DMA 全深度解析(2):AB-buffer的实现
前言
上次我们学习了DMA的原理,今天我们来学习与DMA密切相关的场景AB-buffer(乒乓缓冲区)。
在嵌入式开发中,连续数据流处理是绕不开的基础需求 —— 从传感器 ADC 采集、音频数据收发、高速串口 / 网口数据接收,到高速总线数据读写,几乎所有需要 **“一边接收、一边处理”** 的场景,都会面临同一个核心矛盾:数据产生是连续不间断的,而数据处理是离散且耗时的。
以最常见的 ADC 采集为例:DMA 虽能让数据 “自动搬家” 到内存,无需 CPU 干预,但如果 DMA 写缓冲区的同时,CPU 去读这片内存,轻则数据错乱,重则直接触发系统异常。如何让数据接收和数据处理真正并行工作、互不干扰?AB 双缓冲(Ping-Pong Buffer) 正是解决这类问题的经典、通用、高效的编程思想。
它不局限于 ADC、DMA 或某一种硬件,而是一套适用于所有 “生产者 - 消费者” 模型的底层设计范式 ——ADC 只是我们用来落地、验证、讲解这套思想的最佳实践载体。
本文基于 STM32F4 + FreeRTOS + HAL 库,从零实现一套完整的 AB 缓冲 ADC-DMA 采集系统,不仅解决数据读写冲突,还包含互斥锁保护、优先级继承演示和背压检测,兼顾实用性与进阶特性。
对于没有OS基础或者只想了解ABbuffer原理的,我的建议是主要了解ABbuffer的核心架构设计即可,现在是AI时代,了解架构的原理、和如何设计架构是非常重要的。
一、AB 双缓冲的核心思路
AB 双缓冲的本质是 “分时复用、交替工作”:
- 当 DMA 往 Buffer A 填充 ADC 数据时,CPU 专心处理 Buffer B 中的已有数据;
- 当 Buffer B 被 DMA 填满后,立即切换角色:DMA 转向写 Buffer B,CPU 开始处理 Buffer A;
- 周而复始,采集和处理全程无冲突,最大化利用 CPU 和 DMA 资源。
二、系统架构设计
2.1 数据流与任务分工
整个系统分为两大核心线程 + 一个中断回调,分工明确:
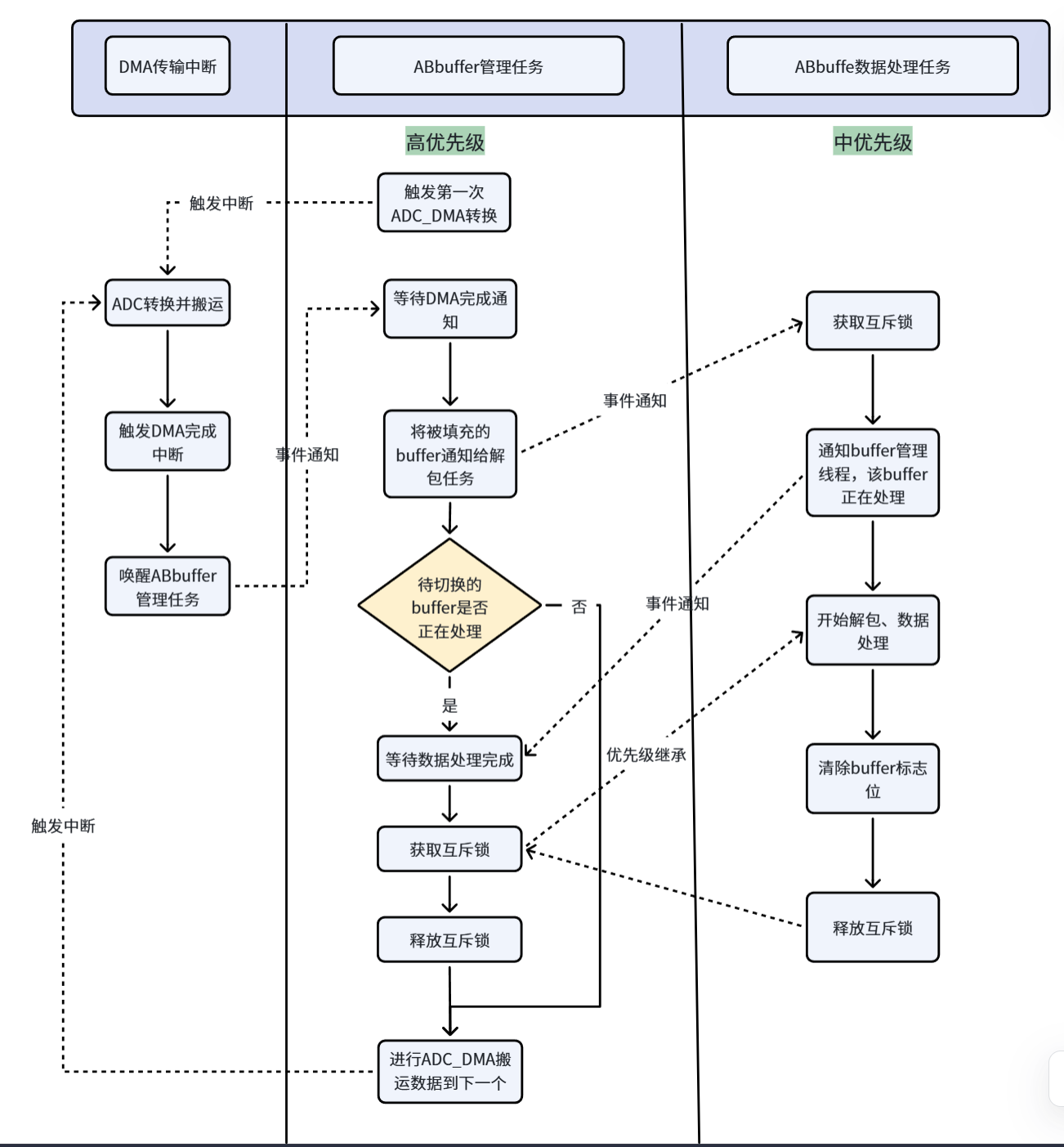
- 管理线程(生产者):高优先级,负责 DMA 启停、缓冲区切换、背压检测,是采集流程的 “总指挥”;
- 处理线程(消费者):普通优先级,负责数据换算、业务处理,是数据的 “加工中心”;
- DMA 完成中断:桥梁作用,通知管理线程 “当前缓冲区已填满”。
2.2 轻量级同步机制
系统摒弃复杂的信号量 / 队列,采用 “单互斥锁 + 任务通知” 实现同步,资源占用更少:
| 标志位 | 发送方 | 接收方 | 核心作用 |
|---|---|---|---|
| FLAG_DMA_DONE (bit8) | ISR 回调 | 管理线程 | 告知 DMA 传输完成 |
| FLAG_BUF0_READY (bit0) | 管理线程 | 处理线程 | Buffer A 数据就绪 |
| FLAG_BUF1_READY (bit1) | 管理线程 | 处理线程 | Buffer B 数据就绪 |
| FLAG_MUTEX_HELD (bit10) | 处理线程 | 管理线程 | 标记消费者已持锁 |
| FLAG_BUF0_DONE/1_DONE | 处理线程 | 管理线程 | 标记缓冲区处理完毕 |
| g_buf_mutex | - | - | 保护缓冲区临界区 + 优先级继承 |
三、核心代码实现(基于 STM32CubeMX 框架)
3.1 CubeMX 配置要点
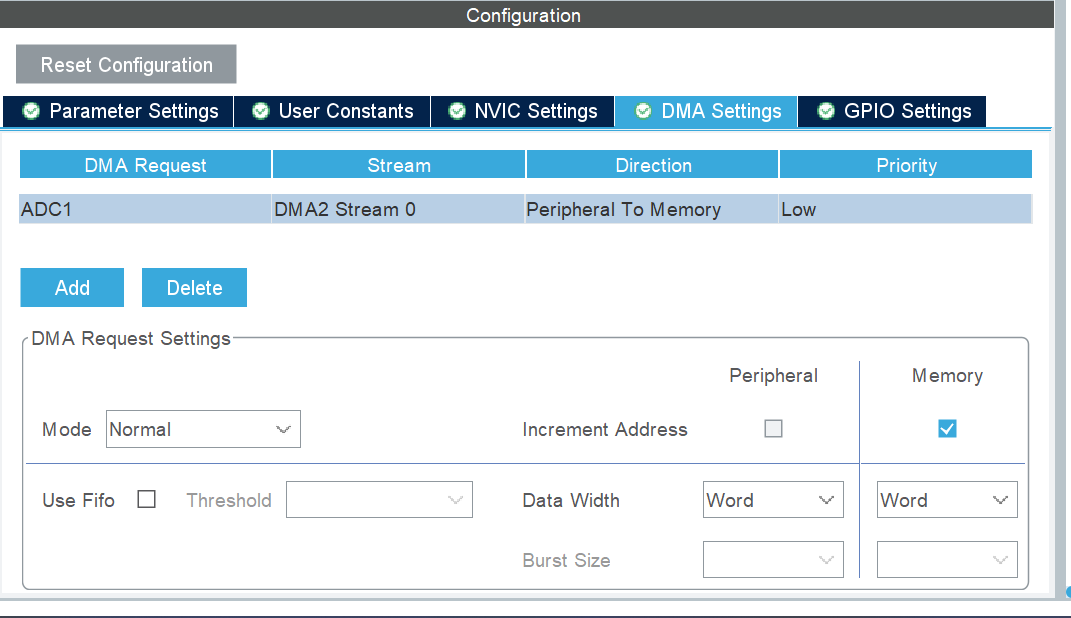
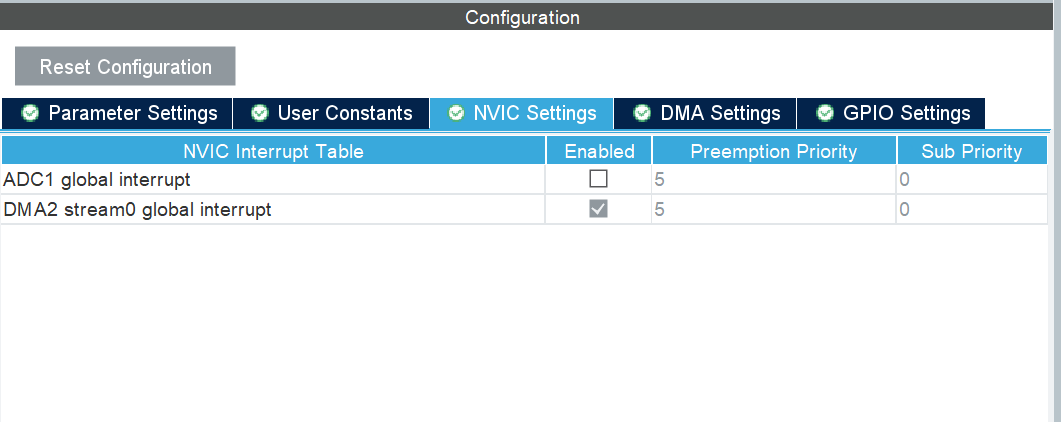
3.2 宏定义与全局变量
先定义核心配置和全局变量,统一管理缓冲区和事件标志:
/* 缓冲区配置 */
#define ADC_DMA_LENGTH 1 // DMA单次传输采样点数
#define BUF_A 0 // 缓冲区A标识
#define BUF_B 1 // 缓冲区B标识
/* 任务通知事件标志位 */
#define BIT(n) (1 << (n))
#define FLAG_BUF0_READY BIT(0) // Buffer A就绪
#define FLAG_BUF1_READY BIT(1) // Buffer B就绪
#define FLAG_BUF0_DONE BIT(2) // Buffer A处理完成
#define FLAG_BUF1_DONE BIT(3) // Buffer B处理完成
#define FLAG_DMA_DONE BIT(8) // DMA传输完成(ISR→线程)
#define FLAG_MUTEX_HELD BIT(10) // 消费者已持锁
/* 辅助宏:通道→标志位映射 */
#define BUF_READY_FLAG(ch) ((ch) == BUF_A ? FLAG_BUF0_READY : FLAG_BUF1_READY)
#define BUF_DONE_FLAG(ch) ((ch) == BUF_A ? FLAG_BUF0_DONE : FLAG_BUF1_DONE)
/* 全局核心变量 */
static uint32_t adc_buf[2] = {0}; // AB双缓冲区
static SemaphoreHandle_t g_buf_mutex; // 互斥锁(单锁保护)
static volatile uint8_t write_ch = BUF_A; // 当前DMA写通道
static volatile uint8_t read_ch = BUF_A; // 当前CPU读通道
static uint8_t buf_pending[2] = {0, 0}; // 缓冲区待处理标志
3.3 任务初始化:优先级与互斥锁
创建线程时区分优先级,确保管理线程优先响应;提前初始化互斥锁避免竞态:
/* 管理线程(高优先级):Normal + 4 */
const osThreadAttr_t adc_manager_task_attributes = {
.name = "adc_manager",
.stack_size = 128 * 4,
.priority = (osPriority_t) osPriorityNormal + 4,
};
/* 处理线程(普通优先级):Normal */
const osThreadAttr_t adc_process_task_attributes = {
.name = "adc_process",
.stack_size = 128 * 4,
.priority = (osPriority_t) osPriorityNormal,
};
void MX_FREERTOS_Init(void) {
// 创建互斥锁
g_buf_mutex = xSemaphoreCreateMutex();
// 创建管理线程(生产者)
adc_manager_task_handle = osThreadNew(adc_dma_manager_task, NULL,
&adc_manager_task_attributes);
// 创建处理线程(消费者)
adc_process_task_handle = osThreadNew(adc_data_process_task, NULL,
&adc_process_task_attributes);
}
3.4 管理线程:采集流程的 “总指挥”
核心逻辑是等待 DMA 完成→通知处理→切换缓冲区→背压检测→启动下一次 DMA:
void adc_dma_manager_task(void *argument)
{
uint32_t notify_bits = 0;
HAL_StatusTypeDef hal_ret;
// 首次启动DMA:写入Buffer A
hal_ret = HAL_ADC_Start_DMA(&hadc1, &adc_buf[write_ch], ADC_DMA_LENGTH);
if (hal_ret != HAL_OK) while (1); // 启动失败挂起
for (;;) {
// 步骤1:等待DMA传输完成(过滤无效通知)
do {
xTaskNotifyWait(0x00, FLAG_DMA_DONE, ¬ify_bits, portMAX_DELAY);
} while (0 == (notify_bits & FLAG_DMA_DONE));
buf_pending[write_ch] = 1; // 标记数据待处理
// 步骤2:通知处理线程“数据就绪”
xTaskNotifyAndQuery(adc_process_task_handle,
BUF_READY_FLAG(write_ch), eSetBits, ¬ify_bits);
// 步骤3:等待处理线程确认持锁(保证时序)
xTaskNotifyWait(0x00, FLAG_MUTEX_HELD, ¬ify_bits, portMAX_DELAY);
// 步骤4:优先级继承演示(高优先级请求锁,自动提升低优先级线程)
if (buf_pending[write_ch] == 1) {
if (xSemaphoreTake(g_buf_mutex, portMAX_DELAY) == pdPASS) {
vTaskDelay(pdMS_TO_TICKS(10)); // 模拟锁占用
xSemaphoreGive(g_buf_mutex);
}
}
// 步骤5:乒乓切换缓冲区
write_ch = (write_ch == BUF_A) ? BUF_B : BUF_A;
// 步骤6:背压检测(防止覆盖未处理数据)
if (notify_bits & BUF_READY_FLAG(write_ch)) {
xTaskNotifyWait(0x00, BUF_DONE_FLAG(write_ch),
¬ify_bits, portMAX_DELAY);
}
// 步骤7:启动下一次DMA
HAL_ADC_Start_DMA(&hadc1, &adc_buf[write_ch], ADC_DMA_LENGTH);
osDelay(100); // 采集间隔(可替换为定时器触发)
}
}
3.5 处理线程:数据的 “加工中心”
等待数据就绪→加锁处理→换算电压→通知完成,全程保护临界区:
void adc_data_process_task(void *argument)
{
uint32_t notify_bits = 0;
float adc_voltage = 0.0f;
for (;;) {
// 步骤1:等待数据就绪通知(不清除标志位,用于判断缓冲区)
xTaskNotifyWait(0x00, 0x00, ¬ify_bits, portMAX_DELAY);
// 判断哪个缓冲区就绪
if (notify_bits & FLAG_BUF0_READY) {
read_ch = BUF_A;
} else if (notify_bits & FLAG_BUF1_READY) {
read_ch = BUF_B;
} else {
notify_bits = 0;
continue; // 无效通知忽略
}
// 步骤2:加锁 + 通知管理线程“已持锁”
if (xSemaphoreTake(g_buf_mutex, portMAX_DELAY) == pdPASS) {
xTaskNotify(adc_manager_task_handle, FLAG_MUTEX_HELD, eSetBits);
// 步骤3:数据处理(12位ADC值→电压换算)
adc_voltage = (float)(adc_buf[read_ch] & 0x0FFF) / 4095.0f * 3.3f;
HAL_Delay(10); // 模拟业务处理耗时(滤波/上传等)
buf_pending[read_ch] = 0; // 标记处理完成
xSemaphoreGive(g_buf_mutex); // 解锁
}
// 步骤4:输出结果(可替换为业务逻辑)
elog_d("", "Process: ch%d | raw=0x%04lX | voltage=%.3fV",
read_ch, adc_buf[read_ch] & 0x0FFF, adc_voltage);
// 步骤5:通知管理线程“处理完毕”+ 清除就绪标志
ulTaskNotifyValueClear(adc_process_task_handle, BUF_READY_FLAG(read_ch));
xTaskNotify(adc_manager_task_handle, BUF_DONE_FLAG(read_ch), eSetBits);
notify_bits = 0; // 重置掩码
}
}
3.6 ISR 回调:中断与线程的 “桥梁”
DMA 完成后,通过中断安全的 API 通知管理线程,避免阻塞:
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc)
{
UNUSED(hadc);
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
// 中断中通知管理线程:DMA传输完成
xTaskNotifyFromISR(adc_manager_task_handle,
FLAG_DMA_DONE, eSetBits,
&xHigherPriorityTaskWoken);
// 唤醒高优先级任务,立即调度
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
四、运行效果与验证
4.1 典型日志输出
通过 SEGGER RTT Viewer 查看运行日志,核心信息如下:
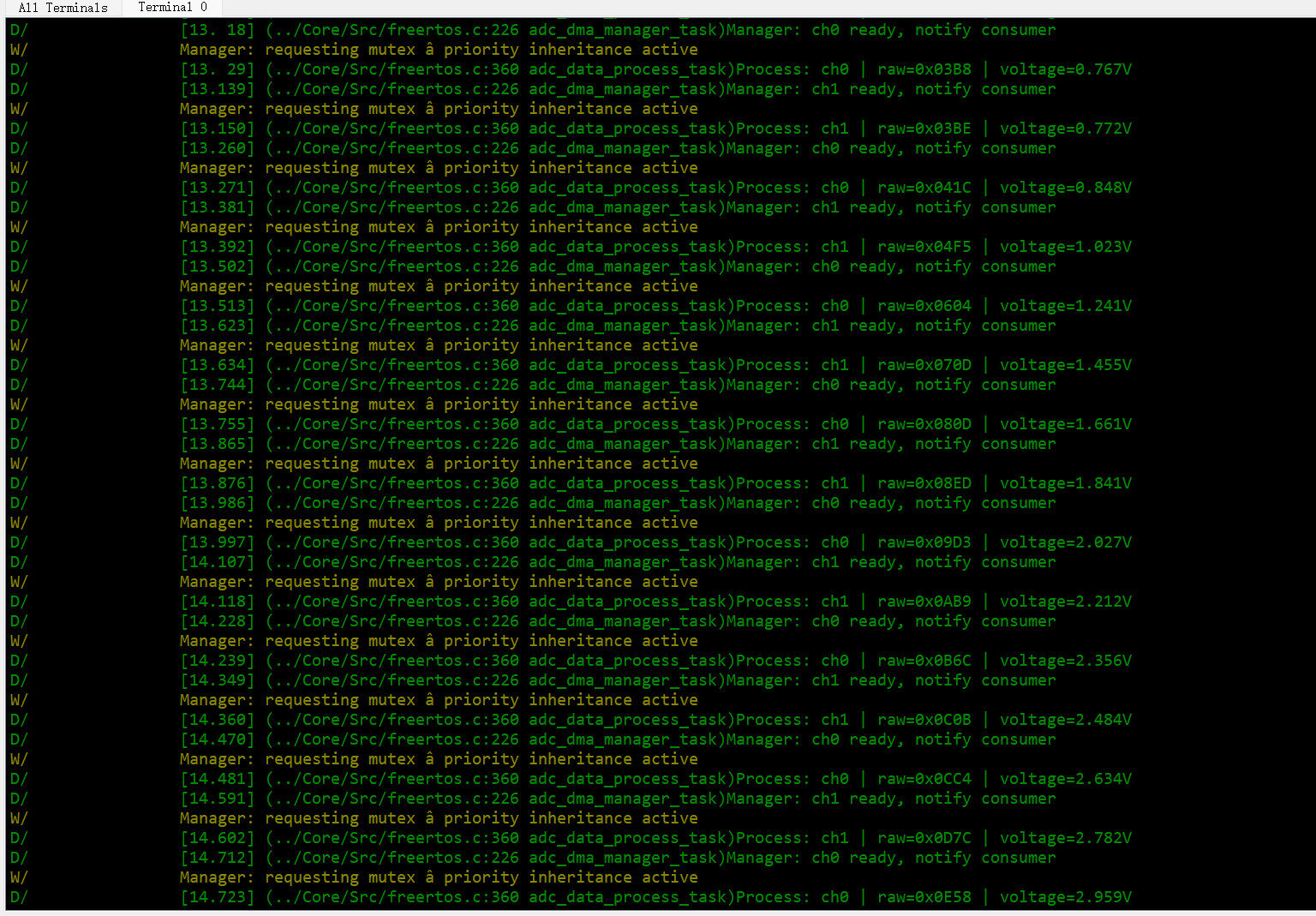
4.2 关键验证点
- 乒乓切换:日志中 ch0/ch1 交替出现,证明 AB 缓冲切换正常;
- 优先级继承:出现 “priority inheritance active”,说明高优先级管理线程请求锁时,FreeRTOS 自动提升处理线程优先级,避免优先级反转;
- 数据正确性:ADC 原始值与电压换算匹配(如 0x0D7C≈2.782V),无数据错乱;
- 背压保护:若处理耗时超过采集间隔,管理线程会阻塞等待,不会覆盖未处理数据。
五、核心设计亮点与扩展方向
5.1 设计亮点
- 单锁极简:一把互斥锁同时保护缓冲区读写和实现优先级继承,无需额外同步组件;
- 背压检测:通过 buf_pending 和任务通知,避免 “生产快于消费” 导致的数据丢失;
- 中断安全:全程使用 FromISR 版本 API,符合 FreeRTOS 中断编程规范;
- 优先级继承:利用 FreeRTOS 互斥锁内置机制,解决优先级反转问题。
5.2 扩展方向
- 增大缓冲区:将 ADC_DMA_LENGTH 改为 50~100,配合滑动平均滤波,提升采样平滑度;
- 定时器触发:用 TIM 的 TRGO 事件触发 ADC,替代 osDelay 实现精确等间隔采样;
- 低功耗优化:在 osDelay 期间让 MCU 进入 Sleep 模式,由 DMA 中断唤醒,降低功耗;
- 多通道采集:开启 ADC 扫描模式,配合 DMA 实现多通道轮流采集,适配复杂场景;
- 数据校验:增加 CRC 校验或数据范围检查,提升鲁棒性。
六、总结
本文实现的 AB 双缓冲 ADC-DMA 采集系统,完美解决了 “连续采集” 与 “离散处理” 的异步矛盾,核心是通过 “乒乓切换 + 互斥锁 + 任务通知”,让 DMA 采集和 CPU 处理并行工作。
下一篇,我将进行环形缓冲区的实现
嵌入式技术是硬功夫,也是细活儿。尽管我已经反复推敲,但受限于个人水平,文中难免存在疏漏或理解偏差。
如果各位读者发现文中有知识点错误、逻辑漏洞,或者涉及到版权/侵权问题,恳请不吝赐教或直接联系我。技术的进步在于分享与纠错,我希望这篇博客不仅能帮到你,也能在大家的反馈中不断进化。
感谢阅读,我们下期见。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)