Kubernetes Network,kubernetes Pod Schedule详解
Kubernetes Network
学习参考:网络策略
环境准备
root@master30:~# kubectl create ns network root@master30:~# kubectl config set-context --current --namespace network
单主机网络通信
Docker 单机网络
Docker中的网络接口默认都是虚拟的接口。虚拟接口的最大优势就是转发效率极高。这是因为Linux在内核中进行数据复制来实现虚拟接口之间的数据转发,即发送接口的发送缓存中的数据包将被直接复制到接收接口的接收缓存中,而无需通过外部物理网络设备进行交换。
Docker 服务默认会创建一个名称为docker0的Linux网桥(其上有一个docker0内部接口),利用了Linux虚拟网络技术,在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通(这样的一对接口叫做vethpair)。Docker默认指定了docker0接口的IP地址和子网掩码,让主机和容器之间可以通过网桥相互通信。
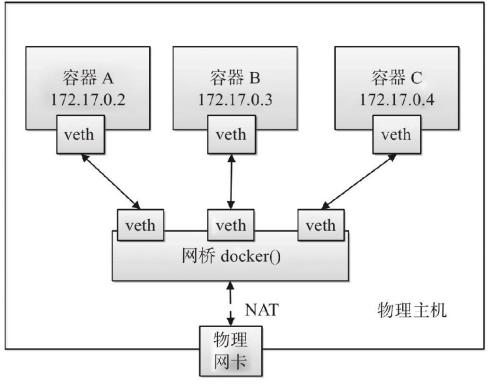
说明:brctl工具由bridge-utils提供。
外部主机要想访问容器,需要通过端口映射实现。
Containerd 单机网络
Containerd 中的网络 与Docker类似,所有网络接口默认都是虚拟接口。
创建容器时,Containerd 会在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通。
跨主机网络通信
跨主机通信架构
以上图
片来源于《基于 kubernetes 的容器云平台实战 》。
跨主机通信方法比较多,可以使用:
-
docker 原生的方案:overlay 和 macvlan。
-
第三方提供的方案:flannel 、calico、weave等。
重点关注两点:配置难易程度和是否支持网络策略。
以下数据来源于《kubernetes 权威指南》。
| 方案 特性 | Flannel | Calico | macvlan | OpenVswitch | 直接路由 |
|---|---|---|---|---|---|
| 方案特性 | 通过虚拟设备flannel0实现对docker0的管理 | 基于BGP协议的纯三层的网络方案 | 基于Linux Kernel 的macvlan技术 | 基于隧道的虚拟路由器技术 | 基于Linux Kernel 的 vRouter 技术 |
| 对底层网络的要求 | 三层互通 | 三层互通 | 二层互通 | 三层互通 | 二层互通 |
| 配置难易程度 | 简单-基于etcd | 简单-基于etcd | 简单-直接使用宿主机网络,需要仔细规划IP地址 | 复杂-需手工配置个节点的bridge | 简单-使用宿主机vRoute功能,需要仔细规划每个Node的IP地址 |
| 网络性能 | host-gw > VxLAN | BGP 模式性能随时小、IPIP 模式较小 | 性能随时可忽略 | 性能随时较小 | 性能随时较小 |
| 网络连通性限制 | 无 | 在不支持BGP的网络环境下无法使用 | 基于macvlan的容器无法与宿主机网络通信 | 无 | 在无法实现大二层互通的网络环境下无法使用 |
跨主机通信方案
我们将从如下几个方面比较,大家可以根据不同场景选择最合适的方案。
-
网络模型,采用何种网络模型支持 multi-host 网络?
-
Distributed Store,是否需要 etcd 或 consul 这类分布式 key-value 数据库存储网络信息?
-
IPMA,如何管理容器网络的 IP?
-
连通与隔离,提供怎样的网络连通性?支持容器间哪个级别和哪个类型的隔离?
-
性能,性能比较。
网络模型
跨主机网络意味着将不同主机上的容器用同一个虚拟网络连接起来。这个虚拟网络的拓扑结构和实现技术就是网络模型。
-
overlay,建立主机间 VxLAN 隧道,原始数据包在发送端被封装成 VxLAN 数据包,到达目的后在接收端解包。
-
Macvlan ,网络在二层上通过 VLAN 连接容器,在三层上依赖外部网关连接不同 macvlan。数据包直接发送,不需要封装,属于underlay 网络。
-
Flannel 支持 backend:vxlan 和 host-gw。vxlan 与 Docker overlay 类似,属于 overlay 网络。host-gw 将主机作为网关,依赖三层 IP 转发,不需要像 vxlan 那样对包进行封装,属于 underlay 网络。
-
Weave, 是 VxLAN 实现,属于 overlay 网络。
-
Calico ,与Flannel使用host-gw类似,将主机作为网关,依赖三层 IP 转发,不需要像 vxlan 那样对包进行封装,属于 underlay 网络。
Distributed Store
Docker Overlay、Flannel 和 Calico 都需要 etcd 或 consul。Macvlan 是简单的 local 网络,不需要保存和共享网络信息。Weave 自己负责在主机间交换网络配置信息,也不需要 Distributed Store。
IPAM
Docker Overlay 网络中所有主机共享同一个 subnet,容器启动时会顺序分配 IP,可以通过 --subnet 定制此 IP 空间。
Macvlan 需要用户自己管理 subnet,为容器分配 IP,不同 subnet 通信依赖外部网关。
Flannel 为每个主机自动分配独立的 subnet,用户只需要指定一个大的 IP 池。不同 subnet 之间的路由信息也由 Flannel 自动生成和配置。
Weave 的默认配置下所有容器使用 10.32.0.0/12 subnet,如果此地址空间与现有 IP 冲突,可以通过 --ipalloc-range 分配特定的 subnet。
Calico 从 IP Pool(可定制)中为每个主机分配自己的 subnet。
连通与隔离
同一 Docker Overlay 网络中的容器可以通信,但不同网络之间无法通信,要实现跨网络访问,只有将容器加入多个网络。与外网通信可以通过 docker_gwbridge 网络。
Macvlan 网络的连通或隔离完全取决于二层 VLAN 和三层路由。
不同 Flannel 网络中的容器直接就可以通信,没有提供隔离。与外网通信可以通过 bridge 网络。
Weave 网络默认配置下所有容器在一个大的 subnet 中,可以自由通信,如果要实现隔离,需要为容器指定不同的 subnet 或 IP。与外网通信的方案是将主机加入到 weave 网络,并把主机当作网关。
Calico 默认配置下只允许位于同一网络中的容器之间通信,但通过其强大的 Policy 能够实现几乎任意场景的访问控制。
性能
性能测试是一个非常严谨和复杂的工程,这里我们只尝试从技术方案的原理上比较各方案的性能。
最朴素的判断是:Underlay 网络性能优于 Overlay 网络。
Overlay 网络利用隧道技术,将数据包封装到 UDP 中进行传输。因为涉及数据包的封装和解封,存在额外的 CPU 和网络开销。虽然几乎所有 Overlay 网络方案底层都采用 Linux kernel 的 vxlan 模块,这样可以尽量减少开销,但这个开销与 Underlay 网络相比还是存在的。所以 Macvlan、Flannel host-gw、Calico 的性能会优于 Docker overlay、Flannel vxlan 和 Weave。
Overlay 较 Underlay 可以支持更多的二层网段,能更好地利用已有网络,以及有避免物理交换机 MAC 表耗尽等优势,所以在方案选型的时候需要综合考虑。
跨主机网络模型
容器网络的配置是一个复杂的过程,为了应对各式各样的需求:
-
容器网络的解决方案也多种多样,例如有flannel,calico,kube-ovn,weave等。
-
容器平台/运行时也是多样的,例如有Kubernetes,Openshift,rkt等。
想要解决这个问题,我们需要一个抽象的接口层,将容器网络配置方案与容器平台方案解耦。
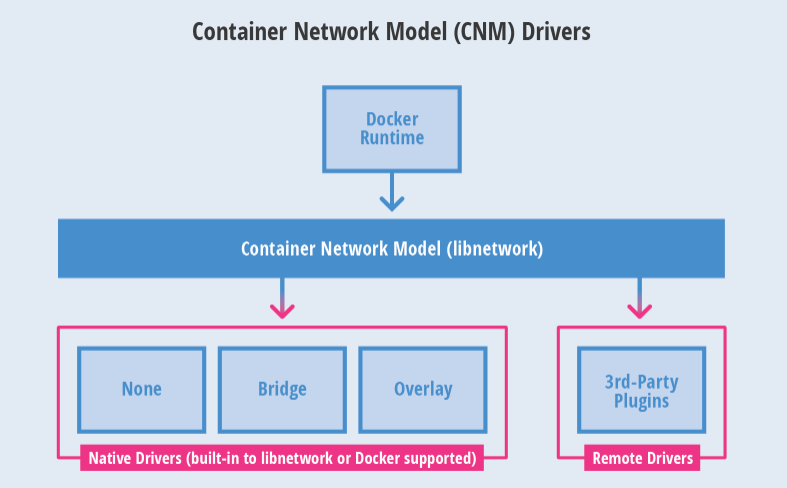
CNM
CNM( Container Network Model,容器网络模型),由 Docker 公司提出,在 docker 项目下的 libnetwork 项目中被采用。按照该模型开发出的 driver 就能与 docker daemon 协同工作,实现容器网络。
-
docker 原生的 driver 包括 none、bridge、overlay 和 macvlan。
-
第三方 driver 包括 flannel、weave、calico 等。
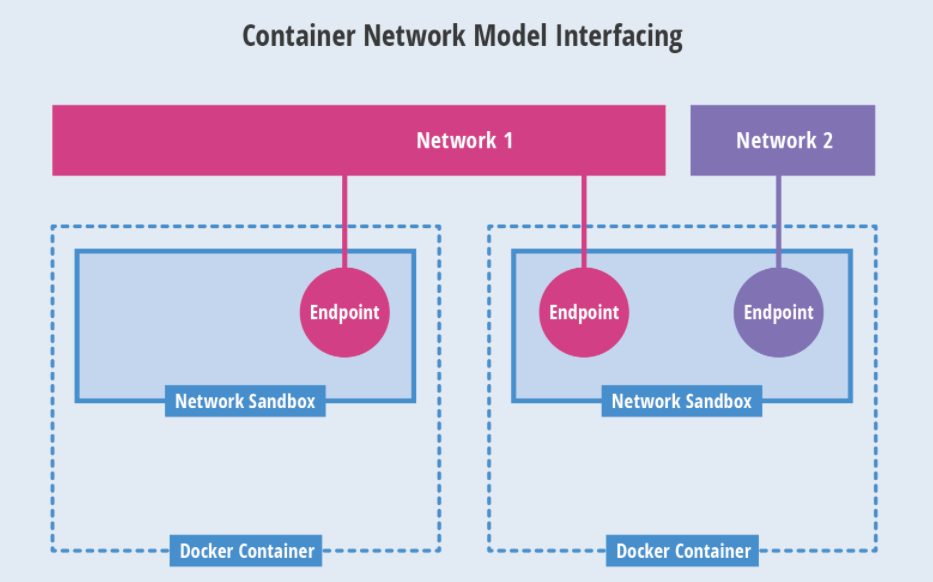
容器网络模型对容器网络进行了抽象,由以下三类组件组成:
-
Sandbox 是容器的网络栈,包含容器的 interface、路由表和 DNS 设置。 Linux Network Namespace 是 Sandbox 的标准实现。Sandbox 可以包含来自不同 Network 的 Endpoint。
-
Endpoint 的作用是将 Sandbox 接入 Network。Endpoint 的典型实现是 veth pair,后面我们会举例。一个 Endpoint 只能属于一个网络,也只能属于一个 Sandbox。
-
Network 包含一组 Endpoint,同一 Network 的 Endpoint 可以直接通信。Network 的实现可以是 Linux Bridge、VLAN 等。
如图所示两个容器,一个容器一个 Sandbox,每个 Sandbox 都有一个 Endpoint 连接到 Network 1,第二个 Sandbox 还有一个 Endpoint 将其接入 Network 2.
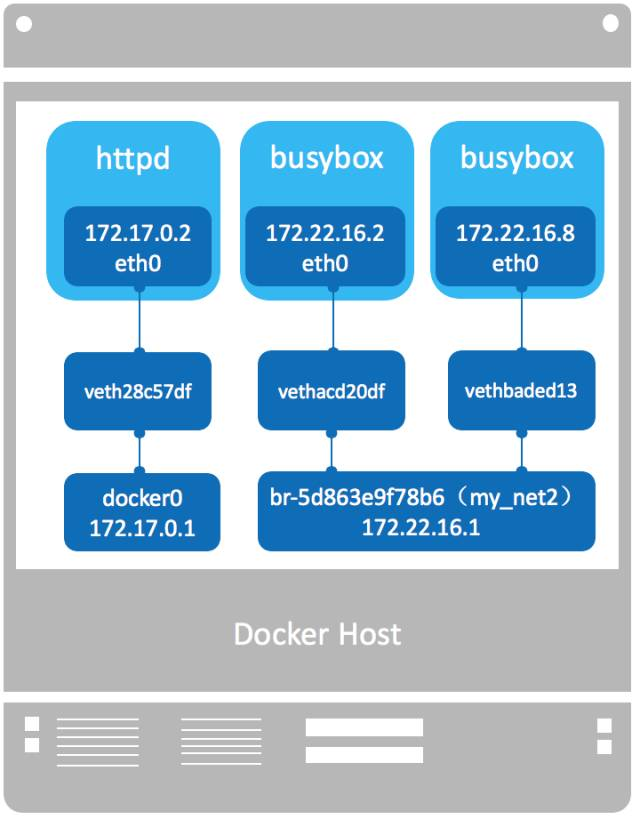
下面我们以 docker bridge driver 为例讨论 libnetwork CNM 是如何被实现的。
-
两个 Network:默认网络 “bridge” 和自定义网络 “my_net2”。实现方式是 Linux Bridge:“docker0” 和 “br-5d863e9f78b6”。
-
三个 Enpoint,由 veth pair 实现,一端(vethxxx)挂在 Linux Bridge 上,另一端(eth0)挂在容器内。
-
三个 Sandbox,由 Network Namespace 实现,每个容器有自己的 Sanbox。
CNI
CNI,全称 Container Network Interface,是 Google 和 CoreOS 联合定制的网络标准,CNI 规范定义了容器和网络插件之间通信规范,实现多容器通信。各个网络厂商通过该接口实现互相通信。
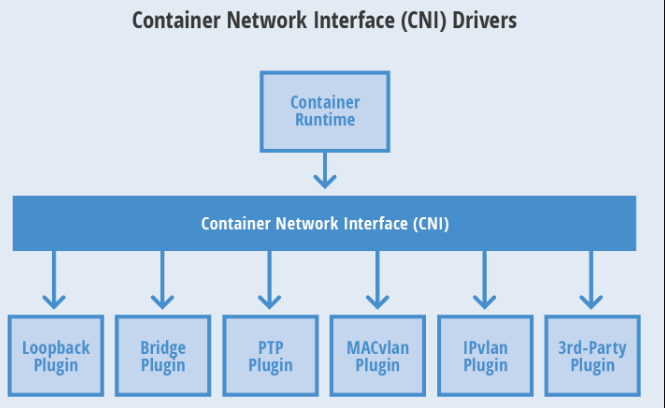
一个容器可以被加入到被不同插件所驱动的多个网络之中。一个网络有自己对应的插件和唯一的名称。
CNI 模型包含2个概念:
-
容器: 独立的 linux 网络命名空间。
-
网络: 用于互联实体, 这些实体拥有各自独立且唯一的 IP 地址, 可以是容器, 物理机, 或者其他网络设备。
通过插件设置网络, 包括 CNI Plugin 和 IPAM ( IP address management) Plugin 两类插件:
-
CNI Plugin 负责配置容器网络。
-
IPAM plugin 负责分配容器的IP 地址。
IPAM Plugin 作为 CNI plugin 的一部分, 与CNI plugin 一起工作。
-
CNM和CNI比较
| 特点 | CNM | CNI |
|---|---|---|
| 标准规范 | Libnetwork | cni |
| 最小单元 | 容器 | POD |
| 对守护进程的依赖 | 依赖 dockerd | 不依赖任何守护进程 |
| 扩主机通信 | 依赖外部 KV 数据库 | 用本身的 KV 数据库 |
| 灵活程度 | 被 docker 绑定 | 插件可随意替换 |
网络策略
网络策略介绍
默认情况,集群网络连通性如下:
-
集群外部主机可以访问集群内部应用
-
集群内部应用也可以访问集群外部主机
-
各个namespace之间没有做任何的隔离策略
如果希望在 IP 地址或端口层面控制网络流量, 考虑使用 Kubernetes 网络策略(NetworkPolicy)。
-
NetworkPolicy 是一种以应用为中心的结构,允许你设置如何允许 Pod 与网络上的各类网络“实体” 通信。
-
NetworkPolicy 适用于一端或两端与 Pod 的连接,与其他连接无关。
提示:网络策略通过网络插件来实现。 要使用网络策略,你必须使用支持 NetworkPolicy 的网络解决方案,例如 calico。
网络策略规约
Pod 有两种隔离: 出口的隔离和入口的隔离。
-
默认情况下,一个 Pod 的出口是非隔离的,即所有外向连接都是被允许的。如果有任何的 NetworkPolicy 选择该 Pod 并在其
policyTypes中包含 “Egress”,则该 Pod 是出口隔离的, 我们称这样的策略适用于该 Pod 的出口。当一个 Pod 的出口被隔离时, 唯一允许的来自 Pod 的连接是适用于出口的 Pod 的某个 NetworkPolicy 的egress列表所允许的连接。 这些egress列表的效果是相加的。 -
默认情况下,一个 Pod 对入口是非隔离的,即所有入站连接都是被允许的。如果有任何的 NetworkPolicy 选择该 Pod 并在其
policyTypes中包含 “Ingress”,则该 Pod 被隔离入口, 我们称这种策略适用于该 Pod 的入口。当一个 Pod 的入口被隔离时,唯一允许进入该 Pod 的连接是来自该 Pod 节点的连接和适用于入口的 Pod 的某个 NetworkPolicy 的ingress列表所允许的连接。这些ingress列表的效果是相加的。
网络策略是相加的,所以不会产生冲突。如果策略适用于 Pod 某一特定方向的流量, Pod 在对应方向所允许的连接是适用的网络策略所允许的集合。 因此,评估的顺序不影响策略的结果。
要允许从源 Pod 到目的 Pod 的连接,则源 Pod 的出口策略和目的 Pod 的入口策略都需要允许连接。如果任何一方不允许连接,建立连接将会失败。
示例:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
# 使用标签过滤限制哪些pod
podSelector:
matchLabels:
role: db
policyTypes:
# Ingress控制外部访问内部
- Ingress
# Egress控制pod访问外部
- Egress
ingress:
# from限制允许哪些主机可以访问pod
- from:
# 通过ip限制
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
# 限制namespace中pod
- namespaceSelector:
matchLabels:
project: myproject
# 限制同一namespace中pod
- podSelector:
matchLabels:
role: frontend
# 限制pod上哪些端口可以访问
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
-
必需字段:与所有其他的 Kubernetes 配置一样,NetworkPolicy 需要
apiVersion、kind和metadata字段。 -
spec:NetworkPolicy 规约 中包含了在一个命名空间中定义特定网络策略所需的所有信息。
-
spec.podSelector:每个 NetworkPolicy 都包括一个
podSelector, 它对该策略所适用的一组 Pod 进行选择。示例中的策略选择带有 "role=db" 标签的 Pod。 空的podSelector选择命名空间下的所有 Pod。 -
spec.policyTypes:每个 NetworkPolicy 都包含一个
policyTypes列表,其中包含Ingress或Egress或两者兼具。policyTypes字段表示给定的策略是应用于进入所选 Pod 的入站流量还是来自所选 Pod 的出站流量,或两者兼有。 如果 NetworkPolicy 未指定policyTypes则默认情况下始终设置Ingress; 如果 NetworkPolicy 有任何出口规则的话则设置Egress。 -
spec.ingress:每个 NetworkPolicy 可包含一个
ingress规则的白名单列表。 每个规则都允许同时匹配from和ports部分的流量。示例策略中包含一条简单的规则: 它匹配某个特定端口,来自三个来源中的一个:-
第一个通过
ipBlock指定 -
第二个通过
namespaceSelector指定 -
第三个通过
podSelector指定。
-
-
spec.egress:每个 NetworkPolicy 可包含一个
egress规则的白名单列表。 每个规则都允许匹配to和port部分的流量。该示例策略包含一条规则, 该规则将指定端口上的流量匹配到10.0.0.0/24中的任何目的地。
to 和 from 选择器
可以在 ingress 的 from 部分或 egress 的 to 部分中指定四种选择器:
-
podSelector:此选择器将在与 NetworkPolicy 相同的命名空间中选择特定的 Pod,应将其允许作为入站流量来源或出站流量目的地。
-
namespaceSelector:此选择器将选择特定的命名空间,应将所有 Pod 用作其入站流量来源或出站流量目的地。
-
namespaceSelector 和 podSelector:指定
namespaceSelector和podSelector的to/from条目选择特定命名空间中的特定 Pod。示例:
... ingress: - from: - namespaceSelector: matchLabels: user: alice - podSelector: matchLabels: role: client ...在
from数组中包含两个元素,允许来自本地命名空间中标有role=client的 Pod 的连接,或来自任何命名空间中标有user=alice的任何 Pod 的连接。 -
ipBlock:此选择器将选择特定的 IP CIDR 范围以用作入站流量来源或出站流量目的地。 这些应该是集群外部 IP,因为 Pod IP 存在时间短暂的且随机产生。
集群的入站和出站机制通常需要重写数据包的源 IP 或目标 IP。 在发生这种情况时,不确定在 NetworkPolicy 处理之前还是之后发生, 并且对于网络插件、云提供商、
Service实现等的不同组合,其行为可能会有所不同。-
对入站流量而言,这意味着在某些情况下,你可以根据实际的原始源 IP 过滤传入的数据包, 而在其他情况下,NetworkPolicy 所作用的
源IP则可能是LoadBalancer或 Pod 的节点等。 -
对于出站流量而言,这意味着从 Pod 到被重写为集群外部 IP 的
ServiceIP 的连接可能会或可能不会受到基于ipBlock的策略的约束。
-
实施网络策略
准备实验环境
环境说明:
-
namespace-web 中有3个 pod:web1、web2、test
-
namespace-laoma 中有1个pod:test
-
如没有特别说明,默认namespace是web !!!!!!
[root@master30 ~ 18:47:31]# kubectl create ns web #kubens 是由 ahmetb 开发的 命令行工具,用于快速切换 Kubernetes 命名空间,是 kubectx 工具集的一部分webinstall... #列出所有命名空间:kubens #切换到指定命名空间:kubens <namespace> #显示当前命名空间:kubens -c [root@master30 ~ 19:38:01]# kubens web Context "cluster1-context" modified. Active namespace is "web". # web命名空间创建 web1 [root@master30 ~ 19:40:39]# kubectl run web1 --image=docker.io/library/nginx --image-pull-policy=IfNotPresent pod/web1 created [root@master30 ~ 19:40:47]# kubectl exec -it web1 -- bash -c 'echo Hello web1 > /usr/share/nginx/html/index.html' # web命名空间创建 web2 [root@master30 ~ 19:40:51]# kubectl run web2 --image=docker.io/library/nginx --image-pull-policy=IfNotPresent pod/web2 created [root@master30 ~ 19:41:01]# kubectl exec -it web2 -- bash -c 'echo Hello web2 > /usr/share/nginx/html/index.html' # 创建service web1和web2 [root@master30 ~ 19:41:06]# kubectl expose pod web1 --port=80 --target-port=80 --type=NodePort service/web1 exposed [root@master30 ~ 19:41:25]# kubectl expose pod web2 --port=80 --target-port=80 --type=NodePort service/web2 exposed [root@master30 ~ 19:41:29]# kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE web1 NodePort 10.109.166.127 <none> 80:32351/TCP 7s web2 NodePort 10.100.158.38 <none> 80:30423/TCP 3s # 同一namespace中web1和web2互相访问 #web命名空间创建test [root@master30 ~ 19:41:32]# kubectl run test --image=docker.io/library/busybox --image-pull-policy=IfNotPresent sleep 3600 pod/test created [root@master30 ~ 19:42:45]# kubectl exec -it test -- sh / # wget web2.web -O web2-index.html Connecting to web2.web (10.100.158.38:80) saving to 'web2-index.html' web2-index.html 100% |*****************************| 11 0:00:00 ETA 'web2-index.html' saved / # cat web2-index.html Hello web2 / # wget web1.web -O web1-index.html Connecting to web1.web (10.109.166.127:80) saving to 'web1-index.html' web1-index.html 100% |*****************************| 11 0:00:00 ETA 'web1-index.html' saved / # cat web1-index.html Hello web1 / # exit # 在不同namespace-zy中创建测试pod-test,访问web1和web2 [root@master30 ~ 19:43:10]# kubectl create ns zy namespace/zy created #在不同命名空间zy下创建test [root@master30 ~ 19:44:09]# kubectl run test -n zy --image=docker.io/library/busybox --image-pull-policy=IfNotPresent sleep 3600 pod/test created #进入zy命名空间下的test进行验证 [root@master30 ~ 19:44:12]# kubectl exec -n zy test -- wget web1.web -O /tmp/web1.html Connecting to web1.web (10.109.166.127:80) saving to '/tmp/web1.html' web1.html 100% |********************************| 11 0:00:00 ETA '/tmp/web1.html' saved [root@master30 ~ 19:44:17]# kubectl exec -n zy test -- wget web2.web -O /tmp/web2.html Connecting to web2.web (10.100.158.38:80) saving to '/tmp/web2.html' web2.html 100% |********************************| 11 0:00:00 ETA '/tmp/web2.html' saved # 集群内访问service web1和web2 [root@master30 ~ 19:44:52]# curl 10.109.166.127 Hello web1 [root@master30 ~ 19:45:14]# curl 10.100.158.38 Hello web2 [root@master30 ~ 19:46:47]# kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE web1 NodePort 10.109.166.127 <none> 80:32351/TCP 5m37s web2 NodePort 10.100.158.38 <none> 80:30423/TCP 5m33s # 集群外节点访问web1和web2 [root@master30 ~ 19:45:26]# curl http://10.1.8.30:32351 Hello web1 [root@master30 ~ 19:46:17]# curl http://10.1.8.30:30423 Hello web2 [root@master30 ~ 19:47:02]# curl http://10.1.8.31:32351 Hello web1 [root@master30 ~ 19:55:14]# curl http://10.1.8.32:32351 Hello web1 结合实验操作详解 4 大核心结论 结论 1:命名空间仅隔离资源,不隔离集群内网网络 对应实验操作 创建两个独立命名空间 web、zy;web 存放 web1、web2、test,zy 单独创建 test 容器; 切换到zy命名空间的 test Pod,直接访问web命名空间的 web1、web2 服务,成功获取页面内容。 详细解释 命名空间可以理解为集群内的资源分类文件夹,作用只是区分不同项目的 Pod、Service,避免同名资源冲突; 它不会阻断集群内部网络,同一个集群里,不管 Pod 放在哪个命名空间,都能互相访问对方的 Service,网络是互通的。 结论 2:CoreDNS 提供集群域名解析,同 ns 简写服务名,跨 ns 使用服务名.命名空间域名 对应实验操作 同命名空间(web)内的 test 容器:直接执行wget web1、wget web2,无需填写 IP 就能访问; 跨命名空间(zy)的 test 容器:仅输入web1解析失败,填写web1.web后才能正常连通服务。 详细解释 集群内置 CoreDNS 相当于集群专属 “通讯录”,自动给每个 Service 分配域名: 目标服务和当前 Pod 在同一个命名空间:只写服务名称即可解析; 目标服务在其他命名空间:必须加上目标命名空间做区分,格式为服务名.目标ns; 底层完整标准域名为 服务名.命名空间.svc.cluster.local。 结论 3:ClusterIP 仅集群内部可用,是 Pod 之间通信的标准入口 对应实验操作 查看 Service 信息,自动生成内网虚拟 IP(web1:10.109.166.127,web2:10.100.158.38); 集群内所有节点、所有 Pod 都能curl这个 IP 访问业务;集群外部机器无法直接连通该 IP。 详细解释 ClusterIP 是 Service 专属集群内网虚拟 IP,仅对集群内部开放,外网无法触达; 集群内容器互相调用业务时,优先使用 ClusterIP 通信,是集群内部访问服务最标准、最安全的方式。 结论 4:NodePort 对外暴露端口,允许集群外部服务器 / 电脑访问容器服务 对应实验操作 创建 Service 时指定--type=NodePort,集群自动分配 30000~32767 区间对外开放端口;web1 端口 32351,web2 端口 30423; 集群外部主机执行 curl 集群节点IP:NodePort端口,成功访问容器内网页。 详细解释 NodePort 会在集群全部宿主机上开启一个公开端口,相当于给集群打通对外通道; 只要外部机器能连通集群节点 IP,搭配 NodePort 端口,就能绕过集群内网,直接访问容器里的业务页面。 整体实验总结 整套实验从命名空间网络隔离特性、集群 DNS 解析、集群内网访问、外网访问入口四个维度,完整演示 K8s Service 的网络访问规则,区分了集群内、集群外两种场景的访问方式。
根据 pod 标签限定
根据pod标签限定:
-
限定同一ns中pod之间访问
-
所有其他ns中pod或者集群外主机都无法访问ns中pod
示例1:允许同一ns中具有标签run: test的pod,访问具有标签run: web1的pod 80端口。
root@master30:~# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
run: test
ports:
- protocol: TCP
port: 80
# 创建network policy [root@master30 ~ 19:59:34]# kubectl apply -f netpol.yaml networkpolicy.networking.k8s.io/my-network-policy created [root@master30 ~ 19:59:39]# kubectl get netpol NAME POD-SELECTOR AGE my-network-policy run=web1 4s # 同一namespace中test可以访问web1,web2不可以访问web1 [root@master30 ~ 20:09:21]# kubectl exec test -- sh -c 'rm index.html;wget web1' Connecting to web1 (10.109.166.127:80) saving to 'index.html' index.html 100% |********************************| 11 0:00:00 ETA 'index.html' saved # 修改现有标签 [root@master30 ~ 20:09:58]# kubectl label pod test run=web2 --overwrite pod/test labeled [root@master30 ~ 20:10:36]# kubectl get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS test 1/1 Running 0 28m run=web2 web1 1/1 Running 0 30m run=web1 web2 1/1 Running 0 30m run=web2 # 只能解析ip,但是流量无法到达目标pod [root@master30 ~ 20:11:21]# kubectl exec test -- wget web1.web Connecting to web1.web (10.109.166.127:80) # 不同 namespace 中pod,即使标签满足也不可以访问 [root@master30 ~ 20:11:59]# kubectl exec test -n zy -- wget web1.web Connecting to web1.web (10.109.166.127:80)
示例2:允许同一namespace中所有pod访问具有标签run: web1的pod 80端口。
matchLabels中不使用任何标签,则允许同一ns中所有pod。
[root@master30 ~ 10:27:44]# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- podSelector: {}
# 或者将以上一行改为两行
# - podSelector:
# matchLabels:
ports:
- protocol: TCP
port: 80
# 应用策略
root@master30:~# kubectl apply -f netpol.yaml
# 同一namespace中所有pod都可以才访问web1
[root@master30 ~ 10:52:12]# kubectl exec test -- wget web1
Connecting to web1 (10.97.231.141:80)
saving to 'index.html'
index.html 100% |********************************| 11 0:00:00 ETA
'index.html' saved
[root@master30 ~ 10:52:21]# kubectl exec web2 -- curl web1
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11 100 11 0 0 5478 0 --:--:-- --:--:-- --:--:-- 11000
Hello web1
# 不同namespace中pod不可以访问web1
[root@master30 ~ 10:52:50]# kubectl exec test -n zy -- wget web1.web
Connecting to web1.web (10.97.231.141:80)
#卡在这不动
根据 pod 所属 ns 限定
用于限定,来源于其他namespace中pod。
示例1:允许具有标签project: myproject的namespace中所有pod,访问当前ns中具有标签run: web1的pod 80端口。
root@master30:~# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
project: myproject
ports:
- protocol: TCP
port: 80
# 应用策略 root@master30:~# kubectl apply -f netpol.yaml # 此时namespace-web中pod和namespace-laoma中pod都无法访问web1 [root@master30 ~ 10:55:02]# kubectl exec test -- wget web1 Connecting to web1 (10.97.231.141:80) [root@master30 ~ 10:55:21]# kubectl exec -n zy test -- wget web1.web Connecting to web1.web (10.97.231.141:80) # 给namespace-laoma添加标签project=myproject,此时namespace-laoma中pod可以访问web1.web [root@master30 ~ 10:57:39]# kubectl exec -n zy test -- wget web1.web Connecting to web1.web (10.97.231.141:80) saving to 'index.html' index.html 100% |********************************| 11 0:00:00 ETA 'index.html' saved
示例2:允许所有namespace中所有pod,访问当前ns中具有标签run: web1的pod 80端口。
root@master30:~# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector: {}
ports:
- protocol: TCP
port: 80
# 创建network policy [root@master30 ~ 10:58:38]# kubectl apply -f netpol.yaml networkpolicy.networking.k8s.io/my-network-policy configured # 所有namespace中所有pod都可以访问web1 [root@master30 ~ 11:01:31]# kubectl exec test -- wget web1 Connecting to web1 (10.97.231.141:80) saving to 'index.html' index.html 100% |********************************| 11 0:00:00 ETA 'index.html' saved [root@master30 ~ 11:02:59]# kubectl exec -n zy test -- wget web1.web Connecting to web1.web (10.97.231.141:80) saving to 'index.html' index.html 100% |********************************| 11 0:00:00 ETA 'index.html' saved
根据 pod IP 限定
示例1:允许网段172.17.0.0/16但不包括子网172.17.1.0/24中主机,访问具有标签run: web1的pod 80端口。
[root@master30 ~ 11:03:03]# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
# 放行 网段10.1.8.0/24
cidr: 10.1.8.0/24
# 不放行网段
except:
- 10.1.8.128/26
ports:
- protocol: TCP
port: 80
# 应用策略 [root@master30 ~ 11:03:39]# kubectl apply -f netpol.yaml networkpolicy.networking.k8s.io/my-network-policy configured # 访问失败 [root@master30 ~ 11:03:45]# kubectl exec test -- wget web1 Connecting to web1 (10.97.231.141:80) [root@master30 ~ 11:04:45]# kubectl exec -n zy test -- wget web1.web Connecting to web1.web (10.97.231.141:80) [root@master30 ~ 11:05:33]# kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE web1 NodePort 10.97.231.141 <none> 80:32657/TCP 15m web2 NodePort 10.103.247.154 <none> 80:31118/TCP 15m #只有访问32主机成功: [root@master30 ~ 11:05:42]# curl http://10.1.8.30:32657 ^C [root@master30 ~ 11:07:30]# curl http://10.1.8.31:32657 ^C [root@master30 ~ 11:07:35]# curl http://10.1.8.32:32657 Hello web1 #解释; NodePort 方式访问:节点 IP:32657 NodePort 流量流程: 客户端 → 节点宿主机内核 kube-proxy → DNAT 转发到后端 Pod NetworkPolicy 只作用于 Pod 容器网络,不管控宿主机 NodePort 层面的 DNAT 转发,且有一个限制: web1 Pod 跑在 worker32(10.1.8.32) 节点; 只有 Pod 所在节点 10.1.8.32:32657 转发后的源 IP 落在 10.1.8.0/24 网段,匹配你的 ipBlock 放行规则; 其他节点(master30、worker31)走 NodePort 转发时,流量经过跨节点网络,SNAT 源地址发生变化,不在你放行的 10.1.8.0/24 网段内,被 NetworkPolicy 拦截,访问卡住不通。 所以你出现: 10.1.8.32:32657 能正常访问 web1 10.1.8.30 / 10.1.8.31 同网段 NodePort 访问超时卡住 不是 NetworkPolicy 不完善,是NodePort 的 SNAT 源地址转换改变了来源 IP,导致规则匹配失效。 # 理论上:10.1.8.0/24网段中主机都可以通过集群任意节点访问web1 # 实际测试:只可以通过pod所在主机的IP访问web1 (10.1.8.32:30790),不可以访问10.1.8.30:30790或10.1.8.31:30790 [root@master30 ~ 11:07:39]# kubectl describe pod web1|grep Node: Node: worker32.zy.cloud/10.1.8.32
从实验测试结果来看,根据网段控制来源还不完善。
如果想放行所有主机,阻止部分主机,规则如下:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 10.1.8.0/26
限定所有端口
root@master30:~# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
run: test
# 应用策略 [root@master30 ~ 11:25:34]# kubectl apply -f netpol.yaml networkpolicy.networking.k8s.io/my-network-policy configured [root@master30 ~ 11:25:40]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES test 1/1 Running 0 33m 10.224.170.30 worker32.zy.cloud <none> <none> web1 1/1 Running 0 35m 10.224.170.8 worker32.zy.cloud <none> <none> web2 1/1 Running 0 35m 10.224.170.38 worker32.zy.cloud <none> <none> # 此时满足条件的pod可以ping通pod地址 [root@master30 ~ 11:31:35]# kubectl run --rm -it ubuntu -l run=test --image ubuntu --bash root@ubuntu:/# apt update root@ubuntu:/# apt install -y iputils-ping root@ubuntu:/# ping -c2 10.224.170.8 PING 10.224.170.8 (10.224.170.8) 56(84) bytes of data. 64 bytes from 10.224.170.8: icmp_seq=1 ttl=62 time=0.926 ms 64 bytes from 10.224.170.8: icmp_seq=2 ttl=62 time=0.348 ms --- 10.224.170.8 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.348/0.637/0.926/0.289 ms root@ubuntu:/# ping web1 -c2 PING web1.web.svc.cluster.local (10.97.231.141) 56(84) bytes of data. From web1.web.svc.cluster.local (10.97.231.141) icmp_seq=1 Destination Port Unreachable From web1.web.svc.cluster.local (10.97.231.141) icmp_seq=2 Destination Port Unreachable --- web1.web.svc.cluster.local ping statistics --- 2 packets transmitted, 0 received, +2 errors, 100% packet loss, time 1002ms root@ubuntu:/# exit # 仍然 ping不通 service,因为service只开放80端口
限定端口范围
root@master30:~# vim netpol.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
run: test
ports:
- protocol: TCP
port: 32000
endPort: 32768
限定项目所有pod
设置podSelector: {},则针对namespace中所有pod。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- from:
......
多条件规则
只要有一个满足条件就可以访问pod。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
namespace: web
spec:
podSelector:
matchLabels:
run: web1
policyTypes:
- Ingress
ingress:
- from:
- ipBlock:
cidr: 10.1.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
run: test
ports:
- protocol: TCP
port: 80
# 创建network policy root@master30:~# kubectl apply -f netpol.yaml # namespace-web中pod-test可以访问web1 root@master30:~# kubectl exec test -- wget web1 Hello web1
默认策略
默认允许所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- {}
默认拒绝所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
此策略可以确保即使容器没有选择其他任何 NetworkPolicy,也仍然可以被隔离。 此策略不会更改默认的出口隔离行为。
默认允许所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
policyTypes:
- Egress
egress:
- {}
默认拒绝所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被允许流出流量。 此策略不会更改默认的入站流量隔离行为。
默认拒绝所有入口和所有出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
此策略可以确保即使没有被其他任何 NetworkPolicy 选择的 Pod 也不会被 允许入站或出站流量。
无法完成的工作
-
特定于节点的策略。
-
基于名字的策略。
-
实现适用于所有命名空间或 Pods 的默认策略。
-
显式地拒绝策略的能力。NetworkPolicy 的模型默认采用拒绝操作, 其唯一的能力是添加允许策略。
-
禁止本地回路或指向宿主的网络流量。Pod 目前无法阻塞 localhost 访问, 它们也无法禁止来自所在节点的访问请求)。
环境清理
root@master30:~# kubectl delete ns network web zy root@master30:~# kubectl delete ns web root@master30:~# kubectl delete ns zy
Kubernetes Pod Scheduler
学习参考:调度、抢占和驱逐
环境准备
[root@master30 ~ 11:36:48]# kubectl create ns scheduler namespace/scheduler created [root@master30 ~ 11:37:20]# kubectl config set-context --current --namespace scheduler Context "cluster1-context" modified.
调度介绍
Kubernetes 调度是指将 Pod 放置到合适的节点上的过程。
kube-scheduler 是 Kubernetes 集群的默认调度器,通过监测(Watch)机制发现集群中未被调度到节点上的 Pod,并将这些未调度的 Pod 调度到一个合适的节点上来运行。
调度过程
Kube-scheduler 选择一个最佳节点来运行新创建的或尚未调度(unscheduled)的 Pod。 由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的节点。
调度术语:
-
满足 Pod 调度请求的所有节点称之为 可调度节点。
-
调度器将 pod 调度到特定节点的这个过程叫做 绑定。
Kubernetes 调度过程:
-
过滤,将满足 Pod 调度需求的所有节点选出来。 例如,PodFitsResources 过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。如果这个列表是空的,代表这个 Pod 不可调度。
-
打分,根据当前启用的打分规则,调度器会给每一个可调度节点进行打分,调度器将 Pod 调度到得分最高的节点上。 如果存在多个得分最高的节点,kube-scheduler 会从中随机选取一个。
在做调度决定时需要考虑的因素包括:
-
单独和整体的资源请求
-
硬件/软件/策略限制
-
亲和以及反亲和要求
-
数据局部性
-
负载间的干扰
-
等等。
kubernetes 使用以下两种方式配置调度器的过滤和打分行为:
-
调度策略,配置过滤所用的 断言(Predicates) 和打分所用的 优先级(Priorities)。
-
调度配置,允许配置实现不同调度阶段的插件, 包括:
QueueSort、Filter、Score、Bind、Reserve、Permit等等。
过滤
以下断言(Predicates)用于主机过滤:
-
PodFitsHostPorts:检查节点是否有空闲端口(网络协议类型)用于 Pod 请求的 Pod 端口。 -
PodFitsHost:检查 Pod 是否通过其主机名指定特定节点。 -
PodFitsResources: 检查 Node 是否有空闲资源(例如 CPU 和内存)来满足 Pod 的要求。 -
NoVolumeZoneConflict: 评估是否 卷 考虑到该存储的故障区域限制,Pod 请求在节点上可用。 -
NoDiskConflict:评估 Pod 是否可以根据它请求的卷以及已经挂载的卷安装在节点上。 -
MaxCSIVolumeCount: 决定多少 CSI 应附加卷,以及是否超过配置的限制。 -
PodToleratesNodeTaints: 检查Pod 的 toleration 可以容忍节点的 taints。 -
CheckVolumeBinding:评估 Pod 是否因它请求的卷而适合。这适用于绑定和未绑定 PVCs.
计分
以下 优先级 Priorities 用于主机评分:
-
SelectorSpreadPriority: 跨主机传播 Pod,考虑属于相同的 Pod 服务, 状态集 或者 副本集。 -
InterPodAffinityPriority:实现首选的 pod 间亲和性和反亲和性。 -
LeastRequestedPriority:支持请求资源较少的节点。换句话说,节点上放置的 Pod 越多,这些 Pod 使用的资源越多,该策略给出的排名就越低。 -
MostRequestedPriority:支持请求资源最多的节点。此策略将使计划的 Pod 适合运行整个工作负载集所需的最少数量的节点。 -
RequestedToCapacityRatioPriority:使用默认资源评分函数形状创建基于 requestsToCapacity 的 ResourceAllocationPriority。 -
BalancedResourceAllocation:支持资源使用均衡的节点。 -
NodePreferAvoidPodsPriority:根据节点注释对节点进行优先级排序scheduler.alpha.kubernetes.io/preferAvoidPods。您可以使用它来暗示两个不同的 Pod 不应在同一个节点上运行。 -
NodeAffinityPriority:根据PreferredDuringSchedulingIgnoredDuringExecution 中指示的节点关联性调度首选项对节点进行优先级排序。您可以在将 Pod 分配给节点中阅读更多相关信息。 -
TaintTolerationPriority:根据节点上不可容忍污点的数量,为所有节点准备优先级列表。此策略会在考虑该列表的情况下调整节点的等级。 -
ImageLocalityPriority: 优先选择已经拥有 容器镜像 对于本地缓存的 Pod。 -
ServiceSpreadingPriority:对于给定的 Service,此策略旨在确保 Service 的 Pod 运行在不同的节点上。它倾向于调度到没有已分配服务的 Pod 的节点上。总体结果是服务对单个节点故障变得更有弹性。 -
EqualPriority:给所有节点一个相等的权重。 -
EvenPodsSpreadPriority:实现首选 pod 拓扑扩展约束。
控制 pod 运行位置
参考学习:将 Pod 指派给节点
你可以约束一个 Pod 只能在特定的 节点 上运行。 通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将 Pod 分散到节点上, 而不是将 Pod 放置在可用资源不足的节点上等等)。不过有些情况我们希望将Pod部署到指定的Node, 比如将有大量磁盘I/O的Pod部署到配置了SSD的Node; 或者Pod需要GPU, 需要运行在配置了GPU的节点上。
你可以使用下列方法中的任何一种来选择 Kubernetes 对特定 Pod 的调度:
-
与节点名匹配的 nodeName :
nodeName —— 直接点名指定节点 最简单粗暴的方式:直接在 Pod 配置里写死要运行的节点名称,调度器会直接跳过,强制放到这个节点上。 类比:你直接说「我就要坐 3 号楼 201 办公室」,不考虑任何其他因素。
-
与节点标签匹配的 nodeSelector:
nodeSelector —— 按节点标签筛选 比 nodeName 灵活:先给节点打上自定义标签(比如 disktype=ssd、gpu=true),然后在 Pod 里指定「只调度到带这个标签的节点上」。 类比:你不说具体哪栋楼,只说「我要带 SSD 高速硬盘的楼」,所有符合的楼都可以选。
-
亲和性与反亲和性 —— 最灵活的高级调度 这是生产环境最常用的高级调度能力,解决了 nodeSelector 表达力不够的问题。核心分两类: 节点亲和性:Pod 和节点的关系 ——「我要 / 不要什么样的节点」; Pod 间亲和性 / 反亲和性:Pod 和其他 Pod 的关系 ——「我要 / 不要和哪些 Pod 挨在一起」。 每一类都支持两种强度: 硬约束(required...):必须满足,不满足就一直 Pending,相当于增强版 nodeSelector; 软约束(preferred...):尽量满足,实在满足不了也能调度,只是优先级低一点。 所有规则后缀都带 IgnoredDuringExecution,意思是:Pod 跑起来之后,就算节点标签变了,Pod 也不会被赶走,继续在上面运行。
-
Pod 拓扑分布约束 —— 均匀分布提升高可用 专门解决「Pod 扎堆」问题:让你的 Pod 均匀分布在不同故障域(节点、可用区、地域)里,是实现高可用的重要手段。 类比:你有 6 个副本、3 个可用区,理想状态是每个区 2 个;拓扑约束就是保证「最多 Pod 的区 和 最少 Pod 的区,数量差不超过你设定的值」。
1.nodeName
nodeName 是 PodSpec 的一个字段,其值是节点名称,调度器将Pod调度到给定节点上运行 。
nodeName 是节点选择约束的最简单方法,也是优先级最高的方法,通常不使用。
使用 nodeName 选择节点的一些限制:
-
如果指定的节点不存在,Pod 将不会运行,甚至会被自动删除。
-
如果指定的节点没有资源来容纳 Pod,Pod 将会调度失败,并且显示实际原因。
例如:OutOfmemory 或 OutOfcpu。
-
云环境中的节点名称并非总是可预测或稳定的。
示例:
示例:
root@master30:~# kubectl create deployment webapp --image nginx --replicas 5 -o yaml --dry-run=client > deploy-webapp.yaml
#这个命令用于生成一个 Kubernetes Deployment 的 YAML 配置文件,而不会实际创建任何资源。它非常适合在正式部署前预览或定制资源配置。这个命令能“凭空”生成 YAML,本质上是 kubectl 这个客户端工具在本地内存中“虚拟”构造了一个 Kubernetes 对象,然后将其序列化打印出来,并主动终止了发送给 API Server 的创建请求。
#可以看到生成了对应要求的模板
[root@master30 ~ 13:56:18]# cat deploy-webapp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: webapp
name: webapp
spec:
replicas: 5
selector:
matchLabels:
app: webapp
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: webapp
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
#在刚才deploy-webapp.yaml文件的基础上修改:
root@master30:~# vim deploy-webapp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: webapp
name: webapp
spec:
replicas: 5
selector:
matchLabels:
app: webapp
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: webapp
spec:
# 添加nodeName配置
nodeName: worker31.zy.cloud
containers:
- image: nginx
name: nginx
resources: {}
status: {}
[root@master30 ~ 13:59:30]# kubectl apply -f deploy-webapp.yaml deployment.apps/webapp created #可以发现创建的pod都在worker31节点上面; [root@master30 ~ 14:00:37]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES webapp-c7589b895-2lp79 1/1 Running 0 32s 10.224.215.189 worker31.zy.cloud <none> <none> webapp-c7589b895-4xchs 1/1 Running 0 32s 10.224.215.185 worker31.zy.cloud <none> <none> webapp-c7589b895-6rv2x 1/1 Running 0 32s 10.224.215.182 worker31.zy.cloud <none> <none> webapp-c7589b895-rsdr9 1/1 Running 0 32s 10.224.215.132 worker31.zy.cloud <none> <none> webapp-c7589b895-xjkb7 1/1 Running 0 32s 10.224.215.136 worker31.zy.cloud <none> <none>
2.nodeSelector
nodeSelector 是 PodSpec 的一个字段。 它包含键值对的映射。为了使 pod 可以在某个节点上运行,该节点的标签中 必须包含这里的每个键值对(它也可以具有其他标签)。
最常见的用法的是使用label。label是key-value对, 各种资源都可以设置label, 灵活添加各种自定义属性。
提示:nodeSelector 是节点选择约束的推荐形式。
# 查看node标签 [root@master30 ~ 14:00:41]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS master30.zy.cloud Ready control-plane 7d23h v1.30.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master30.zy.cloud,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= worker31.zy.cloud Ready <none> 7d23h v1.30.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=worker31.zy.cloud,kubernetes.io/os=linux worker32.zy.cloud Ready <none> 7d23h v1.30.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=worker32.zy.cloud,kubernetes.io/os=linux # 标注worker31 disktype是ssd [root@master30 ~ 14:02:02]# kubectl label nodes worker31.zy.cloud disktype=ssd node/worker31.zy.cloud labeled [root@master30 ~ 14:04:08]# kubectl get nodes -L disktype NAME STATUS ROLES AGE VERSION DISKTYPE master30.zy.cloud Ready control-plane 7d23h v1.30.2 worker31.zy.cloud Ready <none> 7d23h v1.30.2 ssd worker32.zy.cloud Ready <none> 7d23h v1.30.2
在Pod模板的spec里通过nodeSelector指定将此Pod部署到具有label为 disktype=ssd 的Node上。
root@master30:~# vim deploy-webapp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: webapp
name: webapp
spec:
replicas: 3 #修改副本数为3,原本5太多了
selector:
matchLabels:
app: webapp
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: webapp
spec:
# 添加 nodeSelector
nodeSelector:
disktype: ssd
containers:
- image: nginx
name: nginx
resources: {}
status: {}
root@master30:~# kubectl apply -f deploy-webapp.yaml #发现pod都在打标签为disktype=ssd的worker31节点 [root@master30 ~ 14:08:07]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES webapp-7d675f9d9c-92zkx 1/1 Running 0 95s 10.224.215.131 worker31.zy.cloud <none> <none> webapp-7d675f9d9c-c76n5 1/1 Running 0 94s 10.224.215.187 worker31.zy.cloud <none> <none> webapp-7d675f9d9c-p28cf 1/1 Running 0 95s 10.224.215.135 worker31.zy.cloud <none> <none> # 删除worker31标签,并不会在新的node上部署pod [root@master30 ~ 14:10:49]# kubectl label nodes worker31.zy.cloud disktype- node/worker31.zy.cloud unlabeled [root@master30 ~ 14:12:56]# kubectl get nodes -L disktype NAME STATUS ROLES AGE VERSION DISKTYPE master30.zy.cloud Ready control-plane 7d23h v1.30.2 worker31.zy.cloud Ready <none> 7d23h v1.30.2 worker32.zy.cloud Ready <none> 7d23h v1.30.2 #删除原先pod [root@master30 ~ 14:15:01]# kubectl get all NAME READY STATUS RESTARTS AGE pod/webapp-7d675f9d9c-92zkx 1/1 Running 0 8m32s pod/webapp-7d675f9d9c-c76n5 1/1 Running 0 8m31s pod/webapp-7d675f9d9c-p28cf 1/1 Running 0 8m32s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/webapp 3/3 3 3 14m NAME DESIRED CURRENT READY AGE replicaset.apps/webapp-7d675f9d9c 3 3 3 8m32s [root@master30 ~ 14:15:08]# kubectl delete replicasets.apps webapp-7d675f9d9c replicaset.apps "webapp-7d675f9d9c" deleted #重新执行验证效果: [root@master30 ~ 14:15:39]# kubectl apply -f deploy-webapp.yaml deployment.apps/webapp configured [root@master30 ~ 14:15:45]# kubectl get all NAME READY STATUS RESTARTS AGE pod/webapp-7d675f9d9c-5qzx6 0/1 Pending 0 10s pod/webapp-7d675f9d9c-l9gpc 0/1 Pending 0 10s pod/webapp-7d675f9d9c-sxg7j 0/1 Pending 0 10s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/webapp 0/3 3 0 15m NAME DESIRED CURRENT READY AGE replicaset.apps/webapp-7d675f9d9c 3 3 0 28s # 删除模版中nodeSelector属性,会自动触发重新部署。 这个实验揭示了nodeSelector在 Kubernetes 调度体系中的 3 个核心特性。结论如下: 1. 强制约束性(“硬调度”策略) 这是 nodeSelector 最根本的特性:它是 Pod 调度的“必答题”,且答案必须完全匹配(等于)。 • 当 Pod 模板中定义了 disktype: ssd,调度器会执行硬性过滤(RequiredDuringScheduling)。 • 在你的实验中,所有节点要么没有标签(worker31),要么标签值为空(worker32),没有任何节点能通过过滤。因此调度器直接给 Pod 打上 FailedScheduling 标记,将其搁置(Pending)。 • 与“软亲和性”的区别:如果是 nodeAffinity 的 preferredDuringScheduling(软策略),匹配不上顶多让调度器“不爽”,但依然会选个节点凑合跑。而 nodeSelector 匹配不上,Pod 宁愿永远挂起,也不会上线。 2. 生效时机仅限“Pod 创建时刻”(非动态感知) 这个实验让你直观地看到了 nodeSelector没有“动态漂移”能力: • 你在 Pod 处于 Pending 状态时,手动删除了 worker31 节点的标签(disktype-)。此时,那些 Pending 的 Pod 并没有因为节点标签变化而“重新计算”或“尝试调度到其他节点”。 • 原理:调度器只在 Pod 刚创建(首次进入队列)时进行一次节点筛选。一旦筛选失败进入 Pending,后续节点标签的增删改,不会自动触发调度器为该 Pod 重新评估(除非 Pod 被删除重建,或 Deployment 模板发生变化触发滚动更新)。 • 这说明了 nodeSelector 是一个静态声明,而不是一个动态监管机制。 3. 模板属性变更会触发 Deployment 的“级联更新” 这个实验最精彩的地方在于,它暴露了 nodeSelector 在 Workload 控制器(Deployment) 中的特殊地位: • nodeSelector 位于 .spec.template.spec 下,而 .spec.template 是 Deployment 的Pod 模板哈希值(pod-template-hash) 的计算源之一。 • 当你删除 nodeSelector 时,Deployment 控制器发现 Pod 模板变了(哈希值改变),自动执行滚动更新策略——新建一个 ReplicaSet,拉起没有约束的新 Pod,再销毁旧的 Pending Pod。 • 关键推论:这说明 nodeSelector 不仅影响调度,还直接影响 Pod 的生命周期管理。如果你只是想修复调度问题,修改 nodeSelector 意味着“重启应用”;而如果你直接给节点打上缺失的标签(kubectl label nodes ... disktype=ssd),Pod 会原地启动,不会触发滚动更新。 4. 隐含特性:节点标签变更不影响已运行的 Pod 虽然你的 Pod 处于 Pending(未运行),但如果它们已经在 worker31 上跑起来了,你执行 kubectl label nodes worker31 disktype- 删除标签,已经运行的那个 Pod 不会受到任何影响,依然会继续运行。 • nodeSelector 只在调度时起作用,一旦 Pod 绑定到节点(nodeName 确定),运行时的节点标签变化不会驱逐 Pod。这是为了防止因运维误删标签导致大面积服务中断。
3.Affinity and AntiAffinity(亲和性和反亲和性)
亲和性功能包含两种类型的亲和性,即“节点亲和性”和“Pod 间亲和性/反亲和性”。
Kubernetes Pod亲和性与节点亲和性对比:
一句话核心区分:
节点亲和:看节点身上的标签,决定 Pod 能不能上这台机器
Pod 亲和 / 反亲和:看集群里其他 Pod 身上的标签,决定当前 Pod 要不要跟它们放一块
一、节点亲和(nodeAffinity)
-
判断依据:节点的标签 ;只关心机器本身属性:有没有 GPU、SSD、属于哪个可用区、CPU 型号等。
-
作用:筛选机器池,先过滤掉不符合硬件 / 分区要求的节点。
-
匹配对象:Node
-
典型场景:
-
Pod 必须跑在带 GPU 标签的节点
-
只能部署在 zone-a、zone-b 可用区
-
-
关键词配置:
nodeAffinity,匹配节点标签,无 topologyKey
二、Pod 间亲和 / 反亲和(podAffinity /podAntiAffinity)
-
判断依据:其他 Pod 的标签 ;不看机器配置,只看别的 Pod 在哪、是什么业务。
-
作用:控制 Pod 之间的摆放位置,就近放或者分开放。
-
匹配对象:集群内其他 Pod
-
必须配套字段:
topologyKey,用来划定 “一块区域”(节点 / 可用区) -
典型场景:
-
web 和 redis 尽量放同一个可用区,减少网络延迟(podAffinity)
-
同一个服务副本不能放同一台机器,防止整机宕机(podAntiAffinity)
-
三、对比表格,一眼分清
| 对比项 | 节点亲和 nodeAffinity | Pod 间亲和 / 反亲和 podAffinity/AntiAffinity |
|---|---|---|
| 比对谁的标签 | 节点 Node 的标签 | 其他 Pod 的标签 |
| 核心目的 | 筛选符合硬件 / 区域条件的机器 | 控制 Pod 之间的摆放位置 |
| 是否需要 topologyKey | 不需要 | 必须写,划分区域范围 |
| 适用场景 | GPU、SSD、可用区筛选 | 业务就近部署、副本打散高可用 |
四、最简判断技巧(做题 / 排错直接用)
-
yaml 里写
nodeAffinity→ 节点亲和,看机器标签; -
yaml 里写
podAffinity/podAntiAffinity且带topologyKey→ Pod 亲和 / 反亲和,看别的 Pod 在哪。
3.1:nodeAffinity(节点亲和性)
-
和 nodeSelector 的关系
nodeSelector 只能写死硬性要求,功能单一;节点亲和性是 nodeSelector 的升级版,同样靠节点标签筛选机器,但分两种力度,规则写法更丰富。
-
两种节点亲和性分开讲
第一种:requiredDuringSchedulingIgnoredDuringExecution 硬性节点亲和
含义:硬性强制要求,调度 Pod 的时候,找不到符合标签规则的节点,Pod 就一直 pending,绝不随便找机器运行。效果和 nodeSelector 一模一样。 和 nodeSelector 区别: nodeSelector 只能写 “标签键 = 固定值”;硬性亲和支持 In/NotIn/Exists/Gt/Lt 多种判断逻辑,能写更复杂筛选条件。 举例:Pod 必须部署在 a、b 两个可用区,不在这两个区的节点直接全部淘汰。
第二种:preferredDuringSchedulingIgnoredDuringExecution 软性节点亲和 含义:优先推荐,不强制。调度器会给符合规则的节点额外加分,优先往这里放; 极端情况:集群里所有节点都不满足这条偏好规则,Pod 照样能调度到普通节点,不会卡住 pending; weight 权重:每条软规则可以设置 1~100 的权重,权重越高,对应节点加分越多,优先级越高。
注意:如果节点的标签在运行时发生变更,那么 Pod 将仍然继续在该节点上运行。
使用 Pod 规约中的 .spec.affinity.nodeAffinity 字段来设置节点亲和性。
示例:
[root@master30 ~ 14:29:11]# vim deploy-nodeaffinity.yaml
# 指定API版本,Deployment资源固定使用apps/v1
apiVersion: apps/v1
# 资源类型:无状态应用控制器Deployment
kind: Deployment
metadata:
# 给Deployment自身打标签,用于筛选资源
labels:
app: web
# Deployment控制器名称,同命名空间唯一
name: web
spec:
# 期望运行Pod副本数量为2个
replicas: 2
# Pod匹配标签,控制器只管理带app=web标签的Pod
selector:
matchLabels:
app: web
# Pod模板,控制器新建Pod时使用此模板
template:
metadata:
# 新建Pod自动打上app=web标签,和selector对应
labels:
app: web
spec:
# 调度亲和配置
affinity:
# 节点亲和规则
nodeAffinity:
# 硬性节点亲和:调度时必须满足规则,不满足则Pod一直Pending
requiredDuringSchedulingIgnoredDuringExecution:
# 节点匹配条件组,多组为或逻辑
nodeSelectorTerms:
- matchExpressions:
# 匹配节点标签键为CPU
- key: CPU
# 匹配运算符:标签值必须在列表内
operator: In
# 允许的标签值L1、L2
values:
- L1
- L2
# 软性节点亲和:仅做优先推荐,不强制,无符合节点也能正常调度
preferredDuringSchedulingIgnoredDuringExecution:
# 单条偏好规则,权重1,权重越高优先级越大
- weight: 1
preference:
matchExpressions:
# 匹配节点标签键为MEM
- key: MEM
operator: In
values:
- L1
- L2
# Pod内容器配置
containers:
# 第一个容器
- image: docker.io/library/nginx # 使用nginx官方镜像
name: nginx # 容器名称
示例说明:
-
此节点亲和性规则表示:Pod 只能放置在具有标签键
CPU且标签值为L1或L2的节点上。 另外,在满足这些标准的节点中,具有标签键为MEM且标签值为L1或L2的节点应该优先使用。 -
preferredDuringSchedulingIgnoredDuringExecution中的weight字段值的范围是 1-100。 对于每个符合所有调度要求(资源请求、RequiredDuringScheduling 亲和性表达式等) 的节点,调度器将遍历该字段的元素来计算总和,并且如果节点匹配对应的 MatchExpressions,则添加“权重”到总和。 然后将这个评分与该节点的其他优先级函数的评分进行组合。 总分最高的节点是最优选的。 -
你可以使用
operator字段来为 Kubernetes 设置在解释规则时要使用的逻辑操作符。operator(操作符)支持:In,NotIn,Exists,DoesNotExist,Gt,Lt。 -
你可以使用
NotIn和DoesNotExist来实现节点反亲和性行为,或者使用 节点污点 将 Pod 从特定节点中驱逐。 -
如果你同时指定了
nodeSelector和nodeAffinity,两者必须都要满足, 才能将 Pod 调度到候选节点上。 -
如果你指定了多个与
nodeAffinity类型关联的nodeSelectorTerms,则 如果其中一个nodeSelectorTerms满足的话,pod将可以调度到节点上。 -
如果你指定了多个与
nodeSelectorTerms关联的matchExpressions,则 只有当所有matchExpressions满足的话,Pod 才会可以调度到节点上。
如果你修改或删除了 pod 所调度到的节点的标签,Pod 不会被删除。 换句话说,亲和性选择只在 Pod 调度期间有效。
验证1:节点未打标签
[root@master30 ~ 14:53:59]# kubectl apply -f deploy-nodeaffinity.yaml deployment.apps/web created [root@master30 ~ 14:54:06]# kubectl get pods NAME READY STATUS RESTARTS AGE web-854cd4986-4bwsl 0/1 Pending 0 5s web-854cd4986-bvxj5 0/1 Pending 0 5s 验证1:硬性亲和(Required)—— “一票否决,绝不妥协” • 现象:节点没有 CPU 标签,Pod 全部 Pending。 • 原理说明:requiredDuringSchedulingIgnoredDuringExecution 是调度器的 “过滤器(Filter)”。调度器在预选阶段必须找到同时满足 CPU in (L1, L2)的节点,找不到就直接将 Pod 放入等待队列,不会因为软性规则(Preferred)存在而强行调度。 • 结论:硬性亲和是 Pod 调度的 “入场券”,满足则进,不满足则永远挂起。
验证2:节点打标签CPU
[root@master30 ~ 14:54:11]# kubectl label nodes worker31.zy.cloud CPU=L1 node/worker31.zy.cloud labeled [root@master30 ~ 14:55:30]# kubectl label nodes worker32.zy.cloud CPU=L2 node/worker32.zy.cloud labeled [root@master30 ~ 15:24:10]# kubectl get nodes -L CPU NAME STATUS ROLES AGE VERSION CPU master30.zy.cloud Ready control-plane 8d v1.30.2 worker31.zy.cloud Ready <none> 8d v1.30.2 L1 worker32.zy.cloud Ready <none> 8d v1.30.2 L2 [root@master30 ~ 14:59:51]# kubectl get pods NAME READY STATUS RESTARTS AGE web-854cd4986-4bwsl 1/1 Running 0 5m48s web-854cd4986-bvxj5 1/1 Running 0 5m48s #如果节点资源负载差异明显,调度器会倾向于将新 Pod 集中调度到低负载节点。 #只有当所有节点负载相近时,才可能出现“随机分布”的效果,但也不是严格均分。 [root@master30 ~ 15:01:40]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-854cd4986-4bwsl 1/1 Running 0 7m37s 10.224.215.183 worker31.zy.cloud <none> <none> web-854cd4986-bvxj5 1/1 Running 0 7m37s 10.224.215.181 worker31.zy.cloud <none> <none> 验证2:硬性满足 + 软性缺失 —— “资源均衡优先” 现象:打了 CPU 标签后,Pod 成功运行,但全部挤在 worker31(低负载节点)。 原理说明: 此时两个节点都通过了硬性过滤(31有L1,32有L2)。 但 MEM 软性亲和(Preferred)因为两个节点都没打标签,得分为 0。 调度器进入 “打分(Score)” 阶段,在没有软性分差的情况下,默认内置插件(如 NodeResourcesFit) 占据了主导。它发现 worker31 比 worker32 更空闲(worker32 上跑着 Ingress 等多个业务 Pod),于是给 worker31 打了更高的分,两个 Pod 都被“最优解” worker31 吸引过去。 结论:调度器不负责“均匀分布”,只负责“资源最优”。在软性约束缺失时,负载最低的节点会成为“黑洞”。
验证3:worker32节点打标签MEM
[root@master30 ~ 15:19:04]# kubectl label nodes worker32.zy.cloud MEM=L2
node/worker32.zy.cloud labeled
[root@master30 ~ 15:29:26]# kubectl get nodes -L MEM
NAME STATUS ROLES AGE VERSION MEM
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2 L2
# 重新部署
[root@master30 ~ 15:22:19]# kubectl rollout restart deployment.app web
deployment.apps/web restarted
# 只在worker32上运行
[root@master30 ~ 15:22:45]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
web-9d56c8d8d-7zj96 Running worker32.zy.cloud
web-9d56c8d8d-zs7tr Running worker32.zy.cloud
验证3:硬性满足 + 软性匹配 —— “软性偏好逆转调度结果”
• 现象:给 worker32 打上 MEM=L2 并重启 Deployment 后,Pod 全部转向了 worker32。
• 原理说明(这是本实验的高潮):
◦ 重启后,调度器重新为所有 Pod 执行全流程调度。
◦ 硬性过滤:两个节点依旧都满足(31有CPU=L1,32有CPU=L2)。
◦ 打分阶段(关键变化):
■ worker31:只命中硬性(CPU),未命中软性(无 MEM),软性得分 = 0。
■ worker32:既命中硬性(CPU=L2),又命中软性(MEM=L2)。根据你的 YAML,preferredDuringScheduling 的 weight: 1 会为 worker32 额外增加 1 分。
◦ 虽然权重只有 1,但在两个节点基础资源分相差不大的情况下,这 1 分足以让 worker32 的总分超过 worker31。调度器选择总分最高的 worker32,因此两个新 Pod 全部落到了 worker32 上。
• 结论:preferredDuringScheduling 是“加分项”。当硬性条件都满足时,软性亲和可以改变最终的调度倾向,甚至是扭转乾坤。
清理环境
root@master30:~# kubectl delete deployments.apps web root@master30:~# kubectl label nodes worker31.zy.cloud CPU- root@master30:~# kubectl label nodes worker32.zy.cloud CPU- root@master30:~# kubectl label nodes worker32.zy.cloud MEM-
节点亲和性权重
用户可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置 weight 字段,其取值范围是 1 到 100。 当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则, 并将对应表达式的 weight 值加和。
最终的加和值会添加到该节点的其他优先级函数的评分之上。 在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
例如,考虑下面的 Pod 规约:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: docker.io/library/nginx
如果存在两个候选节点,都满足 preferredDuringSchedulingIgnoredDuringExecution 规则, 其中一个节点具有标签 label-1: key-1,另一个节点具有标签 label-2: key-2, 调度器会考察各个节点的 weight 取值,并将该权重值添加到节点的其他得分值之上。
3.2:Inter-pod affinity and anti-affinity(pod间亲和性和反亲和性)
Pod 亲和(podAffinity):希望当前 Pod 和 已有指定标签的 Pod 放在同一范围(节点 / 可用区),就近部署,减少网络延迟。 Pod 反亲和(podAntiAffinity):希望当前 Pod 和 已有指定标签的 Pod 分开部署,不挤在一起,防止单节点故障全挂,提升高可用。
关键字段 topologyKey 划定 “同一块区域” 的范围: kubernetes.io/hostname:同一台节点机器 topology.kubernetes.io/zone:同一个可用区
Pod 间 亲和性 和 反亲和性 提供基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
Pod 间亲和性与反亲和性规则的格式为,如果 X 节点上已经运行了一个或多个满足规则 Y 的 Pod:
-
在亲和性的情况下,Pod 应该运行在 X 节点。
-
在反亲和性的情况下,Pod 不应该运行在 X 节点。
说明:
-
这里的 X 可以是节点、机架、云提供商可用区或地理区域或类似的拓扑域。你可以使用
topologyKey来表示它,topologyKey是节点标签的键以便系统 用来表示这样的拓扑域。 -
Y 则是 Kubernetes 尝试满足的规则,通过标签选择算符 的形式来表达规则(Y)。
注意:
-
Pod 间亲和性与反亲和性会消耗大量计算资源,可能会显著减慢大规模集群中的调度。 我们不建议在超过数百个节点的集群中使用它们。
-
Pod 反亲和性需要对节点进行一致的标记,即集群中的每个节点必须具有适当的标签匹配
topologyKey。如果某些或所有节点缺少指定的topologyKey标签,可能会导致意外行为。
Pod 间亲和性与反亲和性的类型,和节点亲和一样分两种强度:
-
requiredDuringSchedulingIgnoredDuringExecution:例如将两个通信非常频繁的 Pod 调度到同一个可用区内。硬规则,不满足就 Pending -
preferredDuringSchedulingIgnoredDuringExecution:例如将同一服务的多个 Pod 调度到不同可用区中。软规则,优先满足,不满足也能调度
使用 Pod 规约中的 .affinity.podAffinity 字段设置Pod 间亲和性。
使用 Pod 规约中的 .affinity.podAntiAffinity 字段设置Pod 间反亲和性。
语法说明
本示例定义了一条 Pod 亲和性规则和一条 Pod 反亲和性规则。
root@master30:~# vim pod-with-podaffinity.yaml
# 核心API版本,Pod资源固定v1
apiVersion: v1
# 资源类型:单个Pod
kind: Pod
metadata:
# Pod名称
name: pod-with-podaffinity
spec:
# 亲和调度配置
affinity:
# Pod亲和规则:想和指定Pod放在同一区域
podAffinity:
# 硬性规则:必须满足,找不到符合条件可用区Pod就Pending
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
# 匹配目标Pod标签
matchExpressions:
- key: security # 匹配标签key=security
operator: In # 标签值属于下面列表
values:
- S1 # 目标Pod标签 security=S1
# 判定范围:同一个可用区才算同一区域
topologyKey: topology.kubernetes.io/zone
# Pod反亲和:尽量不和指定Pod放同一区域
podAntiAffinity:
# 软性规则:优先避开,实在没办法也能调度进去
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 # 权重100,规避这条规则优先级极高
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2 # 避开标签 security=S2 的Pod
topologyKey: topology.kubernetes.io/zone
# 容器配置
containers:
- name: pod-with-podaffinity
image: docker.io/library/nginx
一、podAffinity 硬性规则解读 约束对象:集群中带有标签 security=S1 的其他 Pod 范围 topologyKey: topology.kubernetes.io/zone:按可用区划分区域 硬性要求: 新 Pod 只能部署在已经存在 security=S1 Pod 的可用区; 如果所有可用区都没有 security=S1 的 Pod,此 Pod 一直处于 Pending,不会启动。 IgnoredDuringExecution:Pod 运行后,就算该可用区的 S1 Pod 被删除,本 Pod 也不会被驱逐。
二、podAntiAffinity 软性规则解读 规避对象:集群带有标签 security=S2 的 Pod 范围同样是可用区 zone 软约束逻辑: 筛选出满足上面亲和要求的可用区后,调度器优先挑选没有 security=S2 Pod 的可用区; weight=100 代表这条偏好权重拉满,能避开就一定会避开。 极端情况:所有存在 S1 Pod 的可用区全都同时跑了 S2 Pod,Pod 依旧能正常调度,不会卡住。
补充说明:
一、Pod 亲和 / 反亲和里能用的 4 个标签匹配操作符
只允许写这 4 种,别的符号语法不识别,分别作用:
-
In目标 Pod 标签的 value,必须在你写的 values 列表里。 例:key=security, In, [S1] → 只匹配标签 security=S1 的 Pod -
NotIn目标 Pod 标签的 value,不能出现在列表里。 例:key=security, NotIn, [S2] → 排除 security=S2 的 Pod -
Exists只要求 Pod 存在这个标签 key,不在乎标签值是什么,不用写 values。 例:key=security, Exists → 只要 Pod 有 security 标签就匹配 -
DoesNotExist要求 Pod没有这个标签 key,不用写 values。 例:key=security, DoesNotExist → 匹配不带 security 标签的 Pod
二、topologyKey 是什么
拓扑键,用来划定「同一区域」的范围,判断两个 Pod 算不算挨在一起。 常用自带标签:
-
kubernetes.io/hostname:同一台节点机器算一块区域 -
topology.kubernetes.io/zone:同一个可用区算一块区域 你自己给节点打的自定义标签,也能当 topologyKey,比如 rack=rack01(机柜)。
三、topologyKey 强制限制规则
-
不管是 podAffinity(Pod 亲和)还是 podAntiAffinity(Pod 反亲和) 不管你写的是硬规则
requiredDuringSchedulingIgnoredDuringExecution,还是软规则preferredDuringSchedulingIgnoredDuringExecutiontopologyKey 这一行必须写,不能空、不能删掉。 不写会直接报 yaml 语法错误,Pod 创建失败。 -
补充一句话:只要是写 Pod 亲和、Pod 反亲和规则,每条规则都必须指定 topologyKey,没有例外,不存在可以省略的场景。
示例 1:根据节点拓扑--亲和性调度
# node节点打标签
#给节点 worker31.zy.cloud和32 打一个可用区拓扑标签:
#标签键:topology.kubernetes.io/zone
#标签值:v
[root@master30 ~ 16:18:08]# kubectl label nodes worker31.zy.cloud topology.kubernetes.io/zone=v
node/worker31.zy.cloud labeled
[root@master30 ~ 16:25:47]# kubectl label node worker32.zy.cloud topology.kubernetes.io/zone=v
node/worker32.zy.cloud labeled
# 创建两个pod
root@master30:~# vim pod-with-podaffinity.yaml
# API版本,Pod资源固定使用v1
apiVersion: v1
# 资源类型,代表创建单个Pod
kind: Pod
metadata:
# Pod名称为web
name: web
# 给当前Pod打上标签,app=web,作为后面亲和规则匹配的目标
labels:
app: web
spec:
# Pod内容器配置
containers:
# 第一个容器配置
- name: nginx # 容器名字叫nginx
image: docker.io/library/nginx # 使用nginx官方镜像启动容器
imagePullPolicy: IfNotPresent # 本地有镜像就不从仓库拉取,加速启动
# 强制固定此Pod运行在worker31.laoma.cloud节点,作为参照Pod
nodeName: worker31.laoma.cloud
---
# 分隔符,同一个文件定义第二个资源
# API版本
apiVersion: v1
# 资源类型Pod
kind: Pod
metadata:
# 第二个Pod名称
name: pod-with-podaffinity
spec:
# 亲和调度配置块
affinity:
# Pod间亲和配置,根据其他Pod的标签调度
podAffinity:
# 硬性约束:调度时必须满足规则,不满足Pod就pending
requiredDuringSchedulingIgnoredDuringExecution:
# 单条亲和规则
- labelSelector:
# 匹配其他Pod标签的条件
matchExpressions:
# 匹配标签键为app
- key: app
# 匹配运算符,标签值在给定列表内才算匹配
operator: In
# 匹配值为web,即匹配标签app=web的Pod
values:
- web
# 拓扑域划分依据,以节点可用区作为同一区域判断标准
topologyKey: topology.kubernetes.io/zone
# 当前Pod的容器配置
containers:
- name: web # 容器名称web
image: docker.io/library/nginx # 使用nginx镜像运行
[root@master30 ~ 16:28:05]# kubectl apply -f pod-with-podaffinity.yaml
pod/web created
pod/pod-with-podaffinity created
[root@master30 ~ 16:28:11]# kubectl describe pod pod-with-podaffinity |grep Node:
Node: worker31.zy.cloud/10.1.8.31
实验结果:pod-with-podaffinity 调度到 worker31节点。
如果此时将work31节点的 topology.kubernetes.io/zone 标签删除,重新创建pod pod-with-podaffinity,会调度到哪个节点呢?
[root@master30 ~ 16:36:21]~# kubectl delete -f pod-with-podaffinity.yaml --force [root@master30 ~ 16:36:21]# kubectl label nodes worker31.zy.cloud topology.kubernetes.io/zone- node/worker31.zy.cloud unlabeled [root@master30 ~ 16:37:12]# kubectl apply -f pod-with-podaffinity.yaml pod/web created pod/pod-with-podaffinity created [root@master30 ~ 16:37:24]# kubectl describe pod pod-with-podaffinity |grep Node: Node: worker32.zy.cloud/10.1.8.32 # 清理环境 root@master30 ~ 16:38:17]# kubectl delete -f pod-with-podaffinity.yaml root@master30 ~ 16:38:17]# kubectl label nodes worker31.zy.cloud topology.kubernetes.io/zone-
实验结论:
实验说明的 4 个核心知识点,大白话总结 1. topologyKey 靠节点标签划分区域,不是靠 Pod 判断两个 Pod 算不算 “同一区域”,完全看节点有没有 topology.kubernetes.io/zone=v 这个标签: worker31 删掉 zone 标签后,哪怕上面跑了 app=web 的 Pod,它也不属于 v 可用区; worker32 保留 zone 标签,单独成为 v 可用区。 2. Pod 硬性亲和的匹配逻辑:同一拓扑域内存在目标 Pod 才算满足 规则要求新 Pod 要放在存在 app=web Pod 的 zone=v 区域: 一开始两台节点都带 zone=v,web 在 worker31(属于 v 域),所以新 Pod 能调度到 worker31; 删除 worker31 的 zone 标签后,web 所在机器不再属于 v 域,v 域只剩 worker32; 集群里确实存在 app=web 的 Pod,所以 v 域合法,新 Pod 只能选 worker32。 3. Pod 亲和生效必须同时满足两个前提(实验结论) 少任意一个,Pod 都会 Pending 无法调度: 节点要有 topologyKey 对应的标签(本例 zone=v),用来划分拓扑域; 集群里必须存在匹配 labelSelector 的 Pod(本例 app=web)。 4. topology 域是隔离独立的,跨域不算满足条件 哪怕集群别的节点有目标 Pod,但不在同一个拓扑标签域,调度器不认。 本案例中 web 跑到无 zone 标签的节点,和 worker32 不属于同一个域,worker32 只会因为 “集群存在 web Pod” 成为唯一可选节点。 5. 实操使用价值 静态 Pod 仅适合做实验验证规则; 生产搭配 Deployment/StatefulSet 控制器使用更有意义:批量让关联服务(web+redis)部署在同一个可用区,减少跨区网络延迟;配合反亲和还能打散副本提升容灾能力。 一句话概括实验核心 Pod 间亲和是按节点拓扑标签划分区域做匹配,只要集群存在目标标签 Pod,新 Pod 就会被调度到同拓扑标签的节点;如果目标 Pod 所在节点丢失拓扑标签,二者不再属于同一区域,调度器会选择其他带相同拓扑标签的节点。
示例 2:根据节点主机名--反亲和性调度
下面是一个简单 redis Deployment 的 YAML 代码段,它有三个副本和选择器标签 app=store。 Deployment 配置了 PodAntiAffinity,用来确保调度器不会将多个副本调度到单个节点上。
# 准备deployment root@master30:~# vim deploy-with-podAntiAffinity.yaml
# Deployment资源固定api版本
apiVersion: apps/v1
# 资源类型:无状态应用控制器Deployment
kind: Deployment
metadata:
# Deployment控制器名称
name: store
spec:
# 控制器匹配Pod标签,只管理带app=store的Pod
selector:
matchLabels:
app: store
# 期望运行3个Pod副本
replicas: 3
# Pod模板,新建Pod都套用下面配置
template:
metadata:
# 创建出的Pod自动打上标签app: store
labels:
app: store
spec:
# 亲和调度配置
affinity:
podAntiAffinity: #代表 Pod 反亲和,含义:不要和匹配到的 Pod 放在同一拓扑域。
requiredDuringSchedulingIgnoredDuringExecution: # 硬性强制约束,不满足条件Pod会Pending无法调度
- labelSelector: # 单条反亲和规则,匹配所有标签 app=store 的 Pod,也就是本业务自己的副本。
# 匹配其他Pod的标签条件
matchExpressions:
# 匹配标签key为app
- key: app
# 运算符In:标签值在列表内则匹配成功
operator: In
# 匹配app=store的Pod
values:
- store
# 拓扑范围:kubernetes.io/hostname代表同一台节点机器
topologyKey: "kubernetes.io/hostname"
# Pod内部容器配置
containers:
# 容器配置项
- name: web-server # 容器名称
image: docker.io/library/nginx # 使用nginx镜像启动
核心规则人话解释:
硬性 Pod 反亲和,拓扑范围按单台节点区分:
同一台机器上,最多只能运行 1 个 app=store 的 Pod。(硬性要求 ——同一台节点(hostname)内,不能同时存在两个及以上 app=store 的 Pod,所以同一机器最多只能跑 1 个 store Pod。)
当前副本数 3,集群至少要有 3 台不同节点才能正常启动全部 Pod;如果节点少于 3 个,多余 Pod 会一直 Pending。
作用:避免单节点宕机导致整个 store 服务全部不可用,提升高可用。
# 查看pod调度情况
[root@master30 ~ 18:39:31]# kubectl apply -f deploy-with-podAntiAffinity.yaml
deployment.apps/store created
[root@master30 ~ 18:39:46]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
store-5596cf4c84-866gk Pending <none>
store-5596cf4c84-bft6m Running worker31.zy.cloud
store-5596cf4c84-r4bdp Running worker32.zy.cloud
结果:在 topologyKey: "kubernetes.io/hostname作用下,每个节点只能运行一个pod。因为每个节点的hostname都是自己的主机名,是唯一的。最后一个pod,找不到可用节点。
示例 3:多个应用亲和性和反亲和性调度
下面 webserver Deployment 的 YAML 代码段中配置了 podAntiAffinity 和 podAffinity,确保每个 web 服务器副本不会调度到单个节点上,同时所有副本与具有 app=store 选择器标签的 Pod 放置在一起。
# 缩容 deployment
[root@master30 ~ 18:39:54]# kubectl scale deployment store --replicas 1
deployment.apps/store scaled
[root@master30 ~ 18:47:23]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
store-5596cf4c84-bft6m Running worker31.zy.cloud
# 准备新deployment
root@master30:~# vim deploy-with-multi-Affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-store
spec:
selector:
matchLabels:
app: web-store
replicas: 1
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: docker.io/library/nginx
[root@master30 ~ 18:47:59]# kubectl apply -f deploy-with-podAntiAffinity.yaml
deployment.apps/web-store created
[root@master30 ~ 18:48:17]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
store-5596cf4c84-bft6m Running worker31.zy.cloud
web-store-7b4779c958-q4ww5 Running worker31.zy.cloud
# 扩容:验证新副本位置
[root@master30 ~ 18:50:16]# kubectl scale deployment web-store --replicas 2
deployment.apps/web-store scaled
[root@master30 ~ 18:55:09]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
store-5596cf4c84-bft6m Running worker31.zy.cloud
web-store-7b4779c958-q4ww5 Running worker31.zy.cloud
web-store-7b4779c958-sxtnq Pending <none>
#进一步扩容再验证:
[root@master30 ~ 18:57:24]# kubectl scale deployment web-store --replicas 5
deployment.apps/web-store scaled
[root@master30 ~ 19:02:09]# kubectl get pods -o wide --no-headers |awk '{print $1,$3,$7}'
store-5596cf4c84-bft6m Running worker31.zy.cloud
web-store-7b4779c958-jnr7n Pending <none>
web-store-7b4779c958-q4ww5 Running worker31.zy.cloud
web-store-7b4779c958-q9j9k Pending <none>
web-store-7b4779c958-r824q Pending <none>
web-store-7b4779c958-sxtnq Pending <none>
# 在亲和性作用下,只有worker31节点具备满足条件的pod
# 在反亲和性作用下,worker31节点上已经运行了一个副本
# 最终结果:第二个(甚至3、4.....) pod 都会pending 挂起。
Taint 和 Toleration
学习参考:污点和容忍度
-
node 使用 Taint(污点),允许特定Pod在本机运行,未匹配的Pod则不能在该节点运行。
-
pod 使用 Toleration(容忍度),允许被调度到带有与之匹配的污点的节点上。
污点和容忍度相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。
思考:nodeAffinity 和 Taint 区别?
-
nodeAffinity,Pod 选 Node 的必要条件。
-
Taint,Node 选 Pod 的必要条件。
两者关系就像男女相亲。例如:
-
女选男,首选挣钱多多,类似于 nodeAffinity;长得丑没关系,类似于Taint。
-
男选女,首选长的漂亮,类似于 nodeAffinity;挣钱少没关系,类似于Taint。
设置 Node Taints(污点)
使用命令 kubectl taint 给节点增加一个污点。
示例:给节点 worker31.laoma.cloud 增加一个污点,键名 CPU,键值 L1,效果 NoSchedule。
[root@master30 ~ 19:06:39]# kubectl taint node worker31.zy.cloud CPU=L1:NoSchedule node/worker31.zy.cloud tainted
表示拥有和这个污点相匹配的tolerations的 Pod 才能够被分配到 worker31.laoma.cloud 这个节点。
若要移除worker污点,执行以下命令:
[root@master30 ~ 19:07:36]# kubectl taint node worker31.zy.cloud CPU:NoSchedule- node/worker31.zy.cloud untainted
设置 Pod tolerations(容忍度)
先搞懂两个基础概念
-
节点污点 taint:打在节点上的「排斥标记」,用来拒绝 Pod 调度、驱逐已有 Pod。
-
Pod 容忍 tolerations:写在 Pod 里的「通行证」,能抵消对应污点的限制。
污点和容忍必须key、operator、value、effect匹配才会生效抵消。
一、operator 两种取值说明
1. Equal(默认)
规则:必须 key相同 + value相同 才算匹配污点。 示例:
tolerations: - key: "CPU" operator: "Equal" value: "L1" effect: "NoSchedule"
含义:只容忍节点污点 CPU=L1:NoSchedule。 节点污点是 CPU=L2、GPU=L1 全都匹配不上,无效。
2. Exists
规则:只看 key 存在,不对比 value,配置里不能写 value 字段。
tolerations: - key: "CPU" operator: "Exists" effect: "NoSchedule"
含义:只要节点有 key 为CPU的污点,不管 value 是 L1/L2/L3,全部容忍。
二、effect 三种效果(污点的三种限制行为)
1. NoSchedule(硬性禁止新 Pod 调度)
-
不能容忍污点的新 Pod:不允许调度到该节点
-
已经跑在节点上的老 Pod:不受影响,不会被赶走
2. PreferNoSchedule(软性、尽量避开)
调度器尽量不把 Pod 放过来,但资源不足时还是可能调度上来,没有强制约束力。
3. NoExecute(驱逐现有 Pod,同时禁止新 Pod)
分 3 种场景:
-
Pod 不能容忍污点:立刻驱逐,马上删掉;
-
能容忍,但没写
tolerationSeconds:永久留在节点,不会被驱逐; -
能容忍,设置
tolerationSeconds:3600:还能继续待 1 小时,超时自动驱逐; 所有不能容忍的新 Pod,也一律不能调度上来。
三、你最后最难理解的一句话重点解析
如果容忍度的 key 为空且 operator 为 Exists,表示这个容忍度与任意的 key 、value 和 effect 都匹配,即这个容忍度能容忍任意 taint。
配置写法
tolerations: - key: "" # key空 operator: "Exists"
人话翻译
这个 Pod 拥有万能通行证,节点上不管打任何污点(不管 key 叫什么、value 是多少、effect 是 NoSchedule/NoExecute),全部无视,完全不受污点限制。
使用场景
-
主节点、系统核心 Pod(kube 组件),必须能调度到所有节点,不受任何污点阻拦;
-
生产业务 Pod 一般不这么写,会丧失节点调度隔离能力。
四、补充特殊规则:key 为空但不是 Exists
只写 key 空、不写 operator=Exists,不能匹配全部污点,只有上面 key:"" + operator:Exists 才是万能容忍。
完整小例子串联理解
-
给节点打污点:
kubectl taint node worker31 CPU=L1:NoSchedule -
Pod 配置 Equal 容忍,就能正常调度到 worker31;
-
若节点污点改为
CPU=L2:NoSchedule,Equal 匹配失败,Pod 无法调度; -
换成 operator:Exists,不管 CPU 等于 L1 还是 L2 都能调度;
-
写
key:"",operator:Exists,就算节点再加 GPU、memory 各类污点,Pod 照样能调度。 -
节点污点 taint:打在节点上的「排斥标记」,用来拒绝 Pod 调度、驱逐已有 Pod。
-
Pod 容忍 tolerations:写在 Pod 里的「通行证」,能抵消对应污点的限制。 污点和容忍必须key、operator、value、effect匹配才会生效抵消。
一个容忍度和一个污点 匹配
示例:
设置 node 污点:
[root@master30 ~ 19:08:18]# kubectl taint node worker31.zy.cloud CPU=L1:NoSchedule node/worker31.zy.cloud tainted [root@master30 ~ 19:21:50]# kubectl taint node worker32.zy.cloud CPU=L2:NoSchedule node/worker32.zy.cloud tainted #查看污点设置成功没有 [root@master30 ~ 19:22:17]# kubectl describe node worker31.zy.cloud | grep -i taints Taints: CPU=L1:NoSchedule [root@master30 ~ 19:24:10]# kubectl describe node worker32.zy.cloud | grep -i taints Taints: CPU=L2:NoSchedule
创建 pod :
[root@master30 ~ 19:24:16]# vim deploy-with-tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
tolerations:
- key: "CPU"
operator: "Equal"
value: "L3"
effect: "NoSchedule"
containers:
- name: nginx
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
# 创建上述pod示例
[root@master30 ~ 19:25:51]# kubectl apply -f deploy-with-tolerations.yaml
deployment.apps/web created
[root@master30 ~ 19:26:06]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-5bf7b7b98f-gg6n4 0/1 Pending 0 5s
web-5bf7b7b98f-rckf5 0/1 Pending 0 5s
# pod状态为Pending
#查看其中一个pod分析原因, Events:事件表明3个节点上的污点与pod不匹配,所以无法创建pod
[root@master30 ~ 19:26:11]# kubectl describe pod web-5bf7b7b98f-gg6n4
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 62s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {CPU: L1}, 1 node(s) had untolerated taint {CPU: L2}, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
# 删除 deployments,将容忍度改为CPU=L1
[root@master30 ~ 19:27:08]# kubectl delete deployments.apps web
deployment.apps "web" deleted
[root@master30 ~ 19:28:17]# vim deploy-with-tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
tolerations:
- key: "CPU"
operator: "Equal"
value: "L1"
effect: "NoSchedule"
containers:
- name: nginx
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
[root@master30 ~ 19:29:27]# kubectl apply -f deploy-with-tolerations.yaml deployment.apps/web created [root@master30 ~ 19:29:56]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-7c99d767-ffcmg 1/1 Running 0 4s 10.224.215.174 worker31.zy.cloud <none> <none> web-7c99d767-qfrqj 1/1 Running 0 4s 10.224.215.173 worker31.zy.cloud <none> <none> # Pod调度成功,而且分配到了worker31 # 清理环境 [root@master30 ~ 19:31:11]# kubectl taint node worker31.zy.cloud CPU:NoSchedule- node/worker31.zy.cloud untainted [root@master30 ~ 19:31:28]# kubectl taint node worker32.zy.cloud CPU:NoSchedule- node/worker32.zy.cloud untainted [root@master30 ~ 19:31:34]# kubectl delete deployments.apps web deployment.apps "web" deleted
多个容忍度和多个污点 匹配
Kubernetes 可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点,特别是以下情况:
-
如果未被过滤的污点中存在至少一个 effect 值为
NoSchedule的污点, 则 Kubernetes 不会将 Pod 分配到该节点。 -
如果未被过滤的污点中不存在 effect 值为
NoSchedule的污点, 但存在 effect 值为PreferNoSchedule的污点, 则 Kubernetes 尝试 不将 Pod 分配到该节点。 -
如果未被过滤的污点中存在至少一个 effect 值为
NoExecute的污点, 则 Kubernetes 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 或者将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
例如,某个节点添加了如下污点:
[root@master30 ~ 19:31:43]# kubectl taint node worker31.zy.cloud CPU=L1:NoSchedule node/worker31.zy.cloud tainted [root@master30 ~ 19:33:38]# kubectl taint node worker31.zy.cloud CPU=L1:NoExecute node/worker31.zy.cloud tainted [root@master30 ~ 19:33:51]# kubectl taint node worker31.zy.cloud MEM=L2:NoSchedule node/worker31.zy.cloud tainted
假定某个 Pod 有两个容忍度:
tolerations: - key: "CPU" operator: "Equal" value: "L1" effect: "NoSchedule" - key: "CPU" operator: "Equal" value: "L1" effect: "NoExecute"
在这种情况下,上述 Pod 不会被调度到上述节点,因为其没有容忍度和第三个污点相匹配。 但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
示例:
设置 node 多个污点
[root@master30 ~ 19:31:43]# kubectl taint node worker31.zy.cloud CPU=L1:NoSchedule node/worker31.zy.cloud tainted [root@master30 ~ 19:33:38]# kubectl taint node worker31.zy.cloud CPU=L1:NoExecute node/worker31.zy.cloud tainted [root@master30 ~ 19:33:51]# kubectl taint node worker31.zy.cloud MEM=L2:NoSchedule node/worker31.zy.cloud tainted [root@master30 ~ 19:34:10]# kubectl taint node worker32.zy.cloud CPU=L2:NoSchedule node/worker32.zy.cloud tainted
创建 Deployment:
[root@master30 ~ 19:36:58]# vim deploy-with-tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
tolerations:
- key: "CPU"
operator: "Equal"
value: "L1"
effect: "NoSchedule"
- key: "CPU"
operator: "Equal"
value: "L1"
effect: "NoExecute"
containers:
- name: nginx
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
# 创建上述pod示例
[root@master30 ~ 19:37:35]# kubectl apply -f deploy-with-tolerations.yaml
deployment.apps/web created
[root@master30 ~ 19:37:52]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-6844d698c4-d8rt7 0/1 Pending 0 4s
web-6844d698c4-f76ln 0/1 Pending 0 4s
# pod状态为Pending
# 事件表明节点上的3个污点与pod不匹配,所以无法创建pod
[root@master30 ~ 19:38:03]# kubectl describe pod web-6844d698c4-d8rt7
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 35s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {CPU: L2}, 1 node(s) had untolerated taint {MEM: L2}, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
0/3 nodes are available: 3 Preemption is not helpful for scheduling.
# 删除deployments,添加容忍度MEM=L2
[root@master30 ~ 19:38:27]# kubectl delete deployments.apps web
deployment.apps "web" deleted
root@master30:~# vim deploy-with-tolerations.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
tolerations:
- key: "CPU"
operator: "Equal"
value: "L1"
effect: "NoSchedule"
- key: "CPU"
operator: "Equal"
value: "L1"
effect: "NoExecute"
- key: "MEM"
operator: "Equal"
value: "L2"
effect: "NoSchedule"
containers:
- name: nginx
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
[root@master30 ~ 19:45:23]# kubectl apply -f deploy-with-tolerations.yaml deployment.apps/web created [root@master30 ~ 19:45:25]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-77d5464ccf-nw4bm 1/1 Running 0 7s 10.224.215.139 worker31.zy.cloud <none> <none> web-77d5464ccf-wlskw 1/1 Running 0 7s 10.224.215.167 worker31.zy.cloud <none> <none> # Pod 调度成功,而且分配到了worker31 # 清理环境 [root@master30 ~ 19:45:32]# kubectl taint nodes worker31.zy.cloud CPU=L1:NoSchedule-node/worker31.zy.cloud untainted [root@master30 ~ 19:46:31]# kubectl taint nodes worker31.zy.cloud CPU=L1:NoExecute- node/worker31.zy.cloud untainted [root@master30 ~ 19:46:36]# kubectl taint nodes worker31.zy.cloud MEM=L2:NoSchedule-node/worker31.zy.cloud untainted [root@master30 ~ 19:46:45]# kubectl taint nodes worker32.zy.cloud CPU=L2:NoSchedule-node/worker32.zy.cloud untainted [root@master30 ~ 19:47:04]# kubectl delete deployments.apps web deployment.apps "web" deleted
Taint 和 Toleration 用例
污点(Taint)作用于节点,是节点的排斥规则;容忍度(Toleration)作用于Pod,是Pod的放行通行证。二者搭配使用,可精准实现 Pod 避开特定节点、限定专属节点、节点异常驱逐Pod等精细化调度管控,以下是企业最常用的三大实战场景详解。
一、场景1:用户专属节点(资源隔离、专属分配)
1. 基础需求
将部分节点单独分配给指定用户/业务使用,普通业务Pod禁止调度,仅专属用户的Pod可以部署,实现资源隔离。
2. 基础配置:仅污点+容忍(宽松模式)
节点操作(打污点):给专属节点添加污点,禁止无容忍的Pod调度
kubectl taint node worker31 dedicated=groupName:NoSchedule
Pod配置(加容忍):专属用户的Pod配置对应容忍度
tolerations: - key: "dedicated" operator: "Equal" value: "groupName" effect: "NoSchedule"
3. 宽松模式核心特点
拥有该容忍度的专属Pod不限制节点:既可以调度到打了专属污点的节点,也可以调度到集群其他普通无污点节点,只是拥有了进入专属节点的权限,没有强制绑定效果。
4. 严格模式:Pod只能跑在专属节点(污点 + 节点亲和 组合)
若要求专属Pod只能部署在专属节点,不能乱跑普通节点,仅靠容忍度不够,必须搭配节点亲和性,双向限制:
第一步:给专属节点打标签(用于亲和匹配)
kubectl label node worker31 dedicated=groupName
第二步:Pod同时配置「容忍度+节点亲和」
-
容忍度:让Pod能进入带专属污点的节点
-
节点亲和:强制Pod只能进入带专属标签的节点
最终实现精准隔离:普通Pod进不来专属节点,专属Pod出不去专属节点。
二、场景2:特殊硬件节点调度(GPU节点资源保留)
1. 基础需求
集群中部分节点配备GPU、高速磁盘等特殊硬件,仅需要运行AI计算、图形渲染等刚需硬件的Pod,普通业务Pod禁止占用,为特殊业务保留专属资源。
2. 实现方案
节点操作(打污点):给特殊硬件节点添加禁止调度污点
kubectl taint node gpu-node-01 special=true:NoSchedule
Pod配置(加容忍):仅使用GPU的特殊业务Pod配置对应容忍度
tolerations: - key: "special" operator: "Equal" value: "true" effect: "NoSchedule"
3. 场景效果
-
无该容忍度的普通Pod:无法调度到GPU节点,自动规避
-
有容忍度的硬件刚需Pod:可正常调度使用特殊资源
-
完美实现资源分层:普通业务跑通用节点,特殊业务跑硬件节点
三、场景3:NoExecute 污点-基于污点的Pod驱逐机制
前文的 NoSchedule 只限制新Pod调度,不影响已运行Pod;而 NoExecute 会直接影响节点上正在运行的Pod,是集群自愈、故障驱逐的核心机制,分三种精准规则:
1. 规则一:Pod无法容忍 NoExecute 污点
节点存在该污点、Pod无对应容忍度 → 立刻驱逐Pod,直接删除运行中的业务。
2. 规则二:Pod可容忍,但未配置 tolerationSeconds
Pod能匹配该污点,且没有设置容忍时间 → 永久运行,不会被节点驱逐,一直常驻节点。
3. 规则三:Pod可容忍,且配置 tolerationSeconds
Pod可容忍污点,但设置了超时时间(单位:秒) → 允许Pod短暂续命运行,超时后自动被驱逐,常用于节点维护、故障缓冲场景。
# 示例:容忍故障污点,续命60秒后驱逐 tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 60
四、K8s 内置自动污点(集群原生故障标记)
K8s 节点异常、资源压力、状态异常时,系统会自动给节点打污点,无需人工操作,配合NoExecute规则实现集群自愈,所有内置污点详解如下:
-
node.kubernetes.io/not-ready:节点未就绪(节点Ready状态为False),节点故障、组件异常时自动添加
-
node.kubernetes.io/unreachable:控制器无法连通节点(节点Ready状态为Unknown),节点离线、断网时触发
-
node.kubernetes.io/memory-pressure:节点内存资源压力过载,内存不足
-
node.kubernetes.io/disk-pressure:节点磁盘压力过载,磁盘空间不足、磁盘IO打满
-
node.kubernetes.io/pid-pressure:节点进程数耗尽,PID资源占满,无法新建进程
-
node.kubernetes.io/network-unavailable:节点网络不可用,无法集群通信
-
node.kubernetes.io/unschedulable:节点被设置为不可调度状态,人工锁定或系统锁定
-
node.cloudprovider.kubernetes.io/uninitialized:云服务器节点初始化未完成,cloud-controller-manager初始化完成后,该污点会自动删除
节点被驱逐时,节点控制器或者 kubelet 会添加带有 NoExecute 效应的相关污点。 如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。
一、节点故障自动打 / 删 NoExecute 污点逻辑 1. 节点出故障(断网、kubelet 挂了、资源打满),节点控制器 /kubelet 会自动给节点打上 NoExecute 类型内置污点; 2. 等节点恢复正常、故障消失,程序会自动把对应的污点删掉; 3. 加污点有限流限速: 比如多台节点同时断连,系统不会一瞬间批量驱逐所有 Pod,而是缓慢分批执行,防止大量业务同时崩溃、集群雪崩。 二、tolerationSeconds 作用:故障后给 Pod 续命一段时间 当节点打上 not-ready / unreachable 这种 NoExecute 污点,Pod 可以设置容忍时长: - 没写时长:要么立刻赶走,要么永久留下; - 写了tolerationSeconds: 6000 = 1000 分钟: 节点断网失联后,Pod 不会马上删掉,再继续跑 1000 分钟,期间如果网络恢复、污点消失,Pod 就正常留在节点,不用重建。 适用场景:有本地缓存、本地数据的应用,不想一断网就销毁 Pod 丢失本地状态。 示例配置解读: tolerations: - key: "node.kubernetes.io/unreachable" operator: "Exists" effect: "NoExecute" tolerationSeconds: 6000 只要节点出现 “无法连通” 污点,Pod 最多再存活 6000 秒,超时才驱逐。 三、普通 Pod 默认自带 5 分钟自动容忍(重点) K8s 会自动给普通 Pod加上两条隐藏容忍,除非你自己 yaml 里写了同名 key 的容忍规则(自己写了就覆盖默认): 1. 容忍 node.kubernetes.io/not-ready,超时 300 秒(5 分钟) 2. 容忍 node.kubernetes.io/unreachable,超时 300 秒(5 分钟) 含义: 节点失联 / 未就绪时,Pod 默认还能坚持跑 5 分钟;5 分钟节点没恢复,才会被驱逐重建。 四、DaemonSet Pod 特殊规则:永远不被故障驱逐 DaemonSet(日志、监控、网络组件这类每个节点必须跑一个的 Pod),系统自动给它们添加 not-ready / unreachable 的 NoExecute 容忍,但不带 tolerationSeconds。 对照前面规则:能容忍 NoExecute 且没写超时时间 → Pod 永久留在节点,不会被驱逐。 目的: 哪怕节点故障断网,监控、日志收集这类基础组件也不能删掉,保证故障节点依旧能采集数据。 --- 把整套故障驱逐流程串起来理解 1. 节点突然断网,master 收不到节点心跳; 2. 节点控制器限流给节点打上污点 node.kubernetes.io/unreachable:NoExecute; 3. 普通业务 Pod:默认容忍 5 分钟,5 分钟内网络恢复则无事;5 分钟没恢复就驱逐重建; 4. 有本地存储的应用:自定义 tolerationSeconds 拉长续命时间,减少重建; 5. DaemonSet(监控 / 日志):无超时,永远不驱逐,持续驻留节点; 6. 节点网络修复,系统自动清除 unreachable 污点,所有 Pod 完全不受影响。
cordon 和 uncordon
kubectl cordon 命令,标记node为不可调度,将无法在node上创建新的pod。
[root@master30 ~ 19:47:11]# kubectl cordon -h
Mark node as unschedulable.
Examples:
# Mark node "foo" as unschedulable
kubectl cordon foo
Options:
--dry-run='none':
Must be "none", "server", or "client". If client strategy, only print
the object that would be sent, without sending it. If server strategy,
submit server-side request without persisting the resource.
-l, --selector='':
Selector (label query) to filter on, supports '=', '==', and
'!='.(e.g. -l key1=value1,key2=value2). Matching objects must satisfy
all of the specified label constraints.
Usage:
kubectl cordon NODE [options]
Use "kubectl options" for a list of global command-line options (applies to all
commands).
[root@master30 ~ 20:02:12]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2
# 标记worker31.zy.cloud为SchedulingDisabled
[root@master30 ~ 20:02:34]# kubectl cordon worker31.zy.cloud
node/worker31.zy.cloud cordoned
[root@master30 ~ 20:03:07]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready,SchedulingDisabled <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2
# 创建一个deployment
[root@master30 ~ 20:03:22]# kubectl create deployment web --image=docker.io/library/nginx --replicas=2
deployment.apps/web created
[root@master30 ~ 20:03:44]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-68b95c775c-j94z6 1/1 Running 0 5s <none> worker32.zy.cloud <none> <none>
web-68b95c775c-vb8lb 1/1 Running 0 5s 10.224.170.41 worker32.zy.cloud <none> <none>
# 取消worker31.zy.cloud标记SchedulingDisabled
[root@master30 ~ 20:03:49]# kubectl uncordon worker31.zy.cloud
node/worker31.zy.cloud uncordoned
[root@master30 ~ 20:04:22]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2
[root@master30 ~ 20:04:27]# kubectl scale deployment web --replicas=4
deployment.apps/web scaled
[root@master30 ~ 20:04:54]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-68b95c775c-gszwr 1/1 Running 0 91s 10.224.215.147 worker31.zy.cloud <none> <none>
web-68b95c775c-j94z6 1/1 Running 0 2m36s 10.224.170.37 worker32.zy.cloud <none> <none>
web-68b95c775c-vb8lb 1/1 Running 0 2m36s 10.224.170.41 worker32.zy.cloud <none> <none>
web-68b95c775c-vmcq5 1/1 Running 0 91s 10.224.215.157 worker31.zy.cloud <none> <none>
drain
学习参考:安全地清空一个节点
在对节点执行维护(例如内核升级、硬件维护等)之前, 可以使用 kubectl drain 从节点安全地逐出所有 Pod。 安全的驱逐过程允许 Pod 的容器体面地终止, 并确保满足指定的 PodDisruptionBudgets。
准备开始
此任务假定你已经满足了以下先决条件:
-
在节点清空期间,确保应用具有高可用性。
-
你已经了解了 PodDisruptionBudget 的概念, 并为需要它的应用配置了 PodDisruptionBudget。
为了确保负载在维护期间仍然可用,可以配置一个 PodDisruptionBudget。 如果可用性对于正在清空的该节点上运行或可能在该节点上运行的任何应用程序很重要, 首先 配置一个 PodDisruptionBudgets 并继续遵循本指南。
建议为你的 PodDisruptionBudgets 设置
AlwaysAllow不健康 Pod 驱逐策略, 以在节点清空期间支持驱逐异常的应用程序。 默认行为是等待应用程序的 Pod 变为 健康后, 才能进行清空操作。
kubectl drain 实践
kubectl drain 命令,驱逐 node 上所有 pod,同时标记 node 为不可调度。默认情况下,该命令忽略节点上不能驱逐的 Pod。有关更多细节,请参阅 kubectl drain 文档。
[root@master30 ~ 20:07:14]# kubectl drain -h
Drain node in preparation for maintenance.
The given node will be marked unschedulable to prevent new pods from arriving.
'drain' evicts the pods if the APIServer supports.
Options:
--chunk-size=500:
Return large lists in chunks rather than all at once. Pass 0 to
disable. This flag is beta and may change in the future.
--delete-emptydir-data=false:
Continue even if there are pods using emptyDir (local data that will
be deleted when the node is drained).
--disable-eviction=false:
Force drain to use delete, even if eviction is supported. This will
bypass checking PodDisruptionBudgets, use with caution.
--dry-run='none':
Must be "none", "server", or "client". If client strategy, only print
the object that would be sent, without sending it. If server strategy,
submit server-side request without persisting the resource.
--force=false:
Continue even if there are pods that do not declare a controller.
--grace-period=-1:
Period of time in seconds given to each pod to terminate gracefully.
If negative, the default value specified in the pod will be used.
--ignore-daemonsets=false:
Ignore DaemonSet-managed pods.
--pod-selector='':
Label selector to filter pods on the node
-l, --selector='':
Selector (label query) to filter on, supports '=', '==', and
'!='.(e.g. -l key1=value1,key2=value2). Matching objects must satisfy
all of the specified label constraints.
--skip-wait-for-delete-timeout=0:
If pod DeletionTimestamp older than N seconds, skip waiting for the
pod. Seconds must be greater than 0 to skip.
--timeout=0s:
The length of time to wait before giving up, zero means infinite
Usage:
kubectl drain NODE [options]
Use "kubectl options" for a list of global command-line options (applies to all
commands).
# 默认不驱逐 DaemonSet 控制的pod
[root@master30 ~ 20:07:23]# kubectl drain worker31.zy.cloud
node/worker31.zy.cloud cordoned
error: unable to drain node "worker31.zy.cloud" due to error:cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/calico-node-9n48n, kube-system/kube-proxy-hkxgn, continuing command...
There are pending nodes to be drained:
worker31.zy.cloud
cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/calico-node-9n48n, kube-system/kube-proxy-hkxgn
# 使用--ignore-daemonsets驱逐DaemonSet控制的pod
[root@master30 ~ 20:09:12]# kubectl drain worker31.zy.cloud --ignore-daemonsets
node/worker31.zy.cloud already cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/calico-node-9n48n, kube-system/kube-proxy-hkxgn
evicting pod scheduler/web-68b95c775c-vmcq5
evicting pod scheduler/web-68b95c775c-gszwr
pod/web-68b95c775c-gszwr evicted
pod/web-68b95c775c-vmcq5 evicted
node/worker31.zy.cloud drained
# 还可以使用以下选项驱逐特定pod:
--pod-selector='': Label selector to filter pods on the node
-l, --selector='': Selector (label query) to filter on,supports '=', '==', and '!='.(e.g. -l CPU=L1,MEM=L2). Matching objects must satisfy all of the specified label constraints.
[root@master30 ~ 20:09:35]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready,SchedulingDisabled <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2
# 删除worker31上SchedulingDisabled标记
[root@master30 ~ 20:09:54]# kubectl uncordon worker31.zy.cloud
node/worker31.zy.cloud uncordoned
[root@master30 ~ 20:10:08]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master30.zy.cloud Ready control-plane 8d v1.30.2
worker31.zy.cloud Ready <none> 8d v1.30.2
worker32.zy.cloud Ready <none> 8d v1.30.2
并行清空多个节点
kubectl drain 命令一次只能发送给一个节点,可以在不同的终端或后台为不同的节点并行地运行多个 kubectl drain 命令。 同时运行的多个 drain 命令仍然遵循你指定的 PodDisruptionBudget。
例如,一个三副本的 Deployments, 设置了一个PodDisruptionBudget,指定 minAvailable: 2。 如果所有的三个 Pod 处于健康(healthy)状态, 并且你并行地发出多个 drain 命令,那么 kubectl drain 只会从 Deployments中逐出一个 Pod, 因为 Kubernetes 会遵守 PodDisruptionBudget 并确保在任何时候只有一个 Pod 不可用 (最多不可用 Pod 个数的计算方法:replicas - minAvailable)。 任何会导致处于健康(healthy) 状态的副本数量低于指定预算的清空操作都将被阻止。
环境清理
[root@master30 ~ 20:10:19]# kubectl delete ns scheduler

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)