基于STM32CubeMX与X-Cube-AI在开发板STM32F407VG上部署MNIST手写数字识别模型,并使用串口发送28*28hex格式数值来进行手写数字识别任务
·
一、环境准备
1.硬件准备
STM32F407VG开发板。
USB转串口模块或数据线(用于调试输出)。
2.软件准备
STM32CubeMX软件。
X-Cube-AI扩展包(下载方式后面有教程)。
IDE:Keil MDK、STM32CubeIDE(本文以Keil为例)。
模型训练框架:PyTorch、TensorFlow或Keras(以ONNX或TFLite格式导出模型)。(本文使用pytorch训练模型,保存模型后将模型转为ONNX格式)
二、 STM32CubeMX软件安装教程
STM32+CubeMX教程——CubeMX 安装图解_stm32cubemx-CSDN博客,该博客很详细,推荐观看。
三、STM32CUBE_AI安装教程
- 安装好STM32_CUBEMX,打开该软件
- 点击install
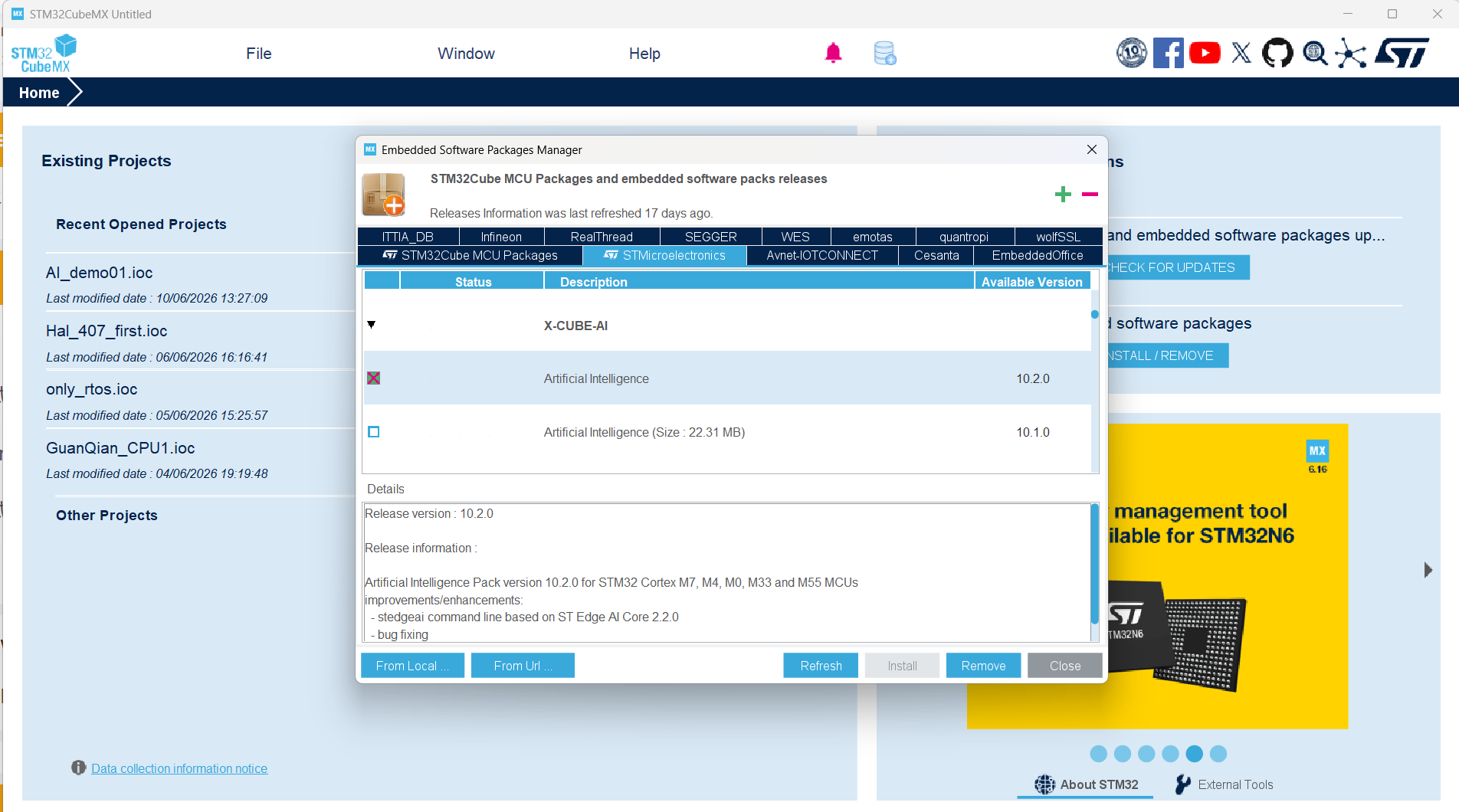
- 按照下图所示选择对应的版本下载。我这边install按钮因为包已经下好了,所以是灰色。正常没有下载的话,选中版本后再点击install开始下载,直到下载完成。
四、创建项目
- 点击ACCESS TO MCCU SELECTOR
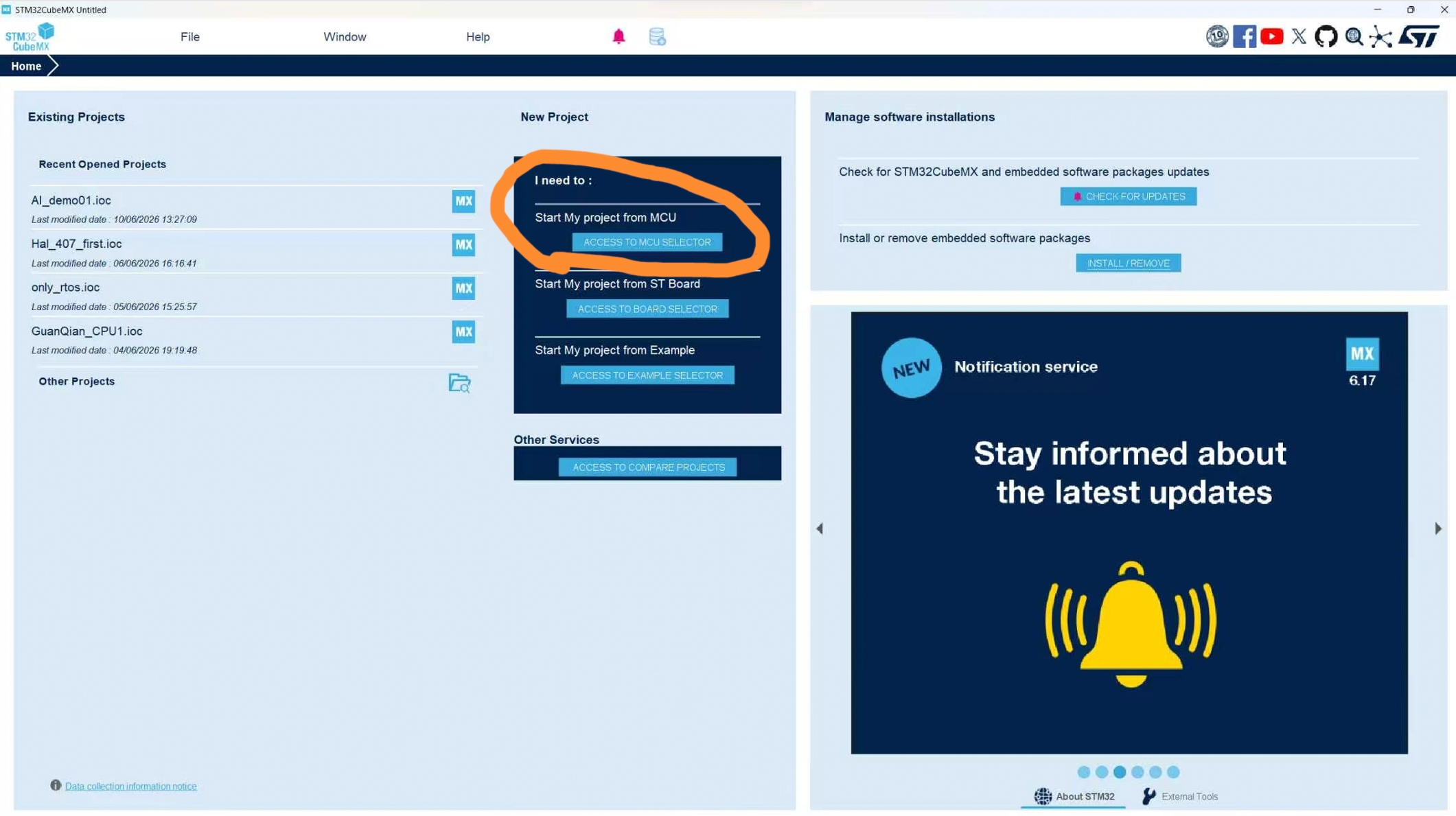
- 选择芯片,根据自己所使用的芯片选择,我使用的是STM32F407VG6芯片,在输入框输入芯片类型进行搜索,点击右下方第一个芯片类型,再点击右上方的Start Projectk即可创建项目。
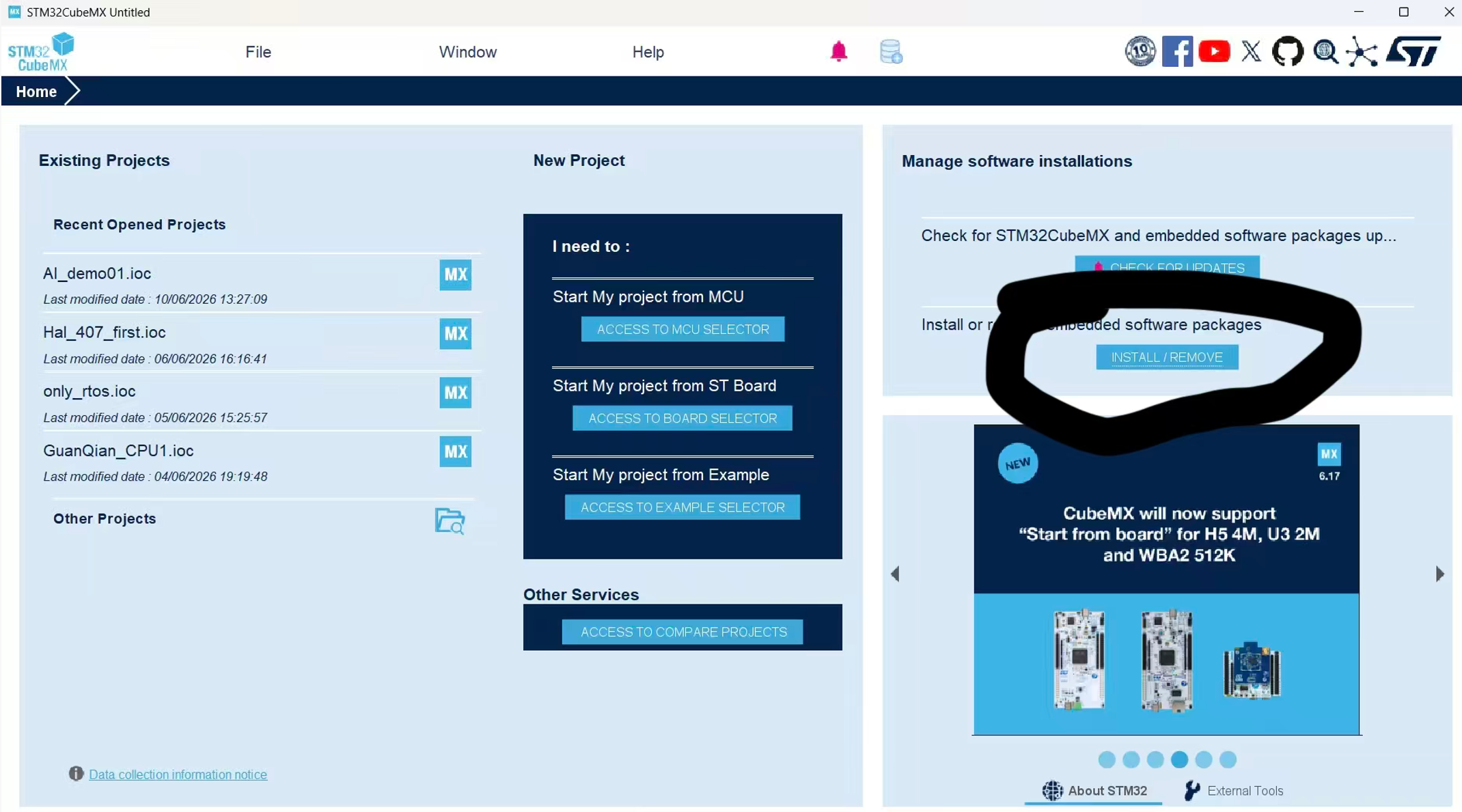
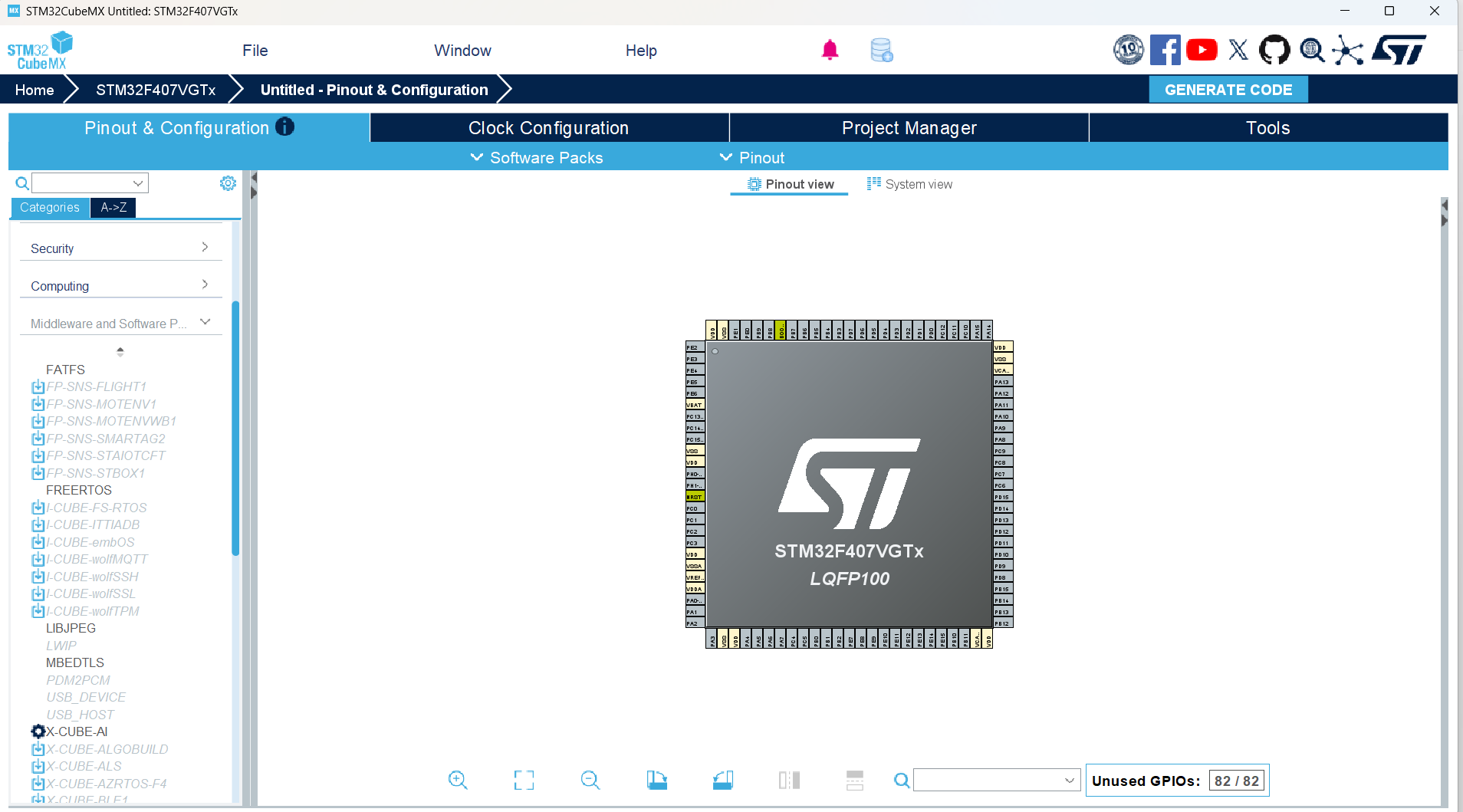
- 项目创建完成后,找到X-CUBE-AI选项,点击它。
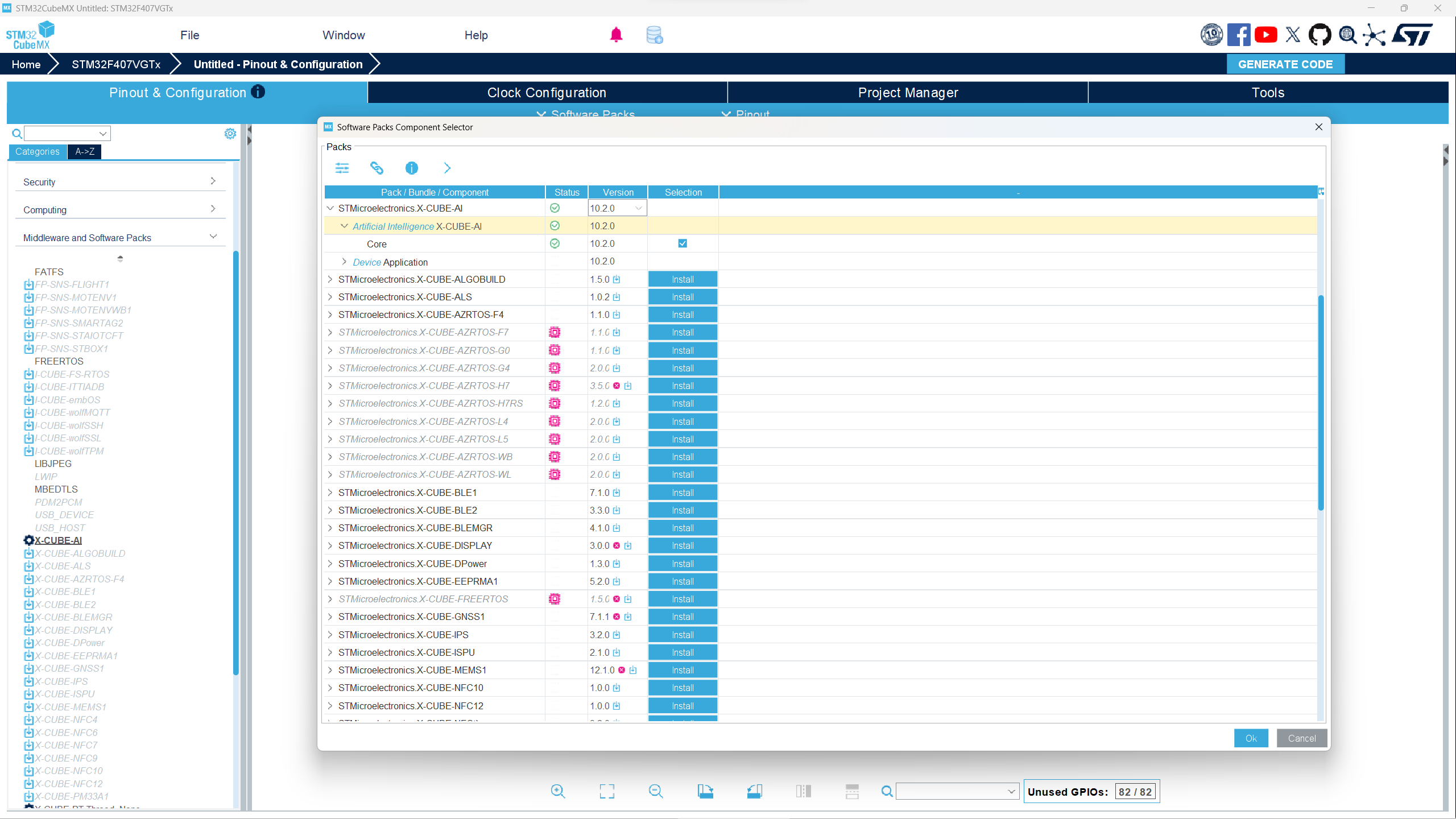
- 点击后,会出现之前下载好的组件,将这个X-CUBE-AI组件的Core选中(打钩),加入到项目中,点击OK。
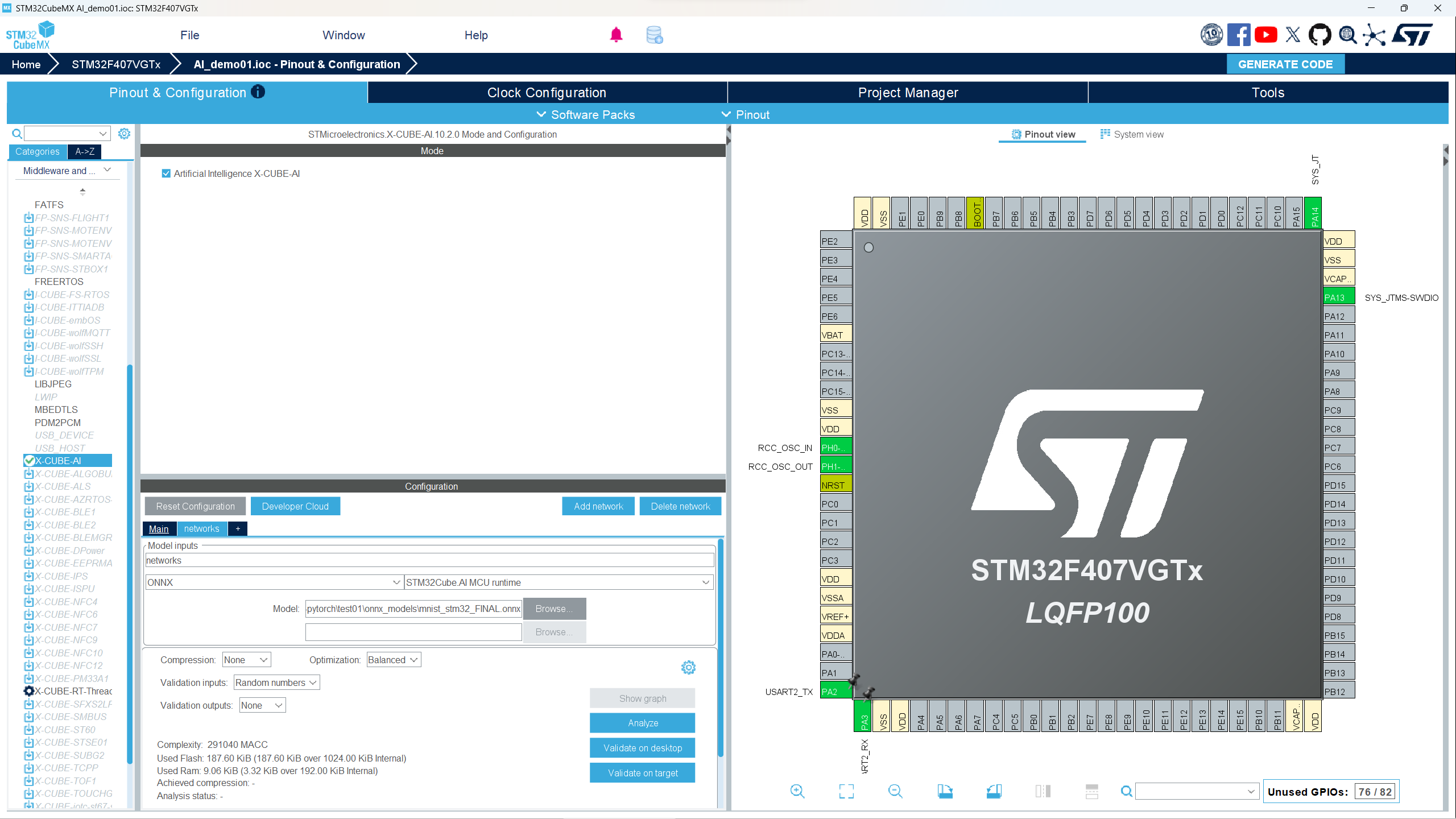
- 然后进行一些AI模型引入项目的配置,我自己使用的是手写数字识别模型,模型简单,配置如下。模型是用pytorch训练,所以加入模型之前需要将保存的模型转为ONNX类型文件,这部分工作可以在模型训练保存后直接转换。我们只需要将ONNX模型文件导入该项目中即可。
- 引入模型后,点击Analyzing Network,会对引入的模型进行分析,如果不报错代表没问题,点击OK。
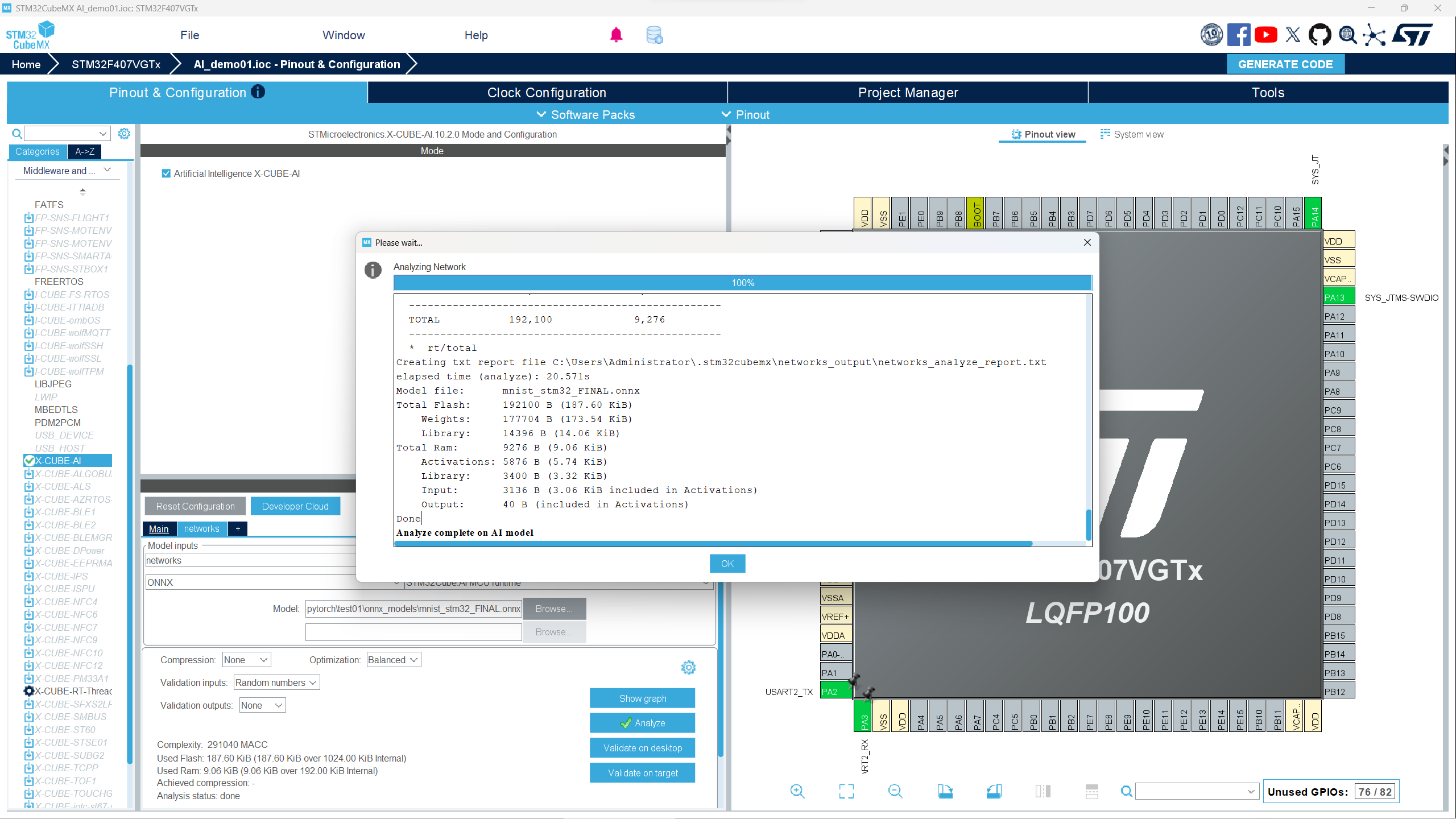
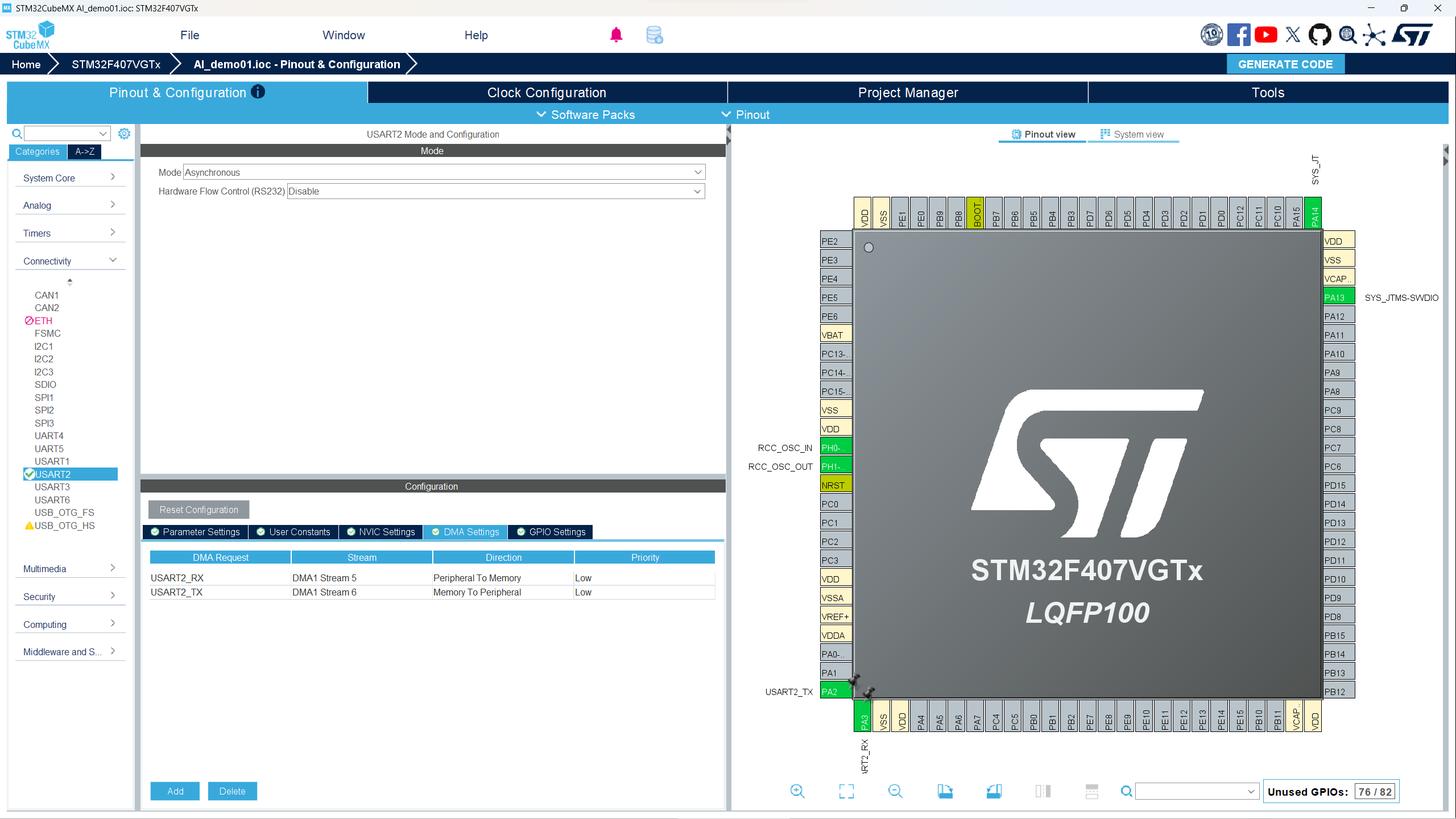
- 因为我们需要使用串口,所以进行串口配置。点击Connectivity,找到USART2进行配置,我选用的是PA2和PA3引脚,如果引脚不同,可以换其他的,类似配置如下图。
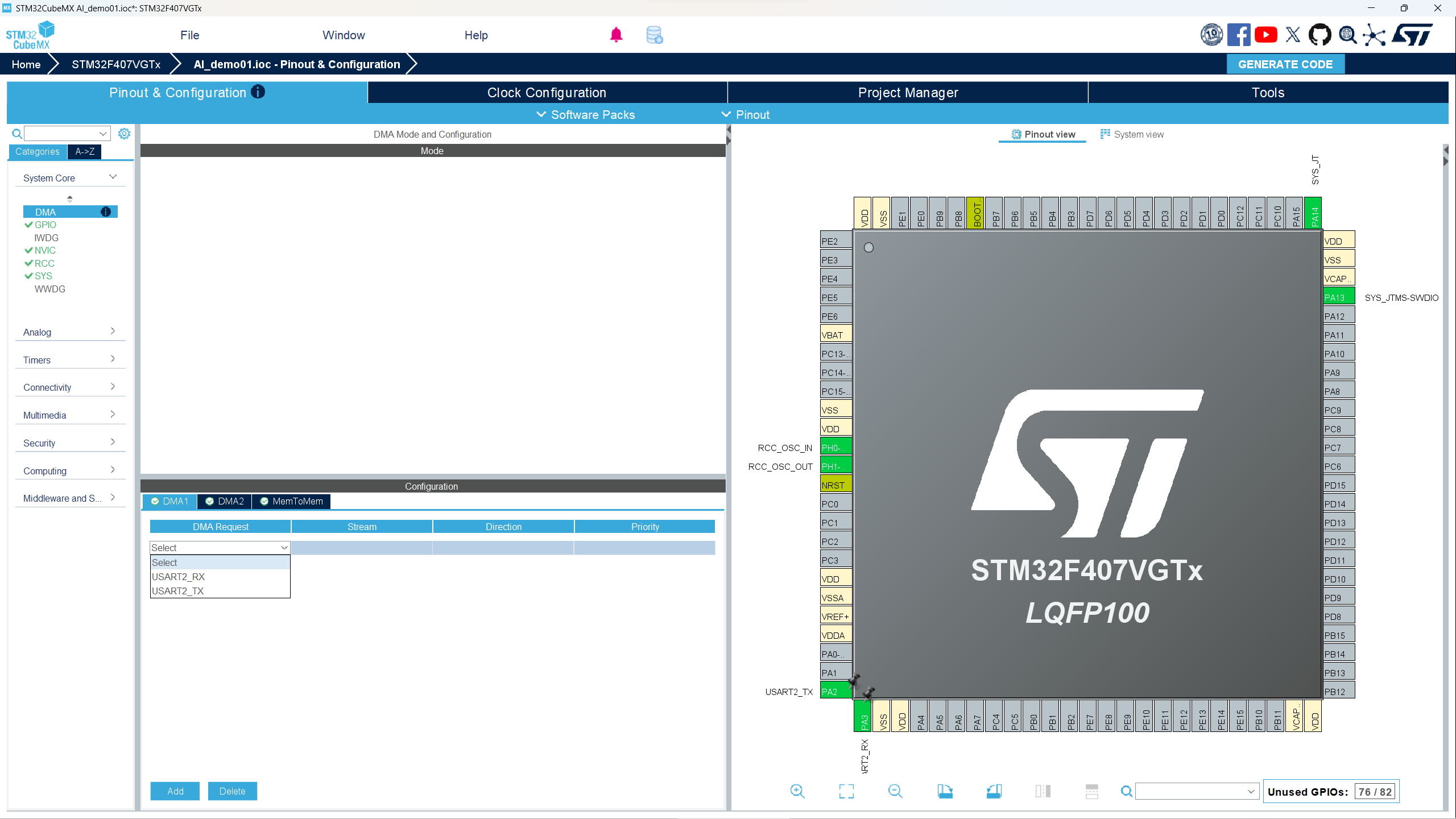
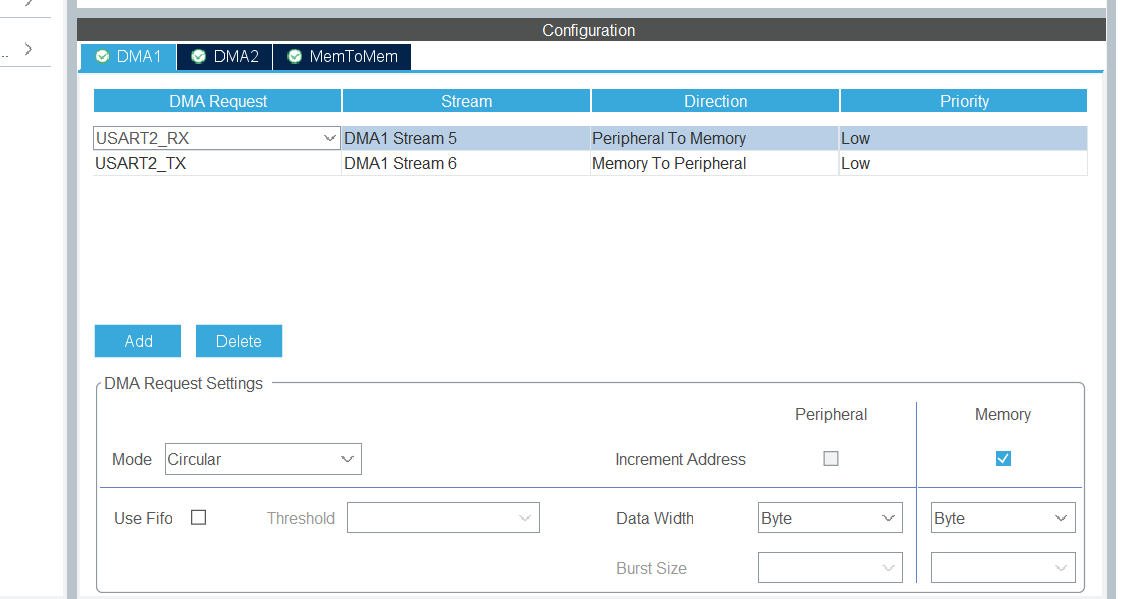
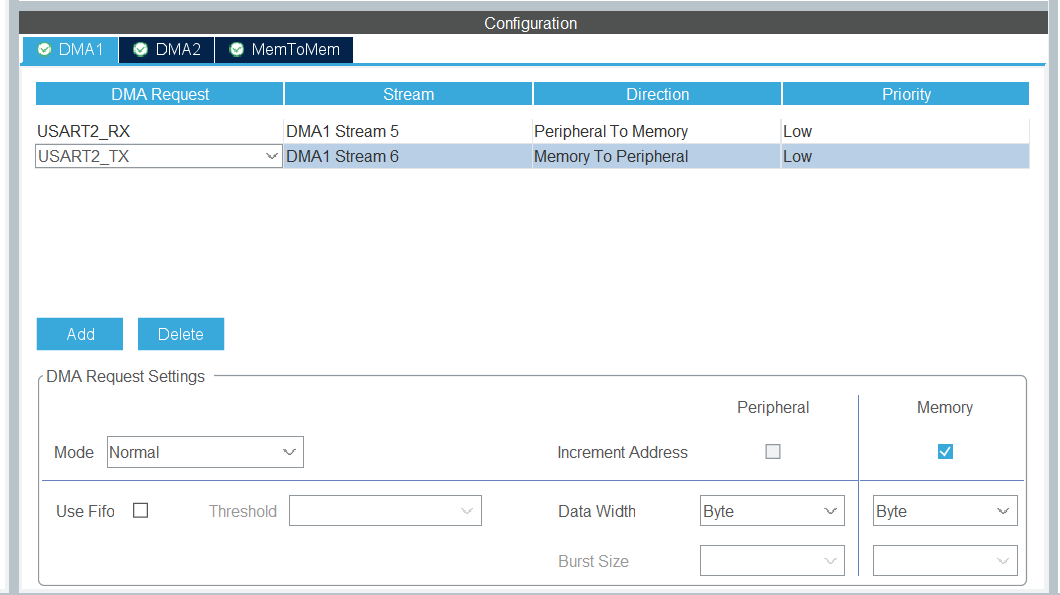
- 在点击System Core,进入其他配置,项目中我使用了DMA来接受电脑发过来的数据和给电脑发送模型识别的结果以及耗费的时间。点击DMA来配置,配置如图所示。mode的配置不同。
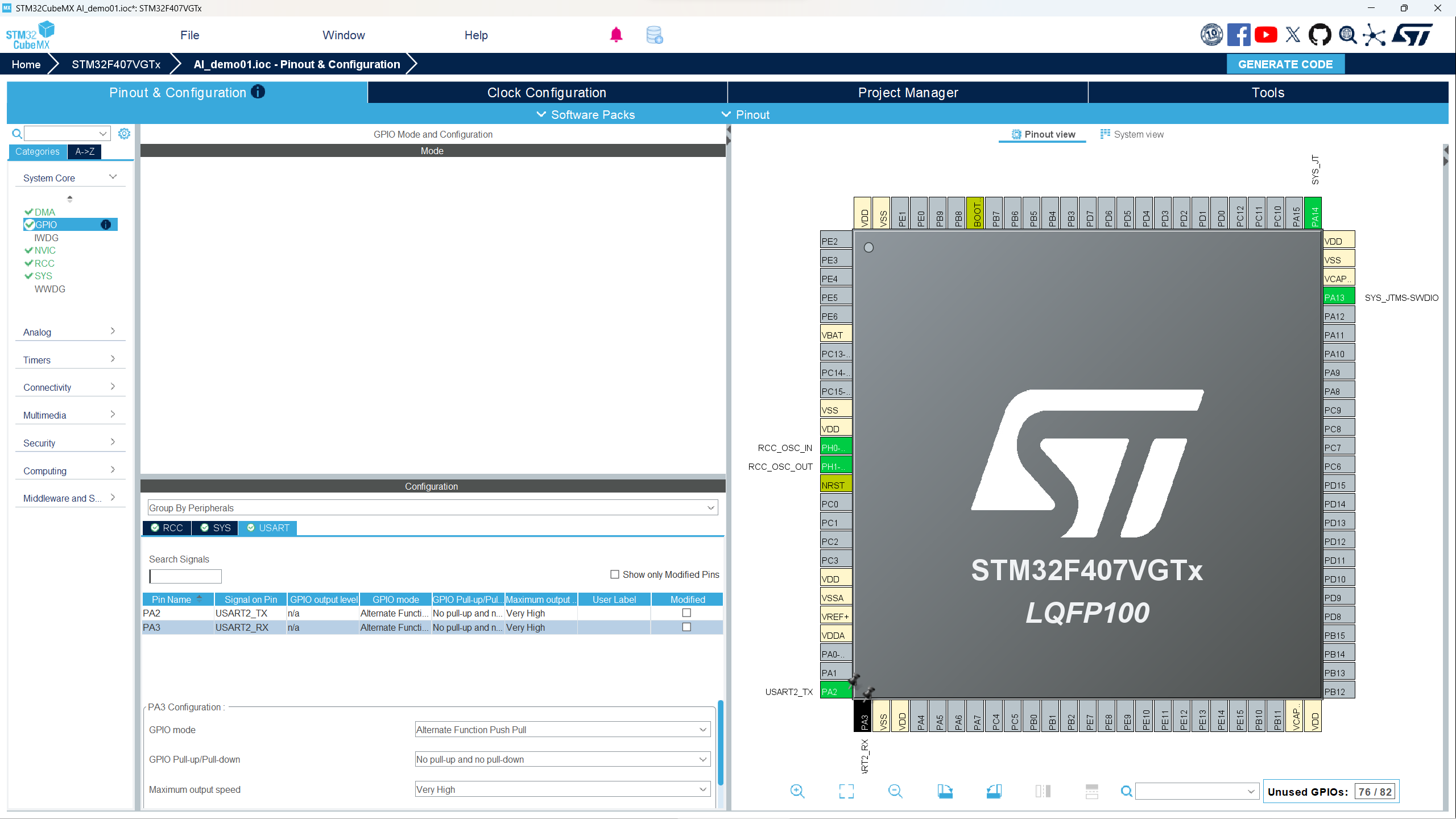
- 点击GPIO,查看USART配置是否正常。如图所示:
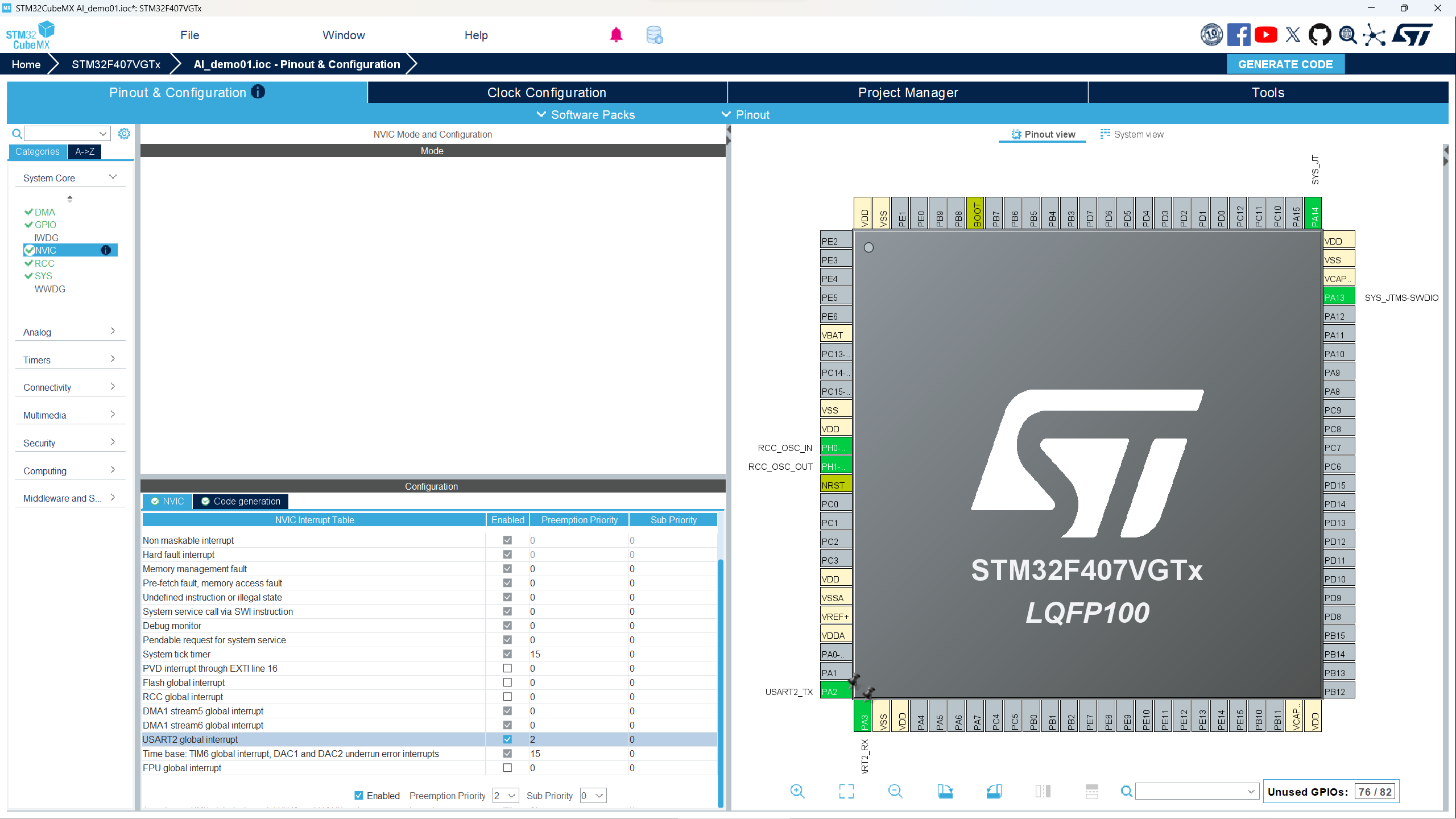
- 点击NVIC,查看串口中断是否勾选,并且优先级设置为2。
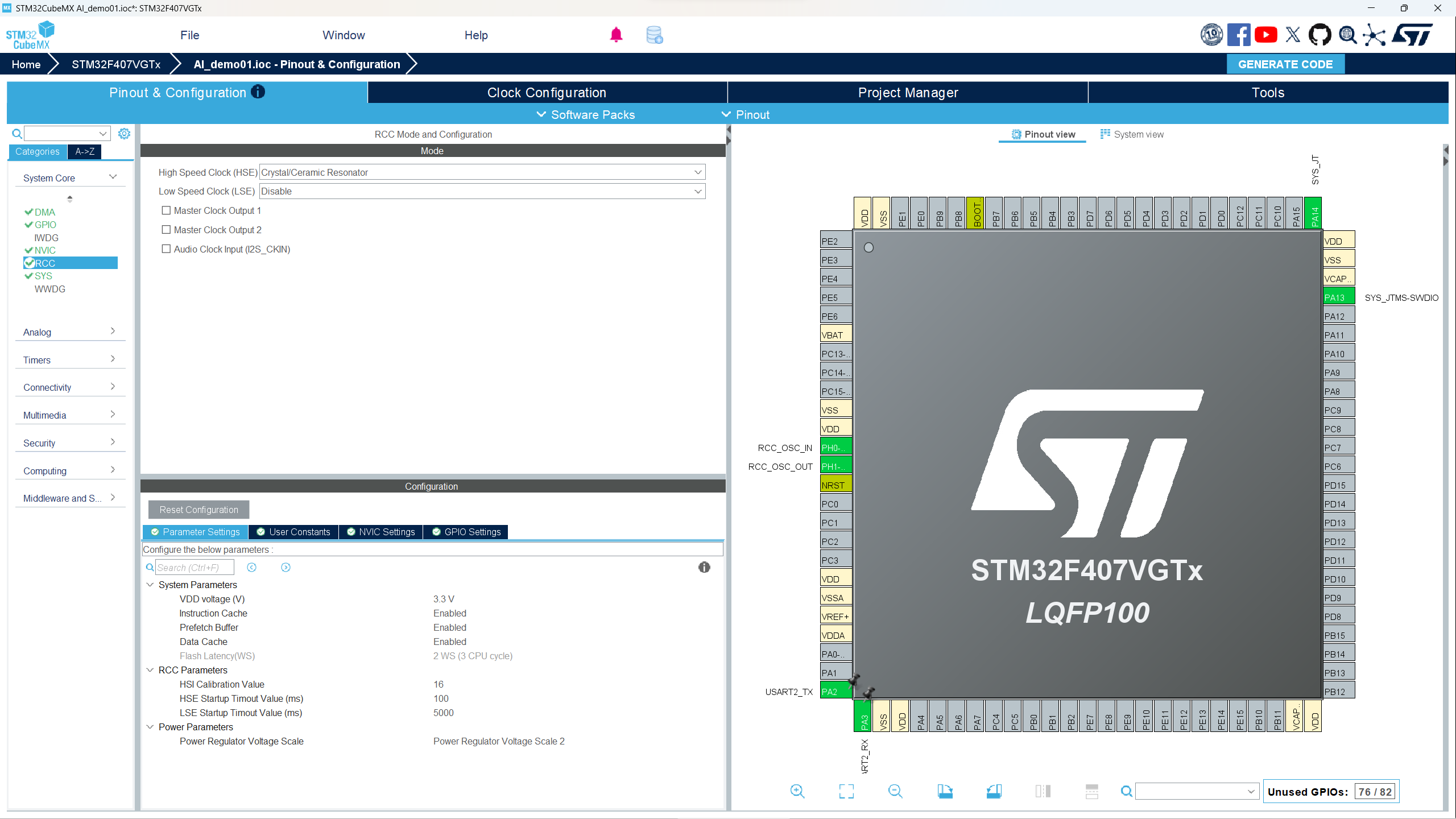
- 点击RCC进行设置。
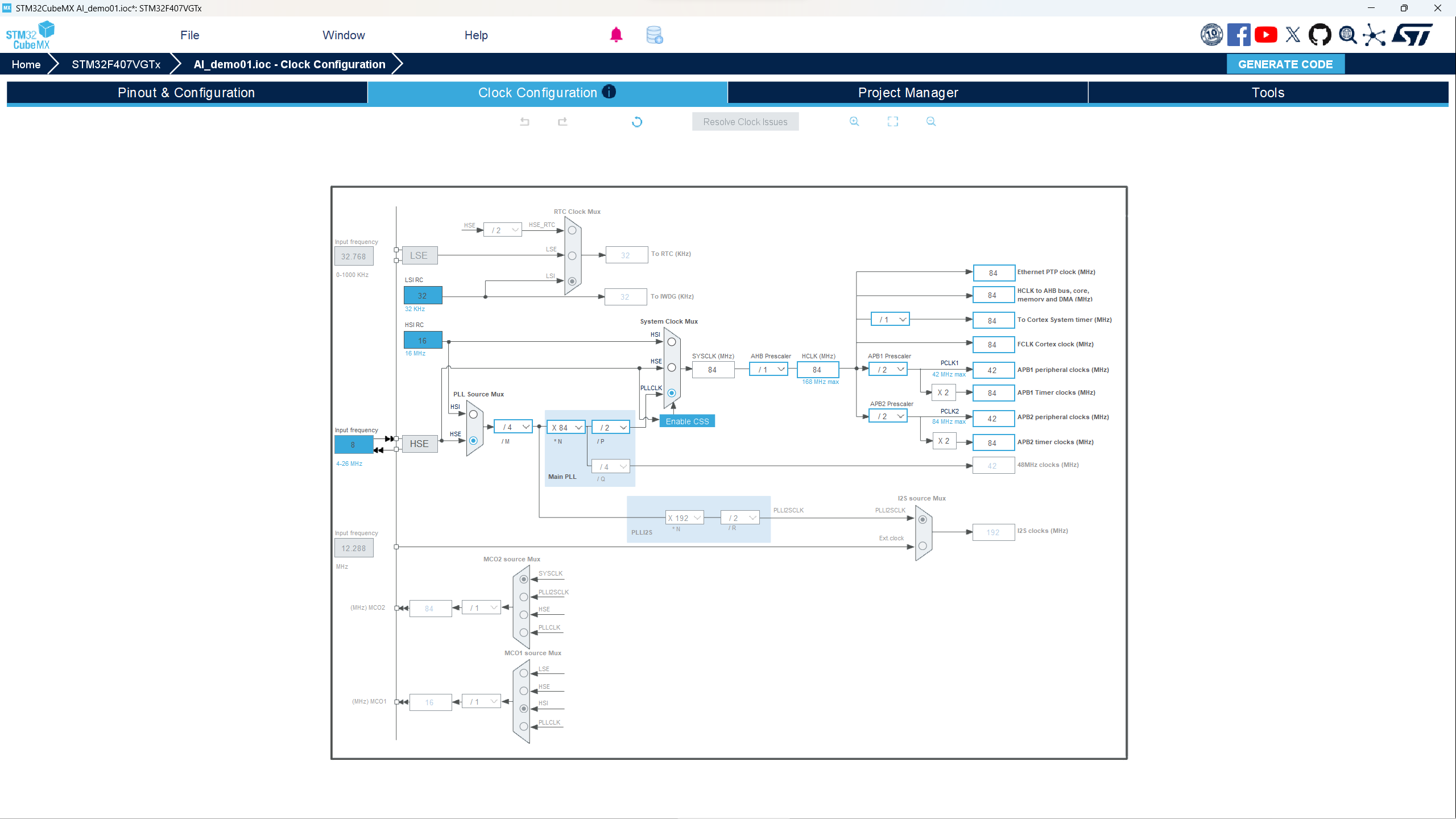
- 点击CLock Configuration,进行时钟配置,如图是我使用的配置。
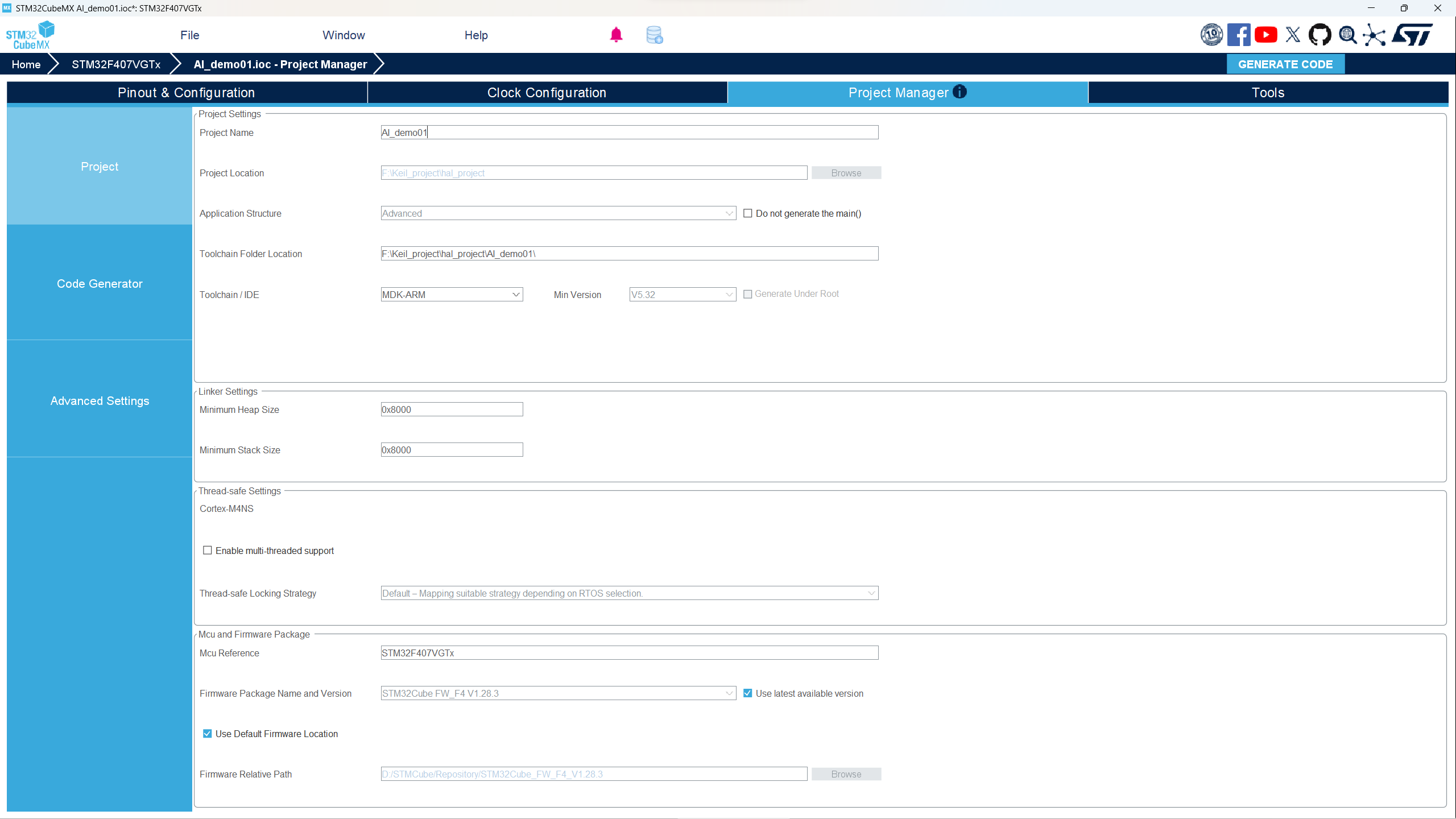
- 点击Peoject Manager,进行项目生成的一些配置,如下图。左边3个列表里面的配置是什么含义,可以截图问问AI,本文不详细说明。设置好之后点击右上角CENERATE CODE生成项目文件。
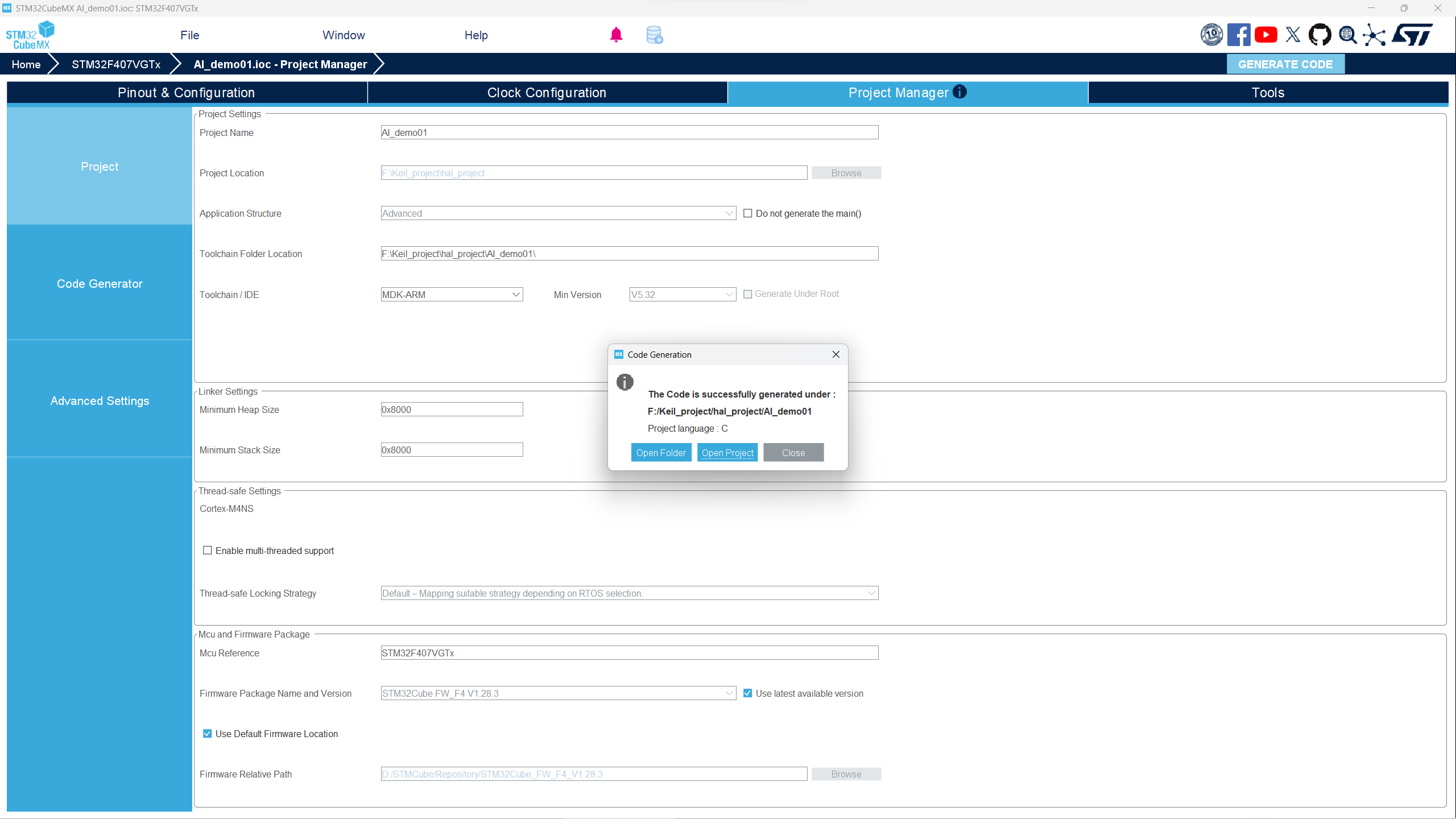
- 创建项目需要一些时间,完成后点击中间的按钮,会直接在Keil中打开文件。
如果还是不清楚,可以参考这篇:手把手教你在单片机上部署深度学习模型——基于STM32CubeMX与X-Cube-AI_stm32部署ai模型-CSDN博客
五、Keil代码
生成的代码项目打开如下图所示,在main文件写代码。
我的代码如下:
/* USER CODE BEGIN Header */
/* USER CODE END Header */
/* Includes ------------------------------------------------------------------*/
#include "main.h"
#include "crc.h"
#include "dma.h"
#include "usart.h"
#include "gpio.h"
/* Private includes ----------------------------------------------------------*/
/* USER CODE BEGIN Includes */
#include "networks.h"
#include "networks_data.h"
#include "ai_platform.h"
#include <string.h>
#include <stdio.h>
/* USER CODE END Includes */
/* Private typedef -----------------------------------------------------------*/
/* USER CODE BEGIN PTD */
// 图像大小:28x28 = 784
#define IMG_LEN 784
// 接收电脑发来的图像数据(uint8 0~255)
uint8_t rx_buffer[IMG_LEN] = {0};
// 模型输入输出
float input_data[28*28] = {0};
float output_data[10] = {0};
// AI 句柄
ai_handle network = AI_HANDLE_NULL;
int result = 0;
// 1) 激活缓存(必须)
static ai_u8 activations[32*1024] AI_ALIGNED(4);
const ai_handle acts[] = { activations };
ai_error err;
volatile uint8_t rx_finish = 0; // 接收完成标志
volatile uint8_t tx_done = 1; // 发送完成标志
char tx_buf[64]; // 全局发送缓冲区
/* USER CODE END PTD */
/* Private define ------------------------------------------------------------*/
/* USER CODE BEGIN PD */
// 发送完成回调
void HAL_UART_TxCpltCallback(UART_HandleTypeDef *huart)
{
if (huart->Instance == USART2)
{
tx_done = 1; // 标记发送完成
}
}
/* USER CODE END PD */
/* Private macro -------------------------------------------------------------*/
/* USER CODE BEGIN PM */
/* USER CODE END PM */
/* Private variables ---------------------------------------------------------*/
/* USER CODE BEGIN PV */
/* USER CODE END PV */
/* Private function prototypes -----------------------------------------------*/
void SystemClock_Config(void);
/* USER CODE BEGIN PFP */
uint32_t get_us(void); // 微秒计时
/* USER CODE END PFP */
/* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 */
/* USER CODE END 0 */
/**
* @brief The application entry point.
* @retval int
*/
int main(void)
{
/* USER CODE BEGIN 1 */
/* USER CODE END 1 */
/* MCU Configuration--------------------------------------------------------*/
/* Reset of all peripherals, Initializes the Flash interface and the Systick. */
HAL_Init();
/* USER CODE BEGIN Init */
__HAL_RCC_CRC_CLK_ENABLE();
/* USER CODE END Init */
/* Configure the system clock */
SystemClock_Config();
/* USER CODE BEGIN SysInit */
/* USER CODE END SysInit */
/* Initialize all configured peripherals */
MX_GPIO_Init();
MX_DMA_Init();
MX_CRC_Init();
MX_USART2_UART_Init();
/* USER CODE BEGIN 2 */
err = ai_networks_create_and_init(&network, acts, NULL);
// 必须判断!!!失败就停住
if (err.type != AI_ERROR_NONE) {
Error_Handler(); // 初始化失败
}
// ---------- 4. 获取输入输出(标准做法) ----------
ai_buffer* input = ai_networks_inputs_get(network, NULL);
ai_buffer* output = ai_networks_outputs_get(network, NULL);
// 绑定数据指针
input->data = (void*)input_data;
output->data = (void*)output_data;
// 【关键】开启 DMA 接收 + 空闲中断
HAL_UART_Receive_DMA(&huart2, rx_buffer, IMG_LEN);
__HAL_UART_ENABLE_IT(&huart2, UART_IT_IDLE);
while(1)
{
if(rx_finish == 1 && tx_done == 1)
{
rx_finish = 0; // 清除标志
tx_done = 0;
//matrix_transpose_28x28(rx_buffer, transposed_img);
// 1. 数据转格式
for(int i=0; i<IMG_LEN; i++){
float val = rx_buffer[i] / 255.0f;
input_data[i] = (val - 0.1307f) / 0.3081f;
}
// 2. 推理
uint32_t t_start = get_us();
ai_networks_run(network, input, output);
uint32_t t_end = get_us();
uint32_t time_us = t_end - t_start;
// 3. 找结果
result = 0;
for(int i=1; i<10; i++){
if(output_data[i] > output_data[result])
result = i;
}
// 4. 发送
sprintf(tx_buf, "Result:%d Time:%lu us\r\n", result, (unsigned long)time_us);
HAL_UART_Transmit_DMA(&huart2, (uint8_t*)tx_buf, strlen(tx_buf));
}
}
/* USER CODE END 2 */
/* Infinite loop */
/* USER CODE BEGIN WHILE */
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
/* USER CODE END 3 */
}
/**
* @brief System Clock Configuration
* @retval None
*/
void SystemClock_Config(void)
{
RCC_OscInitTypeDef RCC_OscInitStruct = {0};
RCC_ClkInitTypeDef RCC_ClkInitStruct = {0};
/** Configure the main internal regulator output voltage
*/
__HAL_RCC_PWR_CLK_ENABLE();
__HAL_PWR_VOLTAGESCALING_CONFIG(PWR_REGULATOR_VOLTAGE_SCALE2);
/** Initializes the RCC Oscillators according to the specified parameters
* in the RCC_OscInitTypeDef structure.
*/
RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE;
RCC_OscInitStruct.HSEState = RCC_HSE_ON;
RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON;
RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE;
RCC_OscInitStruct.PLL.PLLM = 4;
RCC_OscInitStruct.PLL.PLLN = 84;
RCC_OscInitStruct.PLL.PLLP = RCC_PLLP_DIV2;
RCC_OscInitStruct.PLL.PLLQ = 4;
if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK)
{
Error_Handler();
}
/** Initializes the CPU, AHB and APB buses clocks
*/
RCC_ClkInitStruct.ClockType = RCC_CLOCKTYPE_HCLK|RCC_CLOCKTYPE_SYSCLK
|RCC_CLOCKTYPE_PCLK1|RCC_CLOCKTYPE_PCLK2;
RCC_ClkInitStruct.SYSCLKSource = RCC_SYSCLKSOURCE_PLLCLK;
RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1;
RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV2;
RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2;
if (HAL_RCC_ClockConfig(&RCC_ClkInitStruct, FLASH_LATENCY_2) != HAL_OK)
{
Error_Handler();
}
}
/* USER CODE BEGIN 4 */
// USART2 空闲中断服务函数
void USART2_IRQHandler(void)
{
if (__HAL_UART_GET_FLAG(&huart2, UART_FLAG_IDLE) != RESET)
{
// 1. 清空闲标志
__HAL_UART_CLEAR_IDLEFLAG(&huart2);
// 2. 停止当前 DMA 接收
HAL_UART_AbortReceive(&huart2);
// 3. 标记接收完成
rx_finish = 1;
// 4. 重新开启 DMA 接收
HAL_UART_Receive_DMA(&huart2, rx_buffer, IMG_LEN);
}
// 必须调用 HAL 的中断处理函数,否则状态机不会更新
HAL_UART_IRQHandler(&huart2);
}
/**
* @brief 微秒级计时函数
*/
uint32_t get_us(void)
{
return HAL_GetTick() * 1000 + (SysTick->LOAD - SysTick->VAL) * 1000 / SysTick->LOAD;
}
/* USER CODE END 4 */
/**
* @brief Period elapsed callback in non blocking mode
* @note This function is called when TIM6 interrupt took place, inside
* HAL_TIM_IRQHandler(). It makes a direct call to HAL_IncTick() to increment
* a global variable "uwTick" used as application time base.
* @param htim : TIM handle
* @retval None
*/
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
/* USER CODE BEGIN Callback 0 */
/* USER CODE END Callback 0 */
if (htim->Instance == TIM6)
{
HAL_IncTick();
}
/* USER CODE BEGIN Callback 1 */
/* USER CODE END Callback 1 */
}
/**
* @brief This function is executed in case of error occurrence.
* @retval None
*/
void Error_Handler(void)
{
/* USER CODE BEGIN Error_Handler_Debug */
/* USER CODE END Error_Handler_Debug */
}
#ifdef USE_FULL_ASSERT
/**
* @brief Reports the name of the source file and the source line number
* where the assert_param error has occurred.
* @param file: pointer to the source file name
* @param line: assert_param error line source number
* @retval None
*/
void assert_failed(uint8_t *file, uint32_t line)
{
/* USER CODE BEGIN 6 */
/* USER CODE END 6 */
}
#endif /* USE_FULL_ASSERT */
代码复制后进行编译,会报一个错误,原因是在这个文件里的函数重名,我再main函数里面已经写了,删掉这个文件的函数就可,再重新编译下载即可。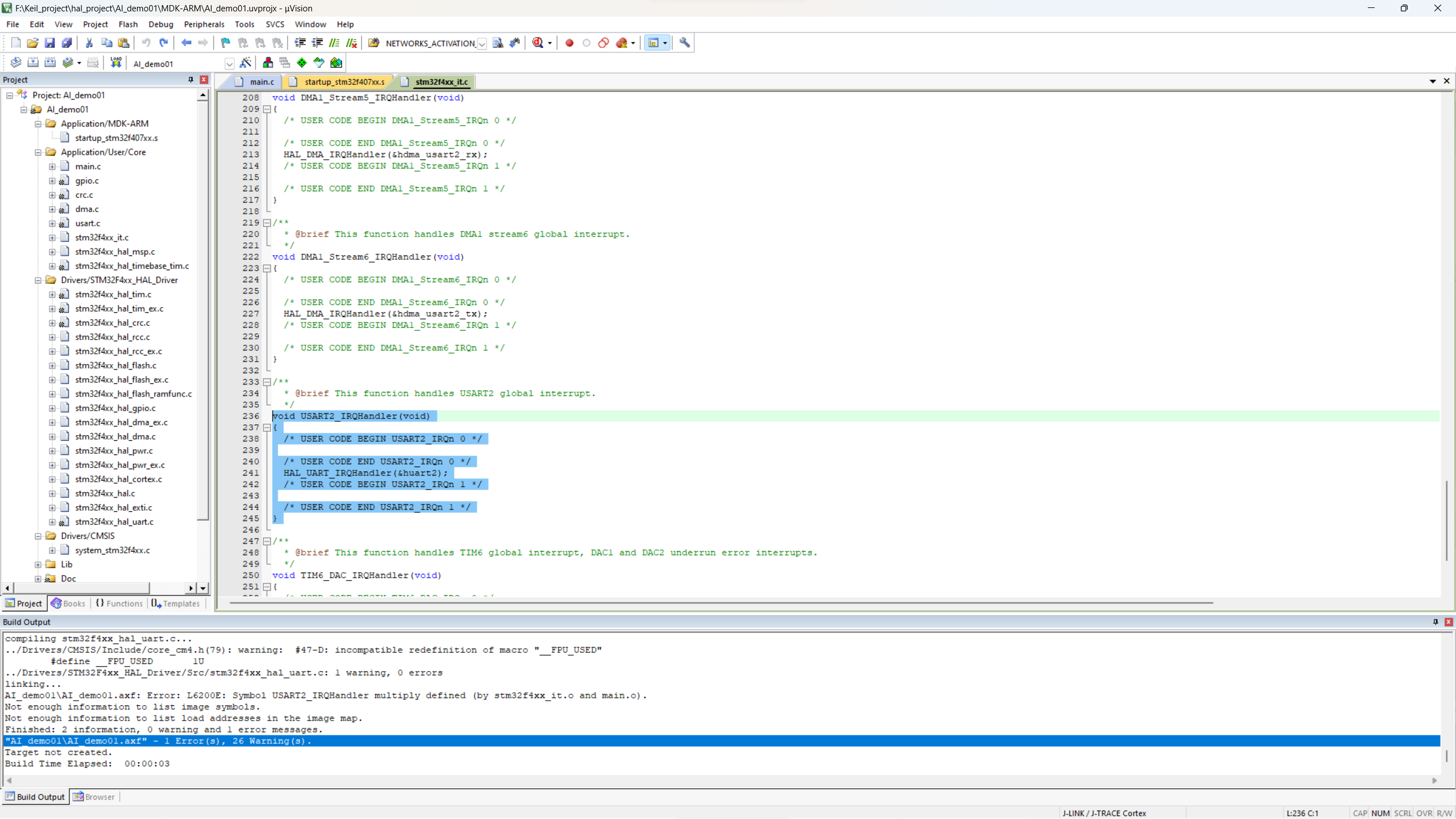
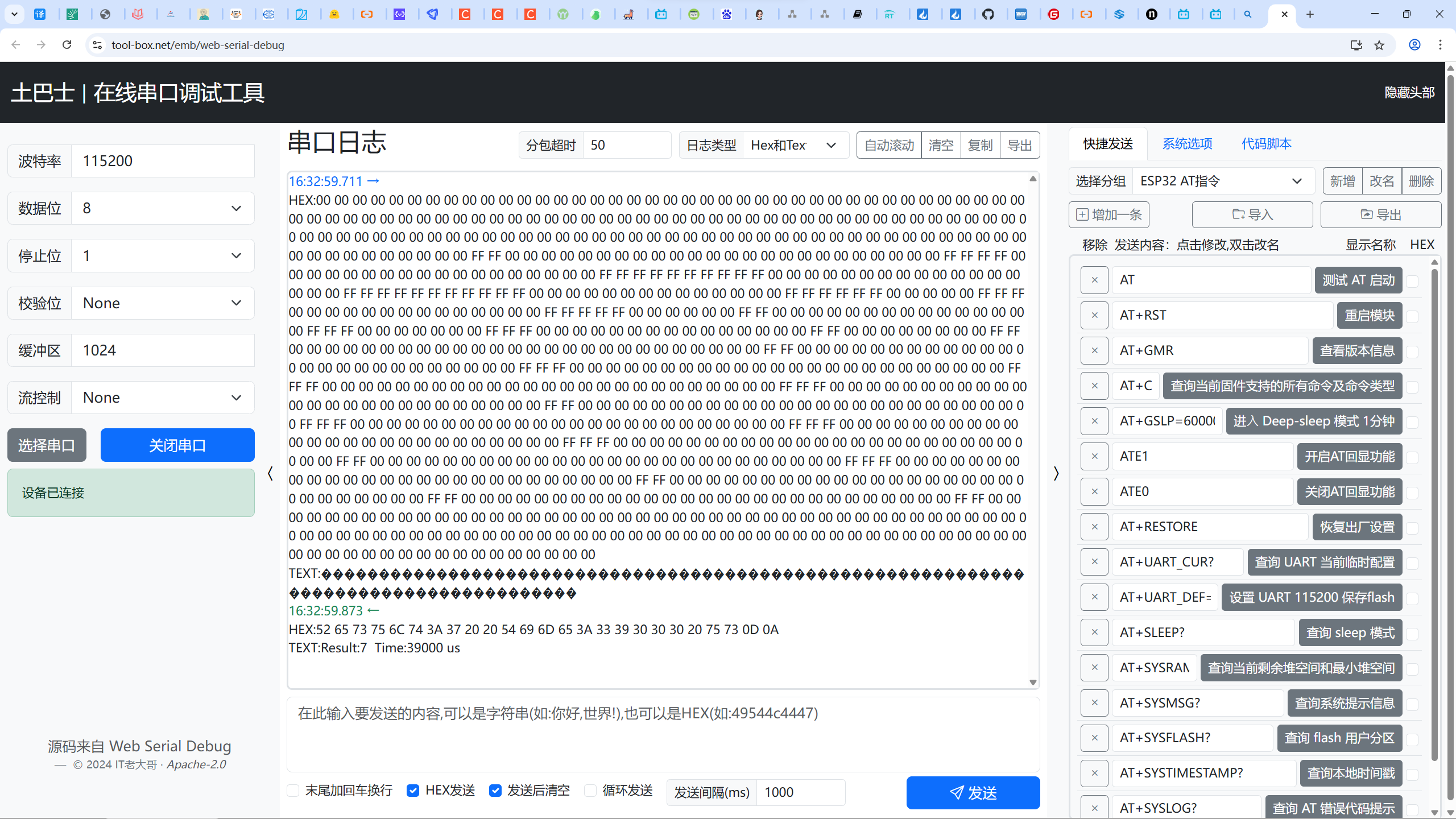
下载后使用串口调试助手进行调试,模型接受的是28*28的图像像素值,串口使用hex发送,数据如下,代表数字7的手写数字。
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF FF 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 FF FF FF FF FF FF FF FF FF FF 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 FF FF FF FF FF FF FF FF FF FF FF 00 00 00 00 00 00 00 00
00 00 00 00 00 00 FF FF FF FF FF FF 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00
00 00 00 00 00 00 FF FF FF FF FF 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 FF FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 FF FF 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00可以看到,收到了模型的识别结果以及模型运行时间。
六、pytorch训练手写数字识别模型代码。
import torch
import os
import numpy as np
import torch.nn.functional as F
import torch.nn as nn
from torch.optim import SGD
from torchvision.datasets import MNIST
from torchvision.transforms import Compose, ToTensor, Normalize
from torch.utils.data import DataLoader
BATCH_SIZE = 100
# 1.加载数据集
def get_dataloader(train=True):
transform_fn = Compose([
ToTensor(),
Normalize(mean=(0.1307,), std=(0.3081,))
])
dataset = MNIST(root="./data", train=train, transform=transform_fn)
data_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
return data_loader
# ============================
# 【终极无Reshape模型】
# 完全没有 view / reshape / flatten
# 100% 兼容 STM32Cube.AI
# ============================
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
# 用卷积替代全连接,彻底避免维度变换
self.conv3 = nn.Conv2d(16, 120, 4)
self.conv4 = nn.Conv2d(120, 84, 1)
self.conv5 = nn.Conv2d(84, 10, 1)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.conv5(x)
return x
# 初始化
model = MnistModel()
optimizer = SGD(model.parameters(), lr=0.01)
# 加载模型
if os.path.exists("./model/model_text.pth"):
model.load_state_dict(torch.load("./model/model_text.pth", weights_only=True))
print("已加载模型")
def train(epoch):
data_loader = get_dataloader()
model.train()
for batch_idx, (input, target) in enumerate(data_loader):
out_predict = model(input).squeeze()
loss = F.cross_entropy(out_predict, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 500 == 0:
print("第{}轮,损失值:{}".format(epoch, loss.item()))
os.makedirs("./model", exist_ok=True)
torch.save(model.state_dict(), "./model/model_text.pth")
def test():
loss_list = []
acc_list = []
model.eval()
test_loader = get_dataloader(train=False)
for idx, (input, target) in enumerate(test_loader):
with torch.no_grad():
cur_out_predict = model(input).squeeze()
cur_loss = F.cross_entropy(cur_out_predict, target)
loss_list.append(cur_loss.item())
pred = cur_out_predict.argmax(dim=1)
cur_acc = pred.eq(target).sum().item()
acc_list.append(cur_acc / target.size(0))
print("测试集损失:{},准确率:{}%".format(np.mean(loss_list), np.mean(acc_list) * 100))
# 导出 ONNX
def ouput_ONNX():
model.eval()
dummy_input = torch.randn(1, 1, 28, 28)
os.makedirs("./onnx_models", exist_ok=True)
torch.onnx.export(
model,
dummy_input,
"./onnx_models/mnist_stm32_FINAL.onnx",
input_names=["input"],
output_names=["output"],
opset_version=14,
do_constant_folding=True,
)
print("🎉 终极 ONNX 导出成功!绝对不报 allowzero!")
if __name__ == '__main__':
train(200)
test()
ouput_ONNX()
智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)