block DMA & scatter-gather DMA
1、DMA 传输
在数据传输过程中,DMA(Direct Memory Access,直接内存访问) 是一种能够在外设与内存之间直接传递数据、无需 CPU 逐字节参与的机制。使用 DMA,可以让 CPU 将数据搬运的工作交给 DMA 控制器,从而腾出资源执行其他任务。
在配置一次 DMA 传输时,通常需要关注以下三个核心要素:
- 源地址(Source Address):数据的起始位置;
- 目的地址(Destination Address):数据要写入的目标位置;
- 传输长度(Transfer Length):需要搬运的数据量。
这三个要素共同定义了一次 DMA 操作的基本范围和方向。
1.1 block DMA
在最基本的 Block DMA(块传输 DMA) 模式下,DMA 控制器一次只能处理一段物理地址连续的内存区域。也就是说,源地址和目的地址在物理内存中都必须是连续的。
由于 DMA 控制器的寻址能力、系统总线带宽、以及操作系统的内存分配策略等因素限制,一次可传输的数据量通常不会太大。因此,对于大块数据,DMA 传输往往需要拆分多次进行。
在每次传输完成后,DMA 控制器通常会产生一个中断通知 CPU,由 CPU 负责启动下一段传输。这样,数据以「块」为单位被依次搬运——这就是 Block DMA 模式 的工作方式。
1.2 scatter-gather DMA
与 Block DMA 不同,Scatter-Gather DMA(分散-聚合 DMA) 支持一次传输中包含多个物理上不连续的内存块。
在这种模式下,系统会先构建一个描述符链表(Descriptor List),其中记录了每个数据块的物理地址和长度信息。DMA 控制器只需获得链表的首地址,就能自动按链表依次读取描述符,连续完成多段数据的搬运。
这样,DMA 控制器在传输完一块数据后,不需要每次都打断 CPU,而是自动读取下一项描述符继续工作。只有当所有数据块都传输完毕时,才会触发一次中断。
以全志 T3 芯片为例,芯片手册中的说明如下: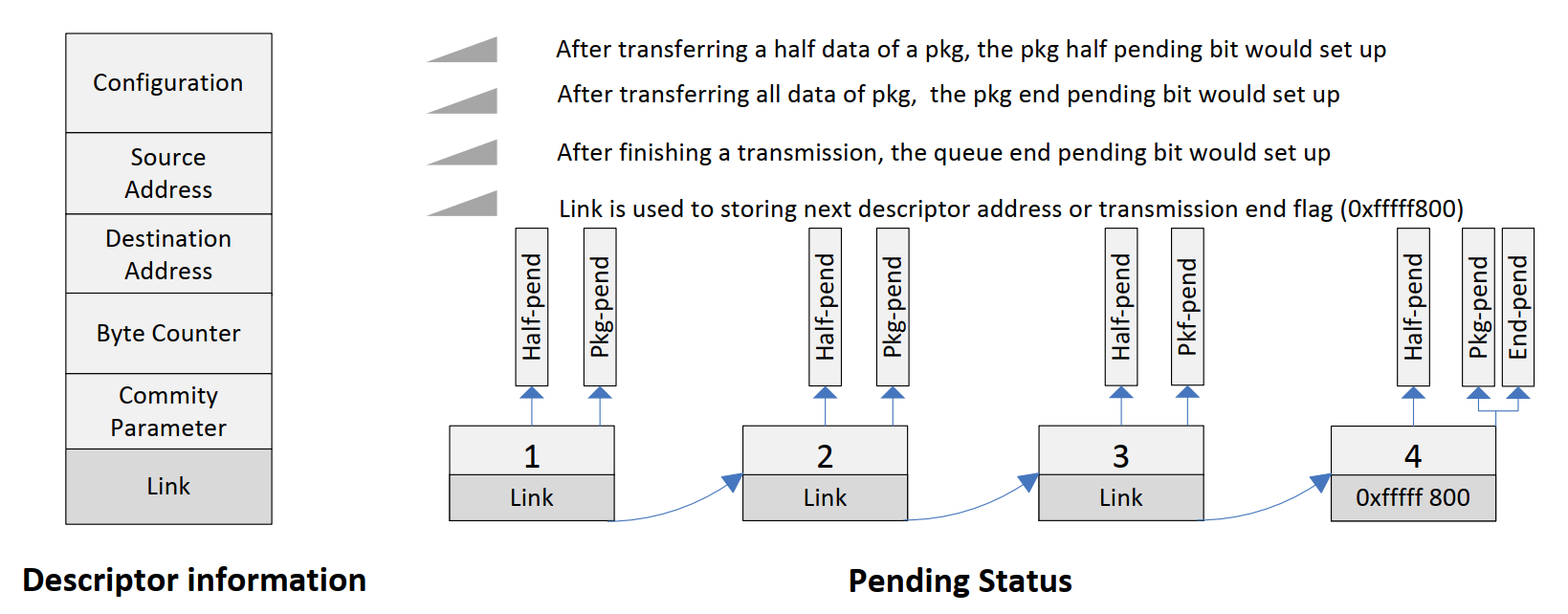
这种方式的优点非常明显:
- 减少了中断次数;
- 降低了 CPU 的参与度;
- 提高了数据传输效率与总线利用率。
因此,Scatter-Gather DMA 常用于高速外设(如网络控制器、存储控制器、GPU)或需要传输大规模、分散数据的场景中。
2、DMA 传输拆分案例
2.1 vmalloc 和 kmalloc 接口区别
Linux 内核中,我们常见的两个内存分配接口 vmalloc 和 kmalloc,两个接口存在着很大差别。
对比 vmalloc 和 kmalloc
- vmalloc:
- 虚拟地址连续,物理地址不一定连续(注意:每个页内的物理地址一定是连续的)
- 分配内存时,分配的粒度是 整页。即使申请的大小小于页大小,内核也会分配一页的大小
- 用于大块内存(通常 >128KB 或超过 kmalloc 上限)。
- kmalloc:
- 虚拟 & 物理都连续
- 粒度是 cache 对象大小(对用户看上去是字节,但底层对齐)
- 用于小块、频繁分配释放的内存。
注意,我们这里为什么不加上 malloc?因为 Linux 有用户态和内核态的概念。在内核里,不存在用户态的 malloc()。所以内核中不会遇到真正的用户态 malloc 出来的内存。用户态的 buffer 只能通过 copy_from_user() 复制进内核。而内核态,简单来说,大部分内存分配接口都可以分为两大类:
- kmalloc、kzalloc、kcalloc 家族,基于 slab/slub 分配器,最终来自 alloc_pages()
- vmalloc、vzalloc、vmap、vmalloc_user 家族,建立虚拟连续 → 物理不连续的映射
2.2 案例
DMA 传输拆分的原因,总结来说就两点:
- 上层传递的 buf 地址是否物理连续
- DMA 控制器自身的数据搬运能力,例如一次最多能搬运多少数据
我们这里以 SPI 控制器驱动为例,讲解 DMA 传输的拆分问题。
spi_map_buf 函数,将上层传递下来的 buf 数据缓冲区进行映射,如下:
int spi_map_buf(struct spi_controller *ctlr, struct device *dev,
struct sg_table *sgt, void *buf, size_t len,
enum dma_data_direction dir);
- buf 缓冲区不能直接给 DMA 控制器使用,因为不确定 buf 缓冲区地址是否物理连续
- 很多时候,DMA 控制器端会有数据传输限制,例如一次传输,最大可以传输多少数据,所以不一定能够将 buf 缓冲区中的数据一次传送完毕,可能需要拆分成多次传输
所以,这里可以简单分为两种情况:
-
物理地址连续
- 根据 DMA 控制器的能力,找到一个能够传输的最大的长度 desc_len,将当前需要传输的总长度 len,拆分成多个 segment(
DIV_ROUND_UP(len, desc_len)) - 如下,buf 缓冲区物理地址由 3 个连续的物理页构成,需要分成三次进行传输,每次传输最大长度为 desc_len

- 根据 DMA 控制器的能力,找到一个能够传输的最大的长度 desc_len,将当前需要传输的总长度 len,拆分成多个 segment(
-
物理地址不连续
- 以页为单位,如果某个物理地址非页对齐,则根据 DMA 控制器的能力 以及
PAGE_SIZE - offset_in_page(buf)长度,找到一个能够传输的最大的长度 desc_len,作为一次传输的长度…如此往复,直至拆分 len 长度结束 - 如下,buf 缓冲区物理地址由 3 个不连续的物理页构成,需要分成三次进行传输

- 以页为单位,如果某个物理地址非页对齐,则根据 DMA 控制器的能力 以及
drivers\spi\spi.c
int spi_map_buf(struct spi_controller *ctlr, struct device *dev,
struct sg_table *sgt, void *buf, size_t len,
enum dma_data_direction dir)
{
/*
* buf 是内核态的数据缓冲区
* 这里会去判断,该 buf 是否由 vmalloc 接口分配而来
*/
const bool vmalloced_buf = is_vmalloc_addr(buf);
/*
* dma_get_max_seg_size 获取 dma 一次最多可以传输的数据块大小
* 该值通常在使用 DMA 的设备驱动中去设置(从其入参 dev 也能看出和设备绑定)
*/
unsigned int max_seg_size = dma_get_max_seg_size(dev);
#ifdef CONFIG_HIGHMEM
const bool kmap_buf = ((unsigned long)buf >= PKMAP_BASE &&
(unsigned long)buf < (PKMAP_BASE +
(LAST_PKMAP * PAGE_SIZE)));
#else
const bool kmap_buf = false;
#endif
int desc_len;
int sgs;
struct page *vm_page;
struct scatterlist *sg;
void *sg_buf;
size_t min;
int i, ret;
/*
* kmalloc 分配的内存:物理地址通常是连续的
* vmalloc 分配的内存:虚拟地址连续,但物理页可能不连续
* ctlr->max_dma_len 的值,在使用 DMA 的设备驱动中设置,该值控制着设备控制器一次所能接收 dma 传输的最大数据量
*/
if (vmalloced_buf || kmap_buf) {
desc_len = min_t(unsigned long, max_seg_size, PAGE_SIZE);
/*
* 注意,虽然 vmalloc 返回的地址一定是页对齐,但是这里还是无法保证,buf 一定是 vmalloc 的返回地址
* 也可能是 vmalloc 返回地址 + 偏移 ,所以 offset_in_page(buf) 可能非 0
* 这里计算出的结果是,最终会被拆分成 sgs 个 segment
*/
sgs = DIV_ROUND_UP(len + offset_in_page(buf), desc_len);
} else if (virt_addr_valid(buf)) {
/*
* 如果是 kmalloc 分配的内存,则不需要考虑物理地址不连续问题,只需要考虑 dma 控制器的数据传输能力
*/
desc_len = min_t(size_t, max_seg_size, ctlr->max_dma_len);
sgs = DIV_ROUND_UP(len, desc_len);
} else {
return -EINVAL;
}
/* 根据 sgs 段数量,分配相关结构体资源 */
ret = sg_alloc_table(sgt, sgs, GFP_KERNEL);
if (ret != 0)
return ret;
/* 初始化每个段(segment)资源 */
sg = &sgt->sgl[0];
for (i = 0; i < sgs; i++) {
if (vmalloced_buf || kmap_buf) {
/*
* Next scatterlist entry size is the minimum between
* the desc_len and the remaining buffer length that
* fits in a page.
*/
min = min_t(size_t, desc_len,
min_t(size_t, len,
PAGE_SIZE - offset_in_page(buf)));
/* 得到 buf 对应的物理 page 页 vm_page */
if (vmalloced_buf)
vm_page = vmalloc_to_page(buf);
else
vm_page = kmap_to_page(buf);
if (!vm_page) {
sg_free_table(sgt);
return -ENOMEM;
}
sg_set_page(sg, vm_page,
min, offset_in_page(buf));
} else {
/*
* 可以看到,如果物理地址已经连续了,这里直接拆分,
* 拆分的原因,完全是因为 dma 控制器数据传输的限制
*/
min = min_t(size_t, len, desc_len);
sg_buf = buf;
sg_set_buf(sg, sg_buf, min);
}
buf += min;
len -= min;
sg = sg_next(sg);
}
/* 流式 DMA 映射 ,*/
ret = dma_map_sg(dev, sgt->sgl, sgt->nents, dir);
if (!ret)
ret = -ENOMEM;
if (ret < 0) {
sg_free_table(sgt);
return ret;
}
sgt->nents = ret;
return 0;
}
关于流式 DMA 映射接口 dma_map_sg,前面章节讲的很详细了,这里不再赘述。
上面提到的数据拆分,其实只是设备驱动层面的操作——驱动会根据硬件的 DMA 传输能力、物理地址的连续性以及应用层传入的缓冲区特征,将一次用户请求拆分成若干个物理上连续的片段(segment)。
这些片段通常通过 sg_table(scatterlist 表) 结构来组织,用于描述整个传输过程中每个段的起始地址和长度信息。驱动最终会把该 sg_table 交给 DMA 框架或 DMA 控制器驱动。
至于底层 DMA 控制器在执行时,究竟采用 Block DMA 还是 Scatter-Gather DMA 模式,这并不是由上层设备驱动决定的,而是由 DMA 控制器驱动 根据硬件特性自行选择的。
struct scatterlist {
unsigned long page_link;
unsigned int offset;
unsigned int length;
dma_addr_t dma_address;
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;
#endif
};
struct sg_table {
struct scatterlist *sgl; /* the list */
unsigned int nents; /* number of mapped entries */
unsigned int orig_nents; /* original size of list */
};
关于 scatterlist 结构,详见:
3、IOMMU
为什么讲解 DMA 的文章中,又谈到了 IOMMU 呢?因为 IOMMU 与 DMA 息息相关,我们经常在各种外设驱动中看到他的身影。
IOMMU(Input–Output Memory Management Unit)和 MMU 类似,但它服务的对象是 I/O 设备的 DMA 访问。
功能有两个:
- 地址翻译:把设备发出的设备虚拟地址(IOVA, I/O Virtual Address) 转换成实际的物理内存地址
- 访问控制:限制设备只能访问它应该访问的内存,防止“野 DMA”(安全和隔离的关键)
IOMMU 属于 SoC/CPU 芯片的一部分,位于设备与系统内存之间的总线上。
- 设备发起 DMA 请求 → 请求先经过 IOMMU → IOMMU 翻译地址 → 最终访问内存
- 所以 IOMMU 的位置类似于“总线上的守门人/翻译器”
以 ARM 架构为例,看一下 IOMMU 在 SOC 中的位置:
(下图中的 System MMU 就是我们常说的 IOMMU,这里不必纠结,我们统称为 IOMMU)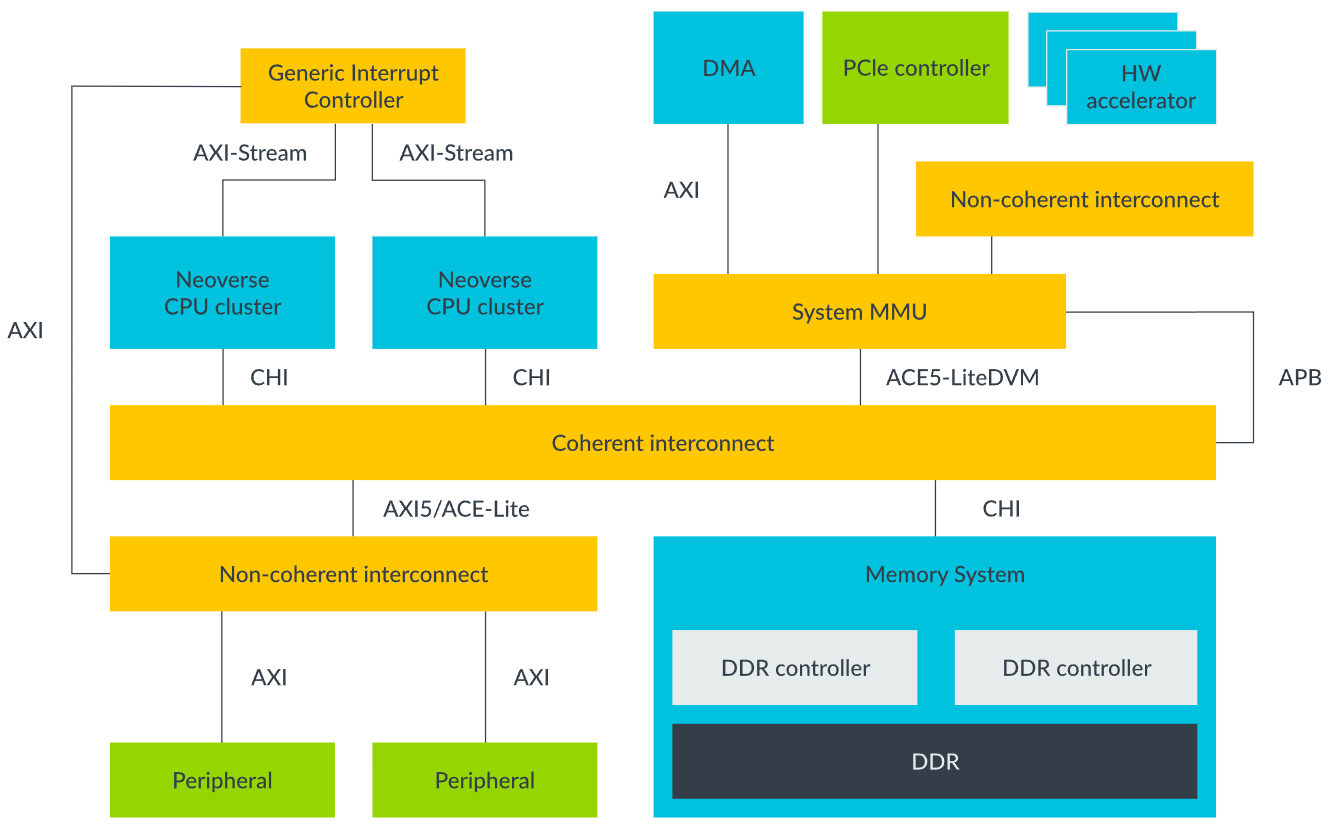
从这里就可以发现,有了 IOMMU 之后,实际上,DMA 的源地址、目的地址,就不再是连续物理地址,而是虚拟地址了。因为此,带来的好处显而易见了:
- 老旧 32 位 DMA 设备也能用高于 4GB 的内存,因为它看到的只是一个 32 位 IOVA,而 IOMMU 会把它翻译到 64 位物理地址
- 驱动只需要用连续的虚拟地址即可,不需要再考虑物理地址是否连续的问题,因为 IOMMU 会帮它映射到可能不连续的物理页
看到这里,我们就会发现,在有 IOMMU 的前提下,DMA 传输数据需要的源地址、目的地址发生了本质变化,不再是需要连续的物理地址了。这一点,我们在前面的 DMA 内存映射浅析 章节也遇到过,有 IOMMU 和没有 IOMMU ,DMA 的使用方式是不一样的。
dma_map_single
--> dma_map_single_attrs
--> dma_map_page_attrs
--> dma_map_direct (直接映射方式,使用 SWIOTLB 机制)
--> get_dma_ops-->map_page (设备支持 IOMMU,通过 IOMMU 提供的操作接口映射内存)

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)