嵌入式知识总结复习
主要硬件通信方式:
串行(相对并行慢):多个数据,利用 一条线 发送 (用的多)
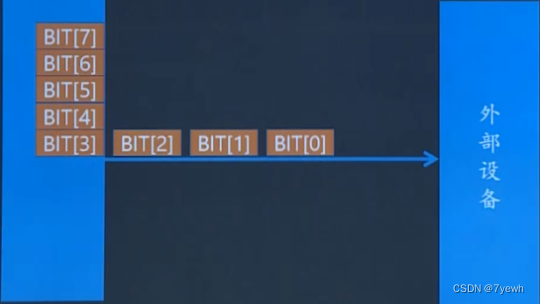
并行(相对串行快):多个数据,利用 多条线 发送

单工通信:单向;主机从机,区分发送器以及接收器;只可以发送器给接收器发送数据;
| 对比维度 | 单工通信 | 双工通信(含全双工 / 半双工) |
|---|---|---|
| 传输方向 | 单向(发送端→接收端) | 双向(双方可互发) |
| 同时性 | 无(仅一方发送) | 全双工:可同时发送;半双工:不可同时 |
| 设备复杂度 | 低(只需发送或接收设备,无需切换) | 高(需双向传输模块,半双工需切换机制) |
| 信道占用 | 占用单信道 | 全双工需双信道(如上下行频段);半双工用单信道交替 |
| 典型应用 | 广播、电视、红外遥控器 | 全双工:电话、手机通信;半双工:对讲机、以太网(早期) |
UART:
特点:异步串行全双工(低位在前)
UART 的数据帧格式
[起始位] + [数据位] + [校验位] + [停止位]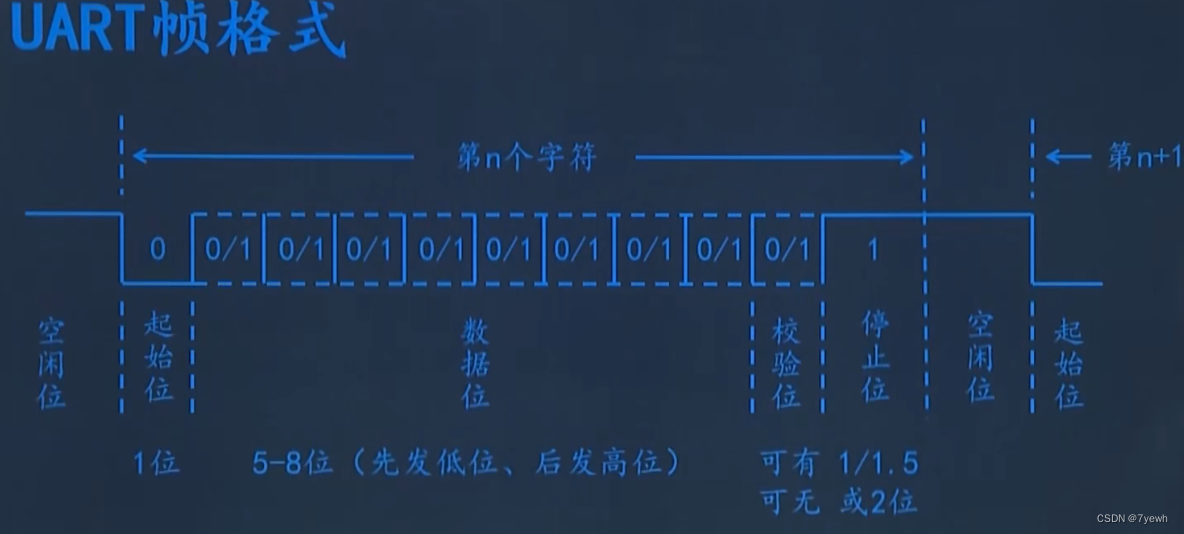 起始位:1 个逻辑 0(低电平),表示一帧数据的开始,用于唤醒接收方。
起始位:1 个逻辑 0(低电平),表示一帧数据的开始,用于唤醒接收方。
数据位:5-9 位(常用 8 位),承载实际传输的有效数据(如 ASCII 字符)。
校验位(可选):用于校验数据传输是否出错,有奇校验、偶校验、无校验等方式:
奇校验:数据位中 1 的个数为奇数,校验位补 0 或 1 使总数为奇;偶校验:同理,确保 1 的总数为偶数。停止位:1-2 个逻辑 1(高电平),表示一帧数据的结束,接收方通过停止位判断帧的边界。
缺点:传输速率较慢(通常≤1Mbps);抗干扰能力较弱(长距离传输易出错);依赖波特率匹配(双方需一致,否则数据错乱)。
电气接口不统一:UART只是对信号的时序进行了定义,没有定义接口的电气特性,没有连接器的标准。也就是时序上我只是定义了高电平跟低电平 但是高电平是多少 低电平是多少 在每个板子 不同环境都有标准
抗干扰能力差:TTL信号抗干扰能力差,容易出错
RS232:
解决UART通信距离短的问题。
接口:9线制,但是真正用的一般来说只有三根线:TX、RX、GND
信号:逻辑 “1” 高电平为 -5V到-15V、逻辑 “0” 低电平为 5V到15V
RS485:
异步串行半双工
RS485 是一种广泛应用于工业控制领域的差分串行通信标准,由 RS232 发展而来,主要解决长距离、多设备通信的需求。它通过差分信号传输提升抗干扰能力,支持多点通信,是工业自动化、楼宇控制等场景的常用通信方式。
特点:
需要四根线,芯片(MAX485、SN75176)
- A(非反向数据)、B(反向数据):传输差分信号;
- GND(地线):提供参考电平,减少共模干扰;
- 屏蔽线(可选):连接设备外壳,进一步抗干扰。
差分信号传输(定义:当 A 线电压比 B 线高 200mV 以上时,表示逻辑 “1”;当 B 线比 A 线高 200mV 以上时,表示逻辑 “0”。)相对稳定
多节点通信支持一主多从或多主多从拓扑结构,总线上最多可连接 32 个节点(通过中继器可扩展至更多),适合多设备组网。
附上一篇MAX485通信案例
MAX485芯片收发详解 实现485通信_max485典型电路图-CSDN博客
IIC
常用:同步、串行、半双工、多主机总线、近距离、低速、芯片与芯片之间的通信;
通过时钟信号(SCL)实现数据同步,传输速率由时钟频率决定(标准模式 100kbps、快速模式 400kbps、高速模式 3.4Mbps)
仅需两根信号线即可通信:
SDA(Serial Data):串行数据线,用于双向传输数据;
SCL(Serial Clock):串行时钟线,由主设备控制,同步数据传输节奏。
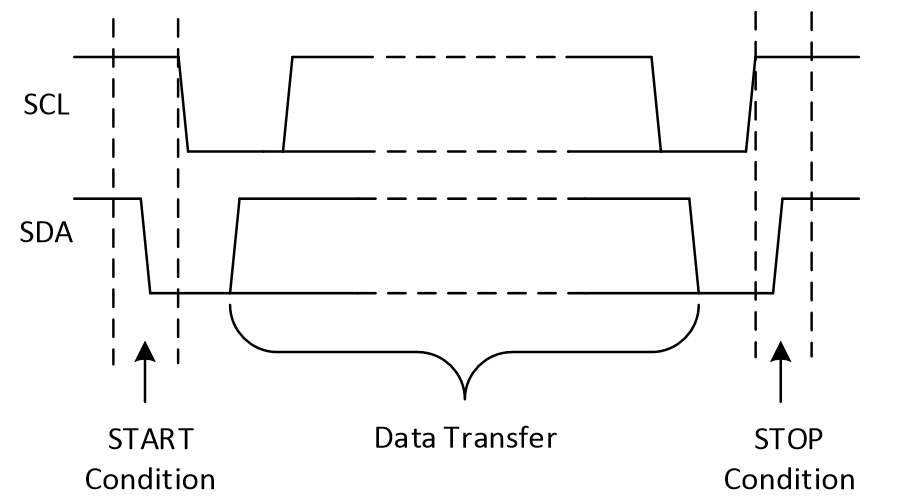
开始/结束信号:
开始信号:SCL为高电平时SDA有高到底
结束信号:SCL为高点平时SDA由低到高
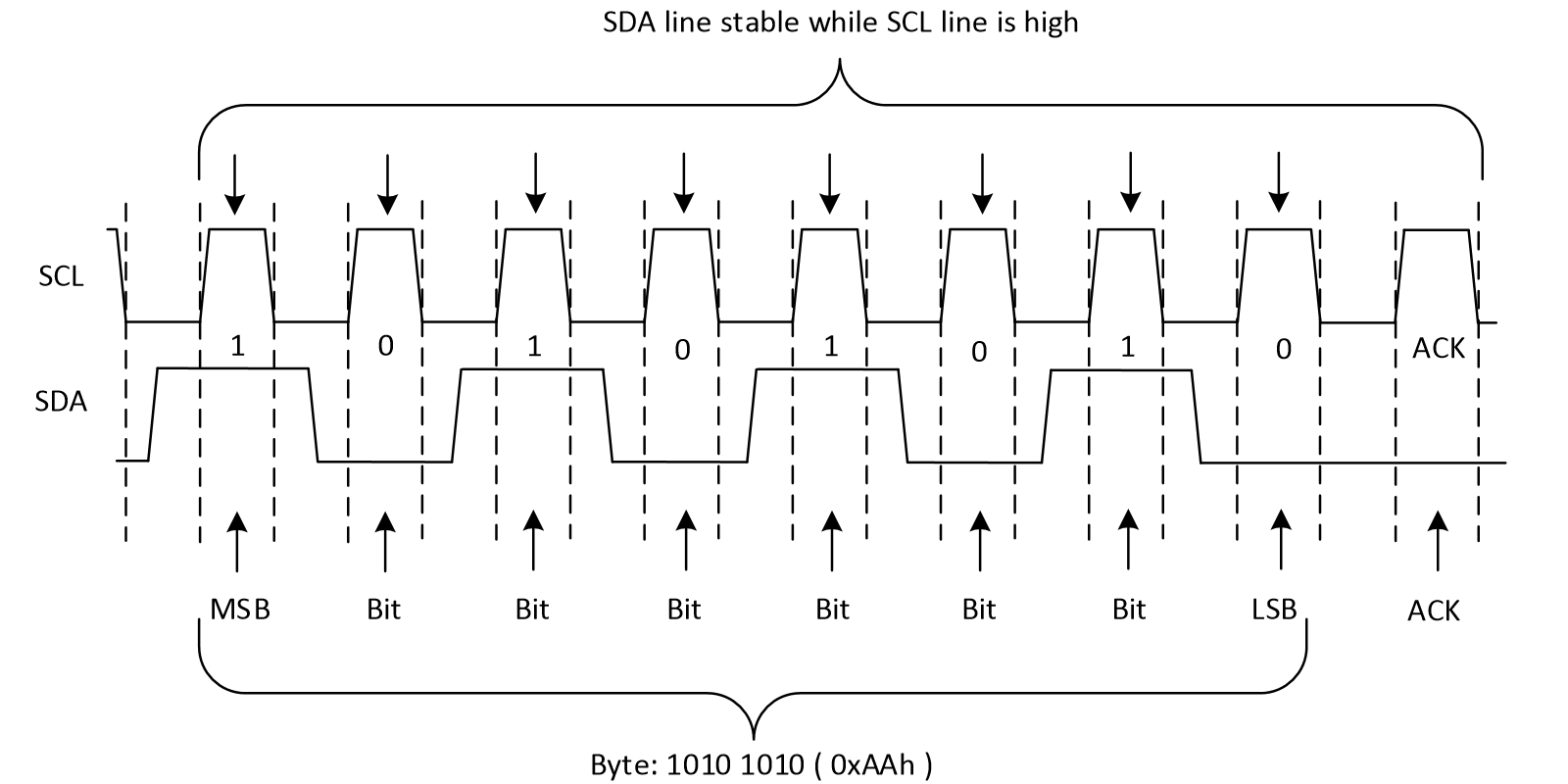
数据传输
SDA数据线上的每个字节必须是8位,对于每次传输的字节数没有限制。每个字节(8位)数据传送完后紧跟着应答信号(ACK,第9位)。数据的先后顺序为:高位在前 。数据在SCL为高电平是读取。SCL为低电平时SDA数据改变。
SPI
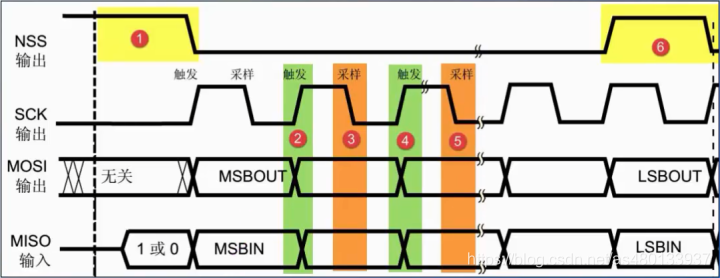
串行,全双工,高速,同步
特点:最少需要 4 根信号线:
- SCK(Serial Clock):串行时钟线,由主设备输出,控制数据传输节奏;
- MOSI(Master Out Slave In):主设备输出 / 从设备输入线,主设备向从设备发送数据;
- MISO(Master In Slave Out):主设备输入 / 从设备输出线,从设备向主设备返回数据;
- SS(Slave Select):从设备选择线(片选),主设备通过拉低某一从设备的 SS 线选中该设备(低电平有效)。
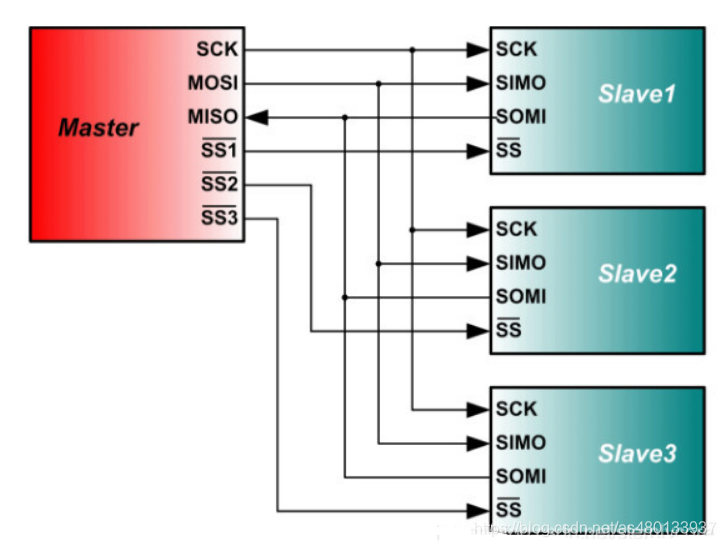
总线上有一个主设备和多个从设备,主设备通过不同的 SS 线单独选中某个从设备进行通信,避免冲突。
连接方式
通信方式
SPI 的主要模式
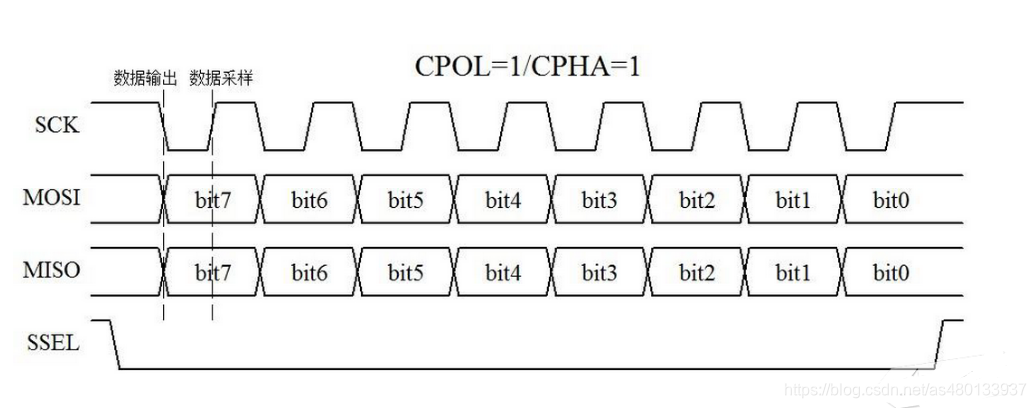
SPI 的时钟极性(CPOL)和时钟相位(CPHA)可组合成 4 种模式,主从设备需使用相同模式才能正确通信:
- CPOL(Clock Polarity):时钟空闲时的电平(0 表示空闲为低电平,1 表示空闲为高电平);
- CPHA(Clock Phase):数据采样的时钟边沿(0 表示在时钟上升沿采样,1 表示在时钟下降沿采样)。
4 种模式组合:
- 模式 0:CPOL=0,CPHA=0(最常用,空闲低电平,上升沿采样);
- 模式 1:CPOL=0,CPHA=1(空闲低电平,下降沿采样);
- 模式 2:CPOL=1,CPHA=0(空闲高电平,下降沿采样);
- 模式 3:CPOL=1,CPHA=1(空闲高电平,上升沿采样)。
CAN总线
CAN是串行通信总线,专为汽车和工业控制领域设计,具有高可靠性、实时性和抗干扰能力,能在多节点间实现高效的数据交互。
一、CAN 总线的核心特点
-
多主通信
总线上所有节点地位平等,均可主动发送数据(无主从之分),适合分布式控制系统。 -
非破坏性总线仲裁
多个节点同时发送数据时,通过标识符(ID)优先级自动仲裁:ID 值越小,优先级越高,高优先级消息会 “抢占” 总线,低优先级节点自动停止发送,避免冲突且不破坏已发送数据。 -
差分信号传输
使用两根信号线(CAN_H 和 CAN_L)传输差分信号,抗电磁干扰能力强,适合工业和汽车等恶劣环境。 -
长距离与多节点
传输速率与距离成反比:低速(125kbps)时可传输 10km,高速(1Mbps)时传输距离约 40m;最多支持 110 个节点(通过中继器可扩展)。 -
错误检测与处理
内置多种错误检测机制(位错误、 CRC 错误等),出错时自动重发,确保数据可靠性。
二、CAN 总线的硬件结构
-
信号线
- CAN_H:高电平信号线
- CAN_L:低电平信号线
- 总线空闲时,CAN_H 和 CAN_L 分别为 2.5V(差分电压 0V);
- 传输显性位(逻辑 0)时,CAN_H=3.5V,CAN_L=1.5V(差分电压 2V);
- 传输隐性位(逻辑 1)时,恢复为空闲状态(差分电压 0V)。
-
节点组成
每个节点包含:- MCU:处理数据
- CAN 控制器:生成 / 解析 CAN 帧
- CAN 收发器:将数字信号转换为差分信号(如 TJA1050)
-
终端电阻
总线两端需接 120Ω 终端电阻(匹配总线特性阻抗),减少信号反射。
CAN 总线数据以 “帧” 为单位传输,最常用的是数据帧,结构如下:
[帧起始] + [仲裁场] + [控制场] + [数据场] + [CRC场] + [ACK场] + [帧结束]- 仲裁场:包含 11 位标准 ID(或 29 位扩展 ID),决定消息优先级(ID 越小优先级越高);
- 数据场:可传输 0~8 字节数据(确保实时性);
- CRC 场:循环冗余校验,检测传输错误;
- ACK 场:接收节点确认收到正确数据。
C语言宏中"#“和"##"的用法
1. # 运算符(字符串化)
# 运算符用于将宏参数转换为字符串常量。当宏参数前面加上 # 时,预处理阶段会将该参数直接转换为用双引号括起来的字符串。
#include <stdio.h>
// 定义一个带#的宏,将参数转换为字符串
#define STR(x) #x
int main() {
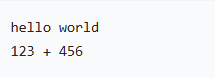
printf(STR(hello world)); // 等价于 printf("hello world")
printf("\n");
printf(STR(123 + 456)); // 等价于 printf("123 + 456")
return 0;
}输出
2. ## 运算符(符号连接)
## 运算符用于将两个符号(标识符、宏参数等)连接成一个新的符号。预处理阶段会将 ## 两边的符号合并为一个整体。
#include <stdio.h>
// 定义一个带##的宏,连接两个参数
#define CONCAT(a, b) a##b
int main() {
int num123 = 100;
printf("%d\n", CONCAT(num, 123)); // 等价于 printf("%d\n", num123)
int var1 = 10, var2 = 20;
printf("%d\n", CONCAT(var, 1)); // 等价于 printf("%d\n", var1)
return 0;
}输出
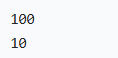
3. 组合使用示例
# 和 ## 可以在同一个宏中配合使用,实现更复杂的功能:
#include <stdio.h>
// 定义一个宏,同时使用#和##
#define DEFINE_VAR(type, name) type var##name; \
printf("Defined " #type " variable: var" #name "\n")
int main() {
DEFINE_VAR(int, 1); // 等价于 int var1; printf("Defined int variable: var1\n")
DEFINE_VAR(float, 2); // 等价于 float var2; printf("Defined float variable: var2\n")
var1 = 100;
var2 = 3.14f;
printf("var1 = %d, var2 = %.2f\n", var1, var2);
return 0;
}输出

4.关键字volatile
在 C 语言中,volatile 是一个类型修饰符(关键字),用于告诉编译器:被修饰的变量可能会被程序之外的因素意外修改(如硬件、中断服务程序等),因此编译器不应对该变量进行优化,每次每次使用时都必须从内存中重新读取其值,而不能使用寄存器中的缓存值。
典型使用场景
-
硬件寄存器访问
硬件设备的寄存器(如传感器数据、定时器值)可能会被硬件自动修改,必须用volatile修饰,否则编译器可能会优化掉对该寄存器的重复读取。volatile unsigned int *sensor_data = (unsigned int *)0x12345678; // 硬件寄存器地址 while (*sensor_data == 0); // 等待传感器数据就绪(必须每次从内存读取) -
中断服务程序(ISR)与主程序共享的变量
中断程序可能会修改某个变量,主程序读取该变量时必须获取最新值,需用volatile修饰。volatile int flag = 0; // 中断与主程序共享的标志 // 中断服务程序 void interrupt_handler() { flag = 1; // 中断中修改标志 } // 主程序 int main() { while (flag == 0); // 等待中断触发(必须每次从内存读取flag) // ... return 0; } -
多线程共享变量(无锁情况下)
在多线程环境中,一个线程修改的变量可能被另一个线程读取,volatile可确保读取到最新值(但需注意:volatile不保证原子性,不能替代线程同步机制)。
5.Static关键字
三个情况,都存储在全局数据区(静态存储区)
模块全局静态变量,作用域在整个文件,生命周期随着程序终止而消亡。
函数内静态变量,作用域仅限于定义它的函数内部,生命周期随着程序终止而消亡。
静态函数,核心特性是作用域被限制在定义它的源文件(.c 文件)内部,无法被其他源文件调用。避免命明冲突。

6.Const关键字
6.1.定义变量为常量
局部变量或全局变量 可以通过 const 来定义为常量,一旦赋值后,该常量的值就不能被修改。
const int N = 100; // 定义常量N,值为100
// N = 50; // 错误:常量的值不能被修改
const int n; // 错误:常量在定义时必须初始化
6.2.修饰函数的参数
使用 const 修饰函数参数,表示该参数在函数体内不能被修改。这样可以保证函数不会无意间修改传入的参数值,增加代码的可维护性。
void func(const int x) {
// x = 10; // 错误:x 是常量,不能修改
}
6.3.修饰函数的返回值
a. 返回指针类型并使用 const 修饰
当函数返回指针时,若用 const 修饰返回值类型,那么返回的指针所指向的数据内容不能被修改,同时该指针也只能赋值给被 const 修饰的指针。
const char* GetString() {
return "Hello";
}
const char* str = GetString(); // 正确,str 被声明为 const
// char* str = GetString(); // 错误,str 未声明为 const,不能修改返回值
b. 返回普通类型并使用 const 修饰
如果 const 用于修饰普通类型的返回值,如 int,由于返回值是临时的副本,在函数调用结束后,返回值的生命周期也随之结束,因此将其修饰为 const 是没有意义的。
const int GetValue() {
return 5;
}
int x = GetValue(); // 正确,返回值可以赋给普通变量
// const int y = GetValue(); // 不必要的,因为返回值会是临时变量,不会被修改
6.4.节省空间,避免不必要的内存分配
const 关键字还可以帮助优化内存管理。当你使用 const 来定义常量时,编译器会考虑将常量放入只读存储区,避免了额外的内存分配。对于宏(#define)和 const 常量,它们在内存分配的方式上有所不同。
使用宏定义的常量(如 PI)会在编译时进行文本替换,所有使用该宏的地方都会被替换为常量值,因此不会单独分配内存;而 const 常量则会在内存中分配空间,通常存储在只读数据区。
宏定义常量的每次使用都会进行文本替换,因此会进行额外的内存分配。相反,const 常量只会分配一次内存。
#define PI 3.14159 // 使用宏定义常量 PI
const double pi = 3.14159; // 使用 const 定义常量 pi
7.new/delete与malloc/free的区别是什么?
new/delete 和 malloc/free 都是用于动态内存管理的工具,但它们分属不同的编程语言范畴(C++ vs C),在功能和使用上有显著区别:
1. 所属语言与本质
-
malloc/free:
是 C 语言的标准库函数,在 C++ 中也可使用。malloc(size):仅负责分配指定大小(字节数)的内存块,返回void*指针,需手动转换为具体类型。free(ptr):仅释放指针指向的内存,不做其他操作。
-
new/delete:
是 C++ 的关键字,而非函数。new T:不仅分配内存,还会自动调用类型T的构造函数初始化对象。delete ptr:不仅释放内存,还会先调用对象的析构函数清理资源。
2. 内存分配方式
-
malloc:需要显式指定分配的字节数,例如:int* p = (int*)malloc(10 * sizeof(int)); // 分配10个int的内存(需计算字节数) -
new:根据类型自动计算所需内存大小,无需手动计算字节数,例如:int* p = new int[10]; // 直接指定元素个数,自动计算大小
3. 返回类型
malloc:返回void*,必须显式强制转换为目标类型指针,否则编译报错(C++ 中)。new:返回与类型匹配的指针,无需强制转换,例如:int* p = new int; // 正确,自动匹配int*类型
4. 对对象的处理(核心区别)
这是两者最关键的区别,体现在对类对象的管理上:
-
malloc/free:仅处理内存分配与释放,不会调用构造函数和析构函数。
若用于类对象,会导致对象未初始化或资源未释放(如文件句柄、动态内存等),造成内存泄漏。示例(错误用法):
class MyClass { public: MyClass() { printf("构造函数\n"); } // 不会被malloc调用 ~MyClass() { printf("析构函数\n"); } // 不会被free调用 }; MyClass* p = (MyClass*)malloc(sizeof(MyClass)); // 仅分配内存,未初始化 free(p); // 仅释放内存,未调用析构函数 -
new/delete:会自动调用构造函数和析构函数,确保对象正确初始化和资源释放。示例(正确用法):
MyClass* p = new MyClass(); // 分配内存 + 调用构造函数 delete p; // 调用析构函数 + 释放内存
5. 数组处理
-
malloc/free:分配数组内存后,释放时与普通内存相同(仅用free):int* arr = (int*)malloc(5 * sizeof(int)); free(arr); // 释放数组内存 -
new/delete:数组需用new[]分配,delete[]释放(否则可能导致部分析构函数不被调用):MyClass* arr = new MyClass[3]; // 分配数组 + 调用3次构造函数 delete[] arr; // 调用3次析构函数 + 释放内存(必须用delete[])
6. 错误处理
-
malloc:分配失败时返回NULL,需手动检查:int* p = (int*)malloc(1024); if (p == NULL) { // 必须检查是否分配成功 // 处理错误 } -
new:分配失败时默认抛出bad_alloc异常(C++ 标准),无需手动检查返回值,可通过异常捕获处理:try { int* p = new int[1024]; // 失败时抛出异常 } catch (const std::bad_alloc& e) { // 处理错误 }
总结对比表
| 特性 | malloc/free |
new/delete |
|---|---|---|
| 语言 | C/C++ 标准库函数 | C++ 关键字 |
| 功能 | 仅分配 / 释放内存 | 分配内存 + 构造函数 / 析构函数 + 释放内存 |
| 类型转换 | 需要显式转换(void*→目标类型) |
自动匹配类型,无需转换 |
| 数组处理 | 统一用 malloc/free |
需用 new[]/delete[] |
| 错误处理 | 返回 NULL |
抛出 bad_alloc 异常 |
| 适用场景 | C 语言 / C++ 中纯内存分配 | C++ 中对象的动态创建与销毁 |
8.strlen("\0")与sizeof("\0")
strlen("\0")结果为 0(遇到第一个'\0'就停止计数,不包含该字符)。sizeof("\0")结果为 2(包含显式的'\0'和字符串默认的终止符'\0',共 2 个字节)。
1. 本质不同
sizeof:是 C 语言的运算符(不是函数),在编译阶段就计算结果。strlen:是 C 语言标准库函数(声明在<string.h>中),在程序运行时才计算结果。
2. 功能不同
-
sizeof:计算操作数所占用的内存字节数。
操作数可以是变量、数据类型、数组、字符串字面量等,结果包含所有内存空间(包括结束符'\0'等)。 -
strlen:计算字符串的有效长度(仅用于字符串)。
从起始地址开始遍历,直到遇到第一个'\0'(空字符)为止,结果不包含这个终止符'\0'。
| 特性 | sizeof |
strlen |
|---|---|---|
| 本质 | 运算符(编译期计算) | 库函数(运行期计算) |
| 功能 | 计算内存字节数 | 计算字符串有效长度 |
| 适用范围 | 所有数据类型 / 变量 / 表达式 | 仅以'\0'结尾的字符串 |
是否包含'\0' |
是(计算字符串时包含终止符) | 否(遇到'\0'即停止) |
| 依赖终止符 | 不依赖(对字符串只是正常计算字节) |
必须依赖(否则可能陷入死循环)
|
9.C语言中 struct与 union
| 特性 | struct(结构体) |
union(共用体) |
|---|---|---|
| 内存分配 | 成员各自独立占用内存,总大小为成员之和(+ 填充) | 所有成员共享内存,总大小为最大成员大小(+ 填充) |
| 成员访问 | 可同时访问所有成员,互不影响 | 同一时间只能有效访问一个成员,修改会覆盖其他成员 |
| 内存效率 | 内存占用较大(成员独立) | 内存效率高(共享内存) |
| 典型用途 | 组合相关数据,需同时使用多个成员 | 节省内存、类型转换、解析二进制数据 |
预处理
1.预处理中#erroe
#error预处理指令的作用是,编译程序时,只要遇到#error就会生成一个编译错误提示消息,并停止编译。其语法格式为:#error error-message。
下面举个例子:
#ifdef XXX
#error “xxx has been defined'
#else
#endif
2.# define还是 const
1.define只是用来进行单纯的文本替换 ,define常量的生命周期止于编译期,不分配内存空间,它存在于程序的代码段,在实际程序中,它只是一个常数:而 const常量存在于程序的数据段,并在堆栈中分配了空间,const常量在程序中确确实实存在,并且可以被调用、传递
2.const常量有数据类型,而 define常量没有数据类型。编译器可以对 const常量进行类型安全检査,如类型、语句结构等,而 define不行。
3.很多IDE支持调试 const定义的常量,而不支持 define定义的常量由于 const修饰的变量可以排除程序之间的不安全性因素,保护程序中的常量不被修改,而且对数据类型也会进行相应的检查,极大地提高了程序的健壮性,所以一般更加倾向于用const来定义常量类型。
3.typedef和 define有什么区别?
typedef使用方式
typedef unsigned long ulong; // 将 unsigned long 类型定义为 ulong
typedef int (*func_ptr)(int, int); // 定义函数指针类型define使用方式
#define PI 3.14 // 定义常量宏
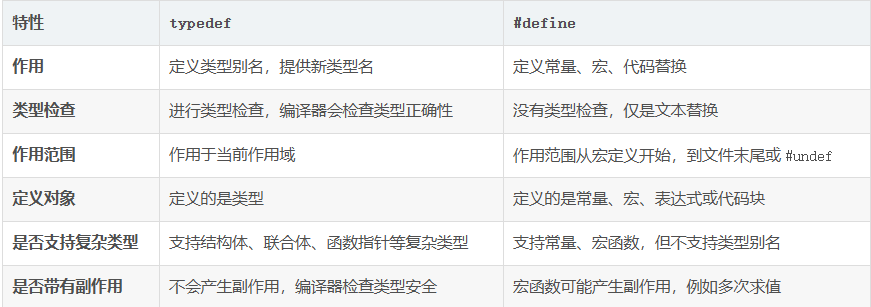
#define MAX(a, b) ((a) > (b) ? (a) : (b)) // 定义函数式宏最主要的区别,typedef会进行类型检查,define是替换文本(在编译阶段就处理完成)
4.#include<filename. h>和#include" filename. h"有什么区别?
对于 # include<filename.h>,编译器先从标准库路径开始搜索 filename.h,使得系统文件调用较快。而对于# include" filename.h".编译器先从用户的工作路径开始搜索 filename.h,然后去寻找系统路径,使得自定义文件较快。
5.在头文件中定义静态变量是否可行,为什么?
不可行,如果在头文件中定义静态变量,会造成资源浪费的问题,同时也可能引起程序错误。因为如果在使用了该头文件的每个C语言文件中定义静态变量,按照编译的步骤,在每个头文件中都会单独存在一个静态变量,从而会引起空间浪费或者程序错误所以,不推荐在头文件中定义任何变量,当然也包括静态变量。
指针
1. 指针的基本概念
- 定义:指针是一种变量,专门用来存储另一个变量的内存地址
- 作用:通过指针可以间接访问和修改所指向变量的值
- 符号:
*表示指针运算符(解引用),&表示取地址运算符
int a = 10;
int *p; // 定义int类型的指针变量p
p = &a; // 将变量a的地址赋值给指针pint x = 5;
int *ptr1 = &x; // 直接初始化,指向变量x
int *ptr2 = NULL; // 初始化为空指针,不指向任何地址指针与数组
int arr[5] = {1,2,3,4,5};
int *p = arr; // 等价于 p = &arr[0]
// 访问数组元素的两种方式
printf("%d", arr[2]); // 数组下标方式
printf("%d", *(p+2)); // 指针方式1.指针与函数
函数返回指针:函数可以返回指针类型,但不能返回局部变量的地址
int *createArray(int size) {
int *arr = malloc(size * sizeof(int));
return arr; // 返回动态分配内存的地址
}2.多级指针
指向指针的指针,用于处理指针的地址
int a = 10;
int *p = &a; // 一级指针
int **pp = &p; // 二级指针
// 访问a的值
printf("%d", a); // 直接访问
printf("%d", *p); // 一级间接访问
printf("%d", **pp); // 二级间接访问3.字符指针
字符串常量本质上是字符数组,可以用字符指针指向
char *str = "Hello"; // 指针指向字符串首地址
printf("%s", str); // 输出整个字符串
printf("%c", *(str+1)); // 输出'e'4.动态内存分配与指针
使用标准库函数进行动态内存管理,返回值为指针
int *p = malloc(5 * sizeof(int)); // 分配内存
if (p != NULL) {
// 使用内存
free(p); // 释放内存
p = NULL; // 避免野指针
}2.指针的进阶用法
1. 函数指针(指向函数的指针)
- 定义:专门用来存储函数地址的指针变量(函数名本身就是函数的入口地址)。
- 作用:通过指针间接调用函数,实现函数的动态调用(如回调函数)。
- 语法:
返回值类型 (*指针变量名)(参数列表);
(括号不可省略,否则会被解析为指针函数)
#include <stdio.h>
// 普通函数:加法
int add(int a, int b) {
return a + b;
}
// 普通函数:乘法
int multiply(int a, int b) {
return a * b;
}
int main() {
// 声明函数指针:指向“返回int、参数为两个int”的函数
int (*func_ptr)(int, int);
// 函数指针指向add函数(函数名即地址,无需&)
func_ptr = add;
printf("3 + 5 = %d\n", func_ptr(3, 5)); // 间接调用add,输出8
// 函数指针指向multiply函数
func_ptr = multiply;
printf("3 * 5 = %d\n", (*func_ptr)(3, 5)); // 等价写法,输出15
return 0;
}2. 指针函数(返回指针的函数)
- 定义:一种返回值为指针类型的函数(本质是函数,只是返回值是指针)。
- 语法:
返回值类型* 函数名(参数列表);
(*与函数名结合,因为()优先级高于*)
#include <stdio.h>
#include <stdlib.h>
// 指针函数:返回动态分配的int数组
int* create_array(int size) {
int* arr = (int*)malloc(size * sizeof(int));
if (arr != NULL) {
for (int i = 0; i < size; i++) {
arr[i] = i * 10; // 初始化数组
}
}
return arr; // 返回指针
}
int main() {
int* ptr = create_array(5); // 调用指针函数,接收返回的指针
if (ptr != NULL) {
for (int i = 0; i < 5; i++) {
printf("%d ", ptr[i]); // 输出:0 10 20 30 40
}
free(ptr); // 释放动态内存
ptr = NULL;
}
return 0;
}
3. 数组指针(指向数组的指针)
- 定义:专门用来指向整个数组的指针(指针指向的是数组整体,而非数组元素)。
- 语法:
数据类型 (*指针名)[数组长度];
(括号不可省略,否则会被解析为指针数组)
#include <stdio.h>
int main() {
int arr[5] = {1, 2, 3, 4, 5};
// 数组指针:指向“int[5]”类型的数组(数组长度必须与指向的数组一致)
int (*arr_ptr)[5] = &arr; // &arr是整个数组的地址(与arr不同,arr是首元素地址)
// 访问数组元素的两种方式
// 1. 通过数组指针解引用(得到数组),再用下标访问
printf("%d\n", (*arr_ptr)[2]); // 输出3(等价于arr[2])
// 2. 数组指针的算术运算(移动步长为整个数组的大小)
// (此处仅作演示,实际很少移动数组指针)
// int arr2[5] = {6,7,8,9,10};
// arr_ptr++; // 移动5*4=20字节(假设int占4字节),指向arr2的话可访问其元素
// 二维数组与数组指针(常用场景)
int matrix[3][4] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
int (*row_ptr)[4] = matrix; // matrix是首行地址,类型为int(*)[4]
// 遍历二维数组
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
printf("%d ", row_ptr[i][j]); // 等价于matrix[i][j]
}
printf("\n");
}
return 0;
}1. 指针数组(存储指针的数组)
- 定义:一个数组,其中每个元素都是指针类型(数组的元素是指针)。
- 语法:
数据类型* 数组名[数组长度];
([]优先级高于*,所以先结合数组名,构成 “元素为指针的数组”)
#include <stdio.h>
int main() {
int a = 10, b = 20, c = 30;
// 指针数组:存储int*类型的元素(每个元素都是int指针)
int* ptr_arr[3] = {&a, &b, &c}; // 初始化:每个元素指向一个int变量
// 遍历指针数组,通过元素(指针)访问变量值
for (int i = 0; i < 3; i++) {
printf("%d ", *(ptr_arr[i])); // 输出:10 20 30
}
// 典型应用:存储字符串(字符串本质是char*)
char* str_arr[3] = {"apple", "banana", "cherry"};
for (int i = 0; i < 3; i++) {
printf("%s ", str_arr[i]); // 输出:apple banana cherry
}
return 0;
}野指针(Wild Pointer)是 C 语言中一种危险的指针状态,指的是未被正确初始化、或指向的内存已被释放、或越界访问的指针。这类指针指向的内存地址是不确定的(可能指向无效内存、系统关键区域或其他程序的内存),操作野指针会导致不可预知的后果。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 51
51 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)