【C语言关键字】
C语⾔默认定义的数据类型,不满⾜实际内存资源分配的。所以C语⾔⽀持在标准类型的基础上,通过组合来形成新的类型。本质上就是⽀持程序员根据实际需要来圈定内存的大小。
C语言关键字
0.总览
链接: B站视频
char、int、float、double、short、long、signed、unsigned、void、struct、union、enum、
auto、static、register、extern、const、volatile、restrict、typedef、
if、else、switch、case、default、for、while、do、break、continue、return、goto
1.sizeof关键字
1.1 sizeof(常量/变量/数据类型)
#include <stdio.h>
int main(void)
{
int a = 10;
printf("size of 10 is: %ld \n", sizeof(10));
printf("size of a is: %ld \n", sizeof(a));
printf("size of int is: %ld \n", sizeof(int));
return 0;
}
#程序运⾏结果
size of 10 is: 4
size of a is: 4
size of int is: 4
1.2 sizeof(函数)
sizeof传⼊函数时,得到的结果是计算出函数「返回值」的内存空间⼤⼩,函数本⾝不会被调⽤
(侧⾯也反应sizeof是在编译时就计算出空间⼤⼩,⽽不是在运⾏时)。
#include <stdio.h>
int func(void)
{
printf("func call \n");//这句log不会被打印
return 0;
}
int main(void)
{
int a = 10;
printf("size of func is: %ld \n", sizeof(func()));
return 0;
}
#程序运⾏结果
size of func is: 4
1.3 sizeof不是函数
- sizeof使⽤时不⼀定要有(),但函数调⽤⼀定要有()
#include <stdio.h>
int a = 10;
int main(void)
{
printf("size of a is: %ld", sizeof a);
return 0;
};
#程序运⾏结果
size of a is: 4
- 翻译成汇编就很清晰看到,sizeof在编译的时候就直接算出内存空间大小,并没有函数的⼊栈出栈、call操作。可以体会⼀下my_sizeof和sizeof在汇编层⾯上的区别:
#include <stdio.h>
int a = 10;
int b = 0;
int c = 0;
int my_sizeof(int a)
{
return sizeof(a);
}
int main(void)
{
b = sizeof(a);
c = my_sizeof(a);
return 0;
}
main:
.LFB1:
...
//b = sizeof(a);
//编译时,就计算出来 b = 4
movl $4, b(%rip)
//c = my_sizeof(a);
movl a(%rip), %eax
movl %eax, %edi
call my_sizeof
movl %eax, c(%rip)
...
2.数据类型关键字
2.1 标准类型
2.1.1 char
最⼩内存空间的数据类型,也是最适合操作硬件的数据类型。
我们知道硬件上最⼩的状态是⾼低电平,对于软件来讲就是0和1状态,那C语⾔中为什么没有bit
这个数据类型关键字呢?因为0-1只有这两个状态,对于内存来讲当然是充分利⽤,但对于CPU来讲处
理效率⾮常低。⽐如要把32(0b100000)这个数据从内存读到CPU内部寄存器,⾄少需要执⾏6个指
令周期(1个指令周期:寻址->发读的控制信息->数据通过数据总线送到寄存器)才能读到0b100000。
所以兼顾CPU性能和内存管理,计算机科学家把操作内存最⼩单位为8bit,也称1byte,也就是char类
型,可以表⽰256种状态。
#include <stdio.h>
int main(void)
{
char a = 9;
printf("a = %d, size of a is %ld byte \n", a, sizeof(a));
return 0;
}
#程序运⾏结果
a = 10, size of a is 1 byte
这⾥的 char a = 10; 相当于在内存中圈出⼀块1byte的内存,内存的标签叫a(也可以理解成这块内
存属于a),内存⾥⾯的值是10
Q:想⼀想,声明和定义的区别?extern char a 和 char a;
A: 声明没有分配内存,定义会分配内存。
char类型除了表⽰⼀个具体数字之外,它还可以描述字符空间,即ASCII码。在计算机的世界⾥,只认识01不认识字符,所以ASCII是⼈为定义的⼀套映射标准。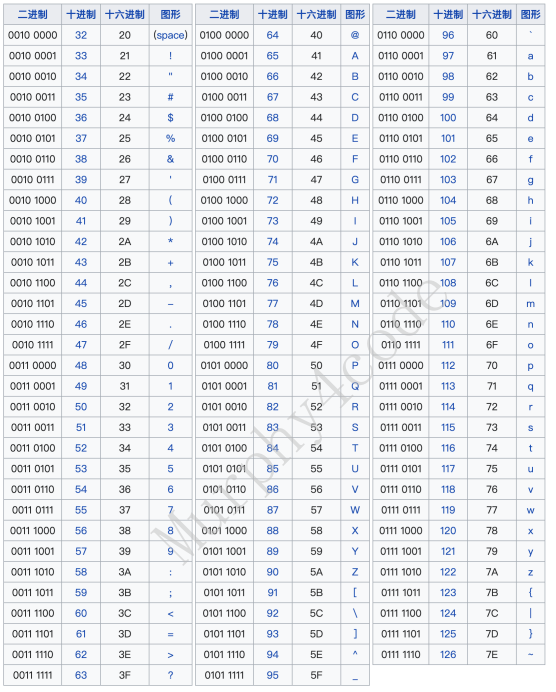
#include <stdio.h>
int main(void)
{
char a = 'a';
printf("a = %c, a ASCII = %d \n", a, a);
return 0;
}
#程序运⾏结果
a = a, a ASCII = 97
在这里插入代码片
2.1.2 int
最适合CPU的数据类型,⼤⼩跟编译器有关。
为了充分发挥CPU的数据处理能⼒,数据总线尽量要充分利⽤,在系统⼀个周期内所能接受的最大处理单位就是int。所以32位的CPU,int就是32bit(4byte),16位的CPU,int就是16bit(2byte)。对于⼀个数字常量默认就是int的,体会以下代码:
#include <stdio.h>
int main(void)
{
int a = 10;
printf("size of 10 is: %ld \n", sizeof(10));
printf("size of a is: %ld \n", sizeof(a));
printf("size of int is: %ld \n", sizeof(int));
return 0;
}
#程序运⾏结果
size of 10 is: 4
size of a is: 4
size of int is: 4
2.1.3 short/long
short和long关键字本质是修饰int的,只是默认情况下我们⽤short和long类型的时候把int省略了。见名知意,short是减少int的空间,long是加⼤int的空间。具体的⼤⼩,由编译器决定
2.1.4 signed/ unsigned
这两个关键字⽤于圈定变量的区间范围。signed代表有符号数,最⾼位代表正负(1:代表负,0:代表正),区间范围从0为⽀点⼀分为半。如,char是8bit,所以signed char范围[-128, 127],unsignedchar范围[0, 255]。⼀般情况可以省略signed不写,int、long、short默认就是signed,但是char在C的标准中,允许定义为signed和unsigned,所以由编译器决定。可以测试⼀下你的机器上char是否是有符号数
2.1.5 float/double
float和double是浮点类型,即可以表⽰⼩数。float是4字节,double是8个字节。在⼀般的嵌⼊式中,浮点的运算相⽐于整形要慢,如果算法没有太⾼的精度要求,建议尽量⽤整形。
float和double是浮点类型在存储上存在精度,所以不能直接判断是否相等,⽽是⼈为的取⼀个精度,然后判断两个⼩数的模与这个精度的⼤⼩。
2.1.6 void
oid类型不能⽤于定义变量,因为空⼤⼩的内存圈定没有意义。⼀般void⽤于函数占位符、void*、强制转换防⽌未⽤参数被编译器警告。
#include <stdio.h>
int main(void)
{
void a;
return 0;
}
#程序运⾏结果
1.c: In function ‘main’:
1.c:5:10: error: variable or field ‘a’ declared void
5 | void a;
|
占位符:表⽰⽆或者空
#include <stdio.h>
//表⽰函数没有形参和返回值
void main(void)
{
printf("hello world \n");
}
void*:表⽰数据空间
#include <stdio.h>
void data_process(void *data,int len)
{
unsigned char* buff = (unsigned char *)data;
for (int i = 0; i < len; i++) {
...
buff[i];
}
}
在这段代码中,void data 是 “无类型指针”,它的核心作用是表示一块 “未知类型的内存空间”,可以用来接收任意类型的数据地址,从而让函数具备处理 “任意类型数据” 的通用性。
具体含义与优势
“无类型” 的灵活性:void * 不指定具体的数据类型(如 int、char* 等),因此可以接收 int、char、结构体 等任意类型变量的地址。例如,你可以传递 int 数组的地址、char 字符串的地址,甚至自定义结构体的地址给这个函数。
“数据空间” 的抽象:data 在这里代表一块 “原始的内存空间”,函数通过 (unsigned char )data 将其强转为 unsigned char 后,就可以按字节(unsigned char 是 1 字节)来访问这块内存中的每一个数据单元,实现对 “任意类型数据” 的字节级处理(比如数据解析、加密、格式转换等)。
表⽰unused:
#include <stdio.h>
void func(int a)
{
int b;
//解决编译器报警告:参数定义未使⽤
(void)a;
}
2.2自定义类型
C语⾔默认定义的数据类型,不满⾜实际内存资源分配的。所以C语⾔⽀持在标准类型的基础上,通过组合来形成新的类型。本质上就是⽀持程序员根据实际需要来圈定内存的大小。
2.2.1 struct
struct 名字 {
char b;
int a;
....
};
Q:下⾯这段代码有分配内存吗?
struct abc {
int a;
char b;
};
A:这⾥只是声明,没有分配内存,a和b这⾥代表结构体的成员
结构体的初始化和访问
#include <stdio.h>
struct abc {
int a;
char b;
};
int main(void)
{
struct abc c = {
.a = 1,
.b = 'c',
};
printf("a = %d b = %c \n",c.a, c.b);
return 0;
}
#程序运⾏结果
a = 1 b = c
字节对⻬
#include <stdio.h>
struct abc {
char b;
int a;
};
int main(void)
{
struct abc c = {
.a = 1,
.b = 'c',
};
printf("int:%ld byte, char:%ld byte, abc:%ld byte\n",
sizeof(int), sizeof(char), sizeof(struct abc));
return 0;
}
#程序运⾏结果
int:4 byte, char:1 byte, abc:8 byte
可以看到,组合成新的结构体类型后,整体的内存变⼤了,不仅仅是简单的叠加。原因也很简单,就是想要充分利⽤CPU,提升性能。在32位的cpu中,每次读取的数据是4byte对⻬访问,字节未对⻬时,对于成员变量a来说,需要读取两次才能拼凑成a的值;⽽对⻬后,只需要⼀个机器周期就可以读取出来。
这也是典型通过空间换效率的例⼦。
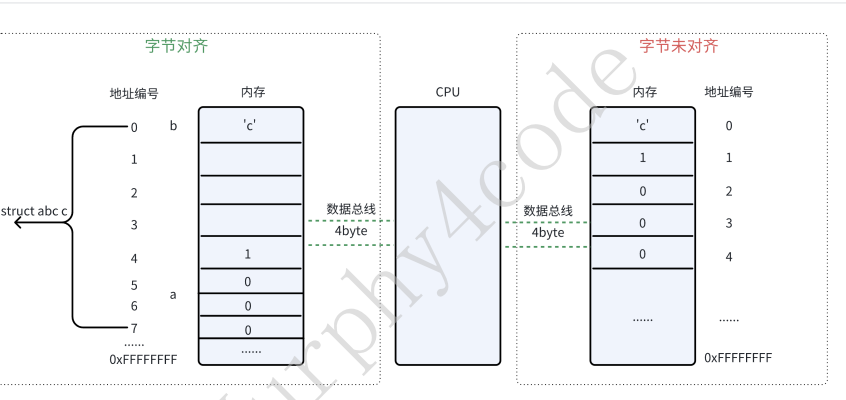
PS:
Tips1:在定义结构体变量时,编译器默认会把⾸地址对⻬到4字节(跟具体体系结构有关,也可能是2
个字节对⻬)的倍数:⾸地址对⻬
Tips2:边界对⻬
1、部分CPU硬件⽀持⾮对⻬访问,典型的就是X86,X86硬件会⾃动处理⾮对⻬访问情况,对软件透
明,代价是牺牲效率(纯硬件做的数据拼接)
2、部分CPU“部分⽀持”⾮对⻬访问,典型的就是ARM,其“单指令”操作⽀持⾮对⻬,但“群指令”操作(SIMD)则不⽀持(必须对⻬访问)
3、部分CPU硬件不⽀持对⻬访问,但通过软件⽀持。典型的就是部分mips架构,其通过内核中对alignment fault异常处理流程中进⾏处理,⽐如将⾮对⻬的数据访问,通过多次访存操作和拼接操作来处理,也可以使⽤类似memcpy的⽅式来处理,当然代价是更严重的性能损失。
#include <stdio.h>
struct abc1 {
char b;
int a;
short c;
};
struct abc2 {
char b;
short c;
int a;
};
int main(void) {
printf("abc1:%ld byte, abc2:%ld byte\n", sizeof(struct abc1), sizeof(struct abc2));
return 0;
}
C 语言中结构体的内存布局会遵循 “内存对齐” 规则,目的是让 CPU 更高效地访问内存(因为 CPU 读取内存时通常按 “字长” 对齐,如 32 位系统字长是 4 字节,64 位是 8 字节)。对齐规则可总结为:
结构体中每个成员的偏移量(相对于结构体起始地址的位置)必须是其自身大小的整数倍。
整个结构体的总大小必须是其所有成员中最大对齐数的整数倍。
分别分析abc1和abc2的内存布局
我们以 32 位系统(int占 4 字节,short占 2 字节,char占 1 字节) 为例分析:
- 分析struct abc1
成员顺序:char b → int a → short c
char b:大小 1 字节,偏移量 0(0 是 1 的整数倍),占据空间[0, 0]。
int a:大小 4 字节,要求偏移量是 4 的整数倍。当前偏移量是 1,需要填充 3 字节(偏移量变为 4),占据空间[4, 7]。
short c:大小 2 字节,要求偏移量是 2 的整数倍。当前偏移量是 8(8 是 2 的整数倍),占据空间[8, 9]。
总大小:最大成员对齐数是 4(int的对齐数),总大小需要是 4 的整数倍。当前总大小是 10,填充 2 字节后变为 12。- 分析struct abc2
成员顺序:char b → short c → int a
char b:大小 1 字节,偏移量 0,占据空间[0, 0]。
short c:大小 2 字节,要求偏移量是 2 的整数倍。当前偏移量是 1,填充 1 字节(偏移量变为 2),占据空间[2, 3]。
int a:大小 4 字节,要求偏移量是 4 的整数倍。当前偏移量是 4(4 是 4 的整数倍),占据空间[4, 7]。
总大小:最大成员对齐数是 4,总大小 8 是 4 的整数倍,无需额外填充。
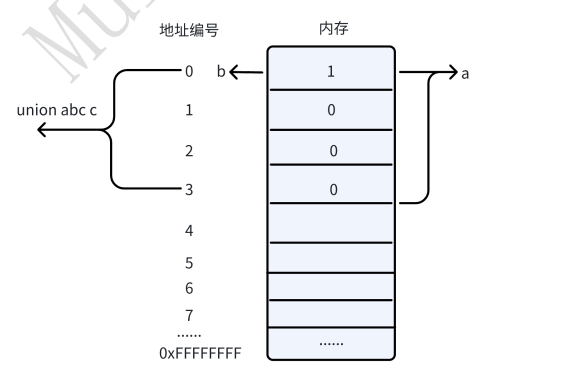
2.2.2 union
union关键字表⽰新的类型叫联合体,内存表现为:共享⼀份内存(以最⼤数据类型作为分配空间)和内存的⾸地址。声明的规则如下:
#include <stdio.h>
union abc {
int a;
char b;
};
int main(void)
{
union abc c = {
.a = 1,
};
printf("a = %d b = %d \n",c.a, c.b);
c.b = 100;
printf("a = %d b = %d \n",c.a, c.b);
return 0;
}
#程序运⾏结果
a = 1 b = 1
a = 100 b = 100
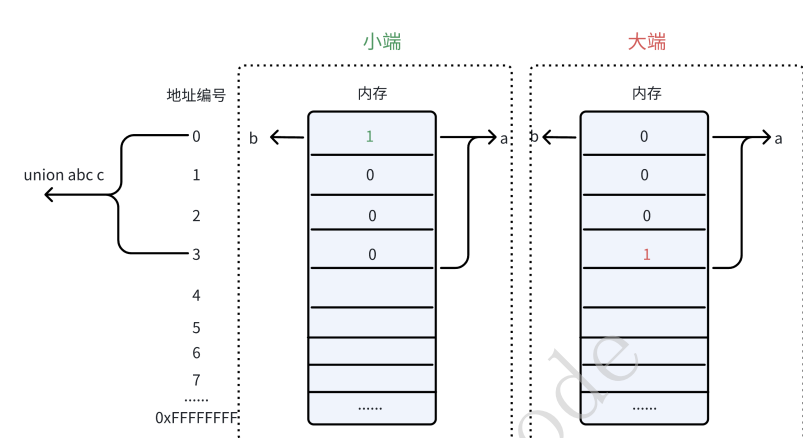
PS:⼤⼩端是计算器存储数据的⼀个规则,⼩端是低地址存放低位,⾼地址存放⾼位;⼤端则相反。
⼀般像x86、arm都是⼩端,51单⽚机是⼤端。两种存储⽅式都是对的,可以通过联合体来判断⼤⼩端情况。
联合体+结构体设计数据包
在uart、usb、2.4G等等常⻅的数据包传输,会⽤到联合体+结构体的设计,这样的设计拓展性很强,符合开放封闭原则:拓展是开放的,修改是封闭的。可以体会⼀下下⾯这个例⼦:
#include <stdio.h>
struct abc {
int a;
short b;
long c;
} __attribute__((packed));//忽略默认的对齐规则,让结构体成员按 “实际大小” 连续存储,不插入任何填充。
//拓展的数据结构
struct efg {
char e;
float f;
int g;
} __attribute__((packed));
#pragma anon_unions
struct package {
unsigned char id;
union {
unsigned char payload[24];
struct abc a;
//拓展的数据结构
struct efg b;
};
};
void send_package(void* data, int len)
{
struct package *p = (struct package *)data;
uart_send(p->id);
for (int i = 0; i < len; i++) {
uart_send(p->payload[i]);
}
}
2.2.3 enum
enum关键字表⽰的类型叫枚举类型,内存表现为:内存根据定义值的⼤⼩默认选择整数常量⼤⼩(int),如果超出int⼤⼩,编译器会选择更⼤的整型类型,⽐如long,所以内存⼤⼩不是固定的。
#include <stdio.h>
enum abc {
A = 0,
B = 1,
C = 3,
D
};
enum efg {
E = 0x123456789,
F,
G
};
int main(void)
{
printf("a = %d, b = %d, c = %d, d = %d\n",A, B, C, D);
printf("size of a = %ld, abc = %ld\n",sizeof(A), sizeof(enum abc));
printf("size of E = %ld, abc = %ld\n",sizeof(E), sizeof(enum efg));
return 0;
}
#程序运⾏结果
a = 0, b = 1, c = 3, d = 4
size of a = 4, abc = 4 //int
size of E = 8, efg = 8 //long int
enum和宏的差别
#define A 0
#define B 1
#define C 3
#define D 4
enum abc {
A = 0,
B = 1,
C = 3,
D
};
在C语⾔中,对于上⾯这段代码使⽤上⼏乎等价。
2.3 地址(指针)类型
C语⾔中,地址类型也称指针类型,圈定的内存⽤来存放地址编号的值。指针类型的内存表现跟编译器有关或者说跟CPU的地址总线有关。在32位的系统中,指针类型占⽤4byte,在64位的系统中,指针类型占⽤8byte
#include <stdio.h>
int main(void)
{
int a = 10;
int *p = &a;
printf("symbol visit:a = %d, addr visit:a = %d\n", a, *p);
return 0;
}
#程序运⾏结果
symbol visit:a = 10, addr visit:a = 10
1、⾸先,p也是⼀个变量(没啥神秘的),这本质上也是圈定⼀块内存,内存的⼤⼩跟编译器有关,p
是这块内存的标签。到这⾥p和a的在变量的视⻆中⼀摸⼀样
2、然后,p的特殊性在于,它圈定的那块内存,存放的不是⼀般的值⽽是⼀个地址编号。所以除了通过
标签p读出这个地址编号外,C语⾔还提供⼀种直接访问这个地址编号的⽅法,那就是在p前⾯加⼀个*
号。
指针类型的内存⼤⼩跟数据类型没有关系
#include <stdio.h>
struct abc {
int a;
int b;
float c;
};
int main(void)
{
char *p1;
int *p2 ;
struct abc *p3;
printf("size of p1:%ld, p2:%ld, p3:%ld\n", sizeof(p1), sizeof(p2),
sizeof(p3));
return 0;
}
#程序运⾏结果
size of p1:8, p2:8, p3:8
2.4 typedef
typedef关键字是给数据类型起⼀个别名,让程序的可读性更⾼,特别是复杂的类型(如函数指针类型),做到⻅字知意。使⽤的规则:
typedef 数据类型 别名
#include <stdio.h>
typedef struct abc {
int a;
int b;
float c;
} abc_t;
typedef int len_t;
typedef unsigned char uint8_t;
typedef void (func*)(void);
func p;
int main(void)
{
len_t a = 0;
uint8_t b;
abc_t c;
return 0;
}
PS:
#define 和 typedef 是 C 语言中两种完全不同的工具:#define 是预处理阶段的文本替换,typedef 是编译阶段的类型重命名.
例子 1:定义 “整数类型别名
#include <stdio.h>
#define INT_PTR int* // 宏定义:文本替换,INT_PTR 替换为 int*
int main() {
INT_PTR a, b; // 预处理后变成:int* a, b;
// 注意:b 实际是 int 类型(不是 int*),因为 * 只绑定到 a
a = NULL;
b = 10; // 编译不报错(b 是 int)
printf("a的类型:%s,b的类型:%s\n",
typeof(a) == int* ? "int*" : "int", // a 是 int*
typeof(b) == int* ? "int*" : "int"); // b 是 int
return 0;
}
结果:a 是 int*,b 是 int(宏替换仅做文本替换,导致 b 类型不符合预期)。
用 typedef 实现:
#include <stdio.h>
typedef int* INT_PTR; // 类型重命名:INT_PTR 是 int* 的别名
int main() {
INT_PTR a, b; // 等价于 int* a, int* b;(a和b都是 int* 类型)
a = NULL;
b = NULL; // 正确:b 是指针类型
// b = 10; // 编译报错(不能给指针赋整数)
printf("a的类型:%s,b的类型:%s\n",
typeof(a) == int* ? "int*" : "int", // a 是 int*
typeof(b) == int* ? "int*" : "int"); // b 是 int*
return 0;
}
结果:a 和 b 都是 int* 类型(typedef 是真正的类型别名,作用于整个变量声明)。
例子 2:定义 “结构体类型”
用 #define 实现:
#include <stdio.h>
#define STU struct Student // 宏替换:STU 替换为 struct Student
struct Student {
int id;
};
int main() {
STU s; // 预处理后:struct Student s;(可行)
// 但 #define 无法解决 "struct Student" 重复书写的问题
// 且宏没有类型语义,编译器只做文本替换
return 0;
}
用 typedef 实现:
#include <stdio.h>
typedef struct Student { // 给 struct Student 起别名 Stu
int id;
} Stu;
int main() {
Stu s; // 直接用别名声明变量,无需写 struct Student
s.id = 1; // 正确:Stu 是明确的类型
return 0;
}
3.修饰关键字
3.1 auto
auto关键字是最⽆感的存在。编译器在默认缺省的情况下,所有变量都是auto的。你就当做它不存在,不曾来过。
3.2 register
register关键字是⼀个建议性关键字。设计的初衷是想要定义的变量放到cpu的寄存器中,但是往往编译器看到这个关键字的时候,发出⼀句呐喊:⾂妾做不到啊。寄存器相对于内存,cpu在访问速度上更快,但也很稀缺,不是说想放就放的。所以编译器只能尽量的去做,它不保证⼀定能做得到,⼤家也就不要奢望了。但值得注意的是加上register修饰后的变量,⽆法通过&来取地址。即使⼤概率放进寄存器会失败,但编译器就不给你寻址,万⼀成功了呢?编译器还是有梦想的。
3.3 static
在C语⾔中static关键字有两个作⽤:1、变量的内存从静态全局数据区分配;2、限定变量或函数的作⽤域。
1.对于变量
⽣命周期:不管是修饰局部变量还是全局变量,最后都在静态全局数据区分配。这意味着变量在整个程序的⽣命周期内都是有效合法的。
#include <stdio.h>
static int a = 20;
int func(void)
{
static int b = 10;
return ++b;
}
int main(void)
{
printf("a = %d , b = %d ,b = %d \n", a, func(), func());
return 0;
}
#程序运⾏结果
a = 20 , b = 12 ,b = 11
限定范围:限定全局变量只在当前定义的⽂件可⻅,其他⽂件即使加上extern修饰,也⽆法引⽤。
会编译报错
//1.c
#include <stdio.h>
static int a = 20;
int main(void)
{
printf("a = %d\n", a);
return 0;
}
//2.c
extern int a;
int func(void)
{
return ++a;
}
#程序运⾏结果
/usr/bin/ld: 2.o: in function `func':
2.c:(.text+0xa): undefined reference to `a'
/usr/bin/ld: 2.c:(.text+0x13): undefined reference to `a'
/usr/bin/ld: 2.c:(.text+0x19): undefined reference to `a'
collect2: error: ld returned 1 exit status
2.对于函数
限定范围:限定函数在当前定义的⽂件可⻅,其他⽂件不可引⽤,但可以实现相同名字的函数(也需
要⽤static修饰),互不影响。感受⼀下下⾯这个例⼦:
//1.c
#include <stdio.h>
static int a = 20;
static int func(void)
{
return ++a;
}
int main(void)
{
printf("a = %d\n", func());
return 0;
}
//2.c
static int a = 10;
static int func(void)
{
return ++a;
}
#程序运⾏结果
a = 21
3.4 extern
extern⽤来声明⼀个没有被static修饰的变量或者函数
//1.c
#include <stdio.h>
extern int func(void);
int main(void)
{
func();
return 0;
}
//2.c
#include <stdio.h>
int func(void)
{
printf("func call \n");
}
#程序运⾏结果
func call
在架构设计中尽量不要⽤extern,会导致代码耦合度⾮常⾼⽽且不太可控。用.c .h就不错
PS:
extern “C”,⽤C++的编译器(g++)按照C的规则进⾏编译。C++和C语⾔在编译规则上有很多不
同,所以在C++中想完全复⽤C写的代码,就可以⽤extern "C"来修饰。这种在C++使⽤C的lib库的
时候⽐较常⻅。
3.5 const
const是constant的缩写,是恒定不变的意思,被修饰的变量经常被⼈误解成常数或者常量。这个
理解不太准确,准确的理解应该是readonly。本质上还是变量,编译器只能尽量的不让你去修改,但
是实际上总有⼀些⽅法可以做到修改const修饰变量的值,往往都是⼀些异常的操作导致(⽐如数组越
界、指针越界访问、栈溢出等等)。我们要建⽴⼀个正确的编程理念:const修饰的变量技术上能改,
但是不要去改。
const 数据类型 变量名 or 数据类型 const 变量名
#include <stdio.h>
int main(void)
{
const int a = 10;
int const b = 20;
//a = 20;//编译错误,编译不给修改
printf("a = %d, b = %d\n", a, b);
return 0;
}
修改const修饰的变量
#include <stdio.h>
int main(void)
{
int a = 1234568;
const int b = 11111111;
int *p = &a;
p[1] = 22222222;
printf("b = %d \n", b);
return 0;
}
const 修饰指针
很多同学对const修饰指针变量,有时候分不清楚是修饰指针变量还是限定指针指向的内容。今天
教⼤家⼀个⽅法,叫"近⽔楼台先得⽉"
#include <stdio.h>
const int * a; //-> const * a ->靠近 *,所以 地址指向的内容(*a)不能变
int const * b; //-> const * b ->靠近 *,所以 地址指向的内容(*d)不能变
int * const c; //-> * const c ->靠近 c,所以 c指针变量不能变
const int * const d; //-> const * const d ->靠近 * ⼜靠近c,所以d和*d都不能变
int main(void)
{
//下⾯5个语句编译器会报错拦截
*a = 1;
*b = 1;
c = 1;
*d = 1;
d = 1;
return 0;
}
//编译器报错
1.c: In function ‘main’:
1.c:11:8: error: assignment of read-only location ‘*a’
11 | *a = 1;
| ^
1.c:12:8: error: assignment of read-only location ‘*b’
12 | *b = 1;
| ^
1.c:13:7: error: assignment of read-only variable ‘c’
13 | c = 1;
| ^
1.c:14:8: error: assignment of read-only location ‘*d’
14 | *d = 1;
| ^
1.c:15:7: error: assignment of read-only variable ‘d’
15 | d = 1;
| ^
^
使⽤const可以提⾼运⾏效率:如果⽤const修饰,编译器会直接把⽴即数200赋值给变量a,⽽没有
const修饰的则每次都需要读取内存中ABC值。这样⽤const修饰时,执⾏效率就⽐较⾼(我们知道
读取内存是相对慢的操作)。
#include <stdio.h>
const int ABC = 200;
int main(void)
{
int a = ABC;
return 0;
}
//int a = ABC;
movl ABC(%rip), %eax //把内存中ABC的值读到寄存器中去
movl %eax, -4(%rbp)
//const int a = ABC;
movl $200, -4(%rbp)
const和宏的区别
const设计的初衷就是为了代替宏,消除它的缺点,继承它的优点。
- 编译器处理⽅式:define宏是在预处理阶段展开;const变量是编译运⾏阶段使⽤
- 安全检查:define宏不做任何类型检查,仅仅是展开;const变量编译阶段会执⾏类型检查
- 内存位置:define宏在代码段;const常量可以在静态全局数据段、栈中
3.6 volatile
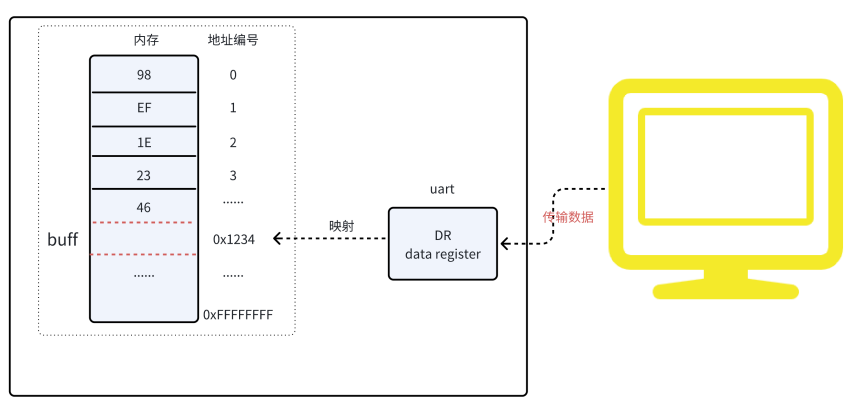
volatile关键字⽤于告诉编译器,被声明为volatile的变量的值可能在程序的控制之外发⽣变化,因此编译器不应该对其进⾏某些优化。主要⽤于处理硬件寄存器、中断服务程序和多线程等情况:下⾯如果buff变量是uart的DR寄存器映射,即使代码中没有地⽅更新buff的值,也应该告诉编译器不要优化,如果有地⽅读取buff的值的时候,都需要从内存中读取,因为外部uart会触发更新。
#include <stdio.h>
volatile unsigned char buff;
int main(void)
{
while (buff) {//等待buff不为0
//do something
}
return 0;
}
体会⼀下下⾯这个例⼦
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
static volatile int wait = 1;
void* function(void* arg)
{
while (1) {
sleep(1);
wait = 0;
printf("flag wait = %d in thread \n", wait);
}
return NULL;
}
int main(void)
{
pthread_t tid;
pthread_create(&tid, NULL, function, NULL);
while(wait);
printf("flag wait = %d in main \n", wait);
return 0;
}
- 不加volatile时(编译器会优化,导致程序卡死)
编译器优化逻辑:
编译器分析main函数中的while(wait);时,发现main函数内没有显式修改wait的代码,会默认认为wait的值是 “稳定的”,于是将wait的值缓存到 CPU 寄存器中(不再每次从内存读取)。
汇编代码体现:
对应汇编逻辑(参考问题中的代码):
asm
movl wait(%rip), %eax ; 第一次从内存读取wait到寄存器%eax
testl %eax, %eax ; 检查%eax是否为0
je .L6 ; 若为0,跳转到.L6(退出循环)
.L7:
jmp .L7 ; 若不为0,无限跳转到.L7(死循环)
此时,即使子线程在内存中把wait改为0,main函数的循环仍在读取寄存器中缓存的旧值(1),导致循环永远不会退出,程序卡死。
- 加volatile时(禁止编译器优化,程序正常退出)
编译器行为变化:
volatile强制编译器每次读取wait时都从内存中重新读取,不能使用寄存器缓存。
汇编代码体现:
对应汇编逻辑(参考问题中的代码):
asm
.L6:
movl wait(%rip), %eax ; 每次循环都从内存读取wait到%eax
testl %eax, %eax ; 检查%eax是否为0
jne .L6 ; 若不为0,跳转到.L6继续循环
; 若为0,退出循环
当子线程将内存中的wait改为0后,main函数的下一次循环会从内存中读取到新值0,循环退出,程序正常执行后续的printf并结束。
4.逻辑关键字
在cpu的眼⾥很单纯,程序指针(PC)指到哪⾥就执⾏哪⾥,默认情况下顺序往下执⾏,⽽逻辑关键字作⽤就是改变PC指针的指向,这个最基本的思想就构成了程序⾥各种逻辑设计(条件、选择、跳转、循环)
4.1 条件 if else
4.2 选择 switch case default
4.3 循环 do while for
4.4 跳转 continue break return goto

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)