笔记:ShapeSpeak: Body Shape-Aware Textual Alignment for Visible-Infrared Person Re-Identification
论文来源: 2025 ACM International Conference on Multimedia (CCF-A)
论文链接:文章arxiv链接
研究方向:VI-ReID 红外可见光行人重识别
问题来源:传统 VI-ReID 主要靠身份监督,难以充分学到高层语义。之前引入 CLIP/文本描述的方法,虽然增强了语义信息,但没有显式建模人体形状(body shape)。作者认为body shape天然更跨模态稳定,所以应该单独拎出来建模。
主要贡献:
1. 提出了一种“身体形状文本对齐框架(BSaTa)”,通过显示建模人体形状将其变为文本原型,再冻结生成好的文本描述,用他们监督视觉编码器的学习。
2. 设计了一个体形文本对齐模块,该模块带有跨模态一致性正则化器,可将体形图转换为结构化的文本表示,从而确保生成的文本表示的质量。
3. 引入了一种体形感知表示学习机制,该机制结合了多文本监督和分布一致性约束,以强调体形信息并增强特征表示。
方法:
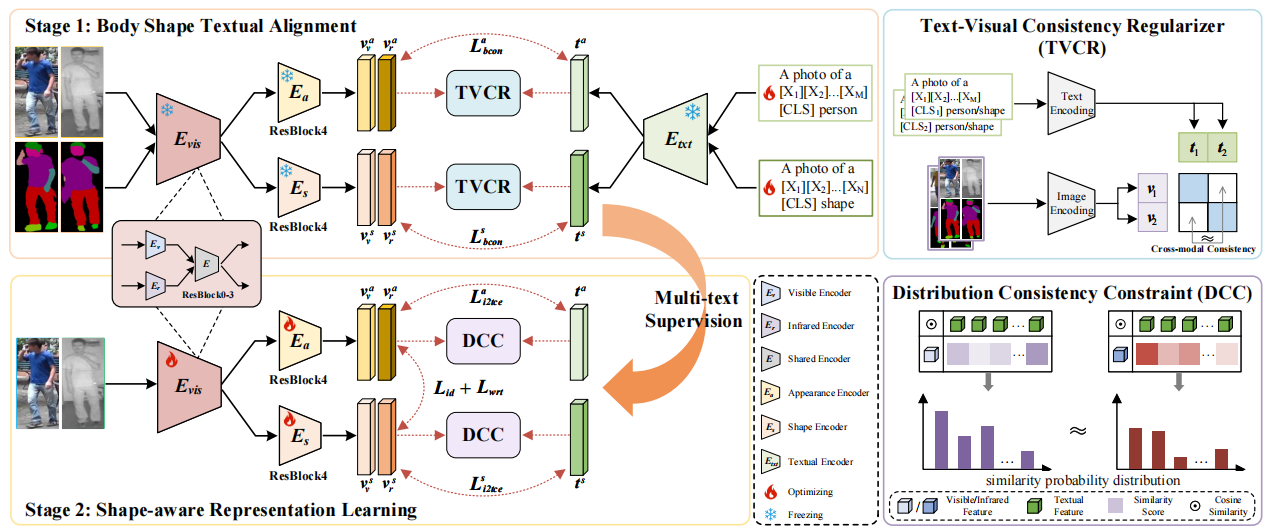
整个框架分为两个阶段,人体形态文本对齐和形态-感知表征学习。
Stage 1:Body Shape Textual Alignment
工作:先从图像中提取 shape 信息,再把它变成文本原型。
具体做法:
1. 用 SCHP human parsing 生成人体 shape map。
2. 用一个额外的 shape encoder 提取 shape visual feature。
3. 然后借助 CLIP 的文本编码器,把 shape feature 对应到一个可学习文本模板上。
A photo of a [X_s1]...[X_sM] [CLS] shape 这里 [X_s] 是可学习 token,[CLS] 实际上对应 identity label。4. 同时,他们还保留了 appearance 文本分支,也就是 appearance 和 shape 两条文本监督都存在。
A photo of a [X_a1]...[X_aN] [CLS] personStage 2:Shape-aware Representation Learning
工作:冻结生成好的文本描述,用它们去监督视觉编码器学习。
具体做法:
1. 用appearance text 和 shape text 一起监督视觉特征。
2. 用DCC模块让可见光和红外图像相对于同一组文本原型的相似度分布尽量一致。
最后推理时,appearance feature + shape feature 直接拼接检索。
关键模块:
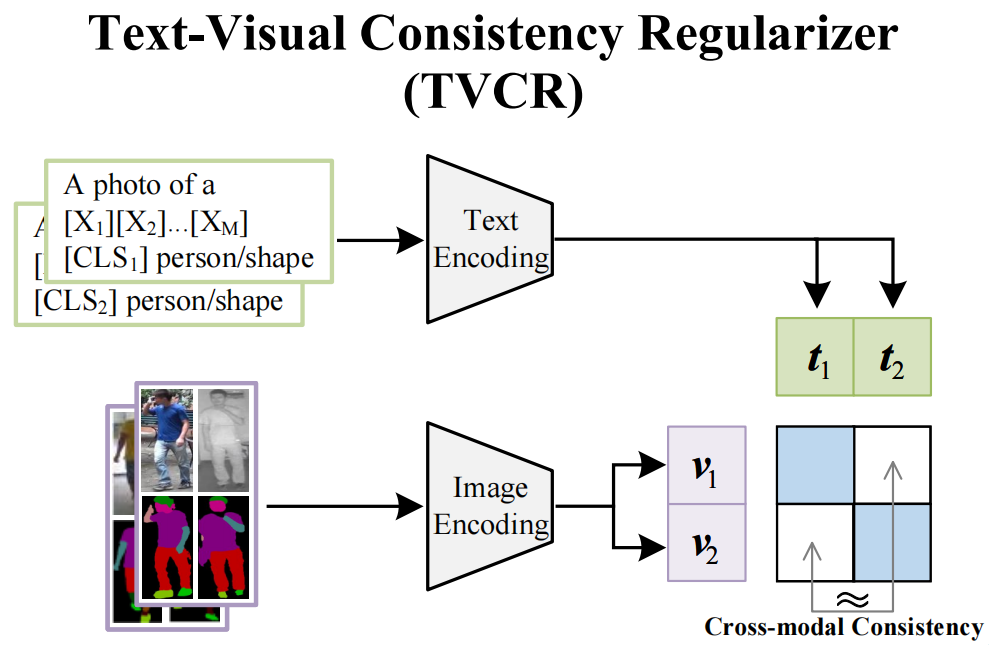
Text-Visual Consistency Regularizer (TVCR)
对于
的矩阵(余弦相似度),分别代表第
个图片对应的特征,理论上来讲,这个矩阵应该是近乎对称的,即
的值应该是基本一致的。这也是TVCR被提出的原因,因为对比学习只能拉近正样本距离
。
最终这个矩阵要达到对称、稳定、一致。这三种状态代表着:交叉关系不失衡,关系不是偶然的,图像端和文本端的语义结构要互相对应。
所以 TVCR 不是在做新的身份监督,而是在做:让学出来的文本 prototype 更像一个可靠原型,而不是一个碰巧能降 loss 的 embedding。
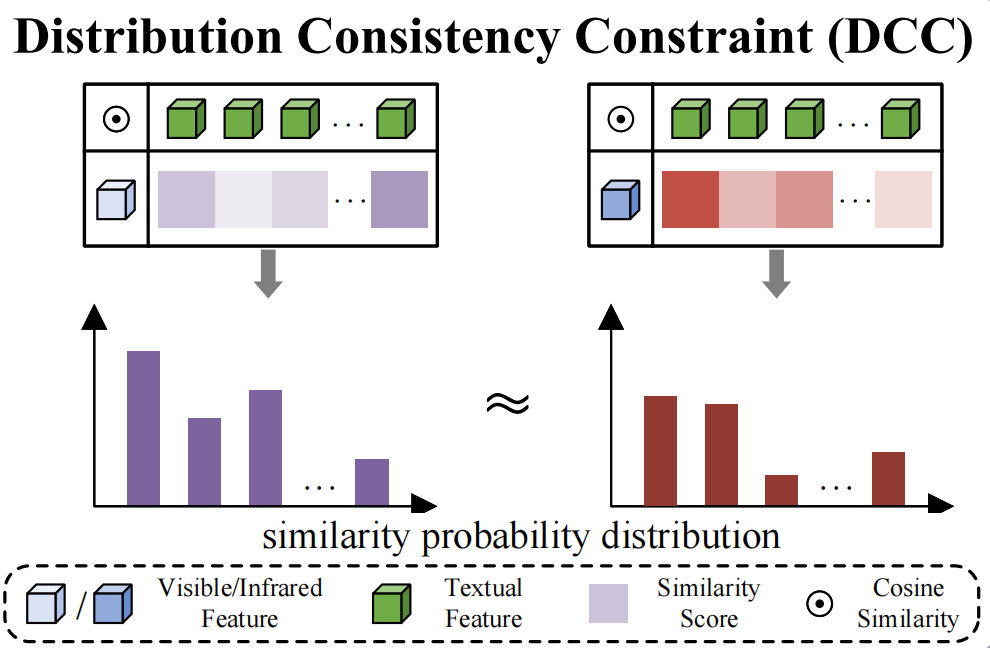
Distribution Consistency Constraint (DCC)
前面的多文本监督做的事情是:每个 visible / infrared 图像特征,都要靠近自己的文本 prototype。但这还不够,因为即便两边都各自靠近了文本原型,也可能出现:visible 特征靠近文本原型的方式是一种几何形状,infrared 特征靠近同一文本原型的方式是另一种几何形状。
所以作者提出DCC,不再只看“某个样本和它自己的原型近不近”,而是看:visible 和 infrared 对所有 identity 文本原型的相似度分布,是否一致。
相对于普通Loss,DCC不仅要求真类得接近,而且对所有类的相对距离模式也要尽量一致。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)