STM32F103C8T6学习——直接存储器访问(DMA)标准库实战1(入门级 - “解放CPU的直观展示”)
本项目演示了在STM32F103C8T6微控制器上,如何利用直接内存访问(DMA)技术实现高效的串口(UART)数据传输。核心程序在主循环中周期性地调用函数,以非阻塞方式启动DMA传输。CPU仅需下达该指令,便可从繁琐的数据搬运任务中解放出来,转而处理其他逻辑。DMA控制器则在后台自主完成内存到UART外设的数据传送。最终,PC串口助手成功接收到开发板循环发送的信息,验证了CPU主程序与DMA数据
核心比喻:一个物流中心的7个装货平台
想象一下 DMA1控制器 是一个大型物流中心。这个中心有 7个装货平台(通道1 到 通道7),负责将各个工厂(外设)的货物(数据)高效地运输出去或接收进来。
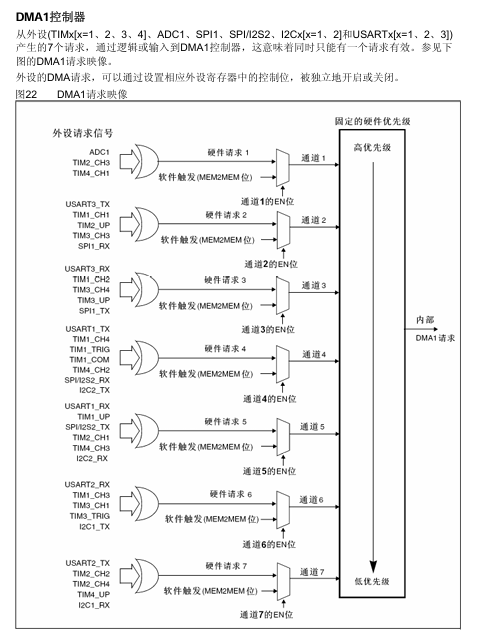
这张图就是这个物流中心的 “平台分配规则图”,它规定了哪个工厂可以使用哪个平台。这个规则是硬件定死的,不能更改。
图解详细说明
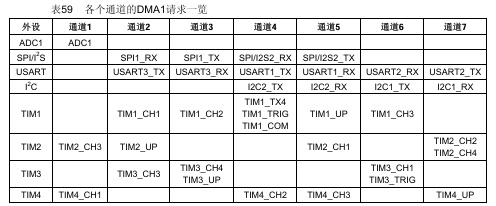
我们从左到右来看这张图的各个部分:
1. 左侧:“外设请求” - 众多等待服务的工厂
这里的列表(ADC1, TIMx_CHx, USARTx_TX, SPIx_RX等)就是 STM32 内部的各种外设(工厂)。当这些外设需要传输数据时,它们就会发出一个“请求(Request)”,相当于工厂打电话给物流中心说:“我有一批货,快来处理!”
关键点:一个平台可以为多个工厂服务,但一次只能为一个服务。
-
看通道1:它只连接了
ADC1、TIM2_CH3、TIM4_CH1这三个外设。这意味着,如果你想用DMA来搬运ADC1的数据,你必须也只能使用通道1。 -
看通道4:它可以服务的工厂就很多了,比如
USART1_TX,TIM1_TRIG,SPI2_TX等等。 -
“或”的关系:在同一时间,通道4虽然对应这么多外设,但你只能选择其中一个来和它绑定。比如,你在程序中配置了
USART1_TX使用DMA,那么通道4就被USART1_TX占用了,此时TIM1_TRIG就不能再使用通道4的DMA功能了。
2. 中间:“硬件请求” vs “软件触发” - 两种呼叫方式
一个平台(通道)如何知道该开始工作了呢?有两种方式:
-
硬件请求 (Hardware Request):这是最常用的方式。工厂(外设)自己准备好后,会自动发出一个电信号(硬件请求)来启动平台(通道)工作。
-
例子1 (发送):
USART1_TX(串口1发送)要发送数据。当它的发送数据寄存器空了,可以接收下一个字节时,它就会自动触发通道4,让DMA从内存里搬一个字节过来。 -
例子2 (接收):
ADC1完成了一次模拟到数字的转换。当新的数据准备好后,它就会自动触发通道1,让DMA把这个数据从ADC搬到内存里。
-
-
软件触发 (Software Trigger / MEM2MEM):这种方式相当于物流中心的经理(CPU)直接通过对讲机下令:“平台X,立即开始工作!”。它不需要工厂(外设)的信号。
-
主要用途:内存到内存 (Memory-to-Memory) 的数据复制。因为这个过程不涉及任何外设,没有“工厂”能发出硬件请求,所以必须由你的代码(软件)来手动启动DMA通道。
-
在图中,每个通道的输入端都有一个来自“软件触发”的箭头,表明任何一个通道都可以被配置为内存到内存的模式。
-
3. 右侧:“通道”与“固定硬件优先级” - 平台的编号和优先权
-
通道 (Channel):就是我们说的1到7号装货平台。它是实际执行数据搬运的工作单元。
-
固定的硬件优先级 (Fixed Hardware Priority):这是这张图最重要的规则之一,它解决了“如果多个平台同时要工作怎么办?”的问题。物流中心内部只有一条主传送带(内部总线),同一时刻只能服务一个平台。
-
规则:通道号越小,优先级越高。即
通道1 > 通道2 > ... > 通道7。 -
通俗例子:假设某一瞬间,
ADC1(使用通道1)和USART1_TX(使用通道4)都准备好了,同时向物流中心发出了请求。 -
仲裁结果:物流中心内部的仲裁器(一个裁判)会根据这个优先级规则,决定让通道1先使用主传送带。等通道1搬完一个数据后,再轮到通道4。这个过程快到微秒级,但规则是严格执行的。
-
综合实例
项目一:入门级 - “解放CPU的直观展示”
项目名称: DMA + USART 发送可变长数据,主循环高速运行
核心目标:
-
掌握最基础的内存 -> 外设的DMA传输模式。
-
理解DMA的**“一次性”触发(Normal Mode)**和“即发即忘”的工作方式。
-
直观感受DMA对CPU的解放,对比轮询发送时CPU被完全占用的情况。
实战价值: 这是产品开发中最常用的功能之一,例如:向上位机发送调试信息、发送传感器数据包、应答主机的命令等。所有这些都要求不能因为发送数据而阻塞主控制流程(如电机控制、姿态解算)。
标准库 (SPL) 实现思路:
-
初始化GPIO和USART:正常配置PA9(TX), PA10(RX)和USART1。
-
使能DMA时钟:这是最容易忘记的一步!
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE); -
配置DMA通道:查阅“DMA请求映像图”,
USART1_TX对应DMA1_Channel4。
部分伪代码(整个项目思路):
#include "stm32f10x.h"
/*******************************************************************************
* 宏定义与全局变量
*******************************************************************************/
// 1. 定义发送缓冲区 (这就是我们要发送的“货物”)
uint8_t TxBuffer[] = "Hello, this is a DMA transfer test on STM32F103C8T6. Project 1 is successful!\r\n";
// 2. 定义发送缓冲区的长度
// sizeof(TxBuffer) 会包含字符串末尾的'\0'结束符,我们通常不发送它,所以长度要减1。
uint16_t TxBufferLength = sizeof(TxBuffer) - 1;
/*******************************************************************************
* 函数声明
*******************************************************************************/
void Serival_init(void);
void Uart1DMATX_init(void);
void My_UART_Transmit_DMA(uint8_t *buffer, uint16_t len);
void delay_ms(uint32_t ms); // 一个简单的延时函数用于主循环
/*******************************************************************************
* 主函数
*******************************************************************************/
int main(void)
{
// 初始化串口1
Serival_init();
// 初始化串口1的DMA发送通道
Uart1DMATX_init();
// 主循环,在这里可以做其他事情,比如闪烁LED,以证明CPU是空闲的
while (1)
{
// 每隔1秒,通过DMA发送一次TxBuffer中的数据
My_UART_Transmit_DMA(TxBuffer, TxBufferLength);
// 延时1秒
delay_ms(1000);
// 在这里可以加上你自己的LED闪烁代码,例如:
// GPIO_SetBits(GPIOC, GPIO_Pin_13);
// delay_ms(100);
// GPIO_ResetBits(GPIOC, GPIO_Pin_13);
// 你会发现LED的闪烁和串口发送互不干扰,完美证明了DMA的价值。
}
}
/*******************************************************************************
* 函数定义 (您提供的函数,我做了必要的修改)
*******************************************************************************/
/**
* @brief 初始化USART1
* @param None
* @retval None
*/
void Serival_init()
{
//开启时钟
RCC_APB2PeriphClockCmd(RCC_APB2Periph_USART1, ENABLE);
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);
//GPIO初始化,把TX(PA9)配置成复用输出,RX(PA10)配置成浮空输入
GPIO_InitTypeDef GPIOA_InitStruct;
// 配置TX引脚
GPIOA_InitStruct.GPIO_Mode = GPIO_Mode_AF_PP;
GPIOA_InitStruct.GPIO_Pin = GPIO_Pin_9;
GPIOA_InitStruct.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIOA_InitStruct);
// 配置RX引脚(即使只发送,最好也初始化)
GPIOA_InitStruct.GPIO_Mode = GPIO_Mode_IN_FLOATING;
GPIOA_InitStruct.GPIO_Pin = GPIO_Pin_10;
GPIO_Init(GPIOA, &GPIOA_InitStruct);
//配置USART(直接使用结构体进行配置即可)
USART_InitTypeDef USART1_InitStruct;
USART1_InitStruct.USART_BaudRate = 115200; //需要什么波特率直接写即可
USART1_InitStruct.USART_HardwareFlowControl = USART_HardwareFlowControl_None;
USART1_InitStruct.USART_Mode = USART_Mode_Tx | USART_Mode_Rx; // 即使只用发送,也建议打开接收
USART1_InitStruct.USART_Parity = USART_Parity_No;
USART1_InitStruct.USART_StopBits = USART_StopBits_1;
USART1_InitStruct.USART_WordLength = USART_WordLength_8b;
USART_Init(USART1, &USART1_InitStruct);
//开关控制(打开串口)
USART_Cmd(USART1, ENABLE);
}
/**
* @brief 初始化USART1的DMA发送通道 (Channel4)
* @note 将您代码中的占位符替换为我们定义的全局变量
* @param None
* @retval None
*/
void Uart1DMATX_init()
{
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);
DMA_InitTypeDef DMA_InitStructure;
// 这里我们只做一次性的基础配置,实际发送时地址和长度在发送函数中更新
// 2. 设置外设地址 (固定不变)
DMA_InitStructure.DMA_PeripheralBaseAddr = (uint32_t)&USART1->DR;
// 3. 设置内存地址 (【修改点】这里使用我们定义的全局缓冲区作为初始值)
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)TxBuffer;
// 4. 方向:内存到外设
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralDST;
// 5. 传输大小 (【修改点】这里使用我们定义的长度作为初始值)
DMA_InitStructure.DMA_BufferSize = TxBufferLength;
// 6. 外设地址不递增
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
// 7. 内存地址递增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;
// 8. 数据宽度:8位
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;
// 9. 模式:普通模式,非循环
DMA_InitStructure.DMA_Mode = DMA_Mode_Normal;
// 10. 优先级:中
DMA_InitStructure.DMA_Priority = DMA_Priority_Medium;
// 11. 非内存到内存模式
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable;
DMA_Init(DMA1_Channel4, &DMA_InitStructure);
// 使能串口的DMA发送请求
USART_DMACmd(USART1, USART_DMAReq_Tx, ENABLE);
// 初始化完成后,保持通道关闭,等待发送函数来启动它
DMA_Cmd(DMA1_Channel4, DISABLE);
}
/**
* @brief 使用DMA启动一次串口发送
* @param buffer 数据缓冲区指针
* @param len 数据长度
* @retval None
*/
void My_UART_Transmit_DMA(uint8_t *buffer, uint16_t len)
{
DMA_Cmd(DMA1_Channel4, DISABLE);
// 在V3.5.0中,最直接的方式是:
DMA1_Channel4->CMAR = (uint32_t)buffer; // 直接设置内存地址寄存器
DMA_SetCurrDataCounter(DMA1_Channel4, len); // 使用库函数设置长度
DMA_Cmd(DMA1_Channel4, ENABLE);
}
/**
* @brief 简单的毫秒延时函数
* @param ms 延时的毫秒数
* @retval None
*/
void delay_ms(uint32_t ms)
{
// 这是一个非常不精确的延时,仅用于演示
// 实际项目中请使用SysTick或定时器
volatile uint32_t i, j;
for (i = 0; i < ms; i++)
{
for (j = 0; j < 8000; j++); // 根据你的时钟频率调整这个值
}
}⭐关键理解
为什么收货地址是固定不变的?这里的收货地址不是指货物地址?我放完一件后这个地址就被占用了?
在内存里,一个地址存了一个数据,这个地址就被“占用”了,下一个数据必须存到下一个地址。这个逻辑在内存到内存的复制中是完全正确的。
但是,外设的“数据寄存器” (USART->DR) 工作原理完全不同。
我们继续用那个物流中心的比喻,这次我们把细节说得更清楚一些:
收货地址不是“货架”,而是“唯一的发货滑槽”
-
内存缓冲区 (
YourTxBuffer):是你的仓库,里面有一排排的货架。你把货物(数据)放到第一个货架(&YourTxBuffer[0])后,这个货架就被占用了。下一件货物必须放到第二个货架(&YourTxBuffer[1])。所以仓库地址必须递增。 -
串口的数据寄存器 (
USART->DR):它不是一个用来“存放”货物的货架。请把它想象成一个神奇的、唯一的“自动发货滑槽”。
这个滑槽有以下特点:
-
它只有一个入口:你只能把货物放在这个滑槽的入口处。这个入口的“门牌号”就是
&USART->DR。 -
它能瞬间处理货物:你把一件货物(一个字节的数据)刚放到滑槽上,
嗖的一下,这件货物就被串口的硬件部分拿走,开始通过TX线一位一位地发送出去了。 -
它立刻就空了:货物被拿走的瞬间,这个滑槽立刻就变回了空闲状态,准备好接收下一件货物。
所以,整个流程是这样的:
-
DMA把第1件货从仓库的第1个货架上搬过来,放到唯一的那个发货滑槽上。
-
滑槽立刻把货发走,然后变空。
-
DMA把第2件货从仓库的第2个货架上搬过来,还是放到同一个发货滑槽上。
-
滑槽又立刻把货发走,然后变空。
-
...
-
DMA把第N件货从仓库的第N个货架上搬过来,依然是放到那同一个发-货-滑-槽上。
结论:
-
“收货地址” (
&USART->DR) 指的是“发货滑槽的入口地址”,它自始至终就只有一个,所以它的地址是固定不变的。 -
“货物地址” 指的是货物在内存仓库里的存放地址,它们是一排排的货架,所以地址是需要递增的。
我们用一张表格来总结这个关键区别:
| 对象 (Object) | 比喻 (Analogy) | 地址行为 (Address Behavior) | 为什么? (Why?) |
内存缓冲区 (YourTxBuffer) |
仓库货架 (Warehouse Shelf) | 必须递增 (DMA_MemoryInc_Enable) |
每个货架只能放一件货,放完要找下一个空货架。 |
串口数据寄存器 (USART->DR) |
唯一的发货滑槽 (The Single Shipping Chute) | 必须固定 (DMA_PeripheralInc_Disable) |
只有一个滑槽,放上去的货立刻被传送走,滑槽马上就空了,可以继续在同一个位置放下一件。 |
互不干扰到底怎么理解
好的,我们来详细解释一下这段代码注释中所说的“互不干扰”的确切含义。
这里的“互不干扰”指的是 CPU(中央处理单元) 和 DMA(直接内存访问)控制器 这两个独立的硬件单元可以并行工作,互不占用对方的时间。
为了完全理解这一点,我们需要从“不使用DMA”和“使用DMA”两种情况来对比分析串口(UART)发送数据的过程。
1. 不使用 DMA 的情况(轮询或中断方式)
想象一下,如果没有DMA,CPU 要发送一串数据(比如 TxBuffer 里的内容)会发生什么。
-
工作流程:
-
CPU 接到发送任务: CPU 执行到发送函数。
-
CPU 开始发送: CPU 将
TxBuffer中的第一个字节(比如'A')写入到串口的数据寄存器(UART_DR)。 -
CPU 等待: 串口硬件开始将这个字节通过物理线路(TX引脚)一位一位地发送出去。在硬件完成发送之前,CPU 不能发送下一个字节,否则会造成数据丢失。这个等待过程,CPU 只能“干等”,或者通过不断检查串口的状态寄存器(“你发完了吗?”)来判断是否可以发送下一个字节。这就是所谓的轮询。
-
发送下一个: 串口硬件发完第一个字节后,CPU 才能把第二个字节(比如'B')写入数据寄存器。
-
重复: 这个过程会一直重复,直到
TxBuffer中的所有数据都发送完毕。
-
-
核心问题: 在这个过程中,CPU 的主要精力被牵扯在“搬运数据”和“等待”这两件简单重复的事情上。如果数据量很大,或者波特率不高(发送速度慢),CPU 就会被长时间占用,无法去执行其他任务,比如代码主循环
while(1)中的LED闪烁。你会观察到,在发送数据的那一刻,LED的闪烁会明显卡顿一下,因为它没有得到CPU的及时处理。
简单比喻: 这就像你(CPU)要去寄一堆信(TxBuffer)。你必须亲自把每一封信送到邮局(串口寄存器),然后站在原地等到邮局处理完这封信,才能再去拿下一封。在你寄信的整个过程中,你无法分身去做别的事情(比如回家做饭)。
2. 使用 DMA 的情况(代码中的方式)
现在,我们来看看代码中使用了 DMA 的情况。
-
工作流程:
-
CPU 初始化任务: CPU 执行
My_UART_Transmit_DMA(TxBuffer, TxBufferLength);函数。在这个函数里,CPU 不会亲自去搬运数据。它会像一个项目经理一样,对 DMA 控制器下达一个指令。-
指令内容: “你好,DMA 控制器。请你把内存地址
TxBuffer开始的,长度为TxBufferLength的数据,自动搬运到串口1的数据寄存器UART_DR去。搬完之后再告诉我。”
-
-
CPU 解放: CPU 下达完这个指令后,它的任务就完成了!它会立刻返回,继续执行
while(1)循环中的其他代码,比如delay_ms(1000)和控制LED闪烁的代码。 -
DMA 接管工作: DMA 控制器是一个独立于CPU的硬件。它接收到指令后,就开始了它的“搬运工作”。当串口硬件空闲时,DMA 会自动从
TxBuffer中取一个字节,写入到串口的数据寄存器,这个过程完全不需要CPU的参与。 -
并行执行:
-
DMA 控制器: 在后台默默地、高效地将数据从内存搬运到串口。
-
CPU: 在前台自由地执行主循环中的任何代码,比如精确地控制LED以固定的频率闪烁。
-
-
-
核心优势 (互不干扰的体现): CPU 的工作和 DMA 的工作是在同时进行的。CPU 在处理LED闪烁的逻辑时,DMA 也在处理数据的发送。两者共享系统总线(访问内存和外设的通道),但DMA的访问非常高效,对CPU的影响微乎其微。
因此,你会看到一个现象:
-
串口监视器上每隔1秒钟就会准确地接收到一次
TxBuffer的数据。 -
与此同时,开发板上的LED(如果添加了代码)会以非常平稳、无卡顿的频率在闪烁。
串口的数据发送和LED的闪烁这两件事完美地并行发生,没有任何一方因为另一方的存在而出现延迟或卡顿。这就是“互不干扰”的精髓所在。
-
简单比喻: 这就像你(CPU)现在是老板。你要寄一堆信(TxBuffer),于是你叫来了你的助理(DMA 控制器),告诉他:“把这堆信拿到邮局(串口寄存器)一封一封寄掉”。在你助理去工作的整个过程中,你完全解放了,可以自由地去做其他更重要的事情(比如回家做饭、看电视)。你和你的助理同时在做各自的事情,互不影响。
总结
| 特性 | 不使用 DMA (轮询/中断) | 使用 DMA (代码所示) |
| 数据搬运工 | CPU | DMA 控制器 |
| CPU状态 | 在数据传输期间被占用,处于等待或处理中断状态 | 仅需启动DMA,之后完全空闲,可执行其他任务 |
| 系统效率 | 低,CPU资源被浪费在简单重复的传输任务上 | 高,CPU和DMA并行工作,CPU资源得到充分利用 |
| 现象 | 发送数据时,其他任务(如LED闪烁)会卡顿 | 发送数据和LED闪烁同时平稳运行 |
| “互不干扰” | 无法做到,CPU同一时间只能做一件事 | 完美实现,CPU的任务和DMA的数据传输任务并行,互不影响 |
完整程序在文章顶端下载获取,感兴趣的铁子可以研究下这个思路,还是很有应用价值的

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 33
33 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)