作系统(RTOS)中,堆(Heap)的核心概念与通用计算机系统中的堆类似,都是用于动态内存分配的内存区域,但 RTOS 的堆设计需满足实时性、确定性和资源受限的特点,因此在实现和使用上有其特殊性。
| 特性 | 通用系统堆(如 Linux) | RTOS 堆 |
|---|---|---|
| 实时性 | 非确定性(耗时可能波动) | 确定性(操作时间可预测) |
| 管理算法 | 复杂(如伙伴系统、 slab 分配器) | 简化(如固定块、内存池) |
| 多任务安全 | 依赖线程库锁 | 内核原生支持(临界区保护) |
| 内存大小 | 较大(可动态扩展) | 固定且较小(受嵌入式硬件限制) |
| 主要用途 | 通用应用程序动态内存 | 内核对象(任务、队列等)和实时数据 |
堆的操作代码
#include <stdint.h>
#include <stddef.h>
#include <stdbool.h>
// 堆管理结构体 - 用于描述一个内存块
typedef struct HeapBlock {
struct HeapBlock *next; // 指向下一个内存块
size_t size; // 内存块大小(包括结构体本身)
bool is_free; // 内存块是否空闲
} HeapBlock;
// 堆内存区域(模拟RTOS中的堆空间)
static uint8_t heap_memory[4096]; // 4KB堆空间
static HeapBlock *heap_start = NULL;
// 临界区保护 - 简化实现,实际RTOS会有专用API
static void enter_critical_section(void) {
// 实际中会禁用中断或获取互斥锁
}
static void exit_critical_section(void) {
// 实际中会启用中断或释放互斥锁
}
// 初始化堆管理器
void heap_init(void) {
enter_critical_section();
// 将整个堆空间初始化为一个大的空闲块
heap_start = (HeapBlock *)heap_memory;
heap_start->next = NULL;
heap_start->size = sizeof(heap_memory);
heap_start->is_free = true;
exit_critical_section();
}
// 分配内存
void *heap_alloc(size_t size) {
if (size == 0) return NULL;
// 加上HeapBlock结构体大小,用于管理
size_t total_size = size + sizeof(HeapBlock);
HeapBlock *current = heap_start;
void *result = NULL;
enter_critical_section();
// 首次适配算法:找到第一个足够大的空闲块
while (current != NULL) {
if (current->is_free && current->size >= total_size) {
// 如果剩余空间足够大,分裂成两个块
if (current->size - total_size >= sizeof(HeapBlock) + 1) {
HeapBlock *new_block = (HeapBlock *)((uint8_t *)current + total_size);
new_block->size = current->size - total_size;
new_block->is_free = true;
new_block->next = current->next;
current->size = total_size;
current->next = new_block;
}
current->is_free = false;
result = (uint8_t *)current + sizeof(HeapBlock); // 跳过管理结构体
break;
}
current = current->next;
}
exit_critical_section();
return result;
}
// 释放内存
void heap_free(void *ptr) {
if (ptr == NULL) return;
enter_critical_section();
// 找到对应的HeapBlock结构体
HeapBlock *block = (HeapBlock *)((uint8_t *)ptr - sizeof(HeapBlock));
block->is_free = true;
// 合并相邻的空闲块,减少内存碎片
HeapBlock *current = heap_start;
while (current != NULL && current->next != NULL) {
if (current->is_free && current->next->is_free) {
// 合并两个相邻的空闲块
current->size += current->next->size;
current->next = current->next->next;
} else {
current = current->next;
}
}
exit_critical_section();
}
// 测试函数
void heap_test() {
heap_init();
// 分配几个内存块
void *ptr1 = heap_alloc(100);
void *ptr2 = heap_alloc(200);
void *ptr3 = heap_alloc(50);
// 释放一个块
heap_free(ptr2);
// 再次分配,应该能重用刚才释放的空间
void *ptr4 = heap_alloc(150);
// 释放所有块
heap_free(ptr1);
heap_free(ptr3);
heap_free(ptr4);
}
栈的概念
栈(Stack)
栈是一种自动分配和释放的内存区域,遵循 "先进后出"(LIFO)的原则。
特点:
- 自动管理:由编译器自动分配和释放,无需程序员手动操作。当函数调用时,参数、局部变量等被压入栈中;函数执行结束后,这些数据自动从栈中弹出并释放内存。
- 固定大小:栈的大小在程序编译时通常已确定(可通过编译器设置调整),一般较小(几 MB)。
- 高效快速:栈的操作(压栈 / 出栈)效率很高,因为它是连续的内存块,访问速度接近寄存器。
- 存储内容:主要存储函数参数、局部变量、返回地址等。
堆和栈的核心区别
| 特性 | 栈(Stack) | 堆(Heap) |
|---|---|---|
| 管理方式 | 编译器自动分配释放 | 程序员手动分配释放 |
| 大小限制 | 较小(固定) | 较大(动态) |
| 分配效率 | 高(连续内存) | 低(可能碎片化) |
| 存储内容 | 局部变量、函数参数、返回值 | 动态分配的数据(如数组、结构体) |
| 内存增长方向 | 向下增长(高地址到低地址) | 向上增长(低地址到高地址) |
| 生命周期 | 随函数调用 / 返回而创建 / 销毁 | 随malloc()/free()控制 |
| 碎片问题 | 无(自动连续分配) | 可能产生碎片 |
RTOS中任务调度辉覆盖LR寄存器吗,LR被覆盖了怎么办
LR(Link Register,链接寄存器)用于存储函数调用的返回地址
在 RTOS 中,正常情况下两个任务操作 LR 寄存器不会互相覆盖,但如果出现覆盖,通常是因为上下文切换机制被破坏或任务栈溢出等异常问题。
一、为什么正常情况下 LR 不会被两个任务覆盖?
RTOS 的核心功能之一是任务上下文切换,其核心机制是通过保存和恢复寄存器状态实现任务的 “无缝切换”。LR 寄存器(链接寄存器)作为 CPU 的关键寄存器,会在任务切换时被妥善保护,具体过程如下:
1. 任务上下文的保存与恢复
每个任务在 RTOS 中都有独立的任务控制块(TCB) 和私有栈空间。当 RTOS 进行任务切换(如从任务 A 切换到任务 B)时:
- 保存任务 A 的上下文:将任务 A 当前的所有寄存器(包括 LR、PC、R0-R15 等)压入任务 A 的私有栈中,并更新 TCB 记录栈顶位置。
- 恢复任务 B 的上下文:从任务 B 的 TCB 中读取栈顶位置,将之前保存的寄存器(包括任务 B 的 LR)从栈中弹出,恢复到 CPU 寄存器中。
因此,任务 A 和任务 B 的 LR 寄存器分别存储在各自的栈中,切换时互不干扰,不会出现互相覆盖的情况。
二 、如果出现LR被覆盖,大概率有以下几个原因:
1. LR 被覆盖的常见原因
- 栈溢出:RTOS 任务栈大小不足,导致栈内存储的 LR(函数调用时会压栈)被后续数据覆盖。
- 内存越界:操作指针时越界写入,意外修改了栈或寄存器存储区中的 LR 值。
- 汇编错误:手动操作 LR 寄存器时(如异常处理、上下文切换),因逻辑错误导致 LR 被错误赋值。
- 中断 / 异常嵌套问题:中断处理中未正确保护 LR,导致被嵌套中断覆盖。
局部变量在栈中分配,如何分配?
RTOS 中的特殊点
在 RTOS 中,每个任务有独立的栈空间,局部变量的分配机制与裸机相同,但需注意:
- 任务栈大小是固定的(创建任务时指定),局部变量总大小不能超过栈余量。
- 多任务切换时,栈指针(SP)会被保存到任务控制块(TCB),恢复任务时再从 TCB 中读取,确保各任务的局部变量互不干扰。
1. 栈的基本结构与栈指针
- 栈空间:每个任务有独立的栈(RTOS 中)或共享一个系统栈(裸机),栈是一块连续的内存区域。
- 栈指针(SP):CPU 中的专用寄存器(如
sp),始终指向栈顶(当前可分配的空闲内存起始地址)。 - 增长方向:多数架构中栈从高地址向低地址增长(如 ARM、x86)。
2. 局部变量的分配步骤(以函数调用为例)
当函数被调用时,编译器会自动完成局部变量的栈分配,过程如下:
(1)函数调用前的准备
调用函数时,先将返回地址(LR) 压入栈中,确保函数执行完能回到调用处。
(2)进入函数,调整栈指针
函数开始执行时,编译器生成指令修改栈指针(SP),为局部变量 "开辟空间":
- 实际分配大小可能因内存对齐(如 4 字节对齐)大于变量总大小(上例中 5 字节→8 字节)。
- 栈指针向下(低地址)移动,"空出" 的区域即为局部变量的存储空间。
(3)局部变量的地址映射
栈空间分配后,编译器将局部变量与栈中的地址绑定
(4)函数返回时自动释放
为什么每个RTOS任务都有自己的栈
RTOS 的核心功能是多任务并发调度(通过时间片轮转、优先级抢占等方式实现 “同时” 运行多个任务),而栈作为函数调用和局部变量存储的关键载体,必须为每个任务独立分配。
多任务调度依赖栈保存 / 恢复上下文
RTOS 的任务切换(上下文切换)本质是 “暂停当前任务,恢复另一个任务”,过程中需要:
- 保存当前任务的上下文:将 CPU 寄存器(如 SP、PC、LR、R0-R15 等)和栈指针(SP)保存到该任务的控制块(TCB,Task Control Block)中。
- 恢复目标任务的上下文:从目标任务的 TCB 中读取其栈指针(SP)和寄存器值,加载到 CPU 中,使任务从上次暂停的位置继续执行。
栈指针(SP)是上下文的核心:每个任务的 SP 指向其栈的当前顶部,任务切换时必须保存和恢复各自的 SP,否则无法正确恢复任务的执行状态。如果共享栈,SP 的值会被其他任务覆盖,导致任务切换后无法找到正确的栈数据。

汇编指令语言快速上手
一、数据传送指令(最基础、最常用)
用于在寄存器与寄存器、寄存器与内存之间传递数据。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
MOV Rd, Rs |
将寄存器 Rs 的值复制到 Rd | MOV R0, R1 → R0 = R1 的值 |
MOV Rd, #imm |
将立即数(常数)imm 存入 Rd | MOV R0, #10 → R0 = 10 |
LDR Rd, [Rn] |
从 Rn 指向的内存地址读取数据到 Rd | LDR R0, [R1] → R0 = 内存 [R1] 的值 |
STR Rd, [Rn] |
将 Rd 的值写入 Rn 指向的内存地址 | STR R0, [R1] → 内存 [R1] = R0 的值 |
LDR Rd, [Rn, #imm] |
从 Rn+imm 地址读取数据到 Rd(偏移寻址) | LDR R0, [R1, #4] → R0 = 内存 [R1+4] |
STR Rd, [Rn, #imm] |
将 Rd 的值写入 Rn+imm 地址(偏移寻址) | STR R0, [R1, #8] → 内存 [R1+8] = R0 |
解析:
- 寄存器以
R0-R15命名(ARM 架构),其中R13是栈指针(SP),R14是链接寄存器(LR),R15是程序计数器(PC)。 - 立即数前加
#,如#0x10(十六进制)、#123(十进制)。 - 内存访问需用
[ ]包裹地址,如[R1]表示 R1 寄存器中存储的地址。
二、算术运算指令
用于基本的加减乘除运算,结果通常存在第一个寄存器中。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
ADD Rd, Rn, Rs |
Rd = Rn + Rs | ADD R0, R1, R2 → R0 = R1 + R2 |
ADD Rd, Rn, #imm |
Rd = Rn + 立即数 imm | ADD R0, R1, #5 → R0 = R1 + 5 |
SUB Rd, Rn, Rs |
Rd = Rn - Rs | SUB R0, R1, R2 → R0 = R1 - R2 |
SUB Rd, Rn, #imm |
Rd = Rn - 立即数 imm | SUB R0, R1, #3 → R0 = R1 - 3 |
MUL Rd, Rn, Rs |
Rd = Rn × Rs(仅支持 32 位整数) | MUL R0, R1, R2 → R0 = R1 × R2 |
DIV Rd, Rn, Rs |
Rd = Rn ÷ Rs(部分 ARM 架构支持) | DIV R0, R1, R2 → R0 = R1 ÷ R2 |
解析:
- 运算结果会影响 CPU 的标志位(如进位、零标志),用于后续条件判断。
- 乘法指令
MUL在部分低端 ARM(如 ARM Cortex-M0)中可能不支持,需用加法模拟。
三、逻辑运算指令
用于位操作(与、或、非、移位等),嵌入式开发中常用于寄存器配置。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
AND Rd, Rn, Rs |
按位与:Rd = Rn & Rs | AND R0, R1, #0x0F → 取 R1 的低 4 位 |
ORR Rd, Rn, Rs |
按位或:Rd = Rn | Rs | ORR R0, R1, #0x80 → 置 R1 的第 7 位为 1 |
EOR Rd, Rn, Rs |
按位异或:Rd = Rn ^ Rs | EOR R0, R1, R1 → R0 = 0(自身异或为 0) |
LSL Rd, Rn, #imm |
逻辑左移:Rd = Rn << imm(低位补 0) | LSL R0, R1, #2 → R0 = R1 × 4 |
LSR Rd, Rn, #imm |
逻辑右移:Rd = Rn >> imm(高位补 0) | LSR R0, R1, #1 → R0 = R1 ÷ 2 |
NOT Rd, Rn |
按位非:Rd = ~Rn(部分架构用MVN指令) |
MVN R0, R1 → R0 = ~R1 |
解析:
- 逻辑运算常用于硬件寄存器配置(如设置 GPIO 引脚方向、使能外设)。例如:
ORR R0, R0, #(1<<5)表示将 R0 的第 5 位置 1。 - 移位指令可替代乘法 / 除法(如左移 2 位 =×4,右移 1 位 =÷2),效率更高。
四、栈操作指令
栈是函数调用、局部变量存储的核心,栈操作依赖栈指针(SP,R13)。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
PUSH {reg_list} |
将寄存器列表压入栈(SP 自动减小) | PUSH {R0, R1, LR} → 保存 R0、R1、LR |
POP {reg_list} |
从栈中弹出数据到寄存器列表(SP 自动增大) | POP {R0, R1, PC} → 恢复 R0、R1、PC |
解析:
- ARM 栈默认从高地址向低地址增长,
PUSH时 SP = SP - 4×n(n 为寄存器数量,每个寄存器 4 字节),POP时 SP = SP + 4×n。 - 函数调用时必须用
PUSH {LR}保存返回地址,函数结束时用POP {PC}恢复返回地址(跳回调用处)。
五、分支(跳转)指令
用于实现函数调用、条件判断(类似 C 语言的if、goto)。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
B label |
无条件跳转到 label 标签处 | B loop → 跳转到 loop 标签 |
BL label |
跳转到 label,并将返回地址存入 LR(函数调用) | BL func → 调用 func 函数,LR = 当前 PC+4 |
BX Rn |
跳转到 Rn 指向的地址(支持 Thumb/ARM 切换) | BX LR → 从函数返回(LR 存返回地址) |
BEQ label |
若标志位为 “零”(相等),则跳转到 label | BEQ equal → 相等时跳转到 equal |
BNE label |
若标志位为 “非零”(不等),则跳转到 label | BNE not_equal → 不等时跳转到 not_equal |
解析:
BL(Branch with Link)是函数调用的核心指令,执行后LR = 当前PC + 4(下一条指令地址),函数结束时用BX LR跳回。- 条件跳转(
BEQ、BNE等)依赖算术 / 逻辑指令执行后设置的标志位(如CMP R0, R1会比较 R0 和 R1 并设置标志位)。
六、比较与测试指令
用于条件判断,不修改操作数,仅设置标志位(供分支指令使用)。
| 指令格式 | 功能说明 | 示例 |
|---|---|---|
CMP Rn, Rs |
比较 Rn 与 Rs(Rn - Rs),设置标志位 | CMP R0, #10 → 比较 R0 和 10 |
TST Rn, Rs |
测试 Rn 与 Rs(Rn & Rs),结果为 0 则置零标志 | TST R0, #(1<<3) → 测试 R0 的第 3 位是否为 0 |
解析:
CMP后常用BEQ(等于)、BGT(大于)等指令判断结果。例如:asm
CMP R0, #5 ; 比较R0和5 BEQ equal ; 若R0=5,跳转到equal BNE not_equal ; 若R0≠5,跳转到not_equalTST常用于检查某一位是否为 1(如TST R0, #(1<<2)→ 检查 R0 的第 2 位)。
RTOS源码概述
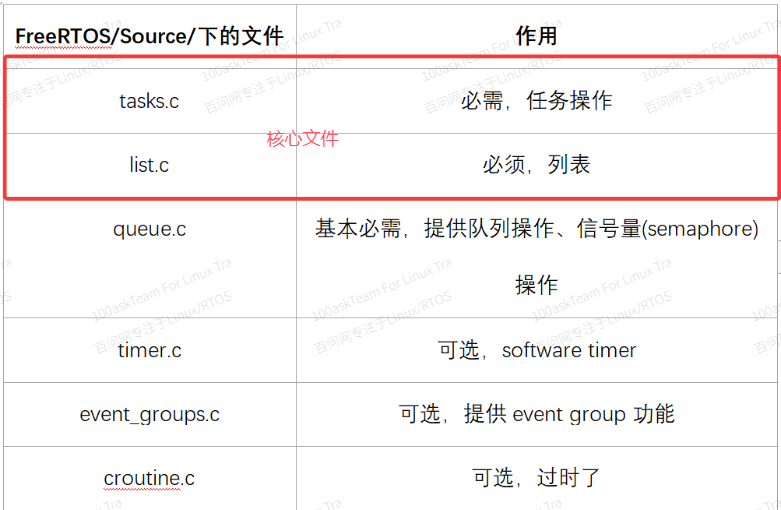
使用STM32CubeMX创建的FreeRTOS工程中,FreeRTOS相关的源码如下:
目录结构



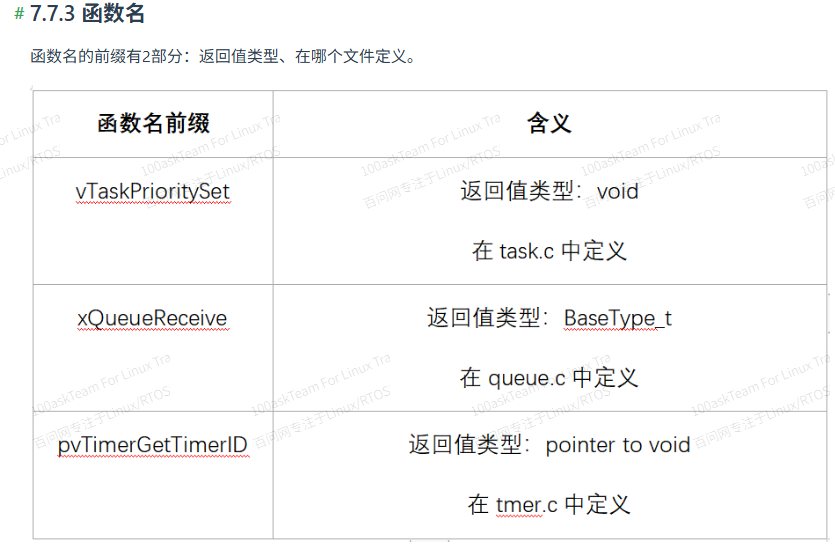
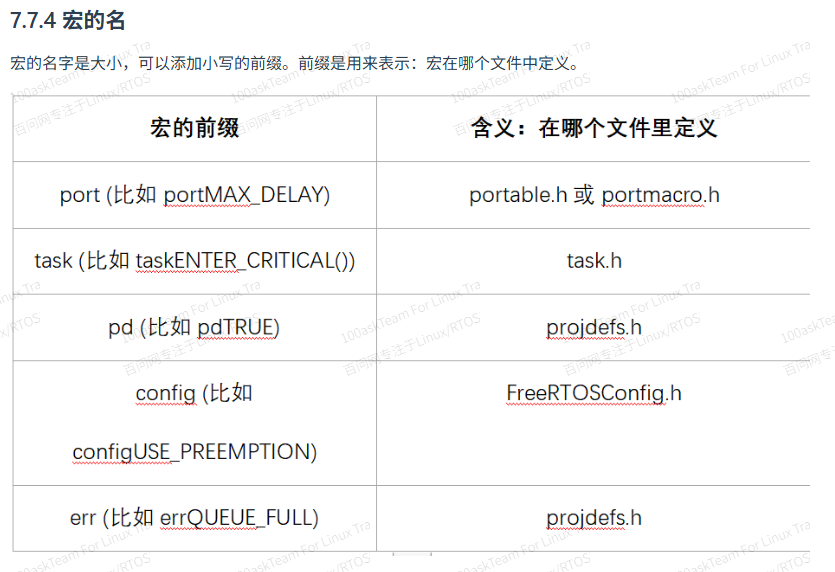
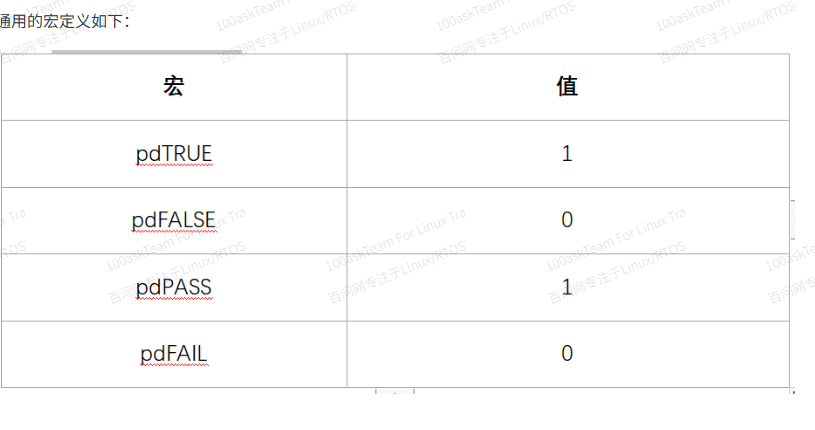
RTOS中内存管理
c语言中的malloc,free原生c函数在嵌入式系统中不适用,因为这类原生函数使用了大量代码,并且不容易调试,对于不同设备兼容性也比较差。

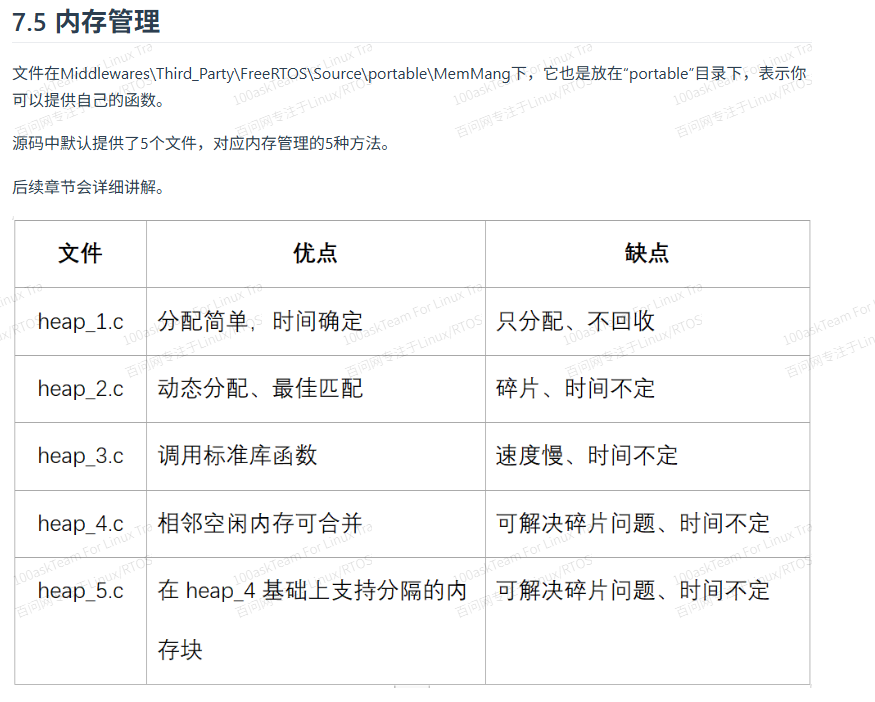
FreeRTOS中内存管理的接口函数为:pvPortMalloc 、vPortFree,对应于C库的malloc、free。 文件在FreeRTOS/Source/portable/MemMang下,它也是放在portable目录下,表示你可以提供自己的函数。
一般只使用heap_4.c与heap_5.c
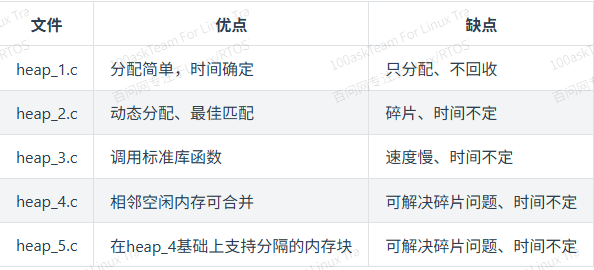
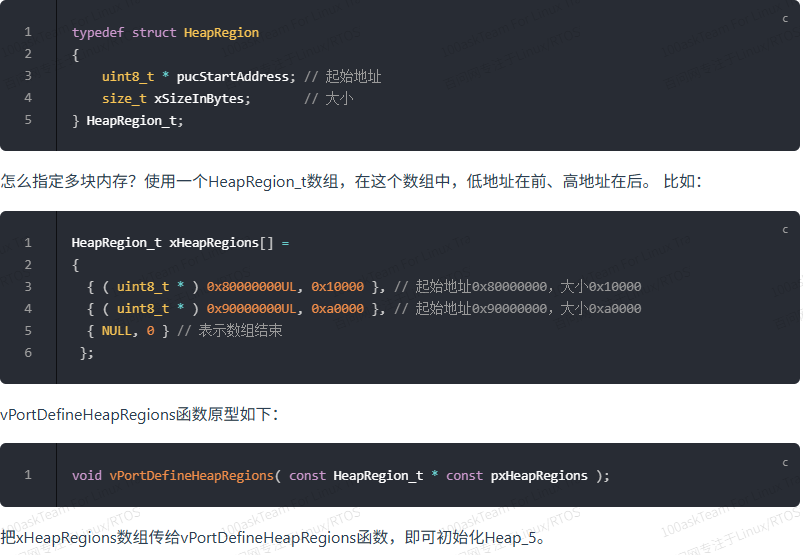
Heap相关的函数
1.pvPortMalloc/vPortFree
函数原型:
void * pvPortMalloc( size_t xWantedSize );
void vPortFree( void * pv );
作用:分配内存、释放内存。
如果分配内存不成功,则返回值为NULL。
2.xPortGetFreeHeapSize
函数原型:
size_t xPortGetFreeHeapSize( void );
当前还有多少空闲内存,这函数可以用来优化内存的使用情况。比如当所有内核对象都分配好后,执行此函数返回2000,那么configTOTAL_HEAP_SIZE就可减小2000。
注意:在heap_3中无法使用。
3.xPortGetMinimumEverFreeHeapSize
函数原型:
size_t xPortGetMinimumEverFreeHeapSize( void );
返回:程序运行过程中,空闲内存容量的最小值。
注意:只有heap_4、heap_5支持此函数。
4.malloc失败的钩子函数
在pvPortMalloc函数内部:
void * pvPortMalloc( size_t xWantedSize )vPortDefineHeapRegions
{
......
#if ( configUSE_MALLOC_FAILED_HOOK == 1 )
{
if( pvReturn == NULL )
{
extern void vApplicationMallocFailedHook( void );
vApplicationMallocFailedHook();
}
}
#endif
return pvReturn;
}
所以,如果想使用这个钩子函数:
- 在FreeRTOSConfig.h中,把configUSE_MALLOC_FAILED_HOOK定义为1
- 提供vApplicationMallocFailedHook函数
- pvPortMalloc失败时,才会调用此函数
任务管理
void func(void *) 这种函数声明表示:这是一个名为 func 的函数,它接受一个 void* 类型的参数(无返回值)。void* 是一种特殊的指针类型,可以指向任何类型的数据,因此它可以接受各种类型的指针作为参数。
使用方法和传参示例:
- 基本用法:
可以将任何类型的指针直接传递给该函数,无需强制类型转换(但建议显式转换以提高可读性)。
#include <stdio.h>
// 函数声明
void func(void *ptr);
int main() {
int num = 10;
char str[] = "Hello";
// 传递int类型指针
func(&num);
// 传递char类型指针
func(str); // 数组名本身就是指针
return 0;
}
// 函数实现
void func(void *ptr) {
// 在函数内部需要将void*转换为具体类型才能使用
// 这里需要知道ptr实际指向的数据类型才能正确转换
// 示例:假设我们知道可能传入int*或char*
// (实际使用时通常需要额外信息来判断类型)
// 假设是int*
int *int_ptr = (int*)ptr;
printf("假设是int: %d\n", *int_ptr);
// 假设是char*
char *char_ptr = (char*)ptr;
printf("假设是字符串: %s\n", char_ptr);
}
总之,使用 void func(void *) 时,关键是要确保在函数内部将 void* 指针正确转换回原始数据类型,否则会导致未定义行为。
在FreeRTOS中,任务就是一个函数,原型如下:
void ATaskFunction( void *pvParameters );创建任务
创建任务时使用的函数如下:
BaseType_t xTaskCreate( TaskFunction_t pxTaskCode, // 函数指针, 任务函数
const char * const pcName, // 任务的名字
const configSTACK_DEPTH_TYPE usStackDepth, // 栈大小,单位为word,10表示40字节
void * const pvParameters, // 调用任务函数时传入的参数
UBaseType_t uxPriority, // 优先级
TaskHandle_t * const pxCreatedTask ); // 任务句柄, 以后使用它来操作这个任务
参数说明:
重要的参数是pvTaskCode(任务函数),usStackDepth(为任务分配栈的大小,要乘以4字节)
pvParameters(调用函数传入的参数),pxCreatedTask(任务的句柄)。
| 参数 | 描述 |
|---|---|
| pvTaskCode | 函数指针,任务对应的 C 函数。任务应该永远不退出,或者在退出时调用 "vTaskDelete(NULL)"。 |
| pcName | 任务的名称,仅用于调试目的,FreeRTOS 内部不使用。pcName 的长度为 configMAX_TASK_NAME_LEN。 |
| usStackDepth | 每个任务都有自己的栈,usStackDepth 指定了栈的大小,单位为 word。例如,如果传入 100,表示栈的大小为 100 word,即 400 字节。最大值为 uint16_t 的最大值。确定栈的大小并不容易,通常是根据估计来设定。精确的办法是查看反汇编代码。 |
| pvParameters | 调用 pvTaskCode 函数指针时使用的参数:pvTaskCode(pvParameters)。 |
| uxPriority | 任务的优先级范围为 0~(configMAX_PRIORITIES – 1)。数值越小,优先级越低。如果传入的值过大,xTaskCreate 会将其调整为 (configMAX_PRIORITIES – 1)。 |
| pxCreatedTask | 用于保存 xTaskCreate 的输出结果,即任务的句柄(task handle)。如果以后需要对该任务进行操作,如修改优先级,则需要使用此句柄。如果不需要使用该句柄,可以传入 NULL。 |
| 返回值 | 成功时返回 pdPASS,失败时返回 errCOULD_NOT_ALLOCATE_REQUIRED_MEMORY(失败原因是内存不足)。请注意,文档中提到的失败返回值是 pdFAIL 是不正确的。pdFAIL 的值为 0,而 errCOULD_NOT_ALLOCATE_REQUIRED_MEMORY 的值为 -1。 |
使用静态分配内存的函数如下:
TaskHandle_t xTaskCreateStatic (
TaskFunction_t pxTaskCode, // 函数指针, 任务函数
const char * const pcName, // 任务的名字
const uint32_t ulStackDepth, // 栈大小,单位为word,10表示40字节
void * const pvParameters, // 调用任务函数时传入的参数
UBaseType_t uxPriority, // 优先级
StackType_t * const puxStackBuffer, // 静态分配的栈,就是一个buffer
StaticTask_t * const pxTaskBuffer // 静态分配的任务结构体的指针,用它来操作这个任务
);
相比于使用动态分配内存创建任务的函数,最后2个参数不一样:
| 参数 | 描述 |
|---|---|
| pvTaskCode | 函数指针,可以简单地认为任务就是一个C函数。 它稍微特殊一点:永远不退出,或者退出时要调用"vTaskDelete(NULL)" |
| pcName | 任务的名字,FreeRTOS内部不使用它,仅仅起调试作用。 长度为:configMAX_TASK_NAME_LEN |
| usStackDepth | 每个任务都有自己的栈,这里指定栈大小。 单位是word,比如传入100,表示栈大小为100 word,也就是400字节。 最大值为uint16_t的最大值。 怎么确定栈的大小,并不容易,很多时候是估计。 精确的办法是看反汇编码。 |
| pvParameters | 调用pvTaskCode函数指针时用到:pvTaskCode(pvParameters) |
| uxPriority | 优先级范围:0~(configMAX_PRIORITIES – 1) 数值越小优先级越低, 如果传入过大的值,xTaskCreate会把它调整为(configMAX_PRIORITIES – 1) |
| puxStackBuffer | 静态分配的栈内存,比如可以传入一个数组, 它的大小是usStackDepth*4。 |
| pxTaskBuffer | 静态分配的StaticTask_t结构体的指针 |
| 返回值 | 成功:返回任务句柄; 失败:NULL |
多个任务使用同一个函数
多个任务可以使用同一个函数,怎么体现它们的差别?
每个任务运行都分配有自己单独的栈,函数在任务中运行就是运行在任务的栈空间中。
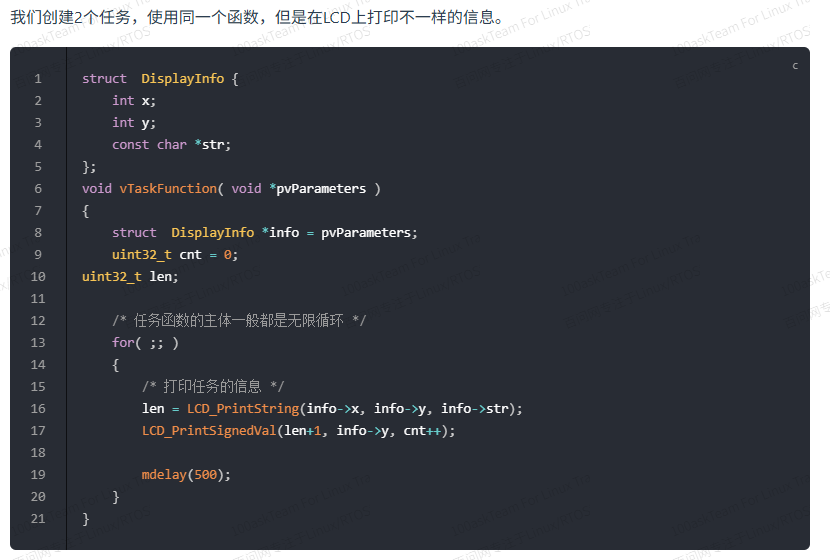

由于栈不同,每个函数的局部变量打印的值也是不同的。
注意:在任务运行中,都调用了LCD如果进行保护措施,该怎么保护,如果在运行LCD打印时任务被切换,LCD函数还能正常打印吗。
删除任务
删除任务使用的函数
void vTaskDelete( TaskHandle_t xTaskToDelete ); 删除任务使用的参数为任务的句柄。如果是任务自杀使用的参数是NULL 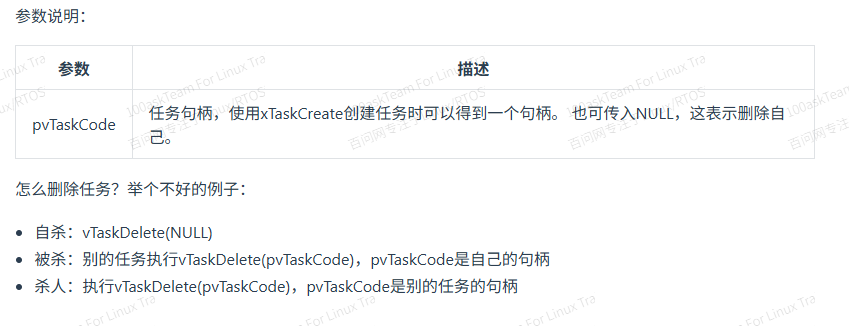
任务优先级和tick
优先级的取值范围是:0~(configMAX_PRIORITIES – 1),数值越大优先级越高。
使用vTaskDelay()延时,会释放CPU资源。不会在像MDelay一样占用CPU资源。其他底优先级的任务也能被调度。使用Mdelay会导致底优先级任务无法被调用。
vTaskDelay(2); // 等待2个Tick,假设configTICK_RATE_HZ=100, Tick周期时10ms, 等待20ms
// 还可以使用pdMS_TO_TICKS宏把ms转换为tick
vTaskDelay(pdMS_TO_TICKS(100)); // 等待100ms任务状态
任务状态有四种:
就绪状态:任务创建成功就进入就绪状态。
暂停状态:
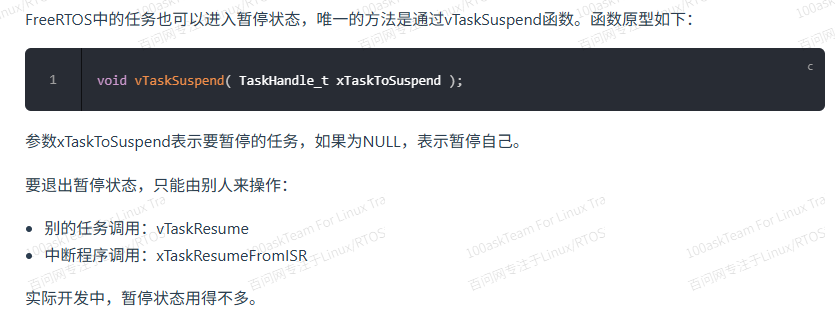
阻塞状态:不会占用CPU资源,需要某个事件唤醒
运行状态:任务运行
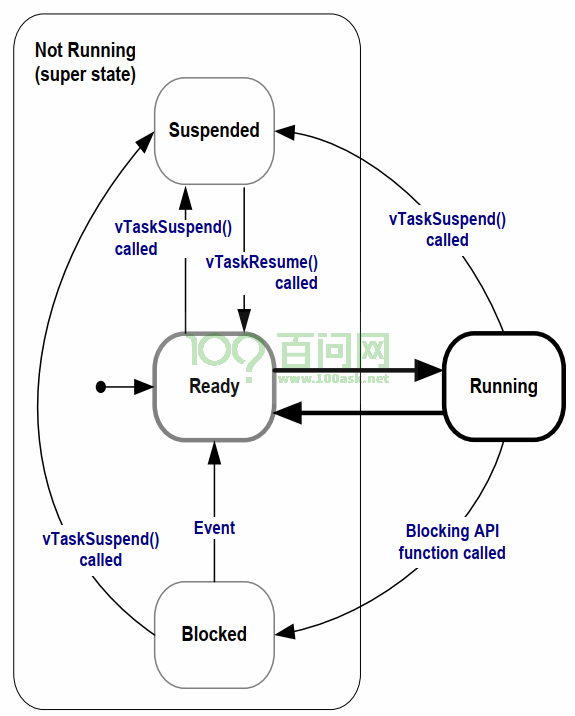
空闲任务:
空闲任务(Idle任务)的作用之一:释放被删除的任务的内存。
- 空闲任务优先级为0:它不能阻碍用户任务运行
- 空闲任务要么处于就绪态,要么处于运行态,永远不会阻塞
空闲任务的优先级为0,这意味着一旦某个用户的任务变为就绪态,那么空闲任务马上被切换出去,让这个用户任务运行。在这种情况下,我们说用户任务"抢占"(pre-empt)了空闲任务,这是由调度器实现的。
要注意的是:如果使用vTaskDelete()来删除任务,那么你就要确保空闲任务有机会执行,否则就无法释放被删除任务的内存。
任务的管理与调度
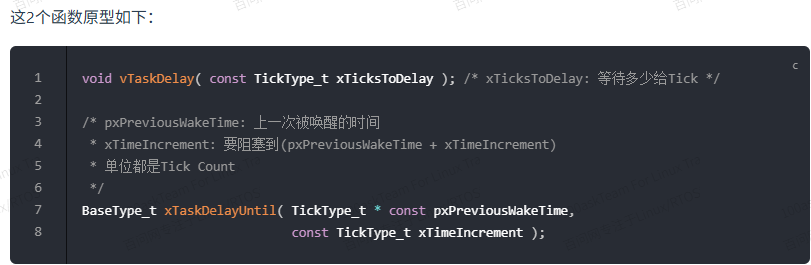
两个Delay函数
vTaskDelay:至少等待指定个数的Tick 任务才能变为就绪状态
vTaskDelayUntil:等待到指定的绝对时刻,任务才能变为就绪态。
同步互斥与通信
全局变量
如果通过一个全局变量来作为标志位,在两个任务中都对该全局变量进行操作,由于在任务A中对全局变量读完该全局变量,但是写操作可能还未完成,就被中断打断。在B任务中对该全局变量操作成功。那么A在操作全局变量时就会发生错误。所以使用全局变量来协调两个任务的操作是有缺陷的。
或者在任务B中要等待任务A完成后置成功标志位才可以操作。在B任务中需要不断中断来判断。很耗费CPU资源。
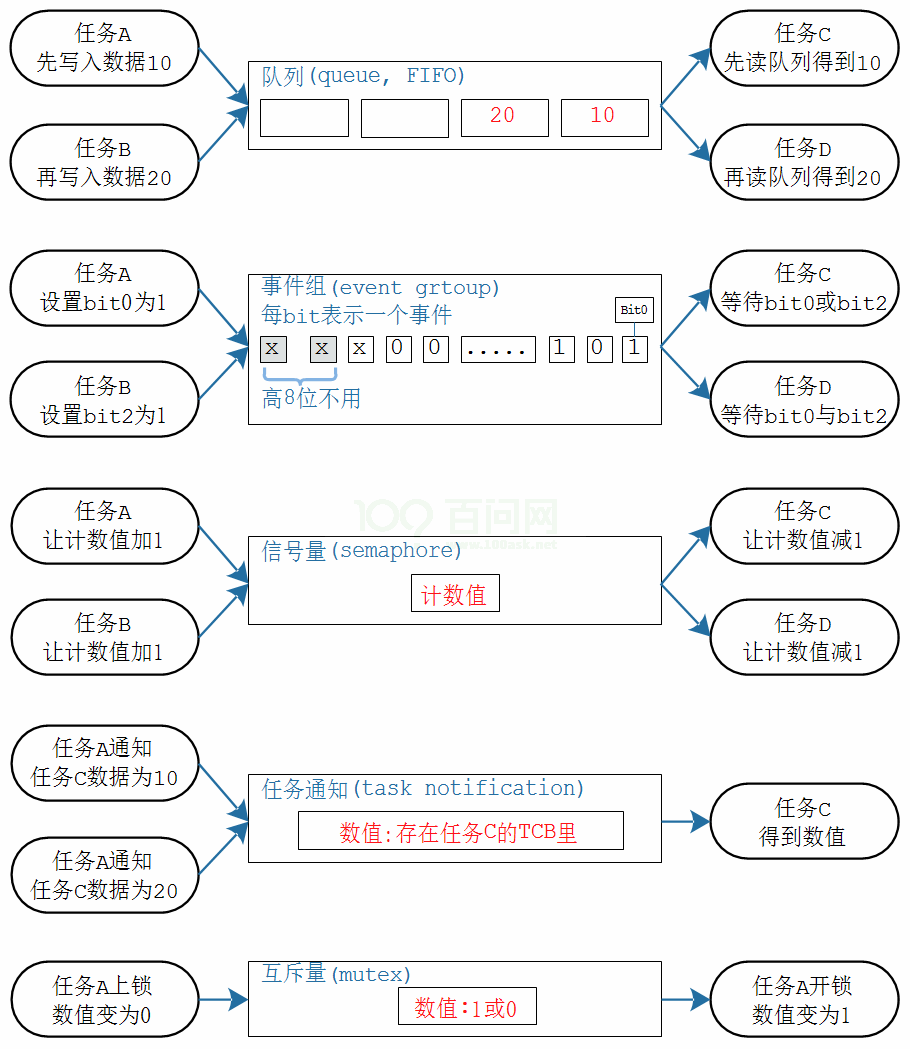
能实现同步、互斥的内核方法有:任务通知(task notification)、队列(queue)、事件组(event group)、信号量(semaphoe)、互斥量(mutex)。
| 内核对象 | 生产者 | 消费者 | 数据/状态 | 说明 |
|---|---|---|---|---|
| 队列 | ALL | ALL | 数据:若干个数据 谁都可以往队列里扔数据, 谁都可以从队列里读数据 | 用来传递数据, 发送者、接收者无限制, 一个数据只能唤醒一个接收者 |
| 事件组 | ALL | ALL | 多个位:或、与 谁都可以设置(生产)多个位, 谁都可以等待某个位、若干个位 | 用来传递事件, 可以是N个事件, 发送者、接受者无限制, 可以唤醒多个接收者:像广播 |
| 信号量 | ALL | ALL | 数量:0~n 谁都可以增加一个数量, 谁都可消耗一个数量 | 用来维持资源的个数, 生产者、消费者无限制, 1个资源只能唤醒1个接收者 |
| 任务通知 | ALL | 只有我 | 数据、状态都可以传输, 使用任务通知时, 必须指定接受者 | N对1的关系: 发送者无限制, 接收者只能是这个任务 |
| 互斥量 | 只能A开锁 | A上锁 | 位:0、1 我上锁:1变为0, 只能由我开锁:0变为1 | 就像一个空厕所, 谁使用谁上锁, 也只能由他开锁 |
RTOS中有多种通信机制。如下图所示。
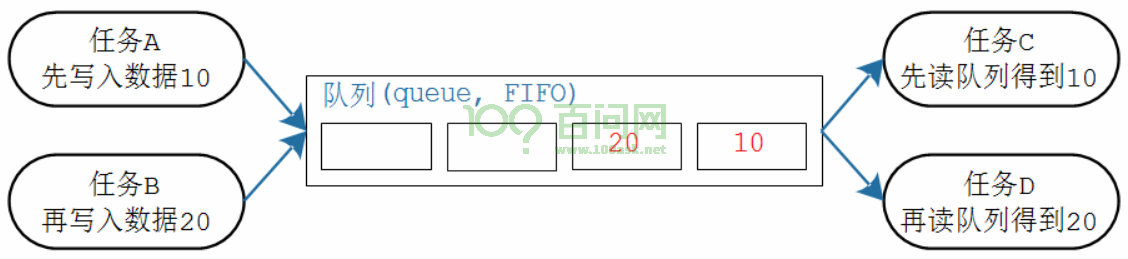
队列
使用队列操作,可以在读任务和写任务中分别定义自己的读写位置,在这种情况下只需要判断队列是否为空,或者是否为满。可以用来解决全局变量在任务中操作的缺陷。
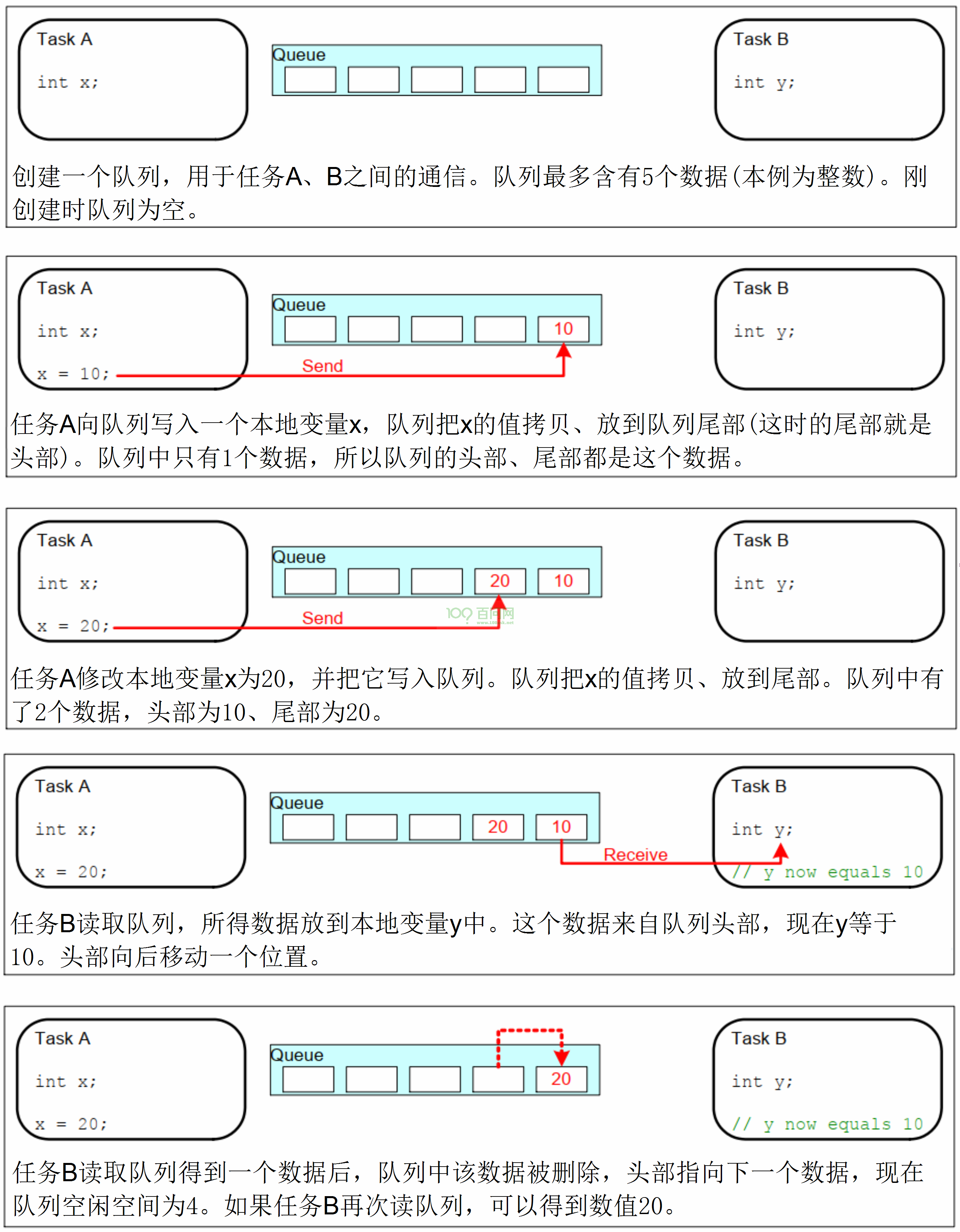
队列数据传输操作有两种
拷贝:把数据、把变量的值复制进队列里
引用:把数据、把变量的地址复制进队列里
FreeRTOS使用拷贝值的方法,这更简单:
- 局部变量的值可以发送到队列中,后续即使函数退出、局部变量被回收,也不会影响队列中的数据
- 无需分配buffer来保存数据,队列中有buffer
- 局部变量可以马上再次使用
- 发送任务、接收任务解耦:接收任务不需要知道这数据是谁的、也不需要发送任务来释放数据
- 如果数据实在太大,你还是可以使用队列传输它的地址
- 队列的空间有FreeRTOS内核分配,无需任务操心
- 对于有内存保护功能的系统,如果队列使用引用方法,也就是使用地址,必须确保双方任务对这个地址都有访问权限。使用拷贝方法时,则无此限制:内核有足够的权限,把数据复制进队列、再把数据复制出队列。
队列的阻塞访问
只要知道队列的句柄,谁都可以读、写该队列。任务、ISR都可读、写队列。可以多个任务读写队列。
读写队列时,如果任务B读队列,但是队列中没有数据,任务B会进入阻塞状态进入QueueRecvList列表与DelayedList(任务超时等待)列表,若队列有数据来,任务B会从这两个链表中移除。如果等待时间(Tick)到了,任务会唤醒DelayList列表。
某个任务读队列时,如果队列没有数据,则该任务可以进入阻塞状态:还可以指定阻塞的时间。如果队列有数据了,则该阻塞的任务会变为就绪态。如果一直都没有数据,则时间到之后它也会进入就绪态。
在多个任务阻塞时任务唤醒优先级
优先唤醒优先级最高的任务。
如果大家的优先级相同,那等待时间最久的任务会进入就绪态。
写任务同样
队列函数
创建:
使用队列的流程:创建队列、写队列、读队列、删除队列。
队列的创建有两种方法:动态分配内存、静态分配内存。
- 动态分配内存:xQueueCreate,队列的内存在函数内部动态分配
- 函数原型:
-
QueueHandle_t xQueueCreate( UBaseType_t uxQueueLength, UBaseType_t uxItemSize );

- 静态分配内存:xQueueCreateStatic,队列的内存要事先分配好
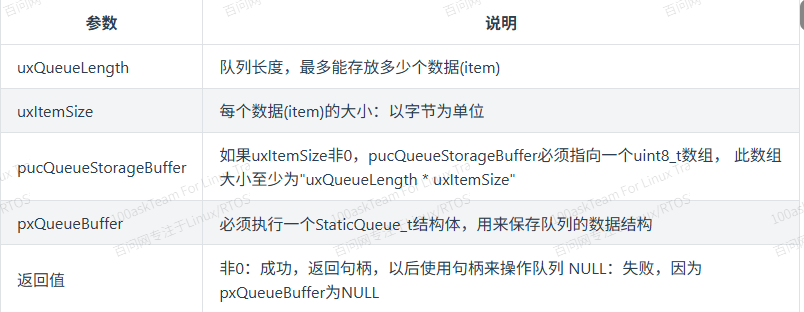
函数原型如下:
QueueHandle_t xQueueCreateStatic(*
UBaseType_t uxQueueLength,*
UBaseType_t uxItemSize,*
uint8_t *pucQueueStorageBuffer,*
StaticQueue_t *pxQueueBuffer*
);
/ 示例代码
#define QUEUE_LENGTH 10
#define ITEM_SIZE sizeof( uint32_t )
// xQueueBuffer用来保存队列结构体
StaticQueue_t xQueueBuffer;
// ucQueueStorage 用来保存队列的数据
// 大小为:队列长度 * 数据大小
uint8_t ucQueueStorage[ QUEUE_LENGTH * ITEM_SIZE ];
void vATask( void *pvParameters )
{
QueueHandle_t xQueue1;
// 创建队列: 可以容纳QUEUE_LENGTH个数据,每个数据大小是ITEM_SIZE
xQueue1 = xQueueCreateStatic( QUEUE_LENGTH,
ITEM_SIZE,
ucQueueStorage,
&xQueueBuffer );
}复位:
队列刚被创建时,里面没有数据;使用过程中可以调用 xQueueReset() 把队列恢复为初始状态,此函数原型为:
/* pxQueue : 复位哪个队列;
* 返回值: pdPASS(必定成功)
*/
BaseType_t xQueueReset( QueueHandle_t pxQueue);删除:
删除队列的函数为 vQueueDelete() ,只能删除使用动态方法创建的队列,它会释放内存。原型如下
void vQueueDelete( QueueHandle_t xQueue );
写队列:
可以把数据写到队列头部,也可以写到尾部,这些函数有两个版本:在任务中使用、在ISR中使用。函数原型如下:
/* 等同于xQueueSendToBack
* 往队列尾部写入数据,如果没有空间,阻塞时间为xTicksToWait
*/
BaseType_t xQueueSend(
QueueHandle_t xQueue,
const void *pvItemToQueue,
TickType_t xTicksToWait
);
/*
* 往队列尾部写入数据,如果没有空间,阻塞时间为xTicksToWait
*/
BaseType_t xQueueSendToBack(
QueueHandle_t xQueue,
const void *pvItemToQueue,
TickType_t xTicksToWait
);
/*
* 往队列尾部写入数据,此函数可以在中断函数中使用,不可阻塞
*/
BaseType_t xQueueSendToBackFromISR(
QueueHandle_t xQueue,
const void *pvItemToQueue,
BaseType_t *pxHigherPriorityTaskWoken
);
/*
* 往队列头部写入数据,如果没有空间,阻塞时间为xTicksToWait
*/
BaseType_t xQueueSendToFront(
QueueHandle_t xQueue,
const void *pvItemToQueue,
TickType_t xTicksToWait
);
/*
* 往队列头部写入数据,此函数可以在中断函数中使用,不可阻塞
*/
BaseType_t xQueueSendToFrontFromISR(
QueueHandle_t xQueue,
const void *pvItemToQueue,
BaseType_t *pxHigherPriorityTaskWoken
);参数

读队列:
使用 xQueueReceive() 函数读队列,读到一个数据后,队列中该数据会被移除。这个函数有两个版本:在任务中使用、在ISR中使用。函数原型如下:
BaseType_t xQueueReceive( QueueHandle_t xQueue,
void * const pvBuffer,
TickType_t xTicksToWait );
BaseType_t xQueueReceiveFromISR(
QueueHandle_t xQueue,
void *pvBuffer,
BaseType_t *pxTaskWoken
);
查询:
可以查询队列中有多少个数据、有多少空余空间。函数原型如下:
/*
* 返回队列中可用数据的个数
*/
UBaseType_t uxQueueMessagesWaiting( const QueueHandle_t xQueue );
/*
* 返回队列中可用空间的个数
*/
UBaseType_t uxQueueSpacesAvailable( const QueueHandle_t xQueue );覆盖/偷看:
当队列长度为1时,可以使用 xQueueOverwrite() 或 xQueueOverwriteFromISR() 来覆盖数据。
注意,队列长度必须为1。当队列满时,这些函数会覆盖里面的数据,这也以为着这些函数不会被阻塞。
函数原型如下:
/* 覆盖队列
* xQueue: 写哪个队列
* pvItemToQueue: 数据地址
* 返回值: pdTRUE表示成功, pdFALSE表示失败
*/
BaseType_t xQueueOverwrite(
QueueHandle_t xQueue,
const void * pvItemToQueue
);
BaseType_t xQueueOverwriteFromISR(
QueueHandle_t xQueue,
const void * pvItemToQueue,
BaseType_t *pxHigherPriorityTaskWoken
);如果想让队列中的数据供多方读取,也就是说读取时不要移除数据,要留给后来人。那么可以使用"窥视",也就是xQueuePeek()或xQueuePeekFromISR()。这些函数会从队列中复制出数据,但是不移除数据。这也意味着,如果队列中没有数据,那么"偷看"时会导致阻塞;一旦队列中有数据,以后每次"偷看"都会成功。
函数原型如下:
/* 偷看队列
* xQueue: 偷看哪个队列
* pvItemToQueue: 数据地址, 用来保存复制出来的数据
* xTicksToWait: 没有数据的话阻塞一会
* 返回值: pdTRUE表示成功, pdFALSE表示失败
*/
BaseType_t xQueuePeek(
QueueHandle_t xQueue,
void * const pvBuffer,
TickType_t xTicksToWait
);
BaseType_t xQueuePeekFromISR(
QueueHandle_t xQueue,
void *pvBuffer,
);信号量



使用信号量之前需要先创建信号量,通过句柄来操作信号量。
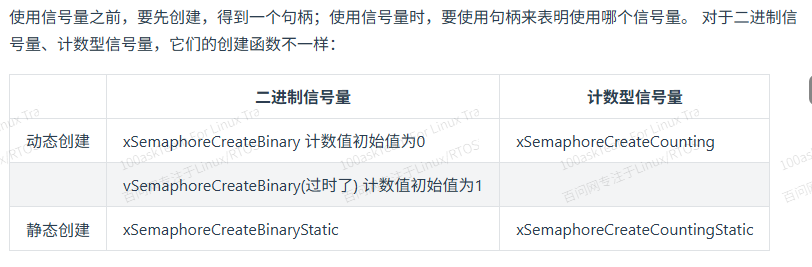
/* 创建一个二进制信号量,返回它的句柄。
* 此函数内部会分配信号量结构体
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateBinary( void );
/* 创建一个二进制信号量,返回它的句柄。
* 此函数无需动态分配内存,所以需要先有一个StaticSemaphore_t结构体,并传入它的指针
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateBinaryStatic( StaticSemaphore_t *pxSemaphoreBuffer );/* 创建一个计数型信号量,返回它的句柄。
* 此函数内部会分配信号量结构体
* uxMaxCount: 最大计数值
* uxInitialCount: 初始计数值
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateCounting(UBaseType_t uxMaxCount, UBaseType_t uxInitialCount);
/* 创建一个计数型信号量,返回它的句柄。
* 此函数无需动态分配内存,所以需要先有一个StaticSemaphore_t结构体,并传入它的指针
* uxMaxCount: 最大计数值
* uxInitialCount: 初始计数值
* pxSemaphoreBuffer: StaticSemaphore_t结构体指针
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateCountingStatic( UBaseType_t uxMaxCount,
UBaseType_t uxInitialCount,
StaticSemaphore_t *pxSemaphoreBuffer );删除信号量
对于动态创建的信号量,不再需要它们时,可以删除它们以回收内存。
vSemaphoreDelete可以用来删除二进制信号量、计数型信号量,函数原型如下:
/*
* xSemaphore: 信号量句柄,你要删除哪个信号量
*/
void vSemaphoreDelete( SemaphoreHandle_t xSemaphore );信号量操作(give,take)
二进制信号量、计数型信号量的give、take操作函数是一样的。这些函数也分为2个版本:给任务使用,给ISR使用。列表如下:
| 在任务中使用 | 在ISR中使用 | |
|---|---|---|
| give | xSemaphoreGive | xSemaphoreGiveFromISR |
| take | xSemaphoreTake | xSemaphoreTakeFromISR |
xSemaphoreGive的函数原型如下:
BaseType_t xSemaphoreGive( SemaphoreHandle_t xSemaphore );xSemaphoreGive函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,释放哪个信号量 |
| 返回值 | pdTRUE表示成功, 如果二进制信号量的计数值已经是1,再次调用此函数则返回失败; 如果计数型信号量的计数值已经是最大值,再次调用此函数则返回失败 |
pxHigherPriorityTaskWoken的函数原型如下:
BaseType_t xSemaphoreGiveFromISR(
SemaphoreHandle_t xSemaphore,
BaseType_t *pxHigherPriorityTaskWoken
);
xSemaphoreGiveFromISR函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,释放哪个信号量 |
| pxHigherPriorityTaskWoken | 如果释放信号量导致更高优先级的任务变为了就绪态, 则*pxHigherPriorityTaskWoken = pdTRUE |
| 返回值 | pdTRUE表示成功, 如果二进制信号量的计数值已经是1,再次调用此函数则返回失败; 如果计数型信号量的计数值已经是最大值,再次调用此函数则返回失败 |
xSemaphoreTake的函数原型如下:
BaseType_t xSemaphoreTake(
SemaphoreHandle_t xSemaphore,
TickType_t xTicksToWait
);
xSemaphoreTake函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,获取哪个信号量 |
| xTicksToWait | 如果无法马上获得信号量,阻塞一会: 0:不阻塞,马上返回 portMAX_DELAY: 一直阻塞直到成功 其他值: 阻塞的Tick个数,可以使用*pdMS_TO_TICKS()*来指定阻塞时间为若干ms |
| 返回值 | pdTRUE表示成功 |
xSemaphoreTakeFromISR的函数原型如下:
BaseType_t xSemaphoreTakeFromISR(
SemaphoreHandle_t xSemaphore,
BaseType_t *pxHigherPriorityTaskWoken
);
xSemaphoreTakeFromISR函数的参数与返回值列表如下:
| 参数 | 说明 |
|---|---|
| xSemaphore | 信号量句柄,获取哪个信号量 |
| pxHigherPriorityTaskWoken | 如果获取信号量导致更高优先级的任务变为了就绪态, 则*pxHigherPriorityTaskWoken = pdTRUE |
| 返回值 | pdTRUE表示成功 |
互斥量
互斥量是一种特殊的二进制信号量。
使用互斥量时,先创建、然后去获得、释放它。使用句柄来表示一个互斥量。
创建互斥量的函数有2种:动态分配内存,静态分配内存,函数原型如下:
/* 创建一个互斥量,返回它的句柄。
* 此函数内部会分配互斥量结构体
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateMutex( void );
/* 创建一个互斥量,返回它的句柄。
* 此函数无需动态分配内存,所以需要先有一个StaticSemaphore_t结构体,并传入它的指针
* 返回值: 返回句柄,非NULL表示成功
*/
SemaphoreHandle_t xSemaphoreCreateMutexStatic( StaticSemaphore_t *pxMutexBuffer );要想使用互斥量,需要在配置文件FreeRTOSConfig.h中定义:

要注意的是,互斥量不能在ISR中使用。
各类操作函数,比如删除、give/take,跟一般是信号量是一样的。
/*
* xSemaphore: 信号量句柄,你要删除哪个信号量, 互斥量也是一种信号量
*/
void vSemaphoreDelete( SemaphoreHandle_t xSemaphore );
/* 释放 */
BaseType_t xSemaphoreGive( SemaphoreHandle_t xSemaphore );
/* 获得 */
BaseType_t xSemaphoreTake(
SemaphoreHandle_t xSemaphore,
TickType_t xTicksToWait
);死锁的概念
日常生活的死锁:我们只招有工作经验的人!我没有工作经验怎么办?那你就去找工作啊!
假设有2个互斥量M1、M2,2个任务A、B:
- A获得了互斥量M1
- B获得了互斥量M2
- A还要获得互斥量M2才能运行,结果A阻塞
- B还要获得互斥量M1才能运行,结果B阻塞
- A、B都阻塞,再无法释放它们持有的互斥量
因为会发生死锁情况,所以要引入递归锁
怎么解决这类问题?可以使用递归锁(Recursive Mutexes),它的特性如下:
-
任务A获得递归锁M后,它还可以多次去获得这个锁
-
"take"了N次,要"give"N次,这个锁才会被释放
递归锁的函数根一般互斥量的函数名不一样,参数类型一样,列表如下:
| 递归锁 | 一般互斥量 | |
|---|---|---|
| 创建 | xSemaphoreCreateRecursiveMutex | xSemaphoreCreateMutex |
| 获得 | xSemaphoreTakeRecursive | xSemaphoreTake |
| 释放 | xSemaphoreGiveRecursive | xSemaphoreGive |
函数原型如下:
/* 创建一个递归锁,返回它的句柄。*
* 此函数内部会分配互斥量结构体*
* 返回值: 返回句柄,非NULL表示成功*
*/
SemaphoreHandle_t xSemaphoreCreateRecursiveMutex( void );
*/ 释放 */
BaseType_t xSemaphoreGiveRecursive( SemaphoreHandle_t xSemaphore );
*/ 获得 */
BaseType_t xSemaphoreTakeRecursive(
SemaphoreHandle_t xSemaphore,
TickType_t xTicksToWait
);事件组
事件组的概念
事件组可以简单地认为就是一个整数:
- 的每一位表示一个事件
- 每一位事件的含义由程序员决定,比如:Bit0表示用来串口是否就绪,Bit1表示按键是否被按下
- 这些位,值为1表示事件发生了,值为0表示事件没发生
- 一个或多个任务、ISR都可以去写这些位;一个或多个任务、ISR都可以去读这些位
- 可以等待某一位、某些位中的任意一个,也可以等待多位
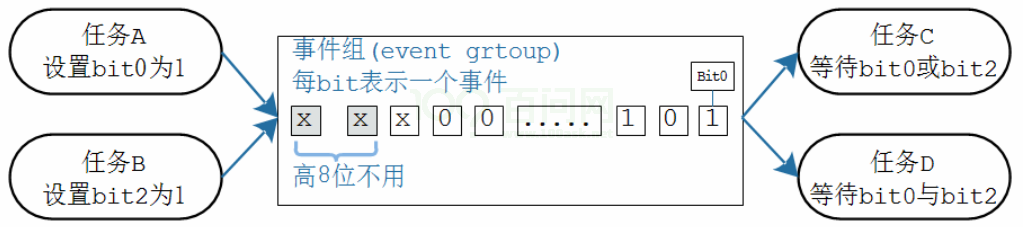
事件组用一个整数来表示,其中的高8位留给内核使用,只能用其他的位来表示事件。那么这个整数是多少位的?
- 如果configUSE_16_BIT_TICKS是1,那么这个整数就是16位的,低8位用来表示事件
- 如果configUSE_16_BIT_TICKS是0,那么这个整数就是32位的,低24位用来表示事件
- configUSE_16_BIT_TICKS是用来表示Tick Count的,怎么会影响事件组?这只是基于效率来考虑
- 如果configUSE_16_BIT_TICKS是1,就表示该处理器使用16位更高效,所以事件组也使用16位
- 如果configUSE_16_BIT_TICKS是0,就表示该处理器使用32位更高效,所以事件组也使用32位
事件组的操作
创建
使用事件组之前,要先创建,得到一个句柄;使用事件组时,要使用句柄来表明使用哪个事件组。
有两种创建方法:动态分配内存、静态分配内存。函数原型如下:
/* 创建一个事件组,返回它的句柄。
* 此函数内部会分配事件组结构体
* 返回值: 返回句柄,非NULL表示成功
*/
EventGroupHandle_t xEventGroupCreate( void );
/* 创建一个事件组,返回它的句柄。
* 此函数无需动态分配内存,所以需要先有一个StaticEventGroup_t结构体,并传入它的指针
* 返回值: 返回句柄,非NULL表示成功
*/
EventGroupHandle_t xEventGroupCreateStatic( StaticEventGroup_t * pxEventGroupBuffer );删除
对于动态创建的事件组,不再需要它们时,可以删除它们以回收内存。
vEventGroupDelete可以用来删除事件组,函数原型如下:
/*
* xEventGroup: 事件组句柄,你要删除哪个事件组
*/
void vEventGroupDelete( EventGroupHandle_t xEventGroup )设置事件
可以设置事件组的某个位、某些位,使用的函数有2个:
- 在任务中使用xEventGroupSetBits()
- 在ISR中使用xEventGroupSetBitsFromISR()
有一个或多个任务在等待事件,如果这些事件符合这些任务的期望,那么任务还会被唤醒。
函数原型如下:
/* 设置事件组中的位
* xEventGroup: 哪个事件组
* uxBitsToSet: 设置哪些位?
* 如果uxBitsToSet的bitX, bitY为1, 那么事件组中的bitX, bitY被设置为1
* 可以用来设置多个位,比如 0x15 就表示设置bit4, bit2, bit0
* 返回值: 返回原来的事件值(没什么意义, 因为很可能已经被其他任务修改了)
*/
EventBits_t xEventGroupSetBits( EventGroupHandle_t xEventGroup,
const EventBits_t uxBitsToSet );
/* 设置事件组中的位
* xEventGroup: 哪个事件组
* uxBitsToSet: 设置哪些位?
* 如果uxBitsToSet的bitX, bitY为1, 那么事件组中的bitX, bitY被设置为1
* 可以用来设置多个位,比如 0x15 就表示设置bit4, bit2, bit0
* pxHigherPriorityTaskWoken: 有没有导致更高优先级的任务进入就绪态? pdTRUE-有, pdFALSE-没有
* 返回值: pdPASS-成功, pdFALSE-失败
*/
BaseType_t xEventGroupSetBitsFromISR( EventGroupHandle_t xEventGroup,
const EventBits_t uxBitsToSet,
BaseType_t * pxHigherPriorityTaskWoken );等待事件
使用xEventGroupWaitBits来等待事件,可以等待某一位、某些位中的任意一个,也可以等待多位;等到期望的事件后,还可以清除某些位。
函数原型如下:
EventBits_t xEventGroupWaitBits( EventGroupHandle_t xEventGroup,
const EventBits_t uxBitsToWaitFor,
const BaseType_t xClearOnExit,
const BaseType_t xWaitForAllBits,
TickType_t xTicksToWait );| 参数 | 说明 |
|---|---|
| xEventGroup | 等待哪个事件组? |
| uxBitsToWaitFor | 等待哪些位?哪些位要被测试? |
| xWaitForAllBits | 怎么测试?是"AND"还是"OR"? pdTRUE: 等待的位,全部为1; pdFALSE: 等待的位,某一个为1即可 |
| xClearOnExit | 函数提出前是否要清除事件? pdTRUE: 清除uxBitsToWaitFor指定的位 pdFALSE: 不清除 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是"非阻塞条件成立"时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
同步点
使用 xEventGroupSync() 函数可以同步多个任务:
- 可以设置某位、某些位,表示自己做了什么事
- 可以等待某位、某些位,表示要等等其他任务
- 期望的时间发生后, xEventGroupSync() 才会成功返回。
- xEventGroupSync成功返回后,会清除事件
xEventGroupSync 函数原型如下:
EventBits_t xEventGroupSync( EventGroupHandle_t xEventGroup,
const EventBits_t uxBitsToSet,
const EventBits_t uxBitsToWaitFor,
TickType_t xTicksToWait );
参数列表如下:
| 参数 | 说明 |
|---|---|
| xEventGroup | 哪个事件组? |
| uxBitsToSet | 要设置哪些事件?我完成了哪些事件? 比如0x05(二进制为0101)会导致事件组的bit0,bit2被设置为1 |
| uxBitsToWaitFor | 等待那个位、哪些位? 比如0x15(二级制10101),表示要等待bit0,bit2,bit4都为1 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是"非阻塞条件成立"时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
参数列表如下:
| 参数 | 说明 |
|---|---|
| xEventGroup | 哪个事件组? |
| uxBitsToSet | 要设置哪些事件?我完成了哪些事件? 比如0x05(二进制为0101)会导致事件组的bit0,bit2被设置为1 |
| uxBitsToWaitFor | 等待那个位、哪些位? 比如0x15(二级制10101),表示要等待bit0,bit2,bit4都为1 |
| xTicksToWait | 如果期待的事件未发生,阻塞多久。 可以设置为0:判断后即刻返回; 可设置为portMAX_DELAY:一定等到成功才返回; 可以设置为期望的Tick Count,一般用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 返回的是事件值, 如果期待的事件发生了,返回的是"非阻塞条件成立"时的事件值; 如果是超时退出,返回的是超时时刻的事件值。 |
示例: 广播
car1运行到终点后,会设置bit0事件;car2、car3都等待bit0事件。car1设置bit0事件时,会通知到car2、car3,这就是一个广播作用。
创建事件组,代码如下:
265 void car_game(void)
266 {
267 int x;
268 int i, j;
269 g_framebuffer = LCD_GetFrameBuffer(&g_xres, &g_yres, &g_bpp);
270 draw_init();
271 draw_end();
272
273 //g_xSemTicks = xSemaphoreCreateCounting(1, 1);
274 //g_xSemTicks = xSemaphoreCreateMutex();
275 g_xEventCar = xEventGroupCreate();
第275行,创建了一个事件组。
car2等待事件,代码如下(car3的代码是一样的):
165 /* 等待事件:bit0 */
166 xEventGroupWaitBits(g_xEventCar, (1<<0), pdTRUE, pdFALSE, portMAX_DELAY);
car1运行到终点后,设置事件,代码如下:
139 /* 设置事件组: bit0 */
140 xEventGroupSetBits(g_xEventCar, (1<<0));
141 vTaskDelete(NULL);
实验现象:car1运行到终点后,car2、car3同时启动。
任务通知(Task Notifications)
我们使用队列、信号量、事件组等等方法时,并不知道对方是谁。使用任务通知时,可以明确指定:通知哪个任务。
使用队列、信号量、事件组时,我们都要事先创建对应的结构体,双方通过中间的结构体通信:

使用任务通知时,任务结构体TCB中就包含了内部对象,可以直接接收别人发过来的"通知":

通知状态和通知值
每个任务都有一个结构体:TCB(Task Control Block),里面有2个成员:
- 一个是uint8_t类型,用来表示通知状态
- 一个是uint32_t类型,用来表示通知值
typedef struct tskTaskControlBlock
{
......
/* configTASK_NOTIFICATION_ARRAY_ENTRIES = 1 */
volatile uint32_t ulNotifiedValue[ configTASK_NOTIFICATION_ARRAY_ENTRIES ];
volatile uint8_t ucNotifyState[ configTASK_NOTIFICATION_ARRAY_ENTRIES ];
......
} tskTCB;
通知状态有3种取值:
- taskNOT_WAITING_NOTIFICATION:任务没有在等待通知
- taskWAITING_NOTIFICATION:任务在等待通知
- taskNOTIFICATION_RECEIVED:任务接收到了通知,也被称为pending(有数据了,待处理)
##define taskNOT_WAITING_NOTIFICATION ( ( uint8_t ) 0 ) /* 也是初始状态 */
##define taskWAITING_NOTIFICATION ( ( uint8_t ) 1 )
##define taskNOTIFICATION_RECEIVED ( ( uint8_t ) 2 )
通知值可以有很多种类型:
- 计数值
- 位(类似事件组)
- 任意数值
任务通知的使用
两类函数
任务通知有2套函数,简化版、专业版,列表如下:
- 简化版函数的使用比较简单,它实际上也是使用专业版函数实现的
- 专业版函数支持很多参数,可以实现很多功能
| 简化版 | 专业版 | |
|---|---|---|
| 发出通知 | xTaskNotifyGive vTaskNotifyGiveFromISR | xTaskNotify xTaskNotifyFromISR |
| 取出通知 | ulTaskNotifyTake | xTaskNotifyWait |
xTaskNotifyGive/ulTaskNotifyTake
在任务中使用xTaskNotifyGive函数,在ISR中使用vTaskNotifyGiveFromISR函数,都是直接给其他任务发送通知:
- 使得通知值加一
- 并使得通知状态变为"pending",也就是taskNOTIFICATION_RECEIVED,表示有数据了、待处理
可以使用ulTaskNotifyTake函数来取出通知值:
- 如果通知值等于0,则阻塞(可以指定超时时间)
- 当通知值大于0时,任务从阻塞态进入就绪态
- 在ulTaskNotifyTake返回之前,还可以做些清理工作:把通知值减一,或者把通知值清零
使用ulTaskNotifyTake函数可以实现轻量级的、高效的二进制信号量、计数型信号量。
这几个函数的原型如下:
BaseType_t xTaskNotifyGive( TaskHandle_t xTaskToNotify );
void vTaskNotifyGiveFromISR( TaskHandle_t xTaskHandle, BaseType_t *pxHigherPriorityTaskWoken );
uint32_t ulTaskNotifyTake( BaseType_t xClearCountOnExit, TickType_t xTicksToWait );
xTaskNotifyGive函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskToNotify | 任务句柄(创建任务时得到),给哪个任务发通知 |
| 返回值 | 必定返回pdPASS |
vTaskNotifyGiveFromISR函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskHandle | 任务句柄(创建任务时得到),给哪个任务发通知 |
| pxHigherPriorityTaskWoken | 被通知的任务,可能正处于阻塞状态。 此函数发出通知后,会把它从阻塞状态切换为就绪态。 如果被唤醒的任务的优先级,高于当前任务的优先级, 则"*pxHigherPriorityTaskWoken"被设置为pdTRUE, 这表示在中断返回之前要进行任务切换。 |
ulTaskNotifyTake函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xClearCountOnExit | 函数返回前是否清零: pdTRUE:把通知值清零 pdFALSE:如果通知值大于0,则把通知值减一 |
| xTicksToWait | 任务进入阻塞态的超时时间,它在等待通知值大于0。 0:不等待,即刻返回; portMAX_DELAY:一直等待,直到通知值大于0; 其他值:Tick Count,可以用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 函数返回之前,在清零或减一之前的通知值。 如果xTicksToWait非0,则返回值有2种情况: 1. 大于0:在超时前,通知值被增加了 2. 等于0:一直没有其他任务增加通知值,最后超时返回0 |
xTaskNotify/xTaskNotifyWait
xTaskNotify 函数功能更强大,可以使用不同参数实现各类功能,比如:
- 让接收任务的通知值加一:这时 xTaskNotify() 等同于 xTaskNotifyGive()
- 设置接收任务的通知值的某一位、某些位,这就是一个轻量级的、更高效的事件组
- 把一个新值写入接收任务的通知值:上一次的通知值被读走后,写入才成功。这就是轻量级的、长度为1的队列
- 用一个新值覆盖接收任务的通知值:无论上一次的通知值是否被读走,覆盖都成功。类似 xQueueOverwrite() 函数,这就是轻量级的邮箱。
xTaskNotify() 比 xTaskNotifyGive() 更灵活、强大,使用上也就更复杂。xTaskNotifyFromISR() 是它对应的ISR版本。
这两个函数用来发出任务通知,使用哪个函数来取出任务通知呢?
使用 xTaskNotifyWait() 函数!它比 ulTaskNotifyTake() 更复杂:
- 可以让任务等待(可以加上超时时间),等到任务状态为"pending"(也就是有数据)
- 还可以在函数进入、退出时,清除通知值的指定位
这几个函数的原型如下:
BaseType_t xTaskNotify( TaskHandle_t xTaskToNotify, uint32_t ulValue, eNotifyAction eAction );
BaseType_t xTaskNotifyFromISR( TaskHandle_t xTaskToNotify,
uint32_t ulValue,
eNotifyAction eAction,
BaseType_t *pxHigherPriorityTaskWoken );
BaseType_t xTaskNotifyWait( uint32_t ulBitsToClearOnEntry,
uint32_t ulBitsToClearOnExit,
uint32_t *pulNotificationValue,
TickType_t xTicksToWait );
xTaskNotify函数的参数说明如下:
| 参数 | 说明 |
|---|---|
| xTaskToNotify | 任务句柄(创建任务时得到),给哪个任务发通知 |
| ulValue | 怎么使用ulValue,由eAction参数决定 |
| eAction | 见下表 |
| 返回值 | pdPASS:成功,大部分调用都会成功 pdFAIL:只有一种情况会失败,当eAction为eSetValueWithoutOverwrite, 并且通知状态为"pending"(表示有新数据未读),这时就会失败。 |
eNotifyAction参数说明:
| eNotifyAction取值 | 说明 |
|---|---|
| eNoAction | 仅仅是更新通知状态为"pending",未使用ulValue。 这个选项相当于轻量级的、更高效的二进制信号量。 |
| eSetBits | 通知值 = 原来的通知值 | ulValue,按位或。 相当于轻量级的、更高效的事件组。 |
| eIncrement | 通知值 = 原来的通知值 + 1,未使用ulValue。 相当于轻量级的、更高效的二进制信号量、计数型信号量。 相当于**xTaskNotifyGive()**函数。 |
| eSetValueWithoutOverwrite | 不覆盖。 如果通知状态为"pending"(表示有数据未读), 则此次调用xTaskNotify不做任何事,返回pdFAIL。 如果通知状态不是"pending"(表示没有新数据), 则:通知值 = ulValue。 |
| eSetValueWithOverwrite | 覆盖。 无论如何,不管通知状态是否为"pendng", 通知值 = ulValue。 |
xTaskNotifyFromISR函数跟xTaskNotify很类似,就多了最后一个参数pxHigherPriorityTaskWoken。在很多ISR函数中,这个参数的作用都是类似的,使用场景如下:
- 被通知的任务,可能正处于阻塞状态
- xTaskNotifyFromISR函数发出通知后,会把接收任务从阻塞状态切换为就绪态
- 如果被唤醒的任务的优先级,高于当前任务的优先级,则"*pxHigherPriorityTaskWoken"被设置为pdTRUE,这表示在中断返回之前要进行任务切换。
xTaskNotifyWait函数列表如下:
| 参数 | 说明 |
|---|---|
| ulBitsToClearOnEntry | 在xTaskNotifyWait入口处,要清除通知值的哪些位? 通知状态不是"pending"的情况下,才会清除。 它的本意是:我想等待某些事件发生,所以先把"旧数据"的某些位清零。 能清零的话:通知值 = 通知值 & ~(ulBitsToClearOnEntry)。 比如传入0x01,表示清除通知值的bit0; 传入0xffffffff即ULONG_MAX,表示清除所有位,即把值设置为0 |
| ulBitsToClearOnExit | 在xTaskNotifyWait出口处,如果不是因为超时推出,而是因为得到了数据而退出时: 通知值 = 通知值 & ~(ulBitsToClearOnExit)。 在清除某些位之前,通知值先被赋给"*pulNotificationValue"。 比如入0x03,表示清除通知值的bit0、bit1; 传入0xffffffff即ULONG_MAX,表示清除所有位,即把值设置为0 |
| pulNotificationValue | 用来取出通知值。 在函数退出时,使用ulBitsToClearOnExit清除之前,把通知值赋给"*pulNotificationValue"。 如果不需要取出通知值,可以设为NULL。 |
| xTicksToWait | 任务进入阻塞态的超时时间,它在等待通知状态变为"pending"。 0:不等待,即刻返回; portMAX_DELAY:一直等待,直到通知状态变为"pending"; 其他值:Tick Count,可以用*pdMS_TO_TICKS()*把ms转换为Tick Count |
| 返回值 | 1. pdPASS:成功 这表示xTaskNotifyWait成功获得了通知: 可能是调用函数之前,通知状态就是"pending"; 也可能是在阻塞期间,通知状态变为了"pending"。 2. pdFAIL:没有得到通知。 |

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 36
36 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)