嵌入式linux开发八股文笔记
这里是在学习八股文时,进行相应的补充和说明,所有不会很完整。
前言
这里是在学习八股文时,进行相应的补充和说明,所有不会很完整。
一、Linux
1、虚拟文件系统
/proc
proc 文件系统是 Linux 内核提供的虚拟文件系统(或称伪文件系统),通过文件接口动态映射内核数据结构与系统运行时信息,不占用物理存储空间。系统全局信息:如 CPU(/proc/cpuinfo)、内存(/proc/meminfo)、设备(/proc/devices)等。进程信息:以 PID 命名的目录(如 /proc/1234)存储进程状态、内存映射、打开文件等。多数文件只读,但部分路径(如 /proc/sys/)支持写入以动态修改内核参数(例如调整网络配置)。
/dev
linux 系统下的 /dev 目录是设备文件(Device Files,devfs)的核心存储位置,作为用户空间程序与物理或虚拟硬件设备交互的标准化接口,每个硬件设备(如硬盘、键盘、USB 设备)或内核虚拟设备(如 /dev/null)在 /dev 下对应一个设备文件,/dev 目录下的文件称为设备节点,用户程序通过标准文件操作(open()、read()、write())访问设备,无需直接调用底层驱动.
/sys
Linux 下的 sysfs 是一个基于内存的虚拟文件系统,从内核 2.6 开始引入,用于向用户空间导出内核对象(kernel object)(如设备、驱动、总线等)的层次结构和属性信息。其核心功能是通过文件系统接口动态展示系统硬件和驱动的状态,便于用户空间管理与调试。
2、总线
计算机系统中的总线是连接各功能部件(如CPU、内存、I/O设备等)的公共通信通道,用于传输数据、地址和控制信号。
按功能层级划分
系统总线:连接CPU、内存和核心I/O设备(如PCIe总线)。
I/O总线:连接外设(如USB、SATA)。
通信总线:用于设备间远距离通信(如RS-232、CAN总线)。
按传输方式划分
并行总线:多线同时传输,速度快但距离短(如IDE接口)。
串行总线:单线逐位传输,适合远距离(如USB、PCIe)。
3、shell
Shell 是计算机操作系统中的一个重要概念,主要有两层含义:
命令行解释器:
作为用户与操作系统内核之间的接口
接收用户输入的命令并解释执行
常见的有Bash(Linux/macOS)、PowerShell(Windows)等
脚本编程语言:
支持自动化任务的脚本编写
包含变量、流程控制等编程元素
常用于系统管理、自动化部署等场景
4、目录项、文件表、inode
在Linux文件系统中,目录项(Directory Entry, dentry)和文件表(File Table)是文件管理的核心数据结构,二者协同工作以实现高效的文件访问和管理。以下是它们的详细解析:
1、目录项(dentry)
目录项是内核维护的内存数据结构,用于记录文件或子目录的名称及其对应的索引节点(inode)指针。
功能:
存储文件名与inode的映射关系,形成目录层级结构(如/home/user/file.txt)。
缓存已访问的目录信息,避免频繁从磁盘读取,提升性能。
特点:
多对一关系:多个目录项可指向同一inode(如硬链接)。
不持久化存储:仅存在于内存中,重启后消失。
2、文件表(File Table)
文件表是系统级数据结构,管理所有进程打开的文件状态。
组成:
进程级文件描述符表(fdtable):每个进程维护一个,记录文件描述符(FD)到file结构的映射。
系统级file结构:存储文件状态(如偏移量、访问模式),多个进程可共享同一file结构(如fork()或dup())。
作用:
通过file结构关联inode,实现文件操作(如read()、write())。
3、inode
inode(索引节点)是文件管理的核心数据结构,用于存储文件的元信息(metadata)和定位数据块。inode是文件系统中每个文件或目录的唯一标识符,其核心功能包括:
存储元数据:如文件大小、权限、所有者、时间戳(atime/mtime/ctime)、数据块位置等。
唯一标识文件:Linux通过inode号而非文件名识别文件,文件名仅作为目录项(dentry)的映射。
5、进程与线程
进程是操作系统资源分配的基本单位,拥有独立的地址空间和系统资源(如内存、文件句柄等);
线程是处理器任务调度和执行的基本单位,共享所属进程的资源,仅拥有独立的运行栈和程序计数器等少量资源。
6、gcc、makefile和cmake
核心功能与定位差异
GCC:作为GNU编译器套件,直接处理源代码的编译和链接,支持C/C++等多种语言,适用于单文件或简单项目的直接编译。
Makefile:定义编译规则和依赖关系的脚本文件,通过make工具调用GCC等编译器实现批量编译,解决多文件项目管理问题。
CMake:跨平台构建工具,通过CMakeLists.txt生成适配不同环境的Makefile或其他构建文件(如Visual Studio项目),简化构建流程。
层级关系与协作流程
编译流程:
源代码 → CMake(读取CMakeLists.txt) → 生成Makefile → Make(调用GCC) → 可执行文件。
工具调用链:
CMakeLists.txt → CMake → Makefile → Make → GCC。
三者形成递进工具链:GCC是底层编译器,Makefile通过规则调用GCC,CMake进一步封装Makefile的生成过程,提升可移植性和管理效率。
7、扇区、页、块和缓冲区
在Linux系统中,扇区、页、块等结构是不同层次的内存与存储管理单元,其关系如下:
- 扇区(Sector)
硬件级单位:磁盘设备的最小寻址单元,通常为512B或4KB
作用:所有块设备的I/O操作必须以扇区为单位进行
特点:物理磁盘的原始传输单位,操作系统不直接操作扇区 - 块(Block)
文件系统级单位:VFS和文件系统的最小逻辑寻址单元,通常为4KB(8个512B扇区)
作用:文件系统读写操作的基本单位,一个块可包含多个扇区
特点:内核通过逻辑块地址(LBA)抽象磁盘访问,隐藏扇区细节 - 页(Page)
内存管理单位:内存数据组织的最小单位,通常为4KB(与块大小一致)
作用:虚拟内存和物理内存交换的基本单元,页框(Page Frame)是物理页的容器
特点:页是内存管理器的操作单位,与磁盘块大小对齐以优化I/O效率 - 缓冲区(Buffer)
数据中转层:磁盘块在内存中的表示,属于页框的一部分
作用:缓存磁盘数据,减少直接I/O操作,通过buffer_head结构管理
特点:一个页框可包含多个块缓冲区,形成链表结构
层级关系总结
硬件到软件:扇区(硬件)→ 块(文件系统)→ 页(内存)
大小关系:1页 = 1块(通常4KB) = 8个扇区(512B)
数据流:磁盘扇区 → 块缓冲区(内存页框) → 文件系统块
8、Kconfig -》menuconfig-》.config、
在Linux内核配置系统中,Kconfig和.config文件是核心组件,它们的关系可概括为:
Kconfig
作为配置选项的"蓝图",定义了内核编译时可选择的模块及其属性(如布尔型、三态或字符串类型),并通过menu/endmenu组织菜单层级结构。它分布在源码树的各个目录中,形成分布式配置数据库,当执行make menuconfig时会解析这些文件生成交互界面。
.config
是用户通过配置工具(如menuconfig)保存的实际选择结果,记录了所有选项的最终状态(如CONFIG_FOO=y/m或is not set)。该文件直接指导编译过程:
=y表示静态编译进内核
=m生成可加载模块
is not set则排除编译。
内核编译时,顶层Makefile会读取.config文件,并生成include/generated/autoconf.h供代码条件编译使用。
交互流程
Kconfig提供配置选项的定义和结构,而.config保存用户的选择。
修改配置时,menuconfig会同步更新.config文件,确保依赖关系合法(如禁用父选项会自动禁用子选项)。
若手动编辑.config可能导致依赖冲突,建议通过配置工具调整。
简言之,Kconfig是"菜单",.config是"点餐单",两者共同完成内核的模块化定制编译。
9、GRUB/LILO:Linux 引导加载器
核心角色
GRUB(GRand Unified Bootloader)和 LILO(LInux LOader)都是 引导加载器(Boot Loader),负责在系统启动时加载 Linux 内核镜像(如 vmlinuz 或 bzImage)。它们的工作流程如下:
A[BIOS/UEFI] --> B[引导加载器 GRUB/LILO]
B --> C[加载内核镜像]
C --> D[移交控制权给内核]
关键区别
与内核镜像的交互方式
GRUB 的工作流程
读取 grub.cfg 配置文件(通常由 grub-mkconfig 生成)。
直接加载内核镜像和 initramfs 到内存(支持文件系统抽象,无需物理扇区定位)。
传递启动参数(如 root=/dev/sda1)给内核。
示例配置片段:
menuentry "Linux" {
linux /vmlinuz-5.15.0 root=/dev/sda1
initrd /initramfs-5.15.0.img
}
initramfs(Initial RAM File System)是 Linux 内核启动时加载的临时根文件系统。它由内核直接解压到内存中运行,为内核挂载真正的磁盘根文件系统(如 ext4、Btrfs)提供必需的准备环境。
LILO 的工作流程
依赖 /etc/lilo.conf 手动配置内核路径:
image=/boot/vmlinuz-4.19.0
label=Linux
root=/dev/sda1 指定系统的根文件系统(/)所在的存储设备位置。
运行 lilo 命令将内核的物理磁盘位置写入 MBR(主引导记录)。
缺陷:磁盘物理结构变化(如调整分区)会导致引导失败,需重新运行 lilo。
10、BIOS 与 UEFI:计算机启动固件
核心定义
BIOS (Basic Input/Output System)
诞生于 1975 年的传统固件
存储在主板 ROM 芯片中
仅支持 16 位处理器模式
最大寻址空间:2.1 TB(受 MBR 分区限制)
UEFI (Unified Extensible Firmware Interface)
2005 年取代 BIOS 的现代标准
模块化设计,支持 C 语言开发
支持 32/64 位模式
寻址空间:9.4 ZB(支持 GPT 分区)
BIOS 的限制
只能读取磁盘前 440 字节的引导代码:
传统BIOS确实会读取磁盘前440字节作为主引导记录(MBR,Master Boot Record)的引导代码部分。这440字节位于MBR的前部,后接64字节的分区表和2字节的结束标志(55AA),共同构成512字节的MBR(Master Boot Record)。
技术细节:
引导代码(Bootstrap Code)占用446字节(实际应用中常称为440字节)
分区表(Partition Table)占用64字节
结束标志占用2字节(0x55AA)
BIOS启动时会将这440字节的引导代码加载到内存地址0x7C00处执行,这是引导过程的第一阶段。
需通过中间加载器(如 GRUB)才能启动内核
示例:安装 Linux 时必须创建 /boot 分区
UEFI 的优势
直接从 EFI 系统分区 (FAT32格式) 加载 .efi 文件
支持原生内核启动(如 Linux 的 EFI stub)
典型路径:
/EFI/
├── ubuntu/grubx64.efi
├── Windows/Bootmgfw.efi
└── macOS/Bootloader.efi
11、Linux内核调度策略
Linux内核的调度策略是其多任务处理能力的核心,通过优先级分类和时间分配算法实现资源高效协调。根据进程类型和需求,主要分为以下策略:
一、实时调度策略
SCHED_FIFO(先进先出)
实时进程按就绪队列顺序执行,一旦占用CPU会持续运行直到主动放弃(如调用sleep())或被更高优先级进程抢占。
优先级范围:0-99(数值越高优先级越高),可抢占所有普通进程。
SCHED_RR(轮转调度)
在SCHED_FIFO基础上增加时间片机制:每个进程执行固定时间片后被放回队列尾部,同优先级进程轮流运行。
避免单一进程长期垄断CPU,适合需公平性的实时场景(如流媒体处理)。
二、普通进程调度策略
SCHED_NORMAL(CFS完全公平调度器)
核心机制:通过vruntime(虚拟运行时间)量化进程CPU使用量,值越小表示累积CPU时间越少,优先级越高。
实现方式:
用红黑树管理调度实体,以vruntime为键值,每次选择最小vruntime的进程执行。
动态调整新建/唤醒进程的vruntime,避免因休眠导致的不公平。
优先级控制:通过nice值(-20至19)影响权重,计算公式:vruntime = 实际运行时间 × (NICE_0_LOAD / 权重),低nice值进程获得更多实际CPU时间。
SCHED_BATCH:针对批处理进程(如编译任务),减少调度频率以提升缓存利用率,适合非交互任务。
SCHED_IDLE:最低优先级策略,仅在系统空闲时运行,不影响其他进程.
12、进程上下文
在Linux系统中,进程上下文(Process Context)是进程执行时所需的环境状态集合,包含用户空间资源、内核数据结构及硬件寄存器值。其核心构成如下:
用户级上下文(User-Level Context)
内容:进程的用户空间资源,包括程序代码段、全局数据、用户堆栈及共享内存区。
可见性:对用户态程序可见,是进程直接操作的地址空间。
系统级上下文(System-Level Context)
内容:内核管理的进程元数据,包括:
进程控制块(task_struct):存储进程状态、优先级、PID等;
内存管理信息(mm_struct):虚拟内存布局、页表等;
文件描述符表:记录打开的文件资源;
内核堆栈:用于系统调用或异常处理时的内核函数调用。
可见性:仅内核态可访问,对用户态不可见。
寄存器上下文(Register Context)
内容:CPU硬件状态,包括程序计数器(PC)、栈指针(SP)、状态寄存器(PSW)、通用寄存器等。
作用:保存进程被切换前的执行点,确保恢复时继续运行。
13、中断上下文
中断上下文(Interrupt Context)是操作系统内核处理硬件中断时的关键执行环境,其核心特征在于与进程解耦的异步响应机制。以下是其核心要点:
定义与触发机制
中断上下文是CPU响应硬件中断(如外设请求)时保存的临时执行环境,通过中断控制器(如GIC)触发,强制暂停当前进程或线程,跳转至中断服务程序(ISR)执行。硬件中断的异步性使其与任何用户进程无关,仅代表硬件事件的处理需求。
关键特性
无进程关联性:中断上下文不与特定task_struct绑定,current宏虽指向被中断进程,但实际不为其服务。
执行限制:
禁止睡眠/阻塞:无法调用可能引发调度的函数(如kmalloc(GFP_KERNEL)或mutex_lock())。
无用户空间访问:被中断进程的页表无效,无法直接读写用户内存。
不可抢占性:默认不可被抢占(除非显式开启),且需避免长时间持有自旋锁。
现场保护:保存中断发生时的寄存器状态(如程序计数器、堆栈指针)、中断号及CPU标志位,确保处理后能恢复原执行流。
为避免中断处理耗时过长,Linux采用顶半部/底半部机制:顶半部(如ISR)仅完成紧急操作(如清除中断标志),耗时任务(如数据处理)延迟至底半部(如软中断、tasklet或工作队列)在进程上下文中执行。例如,网卡中断中,顶半部快速接收数据包,底半部负责协议栈处理。
中断上下文的高效管理是保证系统实时性与吞吐量的关键,其设计需严格遵循上述约束以避免死锁或数据损坏。
14、协程
协程(Coroutine)是一种用户态的轻量级并发单元,其核心特点在于由程序员主动控制调度,而非依赖操作系统内核。以下是协程的关键特性与对比分析:
协作式调度:协程通过主动挂起(yield)和恢复(resume)实现任务切换,无需内核介入,切换开销仅为线程的1/100至1/1000。
单线程内并发:协程运行于同一线程中,通过事件循环或调度器管理任务,天然避免线程竞争问题。
15、管道pipe
Linux管道(pipe)是一种进程间通信(IPC)机制,允许具有亲缘关系的进程(如父子进程)通过内核缓冲区进行数据交换。
管道本质上是一种特殊的文件系统,只存在于内存中而不占用磁盘空间。通过pipe()系统调用创建管道时,内核会返回两个文件描述符:pipe_fd[0]用于读取数据,pipe_fd[1]用于写入数据。管道操作遵循先进先出(FIFO)原则,并提供了互斥、同步和进程存在性检查三方面的协调能力。
在典型使用场景中,父进程创建管道后调用fork()产生子进程。由于子进程继承父进程的文件描述符,双方可通过关闭不需要的描述符来建立单向通信通道。例如父进程关闭读端pipe_fd[0]后向pipe_fd[1]写入数据,同时子进程关闭写端pipe_fd[1]后从pipe_fd[0]读取数据。
管道通信具有以下特性:当写进程将数据写入管道后进入睡眠状态,直到读进程取走数据才会被唤醒;同样地,读进程遇到空管道时也会睡眠等待新数据到达。这种机制能有效避免竞争条件,确保数据传递的可靠性
相关:
IPC
生产者-消费者模型
阻塞队列
16、伪终端
伪终端是一种由软件实现的终端模拟器,它允许程序像控制真实终端一样控制另一个程序。伪终端本质上是运行在用户态的终端模拟器创建的一对字符设备。
伪终端由两个主要部分组成:
主设备(master device, PTY master):通常为/dev/ptmx,模拟终端的控制端。应用程序可以通过此设备与伪终端进行交互,接收和发送数据。
从设备(slave device, PTY slave):通常位于/dev/pts/*目录下,模拟终端的用户端。与普通的物理终端一样,程序通过从设备与用户交互。
当用户通过伪终端与系统交互时,主设备会处理输入和输出流,从设备提供类似物理终端的环境给程序使用。伪终端通过/dev/ptmx字符设备文件实现,当进程打开/dev/ptmx文件时,会同时获得一个指向pseudoterminal master(ptm)的文件描述符和一个在/dev/pts目录中创建的pseudoterminal slave(pts)设备
伪终端与真实终端的区别
伪终端与真实终端(物理终端)有本质区别:
物理终端:直接连接在主机上的显示器、键盘鼠标等设备,在实际机架式服务器部署中,一般是多台服务器共享一套终端(KVM)。
虚拟终端(tty):附加在物理终端之上,用软件方式虚拟实现。在Linux中,可以通过Ctrl-Alt-F[1-6]切换虚拟终端,对应的文件是/dev/tty#。
伪终端(pty):完全由软件实现的终端模拟,主要应用于图形界面下的命令行接口和基于SSH/Telnet协议的远程连接。
伪终端与真实终端的核心区别在于:伪终端是软件仿真终端程序运行在用户空间,而真实终端是物理设备或内核模拟的终端
伪终端存在的根本原因
伪终端(Pseudo Terminal, PTY)作为计算机系统中的重要技术,其存在和发展主要基于以下几个核心原因:
一、解耦终端硬件与会话管理
伪终端最根本的设计目的是实现终端硬件与会话管理的解耦。在传统计算机系统中,命令行程序通常需要直接与物理终端设备交互,这种紧密耦合带来了诸多限制:
硬件抽象:伪终端为应用程序提供了统一的终端接口,使程序无需关心底层是物理终端、图形终端还是远程终端
会话独立性:终端会话可以独立于物理设备存在,支持会话的保存、恢复和迁移
多终端支持:单个系统可以同时支持多个终端会话,而无需实际连接多个物理设备
这种解耦使得命令行程序能够在各种环境中运行,而无需修改代码或重新编译。
二、支持远程登录和终端模拟
伪终端技术为现代计算环境提供了关键支持:
远程访问:SSH、Telnet等协议依赖伪终端实现远程终端会话,使用户能够通过网络访问远程系统
终端模拟器:图形界面下的终端模拟器(如xterm、GNOME Terminal)使用伪终端为shell提供终端接口
多路复用:工具如tmux、screen利用伪终端实现终端会话的多路复用和持久化
三、提供更灵活的终端交互方式
伪终端相比物理终端提供了更灵活和强大的交互能力:
自动化测试:expect等工具利用伪终端实现交互式程序的自动化测试
会话记录:script程序可以完整记录终端会话的输入输出
管道处理:解决标准I/O全缓冲导致的死锁问题,使管道通信更可靠
协同进程:为需要终端交互的协同进程提供支持
四、技术演进与系统兼容性
从技术发展角度看,伪终端的出现也是计算机系统演进的自然结果:
向后兼容:保持对传统终端应用程序的兼容性
扩展功能:在不改变现有程序的前提下,为终端添加新功能
多用户支持:支持多用户同时使用同一系统,每个用户获得独立的终端环境
伪终端的存在体现了计算机系统设计中"抽象"和"分层"的重要思想,通过软件模拟解决了硬件限制带来的问题,为现代计算环境提供了灵活、强大的终端支持能力。
17、elf文件格式
参考:ELF文件结构
二、硬件
1、GPIO的八种工作模式详解
GPIO(通用输入输出)是微控制器与外部设备交互的核心接口,其工作模式决定了引脚的功能特性。以下是STM32等MCU中常见的八种模式分类及典型应用场景:
一、输入模式(用于读取外部信号)
浮空输入(Floating Input)
原理:引脚无内部上拉/下拉电阻,电平完全由外部信号决定。若悬空,电平可能随机漂移。
特点:响应速度快,适合高频数字信号(如UART接收)。
场景:接收明确驱动的信号(如SPI的MISO引脚)。
上拉输入(Input Pull-Up, IPU)
原理:内部上拉电阻(约30-50kΩ)将引脚默认拉至高电平(VDD),外部低电平可拉低引脚。
特点:避免悬空干扰,默认高电平。
场景:按键检测(按键接GND)或模块状态信号(如就绪信号)。
下拉输入(Input Pull-Down, IPD)
原理:内部下拉电阻(约30-50kΩ)将引脚默认拉至低电平(GND),外部高电平可拉高引脚。
特点:默认低电平,防止悬空。
场景:按键检测(按键接VDD)或限位开关。
模拟输入(Analog Input, AIN)
原理:关闭数字缓冲器,引脚直接连接ADC模块,采集连续电压信号。
特点:避免数字电路干扰,精度高。
场景:模拟传感器(如温度、光照)或电池电压检测。
二、输出模式(用于驱动外部设备)
推挽输出(Push-Pull Output)
原理:通过P-MOS(拉高)和N-MOS(拉低)互补驱动,可主动输出高/低电平。
特点:驱动能力强,适合数字信号(如LED、继电器)。
场景:控制LED、蜂鸣器等简单负载。
开漏输出(Open-Drain Output)
原理:仅N-MOS管工作,可拉低电平或高阻态(需外接上拉电阻输出高电平)。
特点:支持“线与”逻辑,避免总线冲突。
场景:I2C、SMBus等总线通信。
复用推挽输出(Alternate Function Push-Pull)
原理:引脚复用为外设功能(如USART、SPI),输出模式为推挽。
场景:串口通信(TX引脚)、SPI主设备输出。
复用开漏输出(Alternate Function Open-Drain)
原理:引脚复用为外设功能,输出模式为开漏。
场景:I2C时钟线(SCL)或需要多设备共享的总线。
关键硬件结构
施密特触发器:稳定输入电平,防止噪声干扰。
保护二极管:防止过压/欠压损坏芯片(如输入电压超过VDD或低于GND时导通)。
总结:GPIO模式的选择需结合信号类型(数字/模拟)、驱动需求(推挽/开漏)及外设复用功能,合理配置可优化系统稳定性和功耗。
2、I2C总线接上拉电阻的核心原因
I2C总线(Inter-Integrated Circuit)采用开漏输出(Open-Drain)结构,其SDA(数据线)和SCL(时钟线)引脚仅能主动拉低电平(逻辑0),无法直接输出高电平(逻辑1)。因此,必须通过外接上拉电阻实现以下关键功能:
确保空闲状态的高电平
当所有设备释放总线时,上拉电阻将SDA/SCL线拉至高电平(Vcc),避免信号线浮空导致的电平不确定或噪声干扰。
支持线与逻辑(Wire-AND)
多设备共享总线时,任一设备拉低总线即可实现逻辑“与”操作(总线为低电平)。若采用推挽输出,多设备同时驱动不同电平会导致短路损坏。
限制电流与保护器件
上拉电阻限制设备拉低总线时的灌电流(Sink Current),防止过流损坏IO端口(如低电平电压超过0.4V或电流超过3mA)。
优化信号完整性
与总线寄生电容形成RC充电回路,平衡上升时间(Rise Time)与噪声抑制。电阻过大会导致上升沿过缓,影响高速通信(如400kHz模式)。
多主机和仲裁
在I2C中,支持多个主机及从机,多个主机同时使用总线时,通过仲裁方式避免数据冲突,决定总线占用权。
在I2C通信中,主机既是发送方也是接收方,在发送每一位数据时,主机都会将自己发送的位与 SDA 线上的实际电平进行比较。
一旦检测到自己发送的电平与 SDA 线上的实际低电平不一致,该主机会判定自己在仲裁中失败,然后放弃对总线的控制,进入接收状态。
输出模式下读取输入状态的硬件条件,大多数微控制器允许在GPIO配置为输出模式时,直接读取输入寄存器(如GPIOx_IDR)获取引脚实际电平。
3、并、串行通信
串行通信和并行通信是数据传输的两种基础方式,主要差异体现在传输路径、效率及适用场景上:
一、传输方式对比
并行通信
定义:通过多条数据线同时传输多位数据(如8位、16位),需额外时钟线同步。
优点:速度快,适合短距离高速传输(如CPU与内存通信)。
缺点:信号线多导致布线复杂,易受串扰影响,长距离传输性能下降。
典型应用:旧式打印机(LPT接口)、PATA硬盘接口、DDR内存总线。
串行通信
定义:通过单条数据线逐位传输数据,依赖协议或时钟同步。
优点:硬件成本低,抗干扰强,适合长距离通信(如RS-485支持1200米)。
缺点:理论速度低于并行通信(但高速协议如PCIe已突破限制)。
典型应用:UART(单片机调试)、I²C(传感器)、SPI(FLASH存储)、USB(外设连接)。
二、通信模式分类
单工/半双工/全双工
单工:单向传输(如电视广播)。
半双工:双向但分时传输(如对讲机)。
全双工:双向同时传输(如电话、USB)。
三、技术演进与场景适配
并行通信:逐渐被高速串行协议(如PCIe、SATA)取代,仅保留在特定短距场景。
串行通信:通过差分信号(如USB)或调制技术(如光纤)提升速率,成为主流。
4、异、同步通信
异步通信和同步通信是数据通信的两种基础模式,主要差异体现在时序控制、传输效率和适用场景上:
一、定义与基本原理
同步通信
定义:依赖共享时钟信号协调数据传输,发送方和接收方需保持同频同相,**数据以块(帧)**为单位连续传输。
特点:
阻塞等待:发送方需等待接收方确认响应后才能继续传输。
高传输速率:适合高速、实时性要求高的场景(如SPI、I²C协议)。
异步通信
定义:无需共享时钟,通过起始位和停止位标记字符边界,数据以单个字符(字节)为单位独立传输。
特点:
非阻塞:发送方无需等待响应即可发送下一数据,灵活性高。
低硬件成本:适合长距离或速率不高的场景(如UART)。
5、CRC循环冗余校验
参考链接:https://blog.csdn.net/liht_1634/article/details/124328005
CRC(循环冗余校验,Cyclic Redundancy Check)是一种基于多项式除法的错误检测编码技术。
在 K 位信息码(目标发送数据)后再拼接 R位校验码,使整个编码长度为 N位,因此这种编码也叫 (N,K) 码。
通俗的说,就是在需要发送的信息后面附加 1个数(即校验码),生成 1个新的发送数据发送给接收端。这个数据要求能够使生成的新数据被 1个特定的数整除。此处整除需要引入模2 除法的概念。
CRC 校验的具体做法:
①选定一个标准除数(P 位二进制数据串),P是发送接收双方约定好了的。
②在要发送的数据(M 位)后面加上 P-1位0,然后将这个新数 (M+P-1位) 以模2 除法的方式除以上面这个标准除数,所得到的余数也就是该数据的 CRC 校验码(注:余数必须比除数少且只少一位,不够就补 0)
③将这个校验码附在原 M位数据后面,构成新的 M+P-1位数据,发送给接收端。
④接收端将接收到的数据除以标准除数,如果余数为 0 则认为数据正确。
注意:CRC 校验中有两个关键点:
①要预先确定一个发送端和接收端都用来作为除数的二进制比特串(或多项式);
②把原始帧与上面选定的除数进行二进制除法运算,计算出 FCS。
前者可以随机选择,也可按国际上通行的标准选择,但最高位和最低位必须均为 “1”。
计算示例:
设需要发送的信息为 M = 1010001101,产生多项式对应的代码为 P = 110101(X[5]+X[4]+X[2]+1),R = 5。在 M 后加 5个0,然后对 P 做模2 除法运算,得余数 r(x) 对应的代码:01110。故实际需要发送的数据是 101000110101110。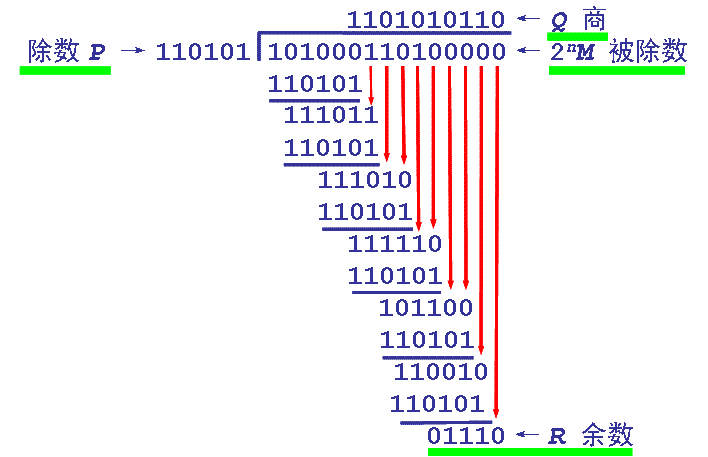
6、CAN(Controller Area Network)
CAN(Controller Area Network,控制器局域网)是一种广泛应用于汽车电子和工业自动化领域的串行通信协议.
物理层设计:双绞线差分信号传输,需120Ω终端电阻匹配阻抗.
阻抗匹配是电子工程中确保信号高效传输的关键技术,其核心在于调整源端、传输线与负载端的阻抗关系,以最小化信号反射并最大化功率传输。
7、中断
单片机中断函数中执行耗时长的代码会导致的问题
在单片机编程中,中断函数(ISR)的设计原则是尽可能简短和快速执行。如果在中断函数中放置耗时长的代码,会导致一系列系统问题。以下是详细分析:
一、中断函数设计原则
快速响应原则:中断函数应尽可能简短,通常不应超过几十个机器周期。中断的本质是让CPU能够快速响应紧急事件,而不是处理复杂任务。
最小化处理:中断函数中只应完成必要的最小化处理,如设置标志位、读取关键数据等。
避免复杂操作:不应在中断函数中进行复杂计算、调用其他函数或执行循环操作。
二、长中断代码导致的具体问题
主程序执行中断:
中断会打断主程序的正常执行流程
长时间中断会导致主程序"饥饿",影响系统实时性
可能导致关键任务无法按时完成
中断丢失:
可能错过其他中断请求,特别是高优先级中断
在51单片机中,相同优先级的中断不会打断正在执行的中断
可能导致系统无法及时响应重要事件
系统稳定性问题:
可能导致系统响应变慢或出现异常
可能造成数据不一致或系统崩溃
在共享资源访问时可能引发竞态条件
性能下降:
频繁的中断处理会占用大量CPU时间
降低系统整体效率
增加功耗
8、DMA
DMA(Direct Memory Access,直接内存访问)是一种计算机系统中允许外设与内存直接双向传输数据的技术,通过专用控制器(DMAC)实现高速数据传输,无需CPU全程介入。其核心价值在于降低CPU负载,提升系统整体效率,尤其适用于大数据量传输场景(如音视频处理、网络通信等)。
DMA工作原理
请求阶段:外设向DMA控制器(DMAC)发送DMA请求(DREQ),DMAC向CPU申请总线控制权。
响应阶段:CPU在当前总线周期结束后释放总线,通过HLDA信号授权DMAC接管总线。
传输阶段:DMAC直接控制数据从源地址(如外设寄存器)传输到目标地址(如内存),支持单字或块传输。
结束阶段:传输完成后,DMAC释放总线并通知CPU,可能触发中断。
DMA控制器关键特性
多通道支持:现代DMA控制器(如STM32的DMA1/DMA2)提供多个独立通道,每个通道可配置优先级和触发源。
仲裁机制:通过软件优先级(高/中/低)和硬件通道编号(低编号优先)解决多通道冲突。
数据宽度与对齐:支持8/16/32位数据宽度,可配置地址自增模式以适应不同外设需求。
9、emmc
eMMC(Embedded MultiMediaCard)是一种面向便携移动设备的嵌入式存储解决方案,由NAND闪存芯片、控制器及标准接口协议集成封装而成,采用BGA(球栅阵列)直接焊接在主板上。其核心优势在于简化设备存储设计,广泛应用于智能手机、平板电脑、智能电视及工业控制领域。
技术架构与组成
NAND闪存:作为数据存储核心,通常采用MLC(多层单元)或TLC(三层单元)技术,平衡成本与性能。
控制器:负责坏块管理、磨损均衡、ECC校验及接口协议处理,提升数据可靠性和寿命。
接口协议:支持MMC标准,早期版本(如eMMC 4.41)速率达104MB/s,最新eMMC 5.1标准提升至400MB/s。
应用场景与优势
中低端市场主导:因成本低、设计简单,成为消费电子主流存储方案。
工业与车载扩展:通过车规级认证的eMMC适用于高可靠性场景。
与其他存储技术的对比
vs UFS:eMMC采用半双工并行接口,而UFS为全双工串行接口,速度更高(UFS 3.0达2400MB/s)。
vs SSD:eMMC为轻量级“硬盘”,SSD性能更强但体积和成本更高。
固态硬盘(Solid State Disk或Solid State Drive,SSD).SSD内部通常包括控制器、缓存和闪存颗粒三部分,闪存颗粒通常会有多个。
技术演进与趋势
自2007年MMC 4.1规范发布后,eMMC持续迭代,但逐渐被UFS取代于高端市场。
UFS(Universal Flash Storage)是一种专为移动设备和嵌入式系统设计的高性能闪存存储标准,具有低功耗、高带宽和全双工通信等特点。
三、c/c++
1、左、右值问题
数组名
在C或C++中,int a[3]定义了一个包含3个整数的数组,而a++和++a这样的操作对数组名a是非法的,会导致编译错误。以下是详细解释:
1.数组名的本质
• 数组名a在大多数表达式中会隐式转换为指向数组首元素的指针(类型为int*),但数组名本身不是左值(即不能被修改)。
• 例如:
int a[3];
int *p = a; // 合法:a 转换为 &a[0]
2.为什么a++和++a非法?
• a++和++a是修改操作,要求操作数是左值(可被赋值)。
• 但数组名a是常量指针(不可修改的地址),尝试修改它会触发编译错误:
a++; // 错误:不能修改数组名
++a; // 错误:同上
• 错误类型:通常是“lvalue required”或“cannot increment value of type ‘int[3]’”。
3.合法操作:指针变量++
• 如果用指针变量指向数组,则可以自增:
int a[3];
int *p = a;
p++; // 合法:p 是变量,可以修改
• 此时p++会让指针指向a[1]。
4.特殊情况:&a的行为
• &a的类型是int (*)[3](指向数组的指针),但它仍然不是左值:
(&a)++; // 非法:&a 也不是左值
5.总结
• 数组名a:是常量指针,不能被修改(a++、++a、a += 1均非法)。
• 指针变量:可以自增(如p++)。
• 如果需要遍历数组,应使用指针变量或数组下标(如a[i])。
关键点
• 数组名在表达式中会退化为指针,但它是不可修改的常量。
• 指针变量(如int *p)可以自由修改,但数组名(如a)不能。
2、类型转换机制(混合运算)
整数提升
先转 int/uint (补码),再截断,再提升。
在表达式计算前,所有小于int的整型(如char、short)会先被提升为int类型。如果原始类型的所有值都能用int表示,则提升为int,否则提升为unsigned int.
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度,再进行截断。
规则:整形提升是按照变量的数据类型的二进制位符号位来提升的。
无符号数整型提升高位补0
有符号数的提升,高位补符号位(负数补1,正数补0)
负数的整型提升
//负数的整型提升
char c1 = -1;
//10000000000000000000000000000001-原码
//11111111111111111111111111111110-反码
//11111111111111111111111111111111-补码
//char类型只有1个字节,即八个比特位,所以我们要对它的补码进行截断
//得到11111111
//整型提升高位补充符号位,即1
//所以提升后的结果为:
//11111111111111111111111111111111
溢出操作
char a = 5;
//00000000000000000000000000000101
//截断后:
//00000101
//整形提升后:
//00000000000000000000000000000101
char b = 126;
//000000000000000000000000111 1110
//截断后:
//0111 1110
//整型提升后:
//000000000000000000000000111 1110
char c = a + b;
//00000000000000000000000000000101
//00000000000000000000000001111110
//00000000000000000000000010000011
//截断后:
//10000011
//整形提升后:
//11111111111111111111111110000011-补码(符号位为1,可知是负数,所以要转换成原码打印)
//11111111111111111111111110000010-反码
//10000000000000000000000001111101-原码
printf("%d\n", c);//-125
对比操作
char a = 0xb6;
short b = 0xb600;
//字符类型和短整型都要进行整型提升
int c = 0xb6000000;
if (a == 0xb6)
printf("a"); 不输出
if (b == 0xb600)
printf("b"); 不输出
if (c == 0xb6000000)
printf("c");//只输出c
算术转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。下面的层次体系称为寻常算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int
如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另外一个操作数的类型后执行运算。数据类型一般朝着浮点精度更高,长度更长的方向转换。
① 【低字节 = 高字节】高字节发生整型截断
int i1 = 257; //0000 0000 .... 0001 0000 0001
char c1 = i1; //截断,只保留最低8位 0000 0001
c1 -》1
② 【高字节 = 低字节】低字节发生整型提升
char c1 = -1; //先int,再截断,补码:1111 ...... 1111,截断-》1111 1111
int i1 = c1; //提升 1111 ..... 1111, 原码:1000 ..... 0001
i1-> -1
③ 【无符号 = 有符号】有符号转换为无符号,转换后注意最高位为数值位
④ 【有符号 = 无符号】无符号转换为有符号,转换后注意最高位为符号位
在C语言中,高字节 = 低字节的运算规则主要涉及类型转换和二进制处理机制。以下是核心规则:
总结:低转高(补0 or 补1),按补码规则进行算术转换
隐式类型转换
当无符号低字节(如unsigned char)与有符号高字节(如signed int)进行运算时,编译器会将低字节隐式转换为高字节的类型。若低字节为无符号数,转换时执行零扩展(高位补0);若低字节为有符号数,则执行符号扩展(高位补符号位)。
运算过程
零扩展:无符号低字节转换为高字节类型时,直接在高位补0。例如,unsigned char a = 0xFF转换为int后为0x000000FF。
符号扩展:有符号低字节转换为高字节类型时,高位补符号位。例如,signed char b = -1(补码0xFF)转换为int后为0xFFFFFFFF。
运算时,所有操作数统一为高字节类型后,按补码规则进行算术或逻辑运算。
结果解释
最终结果的解释取决于目标变量的类型。若结果赋给无符号类型,则按无符号数解释;若赋给有符号类型,则按补码规则转换为有符号值。例如:
unsigned char uc = 0xFF; // 无符号255
int si = uc; // 转换为int后为255(零扩展)
signed char sc = -1; // 有符号-1
unsigned int ui = sc; // 转换为unsigned int后为4294967295(符号扩展)
低字节 = 高字节
总结:先截断,按补码规则进行算术转换
int i = -60343;
unsigned char a = i; a-》201
-60343的32位补码表示:0xFFFF11C9
截取低8位:0xC9(即二进制11001001)
截断后的8位数据0xC9被直接解释为无符号整数,值为201(0xC9的十进制)
int i = -60343;
char a = i; a-》 -55
-60343的32位补码表示:0xFFFF11C9
截取低8位:0xC9(二进制11001001)
截断后的8位数据0xC9被解释为有符号char类型时,其最高位(符号位)为1,表示负数。
补码转换为十进制:
1100 1001 补码
1100 1000 反码
1011 0111 原码-》-55
3、取反操作(~i)
参考:按位取反运计算方法
步骤:
先取补码(计算机中二进制数在内存中是以补码的形式存放的),得到A;
A的二进制的全部位(包括符号位)进行取反,得到B;
取B的补码,得到C;
按补码规则进行算术转换,得到十进制D。
结论:
1. 所有正整数的按位取反是其本身+1的负数
2. 所有负整数的按位取反是其本身+1的绝对值
3. 零的按位取反是 -1(0在数学界既不是正数也不是负数)
32位有符号整数表示中,x = -2147483648(即 -2³¹)是一个特殊的数值,其补码:10000000 00000000 00000000 00000000
~x = |x+1| = 2147483647 (用结论直接算)
对正数5按位取反——> (~5)
补码:0000 0101
全部位取反:1111 1010
再取其补码:1000 0101(反码) -》1000 0110(补码) -》十进制:-6
~5 = -(5+1) = -6(结论求)
对负数 -10 按位取反——> (~ -10)
补码:1000 1010(原码) -》1111 0101(反码) -》1111 0110(补码)
全部位取反:0000 1001
取其补码:0000 1001(原码=反码=补码)-》十进制: 9
~ -10 = |-10+1| = 9 (结论求)
4、取负操作(-i)
步骤:
取补码,得到A;
全部位(包括符号位)取反,得到B;
B+1为取反操作的补码,得到C;
按补码规则进行算术转换,得到十进制D。
结论:
补码取反后,加 1;
32位有符号整数表示中,x = -2147483648(即 -2³¹)是一个特殊的数值,其补码:10000000 00000000 00000000 00000000
-x = 01111111 11111111 11111111 11111111 + 0000… 0001 = 10000000 00000000 00000000 00000000 = x = -2147483648
对 +5 取负:
补码:0000 0101
全部取反: 1111 1010
加 1 : 1111 1011 -》十进制:1111 1010(反码)-》1000 0101(原码)-5
对 -5 取负:
补码:1111 1011
全部取反:0000 0100
加 1:0000 0101-》十进制:0000 0101(原码)5
5、指针
char a 和 char* a
char a; 编译器会为变量a在内存中分配一块大小为 1 个字节的空间,用于存储一个字符。int* a;在 C 语言中,仅定义了一个整型指针变量 a ,此时只为指针变量 a 本身分配了存储“地址”的内存(通常是 4 字节或 8 字节,取决于系统的寻址能力),但并没有为 a 所指向的“整型数据”分配内存。
int* p;
scanf("%d", p);
这段代码存在严重问题,会导致未定义行为(Undefined Behavior)。以下是关键问题分析:
指针未初始化:
int* p 声明了指针但未分配内存
此时 p 指向随机内存地址(野指针)
危险操作:
scanf("%d", p) 试图向未分配的内存写入数据
可能引发段错误(Segmentation Fault)或破坏其他内存数据
正确做法(两种解决方案):
方案一:先分配内存
int* p = malloc(sizeof(int)); // 动态分配
scanf("%d", p);
// 使用后记得 free(p)
方案二:指向有效变量
int value;
int* p = &value; // 指向栈变量
scanf("%d", p);
特别提醒:使用指针时必须确保指向合法的内存地址,动态分配的内存使用后要及时释放。
6、/ %
除号的正负取舍和一般的算数一样,符号相同为正,相异为负
求余符号的正负取舍和被除数符号相同,且求余符号的两个操作数必须是整数类型。
-3/16=0 16/-3=-5 -3%16=-3 16%-3=1
7、volatile
volatile关键字在C/C++中主要用于防止编译器优化和确保内存访问的实时性,其核心作用可归纳为以下方面:
防止编译器优化
当变量被声明为volatile时,编译器会禁止对该变量的读写操作进行优化,强制每次访问都直接从内存中读取或写入,而非使用寄存器中的缓存值。这种机制在硬件寄存器映射或中断服务程序中尤为重要,例如操作内存映射的硬件寄存器时,若未使用volatile修饰,编译器可能合并读-改-写指令序列,导致硬件控制异常。
多线程环境中的可见性(非原子性)
volatile能保证变量在不同线程间的可见性,即一个线程对volatile变量的修改会立即对其他线程可见。但需注意,volatile仅解决可见性问题,并不保证操作的原子性或顺序一致性。例如多线程中的共享计数器若仅用volatile修饰,仍可能因非原子操作(如++)导致数据竞争。
禁止指令重排序
在C++中,volatile能限制编译器对相关指令的重排序优化,确保对volatile变量的操作顺序与代码书写顺序一致。不过,其作用弱于C++11的内存屏障(如std::atomic),无法完全避免CPU层面的指令重排。
典型应用场景
硬件寄存器访问:如嵌入式开发中通过内存地址操作硬件设备时,必须使用volatile防止编译器优化导致读写失效。
中断服务程序:中断修改的全局变量需声明为volatile,确保主程序能感知变化。
信号处理:信号处理函数修改的变量需标记为volatile,避免编译器假设其值不变。
8、指针退化
- 数组传参的“退化”问题
在 C 语言中,当数组作为函数参数传递时,会退化为指向数组首元素的指针。此时,函数内部无法通过这个指针直接获取数组的长度、维度等原始信息。
例如:
void func(int arr[5]) {
// 这里的 arr 实际是 int* 类型,sizeof(arr) 是指针大小,而非数组总字节数
printf("%zu\n", sizeof(arr)); // 输出指针的大小(如 4 或 8,取决于系统)
}
int main() {
int arr[5] = {1,2,3,4,5};
func(arr);
return 0;
}
- typedef 定义数组类型的作用
通过 typedef 可以为“特定长度的数组”定义一个新类型名,从而让数组的“长度信息”被保留下来。
比如typedef int Vec[3]; ,它的含义是:定义了一个新类型 Vec , Vec 代表“包含 3 个 int 的数组”。
- 用 typedef 定义的类型传参,避免退化
当用 typedef 定义的数组类型作为函数参数时,参数不再是单纯的“指针”,而是带有长度信息的“数组类型”,因此能避免“退化”。
示例:
typedef int Vec[3]; // 定义类型 Vec:包含 3 个 int 的数组
void func(Vec v) {
// 此时 v 是“int[3]”类型的数组,sizeof(v) 是数组总字节数(3 * sizeof(int))
printf("%zu\n", sizeof(v)); // 输出 12(假设 int 占 4 字节)
}
int main() {
Vec myVec = {1,2,3}; // myVec 是 int[3] 类型的数组
func(myVec);
return 0;
}
- 多维数组的存储与类型
以 int arr[2][3] 为例,它是一个二维数组,逻辑上可看作“2行3列的整型数组”,但在内存中是连续存储的(按行优先,先存第0行的3个元素,再存第1行的3个元素)。
从类型角度, arr 本身的类型是 int [2][3] ,它不是“指针的指针( int** )”,而是“指向包含3个int的一维数组的指针”(类型为 int (*)[3] )。
- 数组传参的退化规则
当数组作为函数参数传递时,会“退化”为指向其首元素的指针,但“首元素的类型”由原数组的维度决定:
- 对于一维数组 int arr[5] ,首元素是 int 类型,所以退化为 int* 。
- 对于二维数组 int arr[2][3] ,首元素是“包含3个 int 的一维数组”(即 arr[0] 的类型是 int [3] ),所以退化为 int (*)[3] (指向“包含3个 int 的数组”的指针)。
- 为什么不是 int** ?
int** 表示“指向 int* 类型指针的指针”,它的逻辑是“指针存的是另一个指针的地址,最终通过两次解引用得到 int 值”。
但二维数组 int arr[2][3] 的内存是连续的, arr 退化后的指针 int (*)[3] ,只需要一次解引用就能得到“包含3个 int 的数组”,再通过数组下标访问具体元素(本质是连续内存的偏移)。
二者的内存模型和访问逻辑完全不同,因此多维数组传参不会退化为 int** 。
简单总结:二维数组传参退化后的指针,是“指向一维数组的指针”( int (* )[3] ),和“指向指针的指针”( int * * )不是同一个类型.
9、位域
在C语言中,位域(bit - field)是一种特殊的结构体成员定义方式。它允许我们为结构体的成员指定占用的二进制位数,从而可以让一个结构体成员占用少于完整字节的空间,达到节省内存的目的。
例如,我们可以定义一个结构体:
struct BitFieldExample {
unsigned int flag1 : 1; // flag1 占用 1 个二进制位
unsigned int flag2 : 2; // flag2 占用 2 个二进制位
unsigned int value : 5; // value 占用 5 个二进制位
};
在这个例子中, flag1 、 flag2 、 value 都是位域成员,它们分别占用1位、2位、5位,而不是完整的字节(1字节 = 8位)。通过这种方式,能够更高效地利用内存,尤其在处理一些只需要少量位就能表示的信息(如标志位等)时非常有用。
位域本质上是对数据的位级操作,它可以存储各种整数类型(经过转换后以二进制形式存储),并非“只能存储二进制数据”这种表述(数据本身可以是十进制等,存储时是二进制,但概念上不是只能处理二进制形式的数据)。
位域不仅可以用于无符号整型数据,也可以用于有符号整型数据等(不同编译器可能有不同实现,但标准允许有符号整型用于位域)
10、++
对于表达式 int a = 1; int b = (a++) + (++a); 中 b 的值,可以通过以下步骤分析:
大多数编译器按从左到右顺序求值。
初始状态:a 初始值为 1。
表达式求值过程:
(a++):后置自增运算符,先返回 a 的当前值 1,随后 a 自增为 2。
(++a):前置自增运算符,先将 a 从 2 自增为 3,再返回 3。
因此,b = 1 (a++) + 3 (++a) = 4。
最终结果:b 的值为 4,此时 a 的值为 3。
注意:此类表达式的结果依赖于编译器的具体实现(如操作数的求值顺序),不同编译器可能产生不同结果。上述分析基于大多数现代编译器的常见行为。
四、ROTS
1、freertos的移植
①选择对应目标处理器架构的FreeRTOS版本
②安装相应的工具链,文件移植。
③对FreeRTOS进行配置。
内存管理:需要为FreeRTOS分配一定的内存空间。
任务管理:需要配置任务的堆栈大小、优先级等。
时钟和定时器:需要配置FreeRTOS使用哪个时钟源和定时器。
信号量和队列:需要配置信号量和队列的大小和类型。
调度器配置:需要选择FreeRTOS的调度器类型和优化设置。
内存管理:需要为FreeRTOS分配一定的内存空间。
从 portable/MemMang 选择内存分配方案(如 heap_4.c)
修改 FreeRTOSConfig.h 中的内存相关参数:
#define configTOTAL_HEAP_SIZE (16 * 1024) // 16KB堆大小
任务管理:需要配置任务的堆栈大小、优先级等。
/***
* 任务创建任务配置
* 包括: 任务优先级 堆栈大小 任务句柄 创建任务
*/
#define START_PRIO 1 /* 任务优先级 */
#define START_STK_SIZE 64 /* 任务堆栈大小,字为单位,1字等于4字节 */
static TaskHandle_t StartTask_Handler=NULL; /* 创建任务的任务句柄 */
static void StartTaskCreate(void* parameter); /* 创建任务的任务函数名 */
时钟和定时器:需要配置FreeRTOS使用哪个时钟源和定时器。
#define configCPU_CLOCK_HZ SystemCoreClock /* 定义CPU主频, 单位: Hz, 无默认需定义 */
#define configSYSTICK_CLOCK_HZ (configCPU_CLOCK_HZ / 8)/* 定义SysTick时钟频率,当SysTick时钟频率与内核时钟频率不同时才可以定义, 单位: Hz, 默认: 不定义 */
#define configTICK_RATE_HZ 1000 /* 定义系统时钟节拍频率, 单位: Hz, 无默认需定义 */
调度器配置:需要选择FreeRTOS的调度器类型和优化设置。
#define configUSE_PREEMPTION 1 // 抢占式调度
#define configUSE_TIME_SLICING 1 /* 1: 使能时间片调度, 默认: 1 */
信号量和队列:需要配置信号量和队列的大小和类型。
#define configUSE_MUTEXES 1 /* 1: 使能互斥信号量, 默认: 0 */
#define configUSE_RECURSIVE_MUTEXES 1 /* 1: 使能递归互斥信号量, 默认: 0 */
#define configUSE_COUNTING_SEMAPHORES 1 /* 1: 使能计数信号量, 默认: 0 */
#define configQUEUE_REGISTRY_SIZE 8 /* 定义可以注册的信号量和消息队列的个数, 默认: 0 */
#define configUSE_QUEUE_SETS 1 /* 1: 使能队列集, 默认: 0 */
④实现FreeRTOS底层函数。
中断相关:
参考:SysTick定时器及FreeRTOS系统节拍
移植处理器架构相关代码
以 ARM Cortex-M 为例:
复制 portable/GCC/ARM_CM3 目录到工程中
实现以下关键函数:
vPortSetupTimerInterrupt():配置系统滴答定时器(SysTick)
xPortPendSVHandler():PendSV 异常处理(任务切换)
xPortSysTickHandler():SysTick 异常处理(节拍计数)
vPortSetupTimerInterrupt():配置系统滴答定时器(SysTick)
SysTick系统定时器是属于内核中的一个外设,内嵌在NVIC中。该定时器是一个24位的向下递减的计数器。在裸机编程中常用做延时函数,而在FreeRTOS中则用来给系统提供时钟的,在FreeRTOS中任务的切换即每个任务运行的时间是由SysTick定时器提供的。因此非常重要。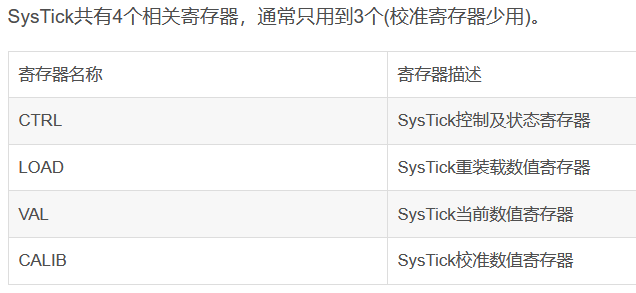
在FreeRTOS中已经提供了SysTick配置的函数vPortSetupTimerInterrupt(),函数在port.c文件中。
在SysTick中断函数(SysTick_Handler)中并不是直接执行任务切换,而是将xTickCount进行加1操作,xTickCount是FreeRTOS的系统时钟节拍数,具体实现函数则是xTaskIncrementTick(),该函数在中断函数中被调用。中断函数的实现在port.c文件中也有定义:xPortSysTickHandler(),因此在SysTick中断函数中直接调用该函数即可。
void SysTick_Handler(void)
{
if(xTaskGetSchedulerState()!=taskSCHEDULER_NOT_STARTED) //系统已经运行
{
xPortSysTickHandler(); //调用port.c中已写好的中断函数,后面介绍
}
}
xPortPendSVHandler():PendSV 异常处理(任务切换)
实现任务上下文切换的核心中断处理函数,通过保存当前任务上下文(R4-R11寄存器)到任务栈,并恢复新任务上下文来完成切换。
/* FreeRTOS中断服务函数相关定义 */
#define xPortPendSVHandler PendSV_Handler
#define vPortSVCHandler SVC_Handler
PendSV_Handler是port.c中的函数,是汇编指令。
通过portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT触发。(在xPortSysTickHandler函数中判断是否触发)
被设计为最低优先级异常(0xFF),确保在高优先级中断完成后执行。
使用进程栈指针(PSP)进行任务栈操作,与主栈(MSP)隔离。
xPortSysTickHandler():SysTick 异常处理(节拍计数)
作用:处理周期性定时中断,主要完成:
调用xTaskIncrementTick()更新系统节拍计数器xTickCount1618
检查任务延迟列表,将到期任务移入就绪列表316
若需任务切换,触发PendSV异常
void xPortSysTickHandler( void )
{
vPortRaiseBASEPRI();
{
/* Increment the RTOS tick. */
if( xTaskIncrementTick() != pdFALSE )
{
/* A context switch is required. Context switching is performed in
* the PendSV interrupt. Pend the PendSV interrupt. */
portNVIC_INT_CTRL_REG = portNVIC_PENDSVSET_BIT;触发PendSV_Handler
}
}
vPortClearBASEPRIFromISR();
}
三函数协同工作流程
初始化阶段:vPortSetupTimerInterrupt()配置SysTick定时器
运行时:
SysTick定期触发xPortSysTickHandler(),该处理函数判断是否需要切换任务,若需要则触发PendSV
xPortPendSVHandler()执行实际上下文切换
首次任务启动:通过SVC异常加载第一个任务,后续切换由PendSV处理
必须将PendSV设为最低优先级(0xFF),SysTick通常设为次低
⑤搭建FreeRTOS应用程序,实现任务调度。
五、其他
1、状态机
参考:状态机
状态机又称有限状态自动机(Finite State Machine, FSM),是现实事物运行规则抽象而成的一个数学模型。
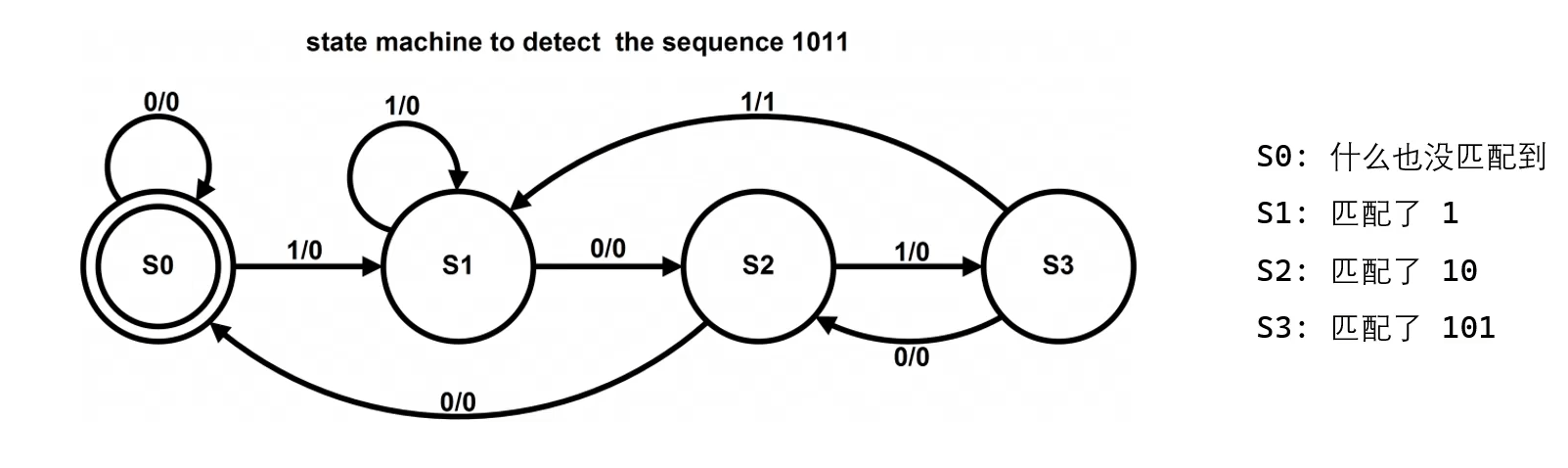
这幅图,是一个用来解码连续01序列中1011串的状态机,这种图示,是状态机的经典画法。
其中,每一个状态用一个圆圈表示,每个状态都有个名字,名字必须各不相同。状态机启动的状态,用两个圆圈表示。状态之间,
用箭头连起来,在连线上,用斜线 /,分开左右两部分,分别表示输入和输出。
状态机每个节拍取得一次输入,并且完成一次输出(也可以不输出)。状态机在下一个节拍的状态,完全由状态机的当前状态和输
入决定。如果还有其他信息用于决定状态机的下一个状态,则这个“其他信息”应该合并到状态里面去。这一点很重要。
状态转换表: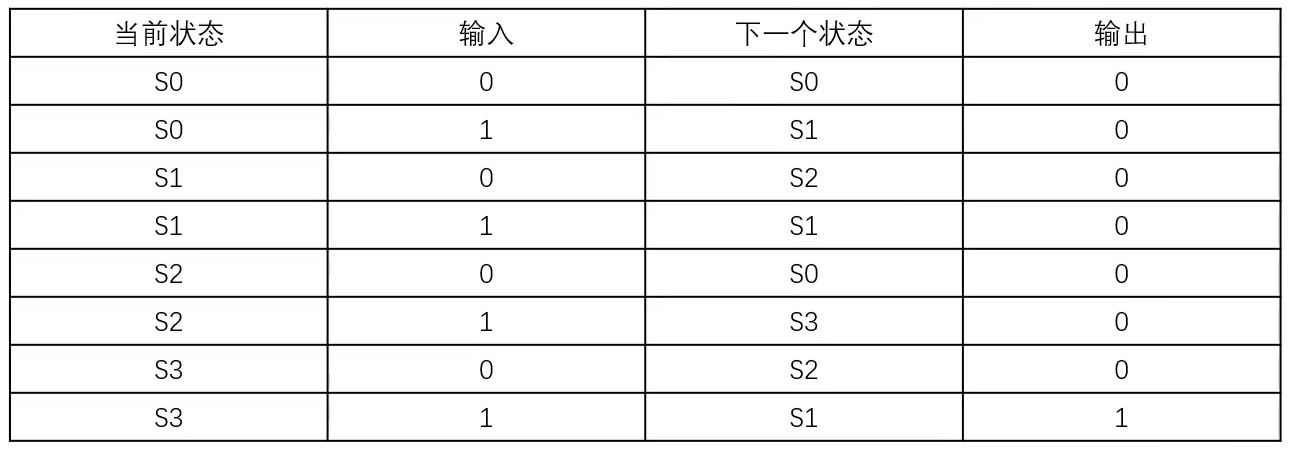
c语言代码: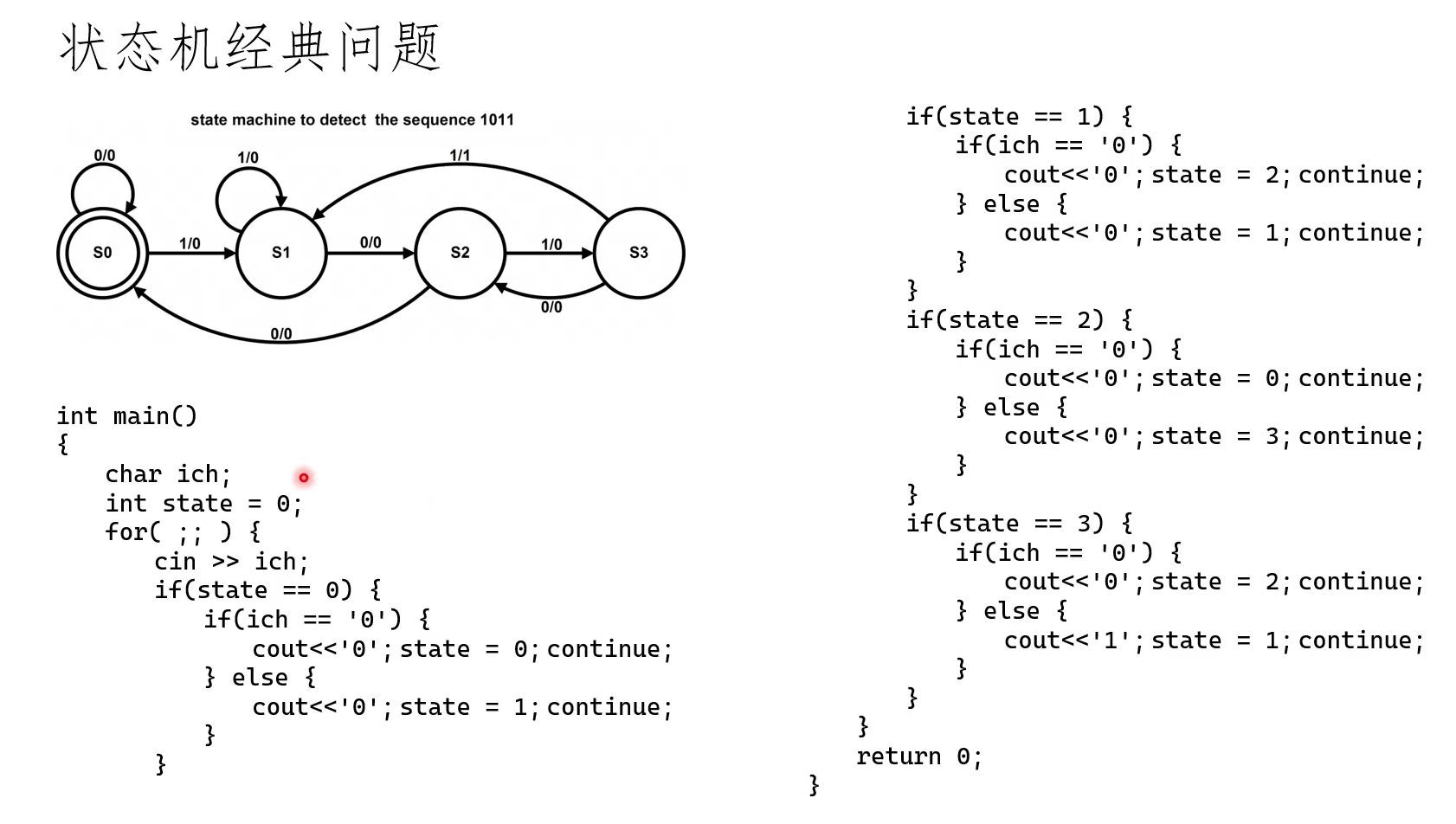
状态机写法:
首先需要先把状态定义出来,画出状态转换图,写出状态转换表。
写代码的时候,先把状态变量初始化。
在状态循环内部,先输入数据。然后一定要先做状态判断,再根据输入情况决定:
①下一个状态是什么?
②输出什么?
一个状态判断结束后,马上continue。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)