DMA 全深度解析(1):从总线原理到实战配置
前言
在嵌入式开发中,CPU 资源永远是寸土寸金的。如果让 CPU 陷在 “取数据 - 写数据” 的循环里,不仅浪费算力,还会拖慢整个系统的响应速度。而 DMA(Direct Memory Access,直接存储器访问)就是解决这个问题的 “神器”—— 让数据自己在内存和外设间 “跑路”,CPU 专心处理核心业务逻辑。本文基于 STM32F4(Cortex-M4),从核心价值到实战配置,把 DMA 讲得明明白白。
本篇文章主要介绍DMA的原理和相关配置,后续我会结合实际需求进行实战,比如环形缓冲区,AB-buffer,DMA配置时序等等
一、DMA 到底解决了什么问题?
没有 DMA 的时候,CPU 是数据搬运的 “苦力”:取一个数据→写到目标地址→再取→再写…… 循环往复,期间啥也干不了。有了 DMA 之后,DMA 控制器会接管总线,自主完成从源地址到目标地址的数据搬运,搬完了只给 CPU 发一个中断通知。核心价值就在于并行—— 数据搬运和 CPU 业务运算同时进行,系统效率直接翻倍。
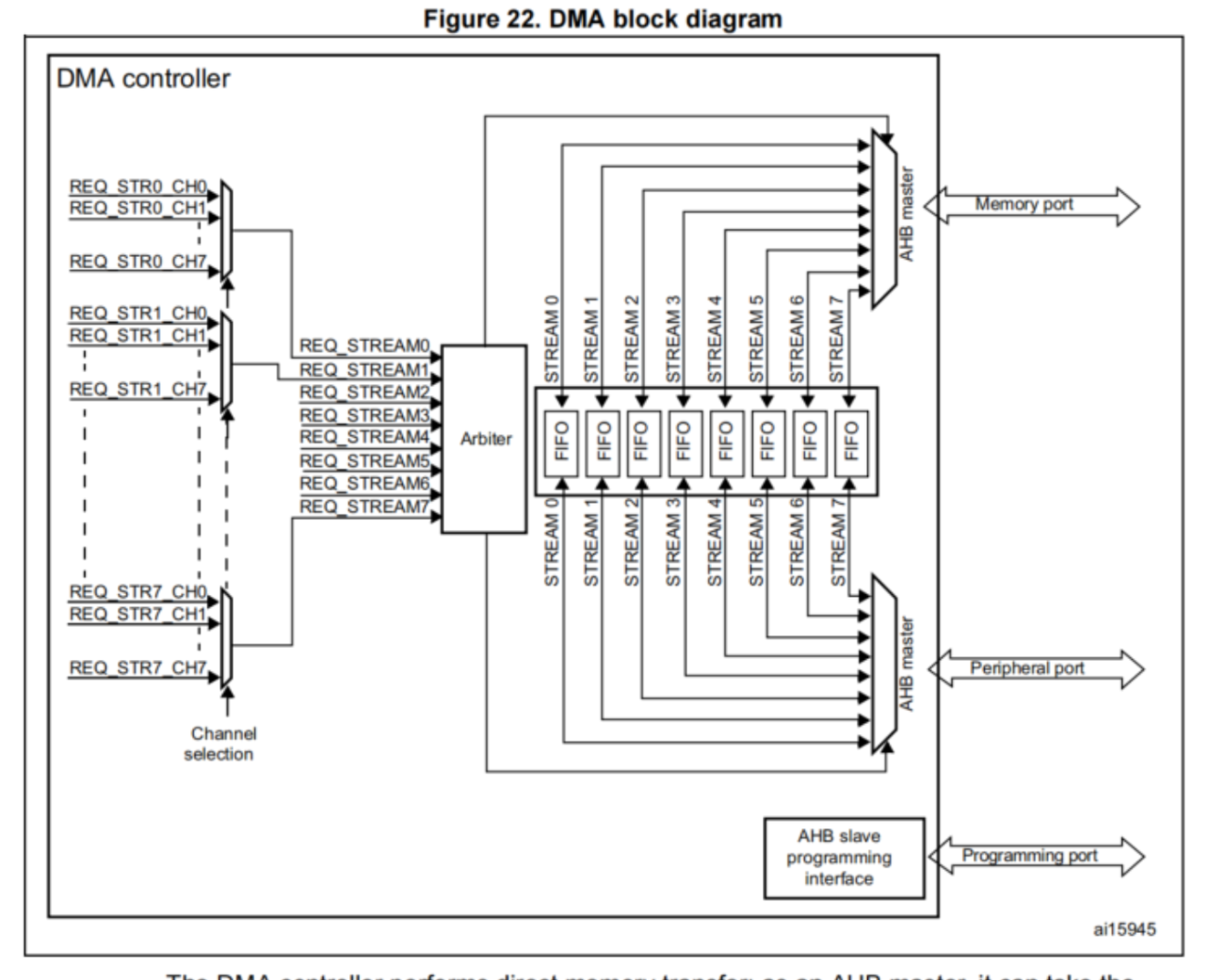
这里我们先来说一下主机(Master)和从机(Slave)
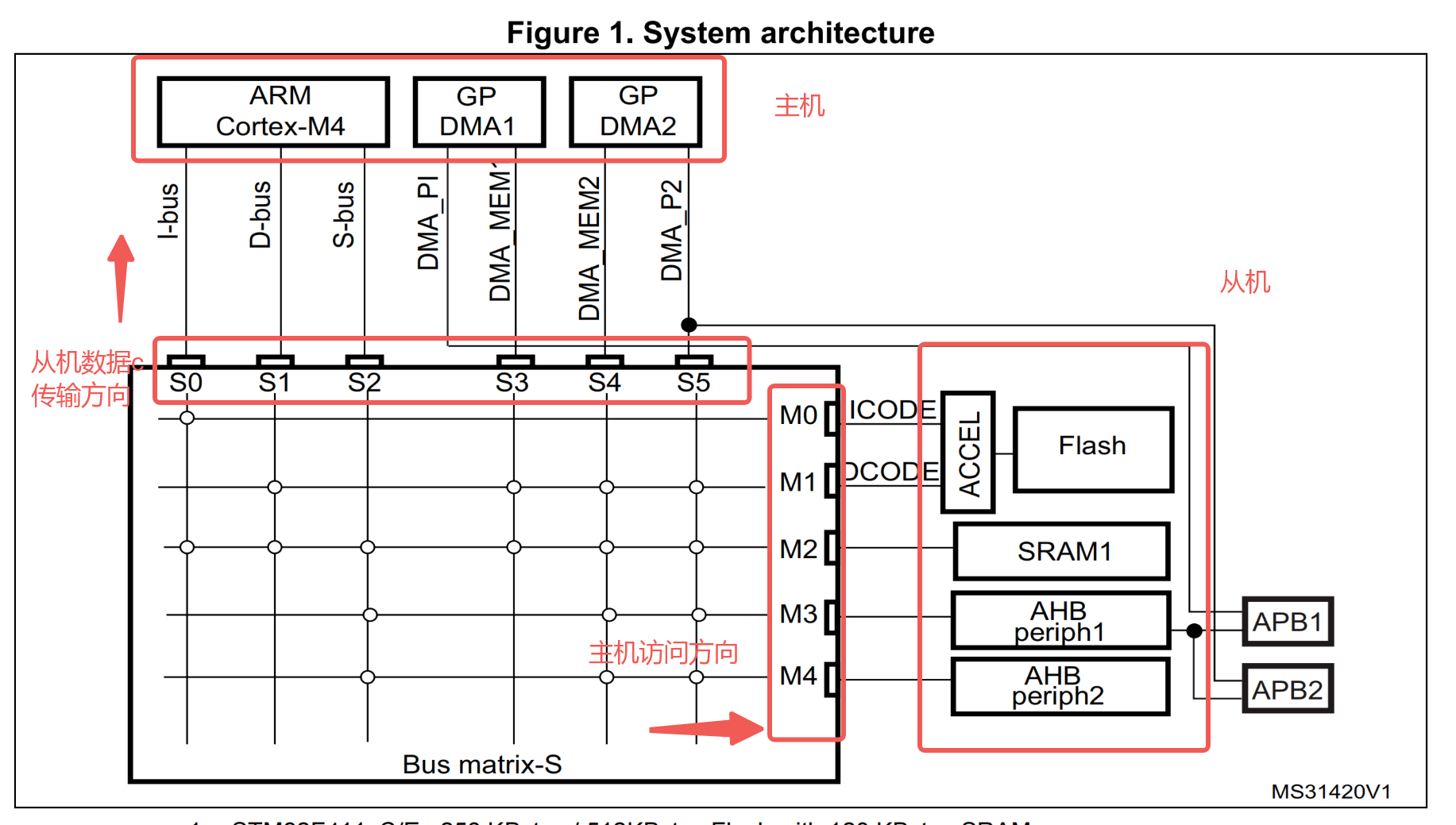
不要被图像的S0-S5和M0-M4误导,只是表示数据方向,而非代表是主从机
如果CPU想访问外设寄存器的内容,放入SRAM,那么数据流向就是:外设->CPU->SRAM
通过两次AHB总线
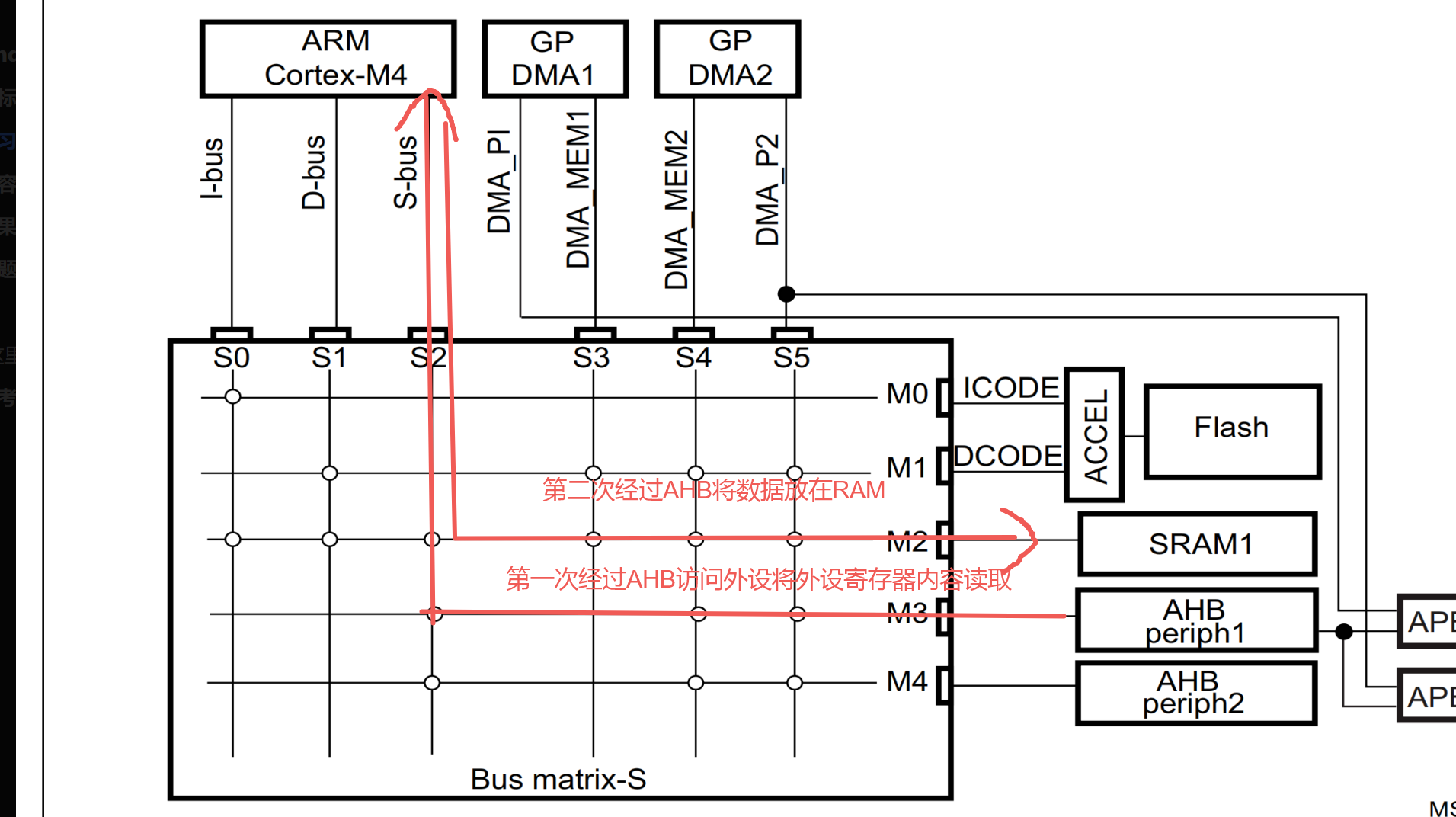
而如果使用到DMA,只需要通过一次AHB,减少一半带宽
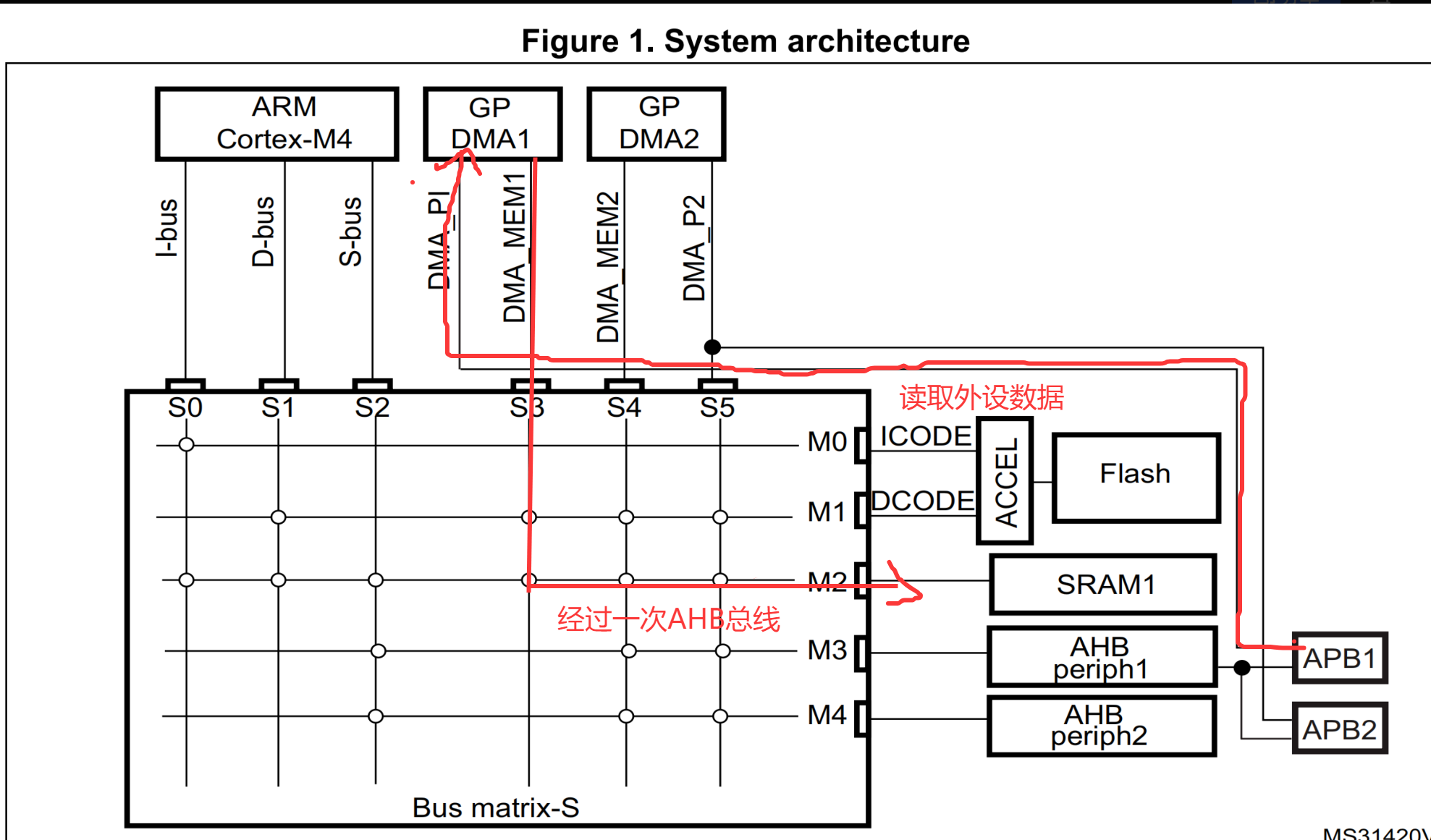
DMA能提高效率的主要原因有二点:
1、DMA也作为一个主机,可在CPU帮助主下动访问外设,在CPU执行其他操作时搬运据实 现了并行化。
2、DMA可以通过单独路线访问外设,降低了AHB的访问次数,降低了一半带宽。
二、STM32F4 的 DMA 架构:先搞懂 “硬件家底”
(1)DMA控制器在MCU内部是一个AMBA advcanced high-performaance bus (AHB)
Master。
(2)DMA控制器和AHB有三个接口:
a.一个Slave接口(用于CPU对它进行编程)
b.两个Master接口,允许将DMA去开启两个AHB总线上两个从设备之间的信号通
信。
(3)每个DMA都具有8个Streams
a.每个Stream都只能单向传输
b.Steam可被配置的模式
1.从内存到外设
2.从外设到内存
3.从内存到内存
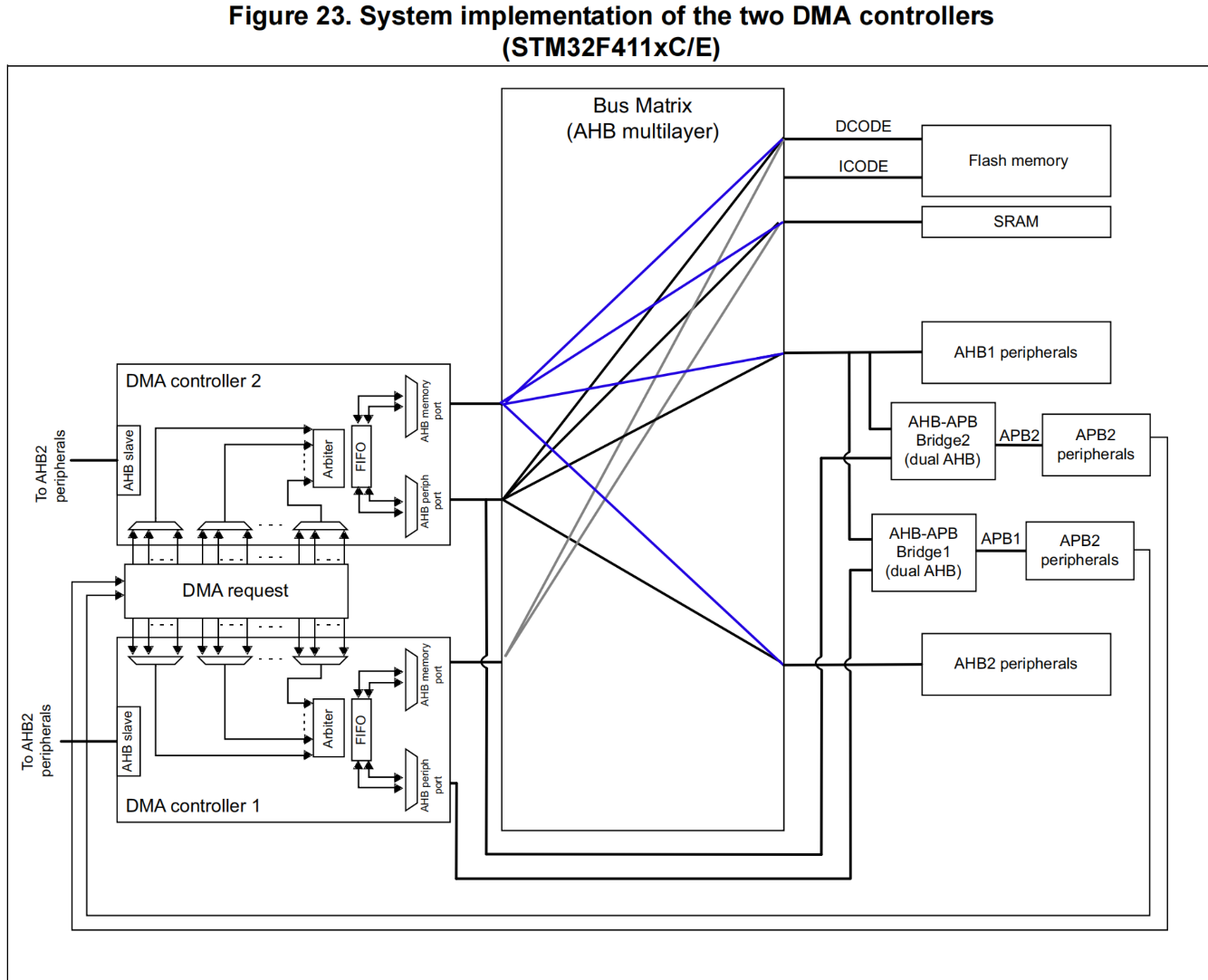
STM32F4 搭载了两个 DMA 控制器,是实现灵活数据传输的基础,先看核心参数对比:
| 控制器 | Stream 数量 | 支持 MemToMem |
|---|---|---|
| DMA1 | 8 个(Stream 0~7) | 不支持 |
| DMA2 | 8 个(Stream 0~7) | 支持 |
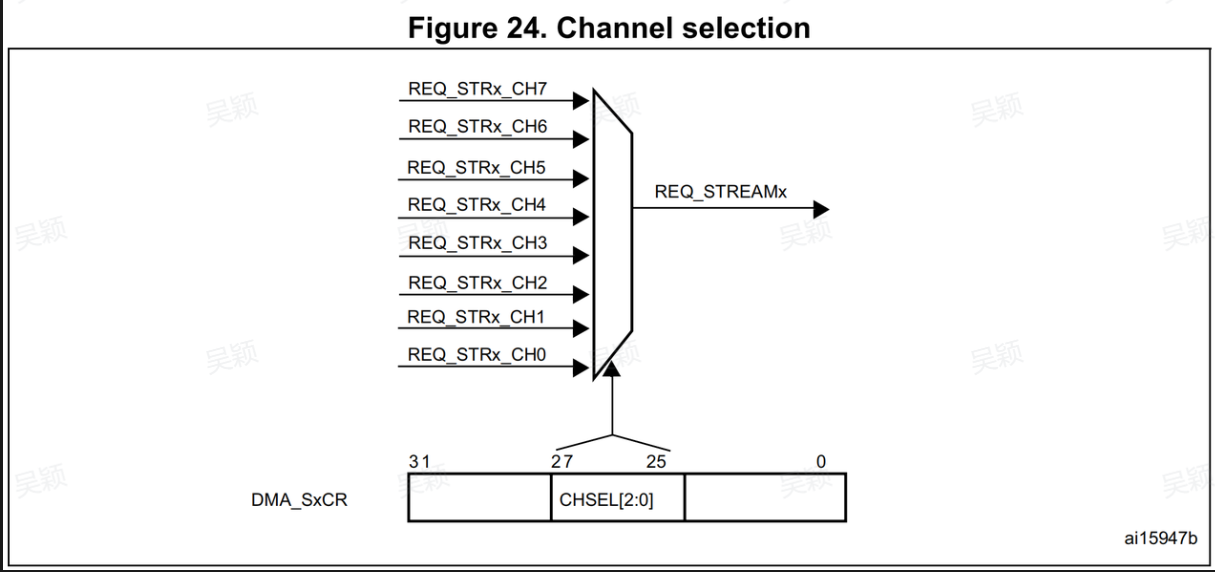
每个 Stream 下还有 8 个 Channel(通道),不同 Channel 对应不同外设的传输请求。这里有个关键注意点:同一个 Stream 不能同时服务两个 Channel,比如把 USART1_RX 和 SPI1_RX 都配到 DMA2 Stream 2,必然会出现冲突,开发时一定要避开。
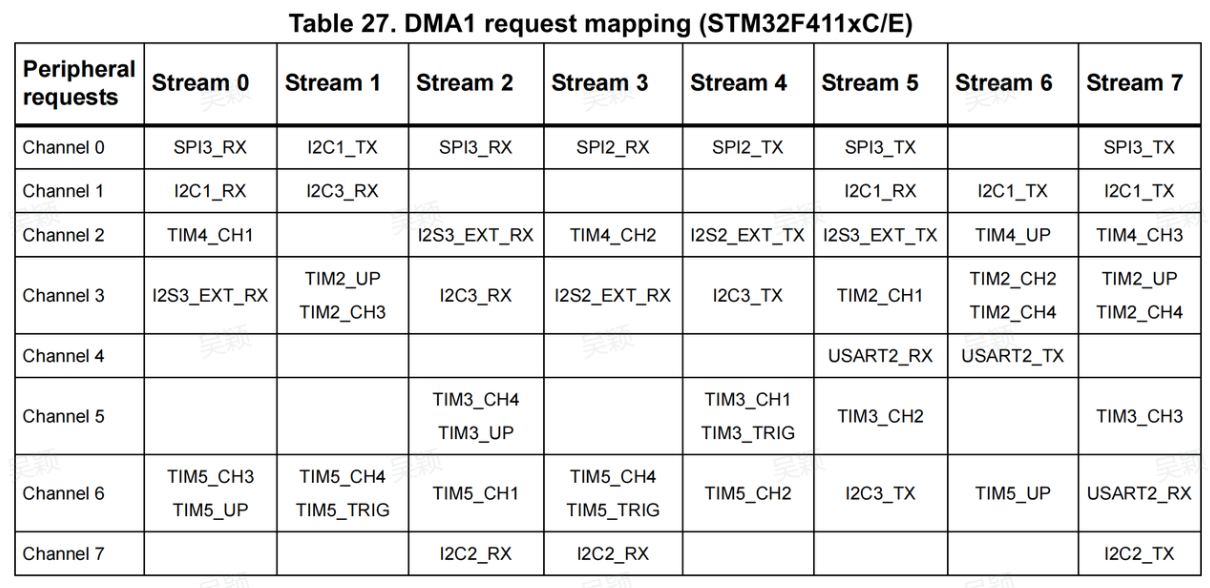
三、DMA 的三种传输方向:覆盖所有应用场景
DMA 支持三种数据传输方向,覆盖了嵌入式开发中几乎所有的数据搬运需求:
1. 外设 → 内存(Peripheral To Memory)
典型场景:UART 接收、ADC 采集、SPI 读取配置要点:
- 方向设为 Peripheral To Memory;
- 外设地址固定(比如 USART1->DR),地址不递增;
- 内存地址递增,数据连续存入缓冲区;
- 持续接收用 Circular(循环)模式,单次接收用 Normal(普通)模式。
// UART DMA 接收缓冲区示例
uint8_t rx_buf[256];
// CubeMX 配置参考:Direction=Peripheral To Memory, Mode=Circular
2. 内存 → 外设(Memory To Peripheral)
典型场景:UART 发送、SPI 写入、PWM DMA 输出配置要点:
- 方向设为 Memory To Peripheral;
- 内存地址递增,外设地址固定;
- 发送完成可通过 DMA 中断或 TC(传输完成)标志判断。
// UART DMA 发送示例
uint8_t tx_buf[] = "Hello DMA!";
HAL_UART_Transmit_DMA(&huart1, tx_buf, sizeof(tx_buf));
3. 内存 → 内存(Memory To Memory)
典型场景:大数组拷贝、数据预处理搬运配置要点:
- 仅 DMA2 支持,DMA1 不具备该功能;
- 源和目标内存地址都递增;
- 仅支持 Normal 模式,不支持 Circular;
- 可开启 Burst 传输提升效率。
// 内存到内存 DMA 拷贝示例
uint8_t src[1024], dst[1024];
HAL_DMA_Start(&hdma_memtomem_dma2_stream0, (uint32_t)src, (uint32_t)dst, 1024);
四、DMA 核心机制:搞懂这些才叫 “会用”
1. 总线仲裁:CPU 和 DMA 的 “抢总线” 规则
DMA 控制器和 CPU 都是总线主设备,通过总线仲裁器分时复用总线。STM32F4 的仲裁优先级分 4 档:Very High > High > Medium > Low。
⚠️ 注意:优先级太高会 “饿死” CPU,太低又会丢外设数据。实际项目中,USB、SDIO 等高速外设的 DMA 通常配 High 或 Very High。
2. FIFO:缓冲区的 “缓冲垫”
STM32F4 每个 DMA Stream 内置 4 字 FIFO(F1 系列无此功能),核心作用是解决外设和内存速度不匹配的问题 —— 先把数据攒在 FIFO 里,攒够了再一次性写入目标,提升传输效率。
FIFO 阈值决定 “攒够” 的标准:1/4 Full、1/2 Full、3/4 Full、Full。不开 FIFO 也能工作,但开启后效率更高,尤其配合 Burst 传输时。
FIFO 的作用:
-
减少 AHB 带宽的占用,减少 AHB 总线的仲裁,让 CPU 能够在 AHB 总线上占用更大的带宽而不需要和 DMA 经常竞争总线。(DMA 接收数据时可以旁路 AHB 总线)
-
减少溢出,在需要动态扩展内存时,DMA 会暂存数据进入 FIFO,给 CPU 执行动态扩展内存争取时间,防止溢出。
-
DMA 多路 Stream 仲裁时,FIFO 可以多路 Stream 缓冲,极大提高并发性。
3. Burst 传输:一次搬 “一箱”,而非一次搬 “一个”
- 普通模式:搬 1 个数据,发 1 次总线请求;
- Burst 模式:连续搬 4/8/16 个数据,仅发 1 次总线请求。
为了确保数据一致性,构成突发传输的每组传输都是不可分割的:AHB 传输被锁定,AHB 总线矩阵的仲裁器在突发传输序列期间不会撤销 DMA 主设备的授权。
这种模式适合大批量连续数据搬运,能大幅减少总线仲裁的开销。
也可以通过 Burst 进行多个寄存器的同时修改,在 M2P 时同时配置多个定时器。
注意:
FIFO和Burst容易混淆概念,初学者会认为FIFO和Burst都是等待一次多少数据再行动,那岂不是冲突了吗?
其实不然,FIFO是等待被填充,当数据足够时,DMA请求总线传输,请求总线以后,Burst每一次会搬运你所配置的数据。
所以这也是为什么如果不开启FIFO无法配置Burst,因为不开启FIFO,一次最多也只能搬运一个数据,Burst也用不到。
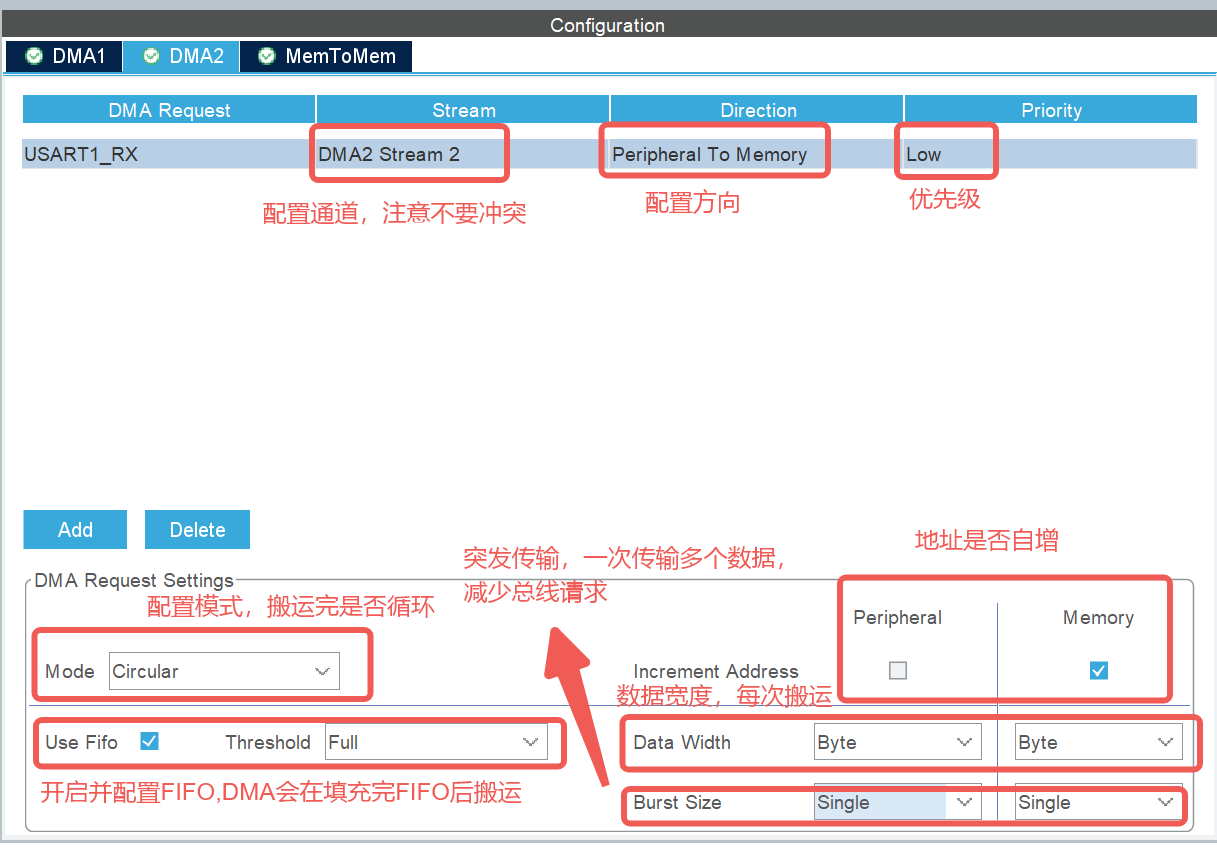
五、CubeMX 配置速查:新手也能一次配对
以 USART1_RX 的 DMA 配置为例,整理了最常用的参数配置表,照配不踩坑:
| 参数 | 推荐配置 | 说明 |
|---|---|---|
| DMA Request | USART1_RX | 指定关联的外设 |
| Stream | DMA2 Stream 5 | 需查手册确认可用 Stream |
| Direction | Peripheral To Memory | 接收方向匹配 |
| Priority | Medium | 平衡 CPU 和 DMA 资源 |
| Mode | Circular | 适配持续接收场景 |
| Peripheral Inc | 不勾选 | 外设地址固定 |
| Memory Inc | 勾选 | 内存地址递增存数据 |
| Data Width | Byte | 匹配 UART 8 位数据宽度 |
| Use FIFO | 可选 | 开启需配合 Burst 提升效率 |
六、避坑指南:这些错误 90% 的开发者都踩过
- 地址递增配反:外设接收时勾选了 Peripheral Increment,导致 DMA 读错地址,数据全乱;
- 数据宽度不匹配:外设是 8 位(如 UART),内存配成 16 位,引发数据错位、高字节丢失;
- 循环模式忘开:持续接收场景用 Normal 模式,收一次就停,后续数据全部丢失;
- 数据竞争:DMA 和 CPU 同时写同一块内存,未做同步(关中断 / 信号量),读到 “脏数据”;
- 漏开 DMA 时钟:DMA1 挂在 AHB1 总线,需通过
__HAL_RCC_DMA1_CLK_ENABLE()开启时钟。
七、DMA 中断 & 回调:精准把控传输状态
STM32F4 每个 DMA Stream 有 5 个核心中断标志,对应不同的传输状态:
| 标志 | 含义 |
|---|---|
| TC | Transfer Complete — 传输完成 |
| HT | Half Transfer — 半传输完成(双缓冲核心) |
| TE | Transfer Error — 传输错误 |
| DME | Direct Mode Error |
| FE | FIFO Error |
HAL 库提供了友好的回调函数,方便开发者处理中断:
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart); // 传输全部完成
void HAL_UART_RxHalfCpltCallback(UART_HandleTypeDef *huart); // 半传输完成
其中,半传输中断(HT)是实现双缓冲(AB Buffer)的关键 ——CPU 处理 A 半区数据时,DMA 继续往 B 半区写数据,实现零拷贝并行处理。
八、面试高频问题:吃透这些,面试官都点头
- Q:DMA 和 CPU 为什么会冲突?怎么解决?A:两者都是总线主设备,同时访问总线会冲突;通过总线仲裁器按优先级分配总线使用权解决。
- Q:Circular 模式和 Normal 模式的区别?A:Normal 模式搬完一次就停止;Circular 模式搬完自动从头开始,适合持续数据流场景。
- Q:为什么需要 FIFO?A:解决外设和内存速度不匹配问题,减少总线访问次数,配合 Burst 传输提升效率。
- Q:DMA1 和 DMA2 的核心区别?A:DMA2 支持 MemToMem 传输,DMA1 不支持;DMA2 还支持更多外设映射。
- Q:DMA 双缓冲(Double Buffer)是什么?A:利用 HT/TC 中断,CPU 处理 A 半区时 DMA 写 B 半区,反之亦然,实现零拷贝并行。
- Q:DMA 传输的数据量有限制吗?A:NDTR 寄存器是 16 位,单次最大传输 65535 个数据单元,超过需软件续传。
总结
DMA 是 STM32F4 开发中提升系统效率的 “利器”,核心是让独立的硬件控制器完成数据搬运,释放 CPU 算力。掌握它的核心要点:
- 本质:独立总线主设备,实现数据并行搬运;
- 适用场景:批量数据传输、高速外设交互、需要并行处理的场景;
- F4 特性:双控制器(DMA1/DMA2)、支持 FIFO/Burst、仅 DMA2 支持 MemToMem;
- 配置关键:方向、地址递增、数据宽度、模式、优先级;
- 避坑重点:地址递增、数据宽度、循环模式的正确配置,以及总线优先级的平衡。
嵌入式技术是硬功夫,也是细活儿。尽管我已经反复推敲,但受限于个人水平,文中难免存在疏漏或理解偏差。
如果各位读者发现文中有知识点错误、逻辑漏洞,或者涉及到版权/侵权问题,恳请不吝赐教或直接联系我。技术的进步在于分享与纠错,我希望这篇博客不仅能帮到你,也能在大家的反馈中不断进化。
感谢阅读,我们下期见。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)