大模型本地部署全攻略与实战应用案例
摘要:本文全面介绍大模型本地部署流程与实战应用,涵盖Llama3、Qwen等主流模型的部署方法。第一部分详细讲解硬件配置、环境搭建和三种部署方式(llama.cpp、vllm、text-generation-webui),提供量化优化等技巧。第二部分展示三个典型应用案例:企业知识库问答系统、VSCode代码生成插件和多模态对话系统,包含完整代码实现。文章还提供性能优化策略和常见问题解决方案,帮助开
前言:为什么需要本地部署大模型?
随着大语言模型(LLM)技术的爆发,企业和个人对模型私有化部署的需求日益增长。本地部署相比云端 API 调用具有三大核心优势:数据隐私性(敏感数据无需上传云端)、成本可控性(一次性硬件投入替代按调用计费)、离线可用性(无网络环境下仍可运行)。
本文将从「本地部署全流程」和「实战应用案例」两部分展开,涵盖主流模型(Llama 3、Qwen、Mistral)的部署工具(llama.cpp、vllm、text-generation-webui)、硬件配置推荐、代码实现、流程设计及优化技巧,帮助读者从零开始搭建本地化大模型系统。
第一部分:大模型本地部署全流程教程
1. 部署前准备:硬件与环境配置
1.1 硬件配置要求
大模型本地部署的核心瓶颈是显存 / 内存和计算能力,不同参数规模的模型对硬件要求差异显著(表 1)。
| 模型类型 | 参数规模 | 最低配置(CPU) | 推荐配置(GPU) | 适用场景 |
|---|---|---|---|---|
| 轻量模型 | 7B-13B | 32GB 内存 + 8 核 CPU | 12GB 显存(RTX 3090/4090) | 个人开发、轻量问答 |
| 中等模型 | 30B-70B | 64GB 内存 + 16 核 CPU | 24GB 显存(RTX A6000)×2 | 企业内部知识库、批量处理 |
| 大模型 | 100B+ | 128GB 内存 + 32 核 CPU | 80GB 显存(A100/H100)×4 | 高精度生成、多模态任务 |
表 1:不同规模模型的硬件配置参考
1.2 软件环境搭建
需提前安装以下基础工具(以 Linux 系统为例,Windows 可通过 WSL 或 Anaconda 实现兼容):
bash
# 1. 安装Python(推荐3.10+)
sudo apt update && sudo apt install python3.10 python3.10-venv python3-pip
# 2. 创建虚拟环境
python3.10 -m venv llm-env
source llm-env/bin/activate # Windows: llm-env\Scripts\activate
# 3. 安装CUDA(GPU加速必需,需匹配显卡型号)
# 参考NVIDIA官网:https://developer.nvidia.com/cuda-toolkit
sudo apt install nvidia-cuda-toolkit
# 4. 验证环境
python -c "import torch; print('CUDA可用:', torch.cuda.is_available())"
# 输出"CUDA可用:True"表示配置成功
2. 主流部署工具与模型下载
2.1 部署工具对比与选择
目前主流的本地部署工具各有侧重,需根据场景选择(表 2):
| 工具名称 | 核心优势 | 支持模型类型 | 适用场景 |
|---|---|---|---|
| llama.cpp | 轻量高效、支持 CPU/GPU 混合推理 | Llama 系列、Qwen、Mistral | 低配置设备、快速验证 |
| vllm | 高吞吐量、支持 PagedAttention | 大部分 Hugging Face 模型 | 高并发服务、批量推理 |
| text-generation-webui | 可视化界面、插件丰富 | 几乎所有开源模型 | 交互式调试、功能演示 |
表 2:主流部署工具特性对比
2.2 模型下载(以 Llama 3 8B 为例)
模型需从 Hugging Face Hub 下载,需提前注册账号并申请模型访问权限(部分模型需审核)。
bash
# 1. 安装Hugging Face CLI
pip install -U "huggingface_hub[cli]"
# 2. 登录(需输入Access Token,在Hugging Face账号设置中获取)
huggingface-cli login
# 3. 下载模型(Llama 3 8B Instruct版本)
mkdir -p models/meta-llama/Llama-3-8B-Instruct
huggingface-cli download meta-llama/Llama-3-8B-Instruct \
--local-dir models/meta-llama/Llama-3-8B-Instruct \
--local-dir-use-symlinks False
3. 三种主流部署方式实战
3.1 方式一:llama.cpp 部署(轻量高效)
llama.cpp 是 C++ 实现的轻量推理框架,支持 INT4/INT8 量化,适合低配置设备。
步骤 1:编译 llama.cpp
bash
# 克隆仓库
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
# 编译(支持CUDA加速)
make LLAMA_CUBLAS=1
步骤 2:模型量化(减少显存占用)
bash
# 将原始模型转换为gguf格式(llama.cpp支持的格式)
python convert.py ../../models/meta-llama/Llama-3-8B-Instruct --outfile models/llama3-8b-instruct.fp16.gguf
# 量化为INT4(显存需求降低75%)
./quantize models/llama3-8b-instruct.fp16.gguf models/llama3-8b-instruct.q4_0.gguf q4_0
步骤 3:启动推理服务
bash
# 命令行交互模式
./main -m models/llama3-8b-instruct.q4_0.gguf -p "请介绍一下人工智能的发展历程" -n 512
# API服务模式(启动HTTP接口)
./server -m models/llama3-8b-instruct.q4_0.gguf --host 0.0.0.0 --port 8080
测试 API:
bash
curl http://localhost:8080/completion -H "Content-Type: application/json" -d '{
"prompt": "请用一句话描述机器学习",
"n_predict": 100
}'
3.2 方式二:vllm 部署(高吞吐量)
vllm 基于 PagedAttention 技术,支持高并发推理,适合生产环境。
步骤 1:安装 vllm
bash
pip install vllm # 支持CUDA 11.7+,如需特定版本:pip install vllm[cuda117]
步骤 2:启动 API 服务
bash
python -m vllm.entrypoints.api_server \
--model models/meta-llama/Llama-3-8B-Instruct \
--port 8000 \
--tensor-parallel-size 1 # 多GPU部署时设置为GPU数量
步骤 3:调用 API(Python 示例)
python
运行
from vllm import LLM, SamplingParams
# 初始化模型
sampling_params = SamplingParams(temperature=0.7, max_tokens=512)
llm = LLM(model="models/meta-llama/Llama-3-8B-Instruct", tensor_parallel_size=1)
# 生成文本
prompts = ["写一段关于环境保护的宣传语", "解释什么是区块链"]
outputs = llm.generate(prompts, sampling_params)
# 打印结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"输入: {prompt}\n输出: {generated_text}\n")
3.3 方式三:text-generation-webui(可视化界面)
适合快速调试和演示,支持插件扩展(如知识库、语音交互)。
步骤 1:安装 webui
bash
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt
步骤 2:启动界面
bash
python server.py --model meta-llama/Llama-3-8B-Instruct --auto-devices --load-in-4bit
启动后访问http://localhost:7860即可看到可视化界面,支持:
- 实时对话交互
- 模型参数调整(温度、top_p 等)
- 插件加载(如
extensions/silero_tts实现语音输出)
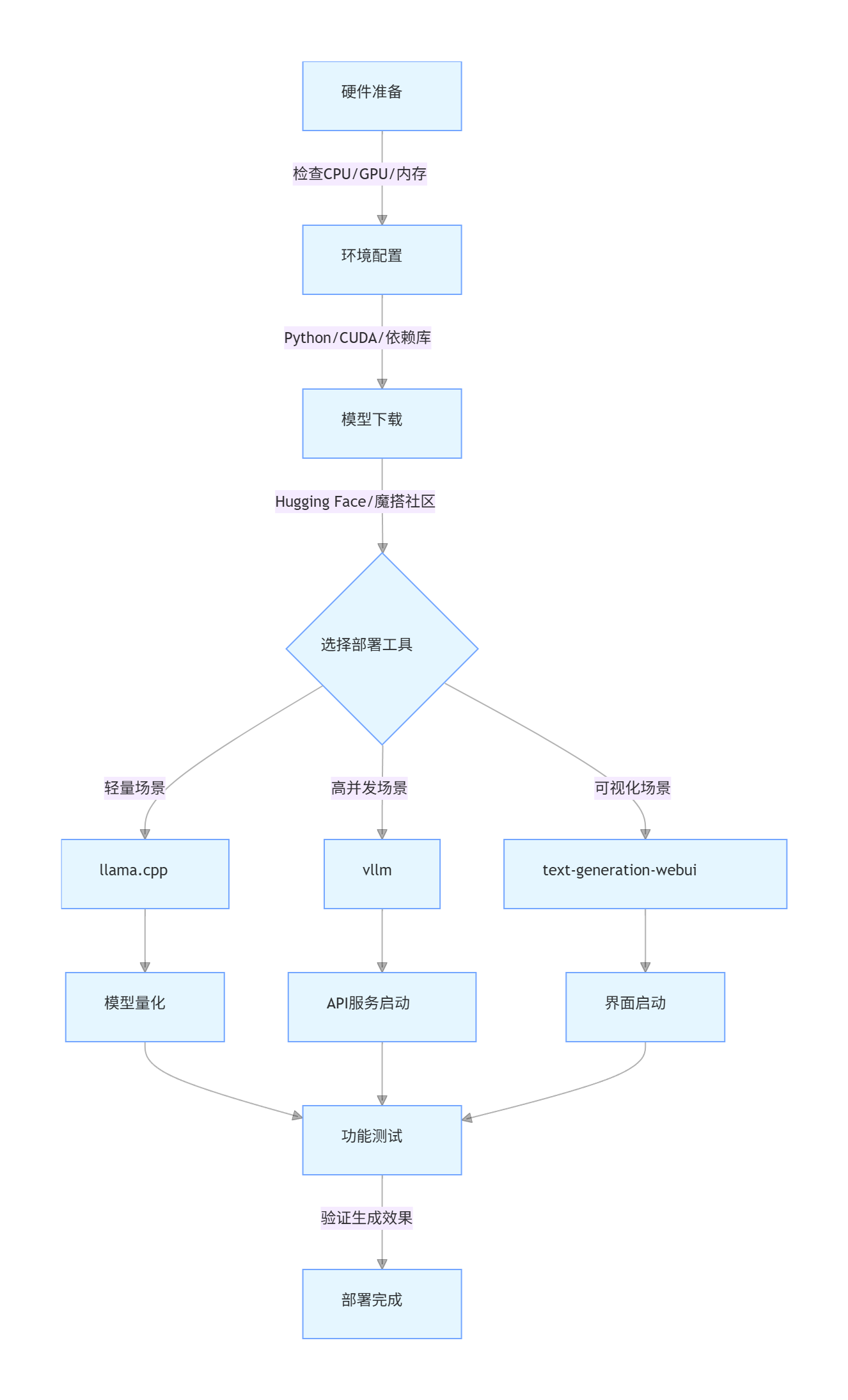
4. 部署流程可视化
graph TD
A[硬件准备] -->|检查CPU/GPU/内存| B[环境配置]
B -->|Python/CUDA/依赖库| C[模型下载]
C -->|Hugging Face/魔搭社区| D{选择部署工具}
D -->|轻量场景| E[llama.cpp]
D -->|高并发场景| F[vllm]
D -->|可视化场景| G[text-generation-webui]
E --> H[模型量化]
F --> I[API服务启动]
G --> J[界面启动]
H & I & J --> K[功能测试]
K -->|验证生成效果| L[部署完成]
第二部分:大模型实战应用案例
案例 1:本地知识库问答系统(企业文档检索)
场景需求
企业内部有大量非结构化文档(如产品手册、规章制度),需构建一个可离线查询的问答系统,支持基于文档内容的精准回答。
技术方案
采用「检索增强生成(RAG)」架构:用户提问→检索相关文档片段→模型结合片段生成回答。
核心组件:
- 文档加载:
langchain.document_loaders - 文本嵌入:
sentence-transformers(生成向量) - 向量数据库:
Chroma(本地轻量数据库) - 大模型:Llama 3 8B(负责生成回答)
实现步骤
步骤 1:安装依赖
bash
pip install langchain chromadb sentence-transformers transformers accelerate
步骤 2:文档处理与向量存储
python
运行
from langchain.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
# 1. 加载文档(指定文件夹下的txt文件)
loader = DirectoryLoader(
path="./company_docs", # 文档存放目录
loader_cls=TextLoader,
glob="*.txt"
)
documents = loader.load()
# 2. 文本分割(按语义拆分,避免截断内容)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", ","]
)
split_docs = text_splitter.split_documents(documents)
# 3. 初始化嵌入模型(生成文本向量)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
# 4. 向量存储(将文档片段存入Chroma)
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="./chroma_db" # 向量库保存路径
)
db.persist()
步骤 3:构建问答链
python
运行
from langchain.llms import VLLM
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 1. 定义Prompt(引导模型结合文档回答)
prompt_template = """
你是企业知识库问答助手,需严格基于以下参考文档回答问题。
若文档中无相关信息,直接回复"未找到相关内容",不编造答案。
参考文档:
{context}
问题:{question}
回答:
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# 2. 连接vllm部署的Llama 3模型
llm = VLLM(
model="models/meta-llama/Llama-3-8B-Instruct",
temperature=0.1, # 降低随机性,保证回答稳定
max_tokens=1024,
top_p=0.9,
host="localhost",
port=8000
)
# 3. 构建检索-生成链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 将检索到的文档片段拼接后输入模型
retriever=db.as_retriever(search_kwargs={"k": 3}), # 检索 top3 相关片段
chain_type_kwargs={"prompt": prompt}
)
步骤 4:测试问答功能
python
运行
# 测试问题1:查询产品保修政策
result = qa_chain.run("本公司产品的保修期限是多久?")
print(f"回答:{result}")
# 测试问题2:查询请假制度
result = qa_chain.run("员工每年可请多少天年假?")
print(f"回答:{result}")
流程可视化
graph LR
A[用户提问] --> B[向量数据库检索]
B -->|返回相关文档片段| C[构建Prompt]
C -->|拼接问题+文档| D[大模型推理]
D --> E[生成回答]
E --> F[返回用户]

Prompt 优化示例
plaintext
你是企业内部合规助手,仅基于提供的《员工手册》回答问题:
1. 回答需简洁明确,使用手册中的原文表述;
2. 若涉及时间、金额等数字,需精确引用;
3. 对模糊问题,优先提供相关条款原文。
参考文档:{context}
问题:{question}
案例 2:本地代码生成助手(IDE 插件)
场景需求
开发一个 VS Code 插件,集成本地大模型,实现在线代码生成、注释添加、bug 修复等功能,无需联网即可使用。
技术方案
- 前端:VS Code 插件(TypeScript)
- 后端:Python API 服务(vllm)
- 模型:CodeLlama 7B(专注代码生成的模型)
实现步骤
步骤 1:部署 CodeLlama 模型
bash
# 下载CodeLlama 7B(需Hugging Face权限)
huggingface-cli download codellama/CodeLlama-7b-Instruct-hf --local-dir models/codellama-7b
# 启动vllm服务(指定代码生成参数)
python -m vllm.entrypoints.api_server \
--model models/codellama-7b \
--port 8001 \
--max_tokens 2048 # 代码生成需要更长的上下文
步骤 2:编写 Python API 适配层
python
运行
# api_server.py
from fastapi import FastAPI
import requests
import json
app = FastAPI()
VLLM_URL = "http://localhost:8001/generate"
@app.post("/generate_code")
async def generate_code(prompt: str):
# 构造CodeLlama所需的Prompt格式
formatted_prompt = f"<s>[INST] {prompt} [/INST]"
# 调用vllm服务
response = requests.post(
VLLM_URL,
json={
"prompt": formatted_prompt,
"temperature": 0.4, # 代码生成需一定确定性
"top_p": 0.95,
"max_tokens": 1024
}
)
return {"code": response.json()["text"][0]}
# 启动服务
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8002)
步骤 3:开发 VS Code 插件(核心代码)
typescript
// extension.ts(VS Code插件入口)
import * as vscode from 'vscode';
import axios from 'axios';
export function activate(context: vscode.ExtensionContext) {
// 注册"生成注释"命令
let disposable = vscode.commands.registerCommand('code-helper.generateComment', async () => {
const editor = vscode.window.activeTextEditor;
if (!editor) return;
// 获取选中的代码
const selection = editor.selection;
const code = editor.document.getText(selection);
if (!code) {
vscode.window.showErrorMessage("请先选中代码");
return;
}
try {
// 调用后端API
const response = await axios.post('http://localhost:8002/generate_code', {
prompt: `为以下Python代码添加详细注释,说明功能、参数和返回值:\n${code}`
});
// 在选中代码上方插入注释
await editor.edit(editBuilder => {
editBuilder.insert(selection.start, `${response.data.code}\n`);
});
} catch (error) {
vscode.window.showErrorMessage("生成失败:" + error);
}
});
context.subscriptions.push(disposable);
}
步骤 4:测试插件功能
- 在 VS Code 中选中一段 Python 代码(如函数定义)
- 按下
Ctrl+Shift+P,输入命令Code Helper: 生成注释 - 插件将调用本地模型生成注释并插入代码中
代码生成 Prompt 示例
plaintext
任务:将以下Python函数改写成TypeScript,要求:
1. 保持功能完全一致;
2. 添加类型注解;
3. 处理可能的空值情况。
Python代码:
def calculate_average(numbers):
if not numbers:
return None
return sum(numbers) / len(numbers)
案例 3:多模态本地对话系统(图文理解)
场景需求
构建一个支持图片 + 文本输入的对话系统,可识别图片内容(如产品、场景)并结合文本提问生成回答(例如:“这张图片中的产品有什么功能?”)。
技术方案
- 视觉编码器:CLIP(将图片转为向量)
- 大模型:Qwen-VL(通义千问多模态模型,支持本地部署)
- 部署工具:text-generation-webui(支持多模态插件)
实现步骤
步骤 1:部署 Qwen-VL 模型
bash
# 下载Qwen-VL-7B(支持图文输入)
huggingface-cli download Qwen/Qwen-VL-Chat --local-dir models/qwen-vl
# 启动webui(加载多模态插件)
cd text-generation-webui
python server.py \
--model Qwen/Qwen-VL-Chat \
--extensions multimodal \
--load-in-4bit
步骤 2:编写图片处理脚本
python
运行
from PIL import Image
import requests
from io import BytesIO
def get_image_data(image_path):
"""将图片转为base64格式(Qwen-VL要求的输入格式)"""
img = Image.open(image_path)
buffer = BytesIO()
img.save(buffer, format="PNG")
return buffer.getvalue()
def query_multimodal(image_path, text):
"""调用webui的API进行多模态对话"""
url = "http://localhost:5000/api/v1/generate"
image_data = get_image_data(image_path)
# 构造Qwen-VL的输入格式(图片+文本)
prompt = f"<img>{image_data}</img>\n{text}"
response = requests.post(url, json={
"prompt": prompt,
"max_new_tokens": 512,
"temperature": 0.6
})
return response.json()["results"][0]["text"]
步骤 3:测试多模态对话
python
运行
# 测试1:识别图片中的物体
result = query_multimodal(
image_path="./product.jpg", # 产品图片路径
text="这张图片中的产品是什么?有哪些特点?"
)
print(f"回答:{result}")
# 测试2:结合图片和文本提问
result = query_multimodal(
image_path="./chart.png", # 数据图表图片
text="根据图片中的图表,2023年的销售额同比增长了多少?"
)
print(f"回答:{result}")
多模态 Prompt 示例
plaintext
已知图片是某公司的办公环境,请回答:
1. 图片中共有多少人?
2. 办公区域的主要颜色是什么?
3. 推测这是哪种类型的公司(如科技、教育)?
<img>{image_data}</img>
第三部分:优化与扩展技巧
1. 性能优化策略
- 模型量化:使用 INT4/INT8 量化(llama.cpp 的
quantize工具),显存需求降低 50%-75%,速度提升 2-3 倍。 - 推理参数调整:减少
max_tokens(生成长度)、降低temperature(随机性)可提升速度。 - 硬件加速:GPU 不足时,可使用 CPU + 内存部署(需关闭
load_in_4bit,但速度较慢)。
2. 功能扩展方向
- 语音交互:集成
whisper(语音转文本)和silero-tts(文本转语音),实现语音对话。 - 多轮对话记忆:通过
langchain.memory保存对话历史,支持上下文连贯的交互。 - 权限控制:在企业部署中添加用户认证(如 JWT),限制不同用户的模型访问权限。
3. 常见问题排查
- 显存不足:检查是否启用量化(
--load-in-4bit)、减少tensor_parallel_size(多 GPU 分配)。 - 模型下载失败:使用
huggingface-cli download --resume-download断点续传。 - 生成速度慢:确认 CUDA 是否正确配置(
nvidia-smi查看显卡状态)、关闭不必要的后台进程。
结语
大模型本地部署已从「技术探索」走向「实用落地」,通过本文介绍的工具和案例,读者可根据自身硬件条件搭建私有化大模型系统,在保护数据隐私的同时享受 AI 技术的便利。随着开源模型(如 Llama 3、Qwen)的持续优化和部署工具的成熟,本地大模型的应用场景将进一步扩展到教育、医疗、制造业等领域,为行业智能化提供新的可能。
建议初学者从 7B 参数模型(如 Llama 3 8B)入手,逐步熟悉部署流程后再尝试更大规模的模型或复杂应用。未来,结合边缘计算和低功耗硬件的本地部署方案,将成为大模型普及的重要方向。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)