项目复盘:基于扎根理论与结构方程模型(SEM)的SOR混合研究设计
一、理论方法
1、SOR 模型(刺激-机体-反应模型)
SOR理论模型(Stimulus-Organism-Response Model)最初由环境心理学家梅拉比安和罗素于1974年提出。它打破了传统心理学认为“外部刺激会直接导致行为”的机械观点,认为:任何外部环境刺激(S),都必须先引发个体内部的认知或情绪变化(O),正是这种“内心的震荡”,最终才决定了个体的行为反应(R)。
-
S (Stimulus) - 外部刺激: 能够打破机体平衡并被用户感知到的外部环境要素 。
-
O (Organism) - 机体变化: 处于刺激与反应中间的“心理中介变量”,包含个体面对刺激时的情绪唤醒、认知评价和心理状态 。
-
R (Response) - 行为反应: 个体最终做出的趋向性(如持续观看、付费)或规避性(如划走、卸载)的行为结果 。
值得注意的是,SOR模型并非一个可用于探索任意变量间关系的通用工具,而是一个基于既有文献支撑的变量分类与单向因果框架。其应用须满足两项前提条件:
第一,变量的归属须有据可依。 研究者需依据成熟理论或前人实证证据,将所涉变量明确界定为外部环境刺激(S)、个体内部机体状态(O)或行为反应(R),不能凭主观直觉随意归入某一层级。每一个变量被放置在"货架"的哪一层,都必须有文献逻辑作为"承重墙"。
第二,变量间的关系方向须先验明确。 SOR模型的路径方向是单向且固定的(S→O→R),这意味着研究者必须在理论上预先确认刺激会影响机体、机体会影响反应,而非相反或双向互构。因此,如果某一对变量间的因果关系方向尚属未知(例如,尚未有文献能支撑A是前因、B是后果,而非B导致A),则不宜强行套用SOR模型,否则将构成"方向性误用"(directional misspecification)。
综上,SOR模型的适用边界可概括为:"已知归属且已知方向"——即变量的分类归属和影响方向均能从前人文献中找到理论锚点。 它接纳新概念的进入(只要能在理论上锚定其层级),但拒绝未知关系的随意拼接。这既是该框架的结构性优势,也是其不容突破的方法论底线。
2、扎根理论
扎根理论是由芝加哥大学的格拉斯(Glaser)和斯特劳斯(Strauss)在1967年联合提出的一种自下而上建构理论的质性研究方法。它强调“不带预设偏见”,直接从原始的现实资料(如深度访谈、一手文本)出发,通过逐字逐句的科学编码与提炼,层层归纳,最终从泥土里“生长”出一个全新的理论模型。
其核心工具是经典的“三级编码”:
-
开放式编码(Open Coding): 揉碎原始资料,打碎并提炼出初始概念 。
-
主轴编码(Axial Coding): 寻找概念之间的关联,聚类并提炼出“主范畴” 。
-
选择性编码(Selective Coding): 提炼出能统领全局的“核心范畴”,穿针引线织成完整的故事线 。
为什么要用扎根理论?
在SOR框架的应用中,变量的分类归属须以既有文献为锚点。然而,针对现有理论尚缺乏的新兴概念,其属性维度与影响路径亦未被充分揭示。为此,本研究首先采用扎根理论(Grounded Theory)进行探索性研究,通过对原始资料的系统性编码,自下而上地提炼概念范畴、厘清变量间的逻辑脉络。此举旨在为那些尚无文献支撑的本土化新名词寻得理论"户口",从而为后续将其合法安置于SOR模型的S、O、R三层货架之上提供经验证据与分类依据。
3、结构方程模型
结构方程模型(Structural Equation Modeling, 简称SEM)是当代社会科学及行为科学中极为强大的一种多元统计分析技术。传统的回归分析一次只能检验一个自变量对因变量的影响,而无法处理“剪不断理还乱”的多重因果和中介效应。SEM的伟大之处在于,它通过结合因子分析(Factor Analysis)与路径分析(Path Analysis),允许研究者同时分析多个测量变量、潜变量(即无法直接测量,需多个题项表征的心理状态,如心流体验)之间的复杂因果网络关系,并精准计算出每一条中介路径的贡献度 。
为什么要用结构方程模型?
在扎根理论完成概念提炼与关系预设之后,本研究进一步引入结构方程模型(Structural Equation Modeling, SEM)。该方法的优势在于,它不仅能同时处理S、O、R多层变量之间的复杂路径关系,还能通过中介效应检验精确测算"机体(O)"在刺激与反应之间所承担的传导权重。简言之,扎根理论负责"搭架子"(质性的归类与命题提出),结构方程模型负责"测承重"(量化的拟合与路径验证),二者前后衔接、各司其职,共同确保SOR框架在本研究中的合法性与科学性。
二、项目实施
1、基于访谈的变量识别与概念建构
(1)数据收集与抽样策略
扎根理论的第一步在于获取富含经验细节的原始资料。常用的数据来源包括深度访谈、政策文本、用户日记或公开评论等,研究者需根据研究问题的性质选择最适配的材料类型。这里选用访谈文本,在抽样环节,应遵循理论抽样原则,即并非随机选取样本,而是有目的地寻找能够最大限度呈现现象差异的典型个案。具体而言,研究者需覆盖不同类型的样本群体——例如重度使用者与轻度使用者、高卷入度与低卷入度参与者、不同人口统计特征的用户等——以确保所收集的资料能够反映研究现象的多元面向与丰富层次。在访谈结束后,须将录音内容逐字逐句转录为文字稿,形成后续分析的基础数据"原料"。
(2)开放式编码
研究者以逐词逐句的方式通读访谈文本,对其中包含信息量的意义单元赋予初始标签(即贴概念标签),并将语义相近的标签归并为初始范畴。此阶段要求研究者悬置个人主观预设,最大程度贴近原始资料的本意,做到"让数据自己说话"。如:02号受访者说:“平台推荐,刷到了精彩片段”;04号受访者说:“抖音平台给我推送的”,我们可以提炼出“被动触发”。但是02号又说:“手头没有任务……无聊的时候看”。可以提炼出概念“时间填补”。这时候你发现,“被动触发”和“时间填补”都在解释“为什么会点开”的最初诱因,于是把它们合并为一个初始范畴,起名叫:“触发机制”。
(3)主轴编码
在开放式编码所产生的大量初始范畴基础上,研究者进一步探寻各范畴之间的逻辑关联——如因果关系、情境关系、过程关系等——将分散的初始范畴整合为层次更高、概括性更强的主范畴。这一步骤的核心任务在于"拉帮结派",重建范畴间的内在秩序。如:把“触发机制”、“观看态度”、“观看场景”这3个初始范畴放在一起。我们会发现不管是“被动推荐”(机制)、“随意消遣”(态度),还是“下班睡前”(场景),统统都在描述用户在什么环境和状态下看剧,于是将他们合并为主范畴:观看情境。
(4)选择性编码
研究者从已提炼出的主范畴中识别出一个能够统摄全局的核心范畴,并以故事线的形式将其他范畴围绕该核心串联起来,形成一个逻辑自洽的理论叙事。至此,变量间的预设关系与初步假说模型便得以生成。如:用户在无聊、碎片化时间的观看情境(S)刺激下点开了AI漫剧; 随后,在机体(O)内部同时激活了求爽的“情绪需求”与对画面的“技术感知”; 这两股力量交织在一起,共同决定了用户对该剧“内容感知”(剧情、节奏)的最终评价; 当用户觉得内容足够吸引人时,便会顺流而下,陷入无法自拔的“心流体验”; 最终,这种极致的沉浸感跨越心理防线,在反应(R)层面上彻底转化为用户的“付费意愿”。
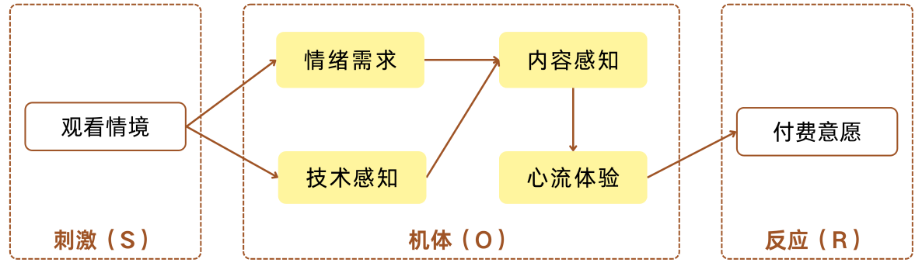
图1 理论模型示例
(5)理论饱和度检验
扎根理论强调"理论生成应止于饱和"。所谓理论饱和度,是指当研究者新增额外的访谈资料时,不再有新的概念或范畴涌现,已有框架足以解释全部数据。实际操作中,研究者通常在完成主体样本的编码后,预留一至两份访谈文本作为校验材料;若将预留文本代入现有理论模型后发现其内容均能被已有范畴所涵盖,而无需新增概念,则可判定为理论饱和,分析工作至此终止。
2、基于量化实证的问卷设计与数据收集
(1)样本获取与调查方法
为确保样本的代表性与广泛性,本研究采用分层配额抽样与多渠道便利抽样相结合的方法进行样本获取。
-
分层配额抽样: 依据主流平台(如抖音、快手、B站)的用户画像,对受访者的性别、年龄段以及观看频率进行合理的配额控制。
-
多渠道便利抽样: 通过社交媒体(小红书、微博、贴吧)的AI漫剧垂直社群、ACG同好群及短视频评论区进行多渠道定向投放。
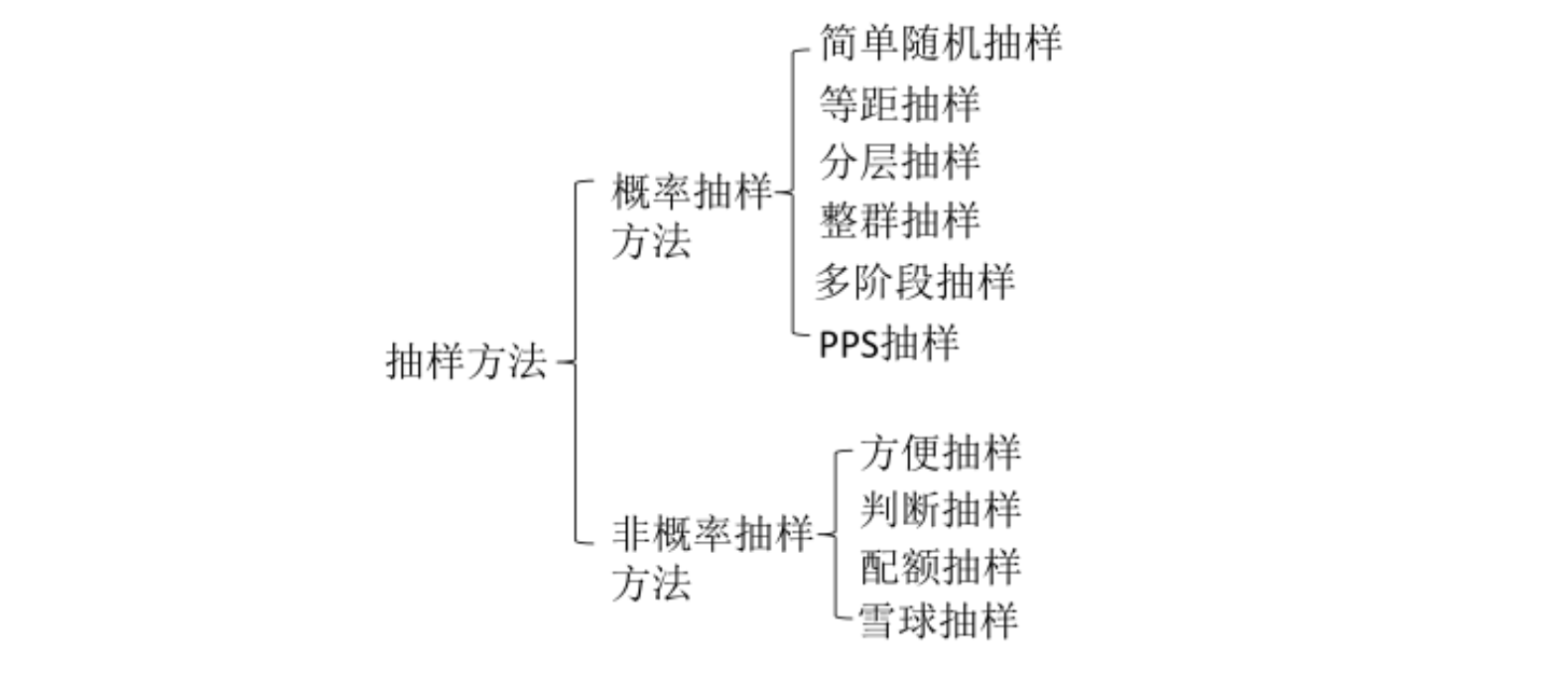
图2 抽样的基本方法
(2)基于 SPSS 的信效度检验
在正式进行路径分析前,本研究利用 SPSS 软件对有效样本数据进行了信度与效度分析,以确保测量工具的可靠性:
-
信度分析: 检验结果显示,各潜变量(观看情境、情绪需求、技术感知、内容感知、心流体验、付费意愿)的 Cronbach's α系数均大于 0.70,表明问卷具有极高的内部一致性与稳定度。
-
效度分析: 经检验,数据的 KMO 值大于 0.80,且 Bartlett 球形检验显著性(p < 0.001),说明数据极佳地适合进行因子分析。同时,组合信度(CR)与平均方差萃取值(AVE)均达到学术规范标准(CR > 0.7,AVE > 0.5),证实问卷具有良好的收敛效度与区别效度。
(3)结构方程模型(SEM)的构建与评估
将回收的有效问卷数据录入统计软件,形成原始数据矩阵。每一份问卷对应一行记录,每一列对应一个测量题项。结构方程模型软件(如AMOS)的底层运算逻辑并非直接求解复杂的因果方程组,而是首先计算所有测量题项两两之间的协方差矩阵。其核心考察逻辑在于:当某一题项的得分呈规律性变化时,其他相关题项的得分是否呈现出一致的联动趋势。
AMOS区别于传统统计软件的核心特征在于其图形化操作界面。研究者需在软件画布上完成以下构建工作:
其一,绘制潜变量。 以椭圆或圆形表示研究涉及的理论构念,即无法直接观测但需通过题项间接测量的抽象概念。
其二,绘制观测变量。 以矩形表示各潜变量对应的具体测量题项,并用单向箭头从潜变量指向其对应的观测变量。这一步骤构成测量模型,用以表征潜变量如何通过观测题项被操作化测量。
其三,绘制路径关系。 根据理论假设,用单向箭头在各潜变量之间建立连接,箭头指向代表因果关系的方向。这一步骤构成结构模型,用以表征各潜变量之间的预设影响路径。
其四,添加误差项。 每一个观测变量(矩形)以及每一个作为结果变量的潜变量(椭圆),均需挂载一个代表测量误差或未被解释方差的小圆圈,通常标记为e1、e2……等残差符号。
在配置好数据源后,研究者通常选择最大似然估计法进行模型参数估计。该算法的核心逻辑在于:以研究者绘制的理论模型为基准,反复调整各路径系数与载荷系数的取值,使模型所预测的协方差矩阵与实际问卷数据计算所得的协方差矩阵之间的差异最小化。当差异达到最小且模型收敛时,运算终止,并输出一系列用于评估模型与数据拟合程度的统计指标。
(4)结构方程模型(SEM)的结果解读
整体拟合度:若χ²/df<3、RMSEA<0.08、CFI>0.9,则模型与数据吻合良好,可继续解读。若未达标,需查阅修正指数(MI)酌情增删路径,或删除因子载荷过低的题项,每次修正后重跑模型,直至达标。
测量模型(因子载荷):各题项载荷大于0.6,说明量表效度良好。若载荷低于0.5,则删除该题后重跑。
路径分析(假设检验):P<0.05则假设成立;P>0.05则该路径不显著,讨论中如实说明即可。
中介效应:Bootstrap置信区间不包含0,则中介成立;若包含0,则中介不成立,讨论中如实报告并分析原因即可。
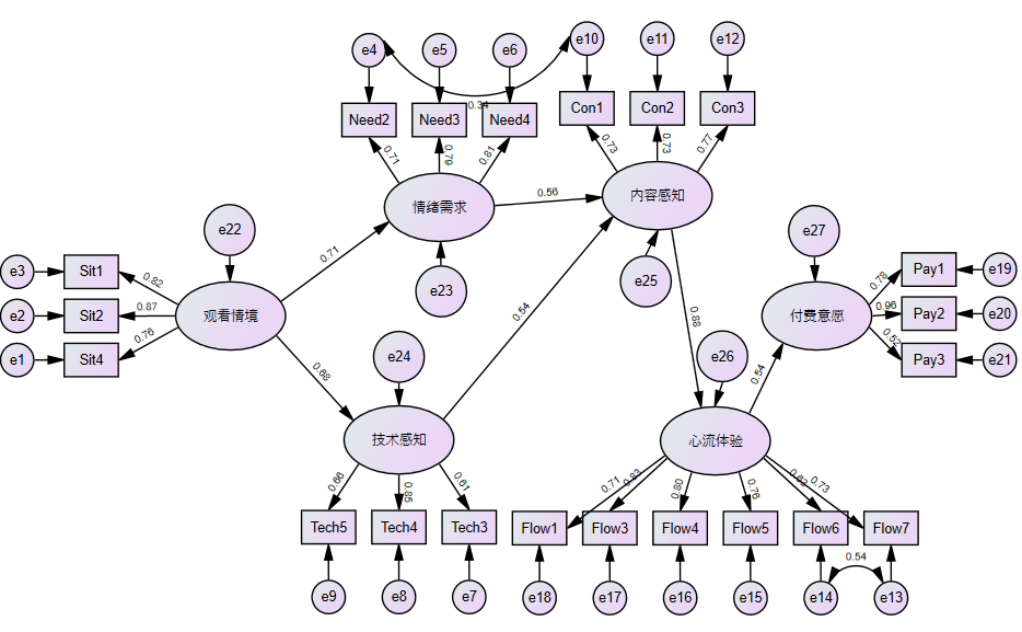
图3 路径分析图
本文章仅为学习复盘,如有问题,敬请指正!

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)