【Python爬虫】Requests库高级用法:深入Session保持与证书处理
Requests是Python中最流行的HTTP请求库,以其简洁的API和强大的功能深受开发者喜爱。它支持GET、POST等请求方法,处理URL参数、头信息和数据体,适合网络爬虫、API调用等场景。print(response.status_code) # 输出:200print(response.json()) # 输出JSON数据Requests的核心优势在于易用性和灵活性,但其高级用法如Se
1. Requests库基础回顾
1.1 Requests库概述
Requests是Python中最流行的HTTP请求库,以其简洁的API和强大的功能深受开发者喜爱。它支持GET、POST等请求方法,处理URL参数、头信息和数据体,适合网络爬虫、API调用等场景。以下是一个简单的GET请求示例:
import requests
response = requests.get('https://api.github.com')
print(response.status_code) # 输出:200
print(response.json()) # 输出JSON数据
Requests的核心优势在于易用性和灵活性,但其高级用法如Session保持和证书处理能进一步提升效率和安全性。本文将深入探讨这些功能,结合代码,由浅入深讲解。
1.2 HTTP请求核心组件
HTTP请求包括方法、URL、头信息、消息体等。以下是常见场景:
- GET:获取资源,如网页或API数据。
- POST:提交数据,如表单或文件上传。
- 头信息:如
User-Agent、Cookie等,影响服务器响应。 - 状态码:
- 200:成功
- 401:未授权
- 429:请求超限
了解这些基础有助于掌握高级用法,如处理会话和SSL证书。
2. Session保持详解
2.1 Session对象的作用
requests.Session是Requests库的核心功能之一,用于保持HTTP会话状态。Session对象可以在多次请求间复用TCP连接、保存Cookie,适合需要登录或连续请求的场景。例如,爬取需要登录的网站时,Session能自动管理Cookie。
基本用法:
import requests
# 创建Session对象
session = requests.Session()
# 登录请求
login_data = {'username': 'user', 'password': 'pass123'}
response = session.post('https://example.com/login', data=login_data)
# 后续请求自动携带Cookie
profile_response = session.get('https://example.com/profile')
print(profile_response.text)
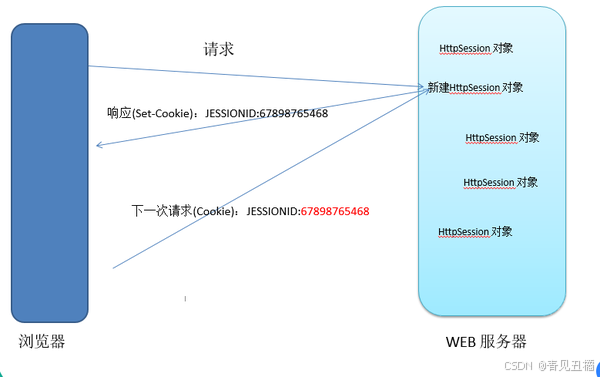
图示:Session保持流程
客户端(Session) 服务器
| --登录请求--> |
| <--Set-Cookie-- |
| --后续请求--> |
| (携带Cookie) |
| <--响应数据--- |
2.2 Session的持久化连接
Session通过复用TCP连接减少了建立连接的开销,尤其在高频请求时效果显著。以下是对比示例:
import requests
import time
# 无Session
start = time.time()
for _ in range(10):
requests.get('https://httpbin.org/get')
print(f'无Session耗时: {time.time() - start}')
# 使用Session
session = requests.Session()
start = time.time()
for _ in range(10):
session.get('https://httpbin.org/get')
print(f'使用Session耗时: {time.time() - start}')
结果:Session通常比单独请求快,因为它避免了重复的TCP握手。
2.3 自定义Session配置
Session支持自定义头信息、代理等,增强灵活性。例如,设置全局头信息:
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124',
'Accept-Language': 'en-US,en;q=0.9'
})
response = session.get('https://example.com')
print(response.request.headers) # 查看请求头
代理设置:
session = requests.Session()
session.proxies = {
'http': 'http://proxy.example.com:8080',
'https': 'https://proxy.example.com:8080'
}
response = session.get('https://example.com')
2.4 Cookie管理
Session自动管理Cookie,但开发者也可手动操作。例如,提取和设置Cookie:
session = requests.Session()
response = session.get('https://httpbin.org/cookies/set?name=value')
# 查看Cookie
print(session.cookies.get_dict()) # 输出:{'name': 'value'}
# 手动设置Cookie
session.cookies.set('custom_key', 'custom_value')
response = session.get('https://httpbin.org/cookies')
print(response.json()) # 输出:{'cookies': {'name': 'value', 'custom_key': 'custom_value'}}
注意:某些网站使用加密Cookie,需结合JavaScript逆向分析。
3. SSL证书处理
3.1 HTTPS与SSL/TLS基础
HTTPS通过SSL/TLS加密通信,保护数据安全。爬虫处理HTTPS网站时,需正确验证服务器证书,否则可能遇到SSLError。Requests默认启用证书验证,但开发者可根据需求调整。
默认验证:
import requests
response = requests.get('https://example.com') # 自动验证证书
print(response.status_code) # 输出:200
3.2 忽略证书验证
某些网站使用自签名证书或证书错误,可能导致验证失败。此时可禁用验证(不推荐,存在安全风险):
import requests
response = requests.get('https://self-signed.badssl.com', verify=False)
print(response.text)
警告:禁用验证可能导致中间人攻击,仅用于测试或可信环境。
3.3 使用自定义证书
对于自签名证书,可指定证书文件:
import requests
cert_path = 'path/to/cert.pem'
response = requests.get('https://self-signed.example.com', verify=cert_path)
print(response.status_code)
证书格式:
.pem:包含公钥证书。.crt:类似.pem,常用于服务器证书。
3.4 客户端证书认证
某些API或企业网站要求客户端证书认证,需提供证书和私钥:
import requests
cert = ('client.crt', 'client.key')
response = requests.get('https://auth.example.com', cert=cert)
print(response.status_code)
注意:确保证书文件安全,私钥泄露会导致严重后果。
3.5 处理证书错误
常见错误及解决方法:
- SSLError:检查URL是否正确,或尝试
verify=False。 - CertificateExpired:更新本地CA证书,或使用自定义证书。
- ConnectionError:确认网络连接和代理设置。
更新CA证书示例:
import certifi
import requests
response = requests.get('https://example.com', verify=certifi.where())
print(response.status_code)
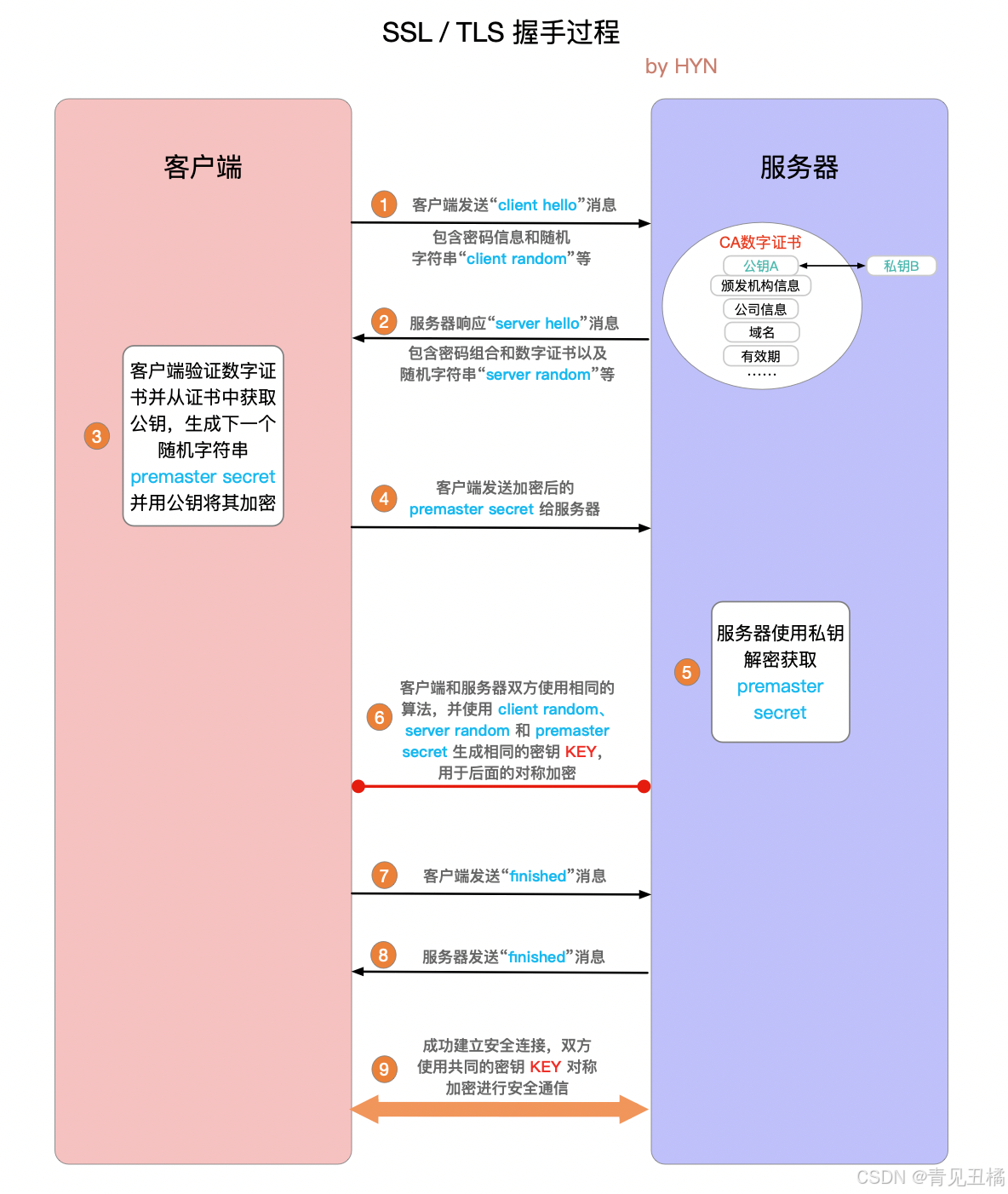
图示:SSL握手流程
客户端 服务器
| --ClientHello--> |
| <--ServerHello--- |
| <--Certificate--- |
| --Verify Cert--> |
| --Key Exchange--> |
| <--Finish-------- |
4. 高级用法进阶
4.1 请求超时与重试
网络不稳定时,设置超时和重试机制可提高爬虫健壮性:
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
session = requests.Session()
retries = Retry(total=3, backoff_factor=1, status_forcelist=[429, 500, 502, 503, 504])
session.mount('https://', HTTPAdapter(max_retries=retries))
try:
response = session.get('https://example.com', timeout=(3, 5)) # 连接超时3秒,读取超时5秒
print(response.status_code)
except requests.exceptions.RequestException as e:
print(f'请求失败: {e}')
total:最大重试次数。backoff_factor:重试间隔递增因子。status_forcelist:触发重试的状态码。
4.2 流式响应处理
对于大文件下载,流式处理避免内存溢出:
import requests
response = requests.get('https://example.com/largefile.zip', stream=True)
with open('largefile.zip', 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
4.3 并发请求
Requests本身不支持异步,但可结合concurrent.futures实现并发:
from concurrent.futures import ThreadPoolExecutor
import requests
urls = ['https://httpbin.org/get'] * 5
session = requests.Session()
def fetch(url):
return session.get(url).text
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(fetch, urls))
print(len(results)) # 输出:5
注意:对于更高并发,建议使用aiohttp或httpx。
4.4 自定义请求钩子
Requests支持钩子函数,允许在请求前后执行自定义逻辑:
def log_response(response, *args, **kwargs):
print(f'请求URL: {response.url}, 状态码: {response.status_code}')
return response
session = requests.Session()
session.hooks['response'] = log_response
response = session.get('https://example.com')
5. 实战案例:爬取登录网站
以下是爬取需要登录的网站的完整示例:
import requests
from bs4 import BeautifulSoup
# 初始化Session
session = requests.Session()
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124'
})
# 登录
login_url = 'https://example.com/login'
login_data = {'username': 'user', 'password': 'pass123'}
response = session.post(login_url, data=login_data)
# 检查登录状态
if response.status_code == 200:
print('登录成功')
# 爬取受保护页面
profile_url = 'https://example.com/profile'
response = session.get(profile_url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.select_one('h1').text) # 输出页面标题
注意:需替换URL和登录信息,并处理可能的CSRF令牌。
6. 优化与注意事项
6.1 性能优化
- 复用Session:减少连接开销。
- 适当超时:避免请求挂起。
- 压缩响应:设置
Accept-Encoding: gzip。
session = requests.Session()
session.headers.update({'Accept-Encoding': 'gzip, deflate'})
6.2 错误处理
全面捕获异常,确保爬虫稳定:
try:
response = session.get('https://example.com', timeout=5)
response.raise_for_status() # 抛出HTTP错误
except requests.exceptions.HTTPError as e:
print(f'HTTP错误: {e}')
except requests.exceptions.ConnectionError:
print('连接失败')
except requests.exceptions.Timeout:
print('请求超时')
6.3 合规性
- 遵守
robots.txt。 - 避免高频请求,设置随机延迟:
import random
import time
time.sleep(random.uniform(1, 3)) # 1-3秒随机延迟

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)