DMA 全深度解析(4):DMA+PWM实现单总线协议
本文介绍了利用STM32的DMA+TIM PWM实现非标准时序协议的高效通信方案。针对WT588F02B语音模块的一线串口协议,传统CPU软件延时方式会完全占用CPU资源(11.4ms/字节),而DMA方案通过预存比较值数组,由DMA自动搬运到定时器CCR寄存器生成精确PWM波形,使CPU仅在准备数据时短暂工作(<1us),其余时间完全空闲。该方案具有硬件定时精度、零CPU占用、支持多任务等
一、前言
在嵌入式开发中,除了常见的 UART、SPI、I2C 等标准协议,还存在大量非标准时序协议:DHT11 温湿度传感器的单总线协议、红外遥控的 38kHz 调制、WS2812 彩灯的归零码、语音模块的一线串口…… 这些协议没有硬件外设直接支持,传统做法只能用 CPU 软件延时 + GPIO 翻转 来 “bit-bang” 实现。
这种方式有一个致命问题:CPU 被完全占用。发送一个字节需要 6~8ms 的阻塞延时,期间 CPU 什么都干不了 —— 任务调度被阻塞、中断响应被延迟、实时性荡然无存。
**DMA 内存到外设(Memory-to-Peripheral)** 就是解决这个问题的利器:
- CPU 只需把时序波形的比较值预先填入数组
- DMA 自动将数组中的值逐个搬运到定时器的比较寄存器
- 定时器产生 PWM 波形,精确控制每个 bit 的高 / 低电平时间
- CPU 完全解放,DMA 传输期间可以执行其他任务
本文基于 STM32F4 + TIM2 PWM + DMA 实现 WT588F02B 语音模块的一线串口通信,通过与传统 CPU 控制方式的对比,展示 DMA 在时序发送场景中的优越性。
想动手的可以看看代码实现
想做了解的,主要看第二章和第四章原理实现即可;
二、一线串口协议和原理分析
2.1 协议时序
WT588F02B 是一款常用的语音播放模块,通过一线串口(单根数据线)与 MCU 通信。协议时序如下:
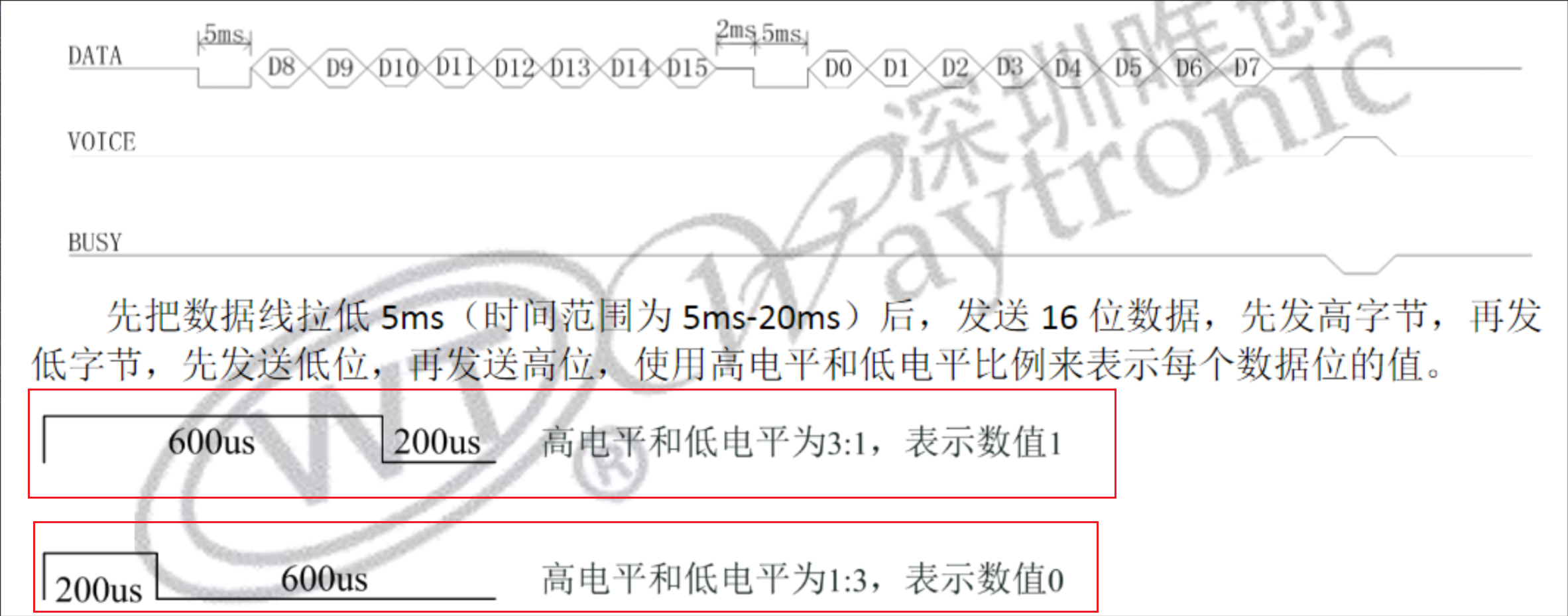
2.2 关键参数
| 参数 | 值 | 说明 |
|---|---|---|
| 起始信号 | DATA=LOW 5ms | 拉低数据线 5ms 启动通信 |
| 逻辑 "1" | HIGH 600us + LOW 200us | 高电平长,低电平短 |
| 逻辑 "0" | HIGH 200us + LOW 600us | 高电平短,低电平长 |
| 单 bit 周期 | 800us | 无论 0 或 1,总时长相同 |
| 8 bit 总耗时 | 6.4ms | 不含起始信号 |
| 字节间延时 | 2~5ms | 连码发送时需要 |
2.3 通信原理
分析发现,上述通信时序中,每个数据位都为周期800us的方波,数据1的高电平时间为600us,数据0的高电平时间为200us,并且都是高电平在前,低电平在后。 这种波形其实就是一个占空比在变化的PWM波,其具有两种占空比,很容易想到使用定时器的PWM输出来实现,将定时器的周期配置为800us,对于数据1和数据0分别配置不同的CCR比较寄存器数值,来产生不同的占空比。
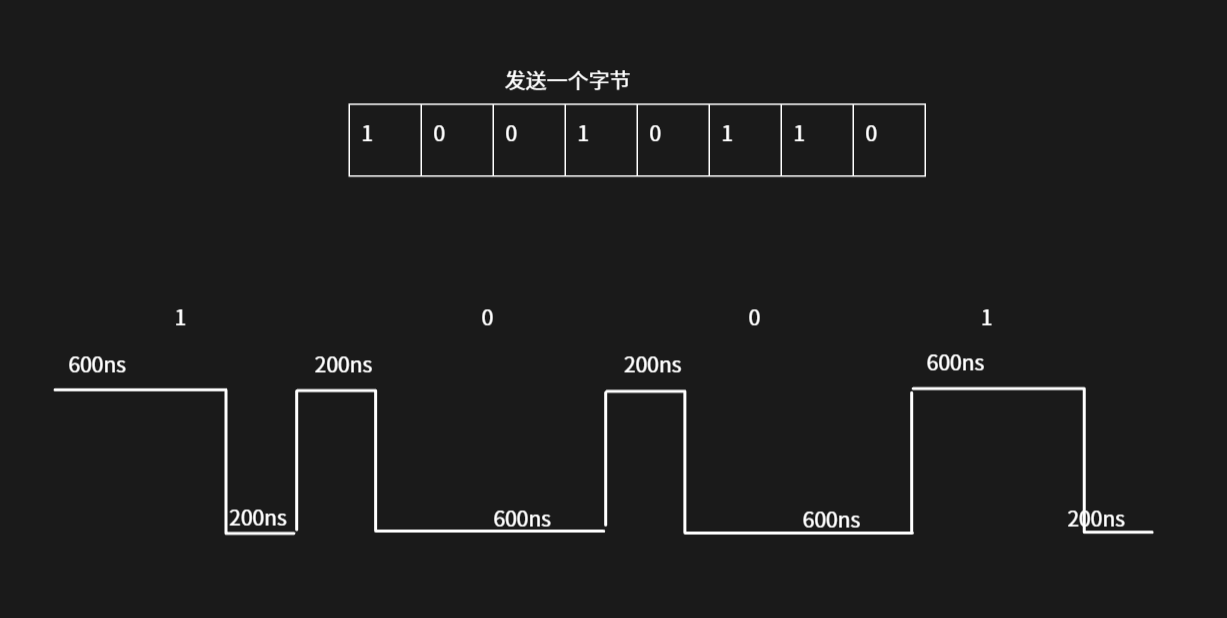
一个周期800ns,设置向上计数
当发送1时设置CCR比较寄存器为600;
当发送0时设置CCR比较寄存器为200;
现在原理已经知道,那总不能每发送一个字节中断一次,设置CCR吧,那这样的话,一个字节就需要中断8次,好像还是太麻烦了,那该怎么办呢?
我们可以使用DMA进行搬运,那总要有一个搬运的源地址吧,所以我们可以想到将对应位的CCR值放入对应的数组里面,如代码所示
uint8_t data = 0x96; //要发送的字节
uint32_t cmp_buff[8] = {0}; //DMA需要搬运的数组
for(uint8_t i=0; i<8; ++i){
if((data >> i) & 0x01) // LSB优先
cmp_buff[i] = 600; // 数据1对应的pwm比较值
else
cmp_buff[i] = 200; // 数据0对应的pwm比较值
}以上代码就可以配置好待搬运的buffer。
但是我们还得考虑到起始信号,起始信号为高电平5ms以上,每次周期为800ns,差不多时800ns *7 = 5.6ms,7个周期。所以我们可以在数组前7位设置为固定800,如代码所示:
/* 1. 根据数据位,配置 PWM 比较值数组 */
static uint32_t cmp_buff[16] = {0};
/* 前 7 个元素 = 0 → 产生 5.6ms 低电平(起始信号) */
cmp_buff[15] = 800; /* 最后一个元素,等待最后一个 Update 事件 */
for (uint8_t i = 7; i < 15; ++i) {
if (data & 0x01)
cmp_buff[i] = 600; /* 逻辑 "1":600us 高 + 200us 低 */
else
cmp_buff[i] = 200; /* 逻辑 "0":200us 高 + 600us 低 */
data = data >> 1;
}三、传统方式 vs DMA 方式对比
3.1 传统方式:CPU 软件延时(Bit-Bang)
/**
* @brief 一线串口控制程序(单字节指令)—— CPU 软件延时方式
* @param data 待发送数据
*/
void Line_1A_WT588F(uint8_t data)
{
SET_DATA_LOW; // 拉低数据线
PORT_DELAY_MS(5); // ★ CPU 阻塞 5ms
for (uint8_t i = 0; i < 8; i++) {
if (data & 0x01) { // 逻辑 "1"
SET_DATA_HIGH;
PORT_DELAY_US(600); // ★ CPU 阻塞 600us
SET_DATA_LOW;
PORT_DELAY_US(200); // ★ CPU 阻塞 200us
}
else { // 逻辑 "0"
SET_DATA_HIGH;
PORT_DELAY_US(200); // ★ CPU 阻塞 200us
SET_DATA_LOW;
PORT_DELAY_US(600); // ★ CPU 阻塞 600us
}
data = data >> 1;
}
SET_DATA_HIGH; // 拉高数据线
}
问题分析:
| 项目 | 数据 |
|---|---|
| 发送 1 字节 CPU 占用时间 | 5ms(起始)+ 8 × 800us = 11.4ms |
| 连码发送 4 字节 CPU 占用时间 | ~50ms+(含字节间延时) |
| CPU 利用率 | 100%(全程阻塞) |
| 定时精度 | 取决于 Delay_us() 实现,受中断干扰 |
| 能否响应其他任务 | 不能(阻塞在延时循环中) |
3.2 DMA 方式:TIM PWM + DMA
static volatile uint8_t tx_busy = 0; /* 发送状态标志 */
/**
* @brief wt588f 及底层外设初始化
*/
void wt588f_init()
{
/* 注册 DMA 传输完成回调 */
HAL_DMA_RegisterCallback(
htim2.hdma[TIM_DMA_ID_UPDATE],
HAL_DMA_XFER_CPLT_CB_ID,
wt588f_dma_callback
);
/* 使能定时器 Update 事件触发 DMA 请求 */
__HAL_TIM_ENABLE_DMA(&htim2, TIM_DMA_UPDATE);
HAL_Delay(200); /* WT588F02B 模块上电延时 */
}
/**
* @brief 一线串口控制程序(单字节指令)—— TIM PWM + DMA 方式
* @param data 待发送数据
*/
void wt588f_send_byte(uint8_t data)
{
/* 1. 根据数据位,配置 PWM 比较值数组 */
static uint32_t cmp_buff[16] = {0};
/* 前 7 个元素 = 0 → 产生 5.6ms 低电平(起始信号) */
cmp_buff[15] = 800; /* 最后一个元素,等待最后一个 Update 事件 */
for (uint8_t i = 7; i < 15; ++i) {
if (data & 0x01)
cmp_buff[i] = 600; /* 逻辑 "1":600us 高 + 200us 低 */
else
cmp_buff[i] = 200; /* 逻辑 "0":200us 高 + 600us 低 */
data = data >> 1;
}
/* 2. 开启 PWM 输出 */
HAL_TIM_PWM_Start(&htim2, TIM_CHANNEL_1);
/* 3. 启动 DMA:将 cmp_buff → TIM2->CCR1 */
HAL_DMA_Start_IT(
htim2.hdma[TIM_DMA_ID_UPDATE],
(uint32_t)cmp_buff, /* 源地址:比较值数组 */
(uint32_t)&htim2.Instance->CCR1, /* 目标地址:CCR1 寄存器 */
16 /* 传输 16 个字 */
);
tx_busy = 1; /* 标记发送忙 */
}
/**
* @brief DMA 传输完成回调(ISR 上下文)
*/
void wt588f_dma_callback(DMA_HandleTypeDef* _hdma)
{
if (_hdma == htim2.hdma[TIM_DMA_ID_UPDATE]) {
tx_busy = 0; /* 标记发送完成 */
HAL_TIM_PWM_Stop(&htim2, TIM_CHANNEL_1); /* 停止 PWM */
}
}
/**
* @brief 连码发送示例
*/
void wt588f_list_play()
{
wt588f_send_byte(0xF3);
while (tx_busy) {} /* 等待 DMA 完成,期间 CPU 可做其他事 */
HAL_Delay(2);
wt588f_send_byte(0x01);
while (tx_busy) {}
HAL_Delay(5);
wt588f_send_byte(0xF3);
while (tx_busy) {}
HAL_Delay(2);
wt588f_send_byte(0x02);
while (tx_busy) {}
HAL_Delay(5);
}
优势分析:
| 项目 | DMA 方式 |
|---|---|
| CPU 准备数据时间 | < 1us(填数组 + 启动 DMA) |
| DMA 传输期间 CPU 状态 | 完全空闲,可执行其他任务 |
| 定时精度 | 由硬件定时器保证,不受中断干扰 |
| 发送完成通知 | DMA 中断回调,非阻塞 |
四、DMA 实现原理详解
4.1 硬件连接
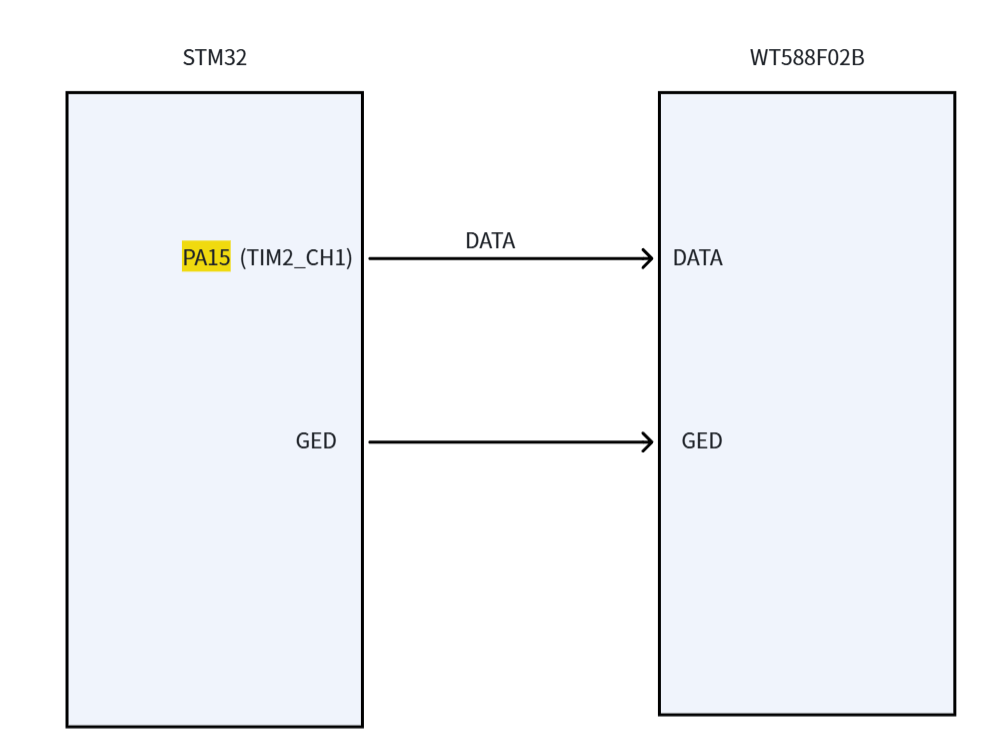
PA15 复用为 TIM2 通道 1 的 PWM 输出,通过 DMA 自动更新比较值,产生符合 WT588F 协议的波形。
4.2 DMA传输路线
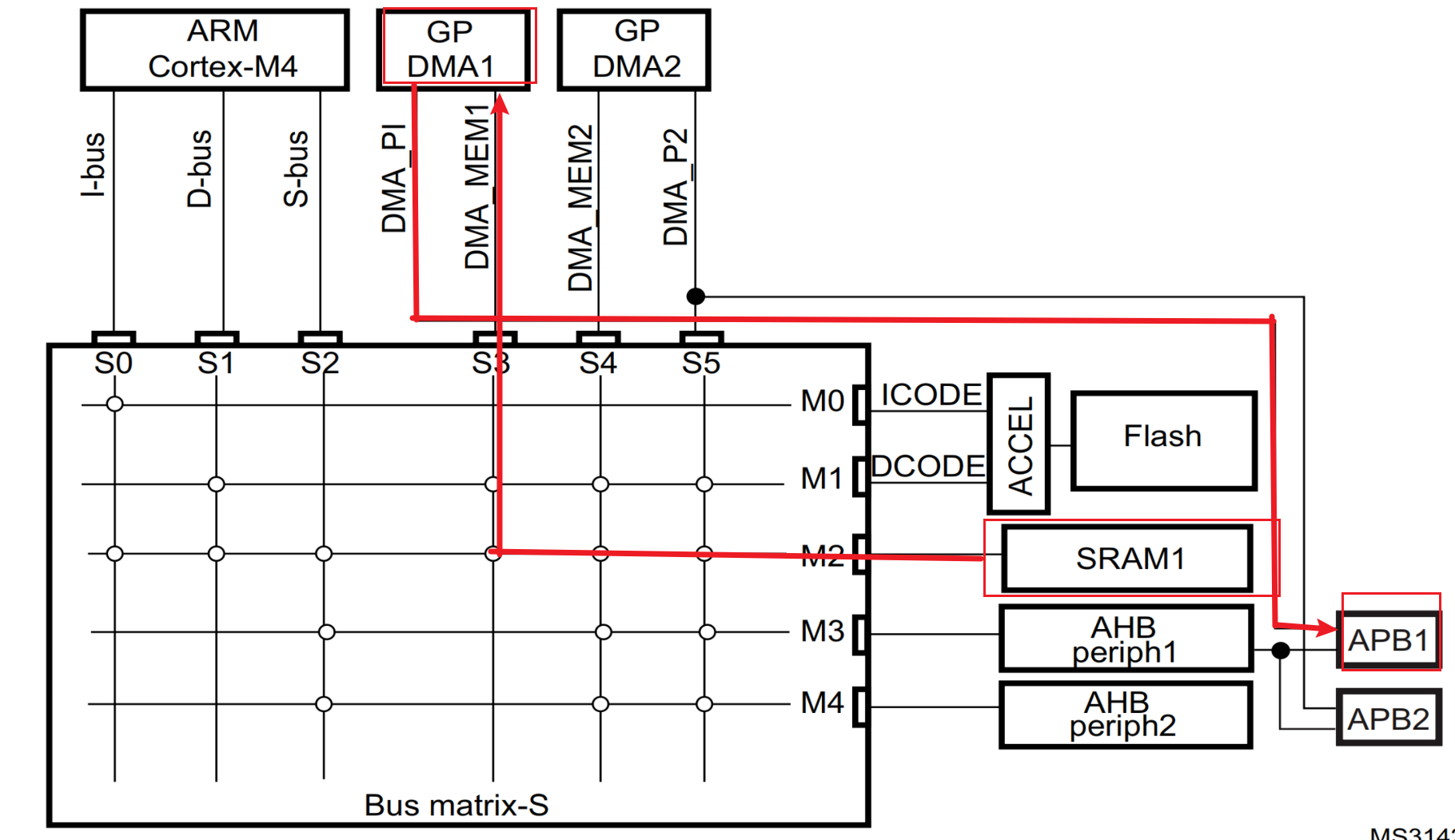
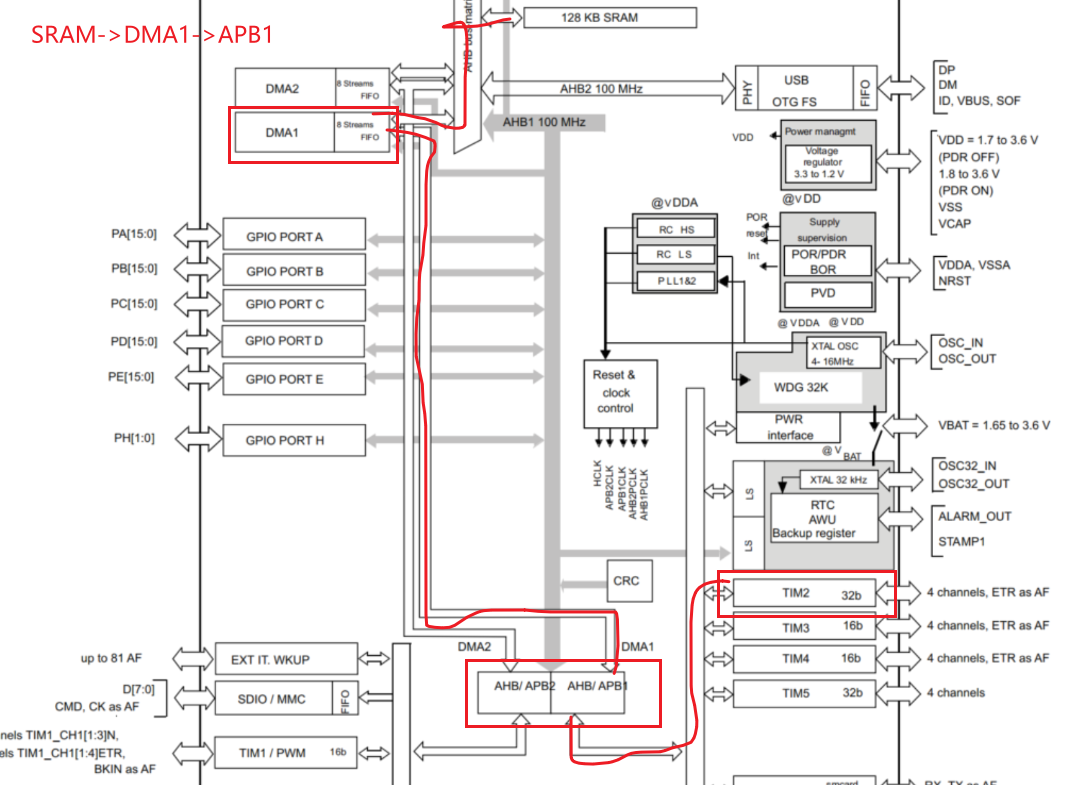
4.3 定时器配置
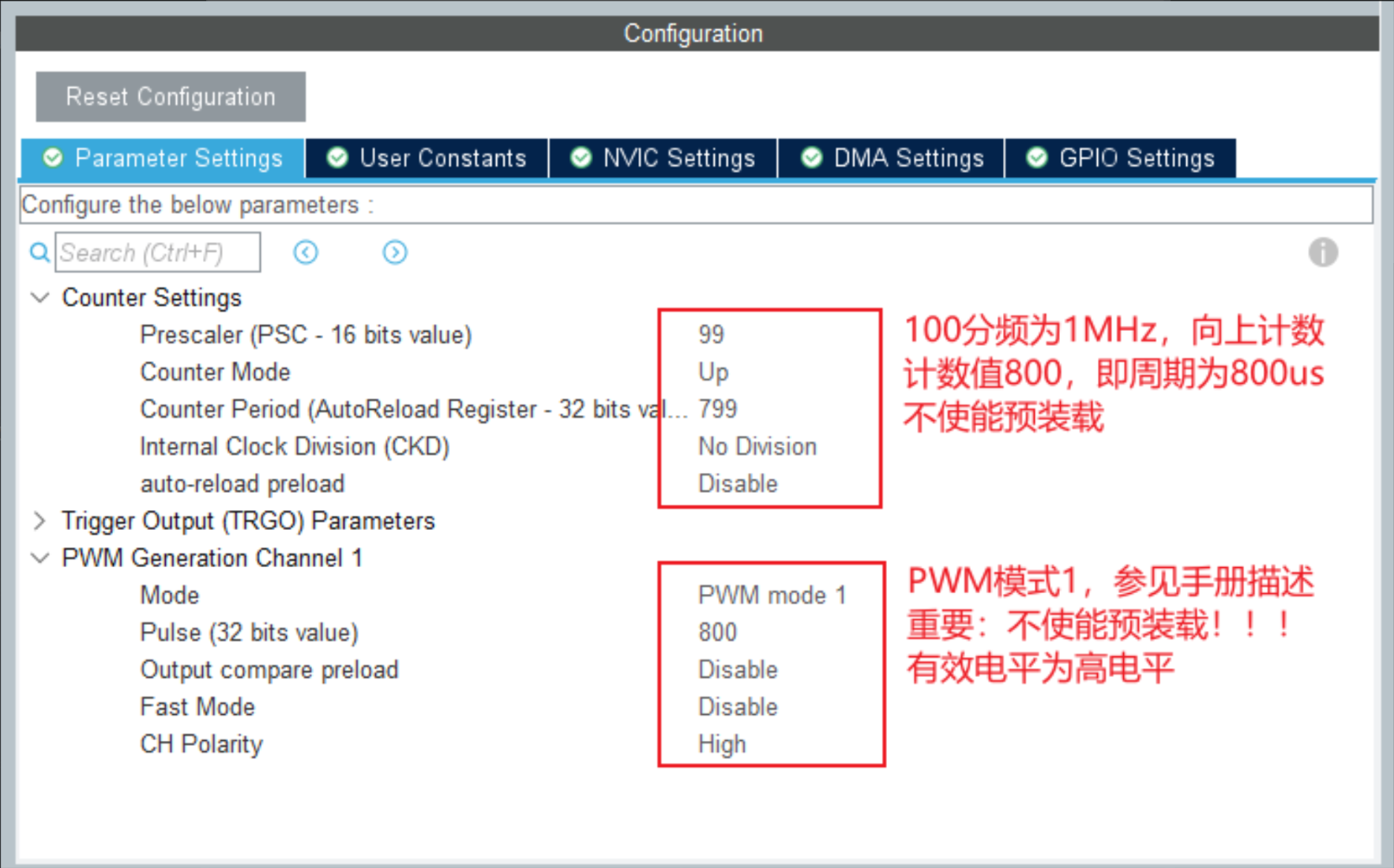
htim2.Instance = TIM2;
htim2.Init.Prescaler = 99; /* 预分频:100MHz / 100 = 1MHz */
htim2.Init.CounterMode = TIM_COUNTERMODE_UP;
htim2.Init.Period = 799; /* 自动重装:800 → 800us 周期 */
htim2.Init.ClockDivision = TIM_CLOCKDIVISION_DIV1;
htim2.Init.AutoReloadPreload = TIM_AUTORELOAD_PRELOAD_DISABLE;
/* PWM 通道配置 */
sConfigOC.OCMode = TIM_OCMODE_PWM1;
sConfigOC.Pulse = 800; /* 默认比较值(全低电平) */
sConfigOC.OCPolarity = TIM_OCPOLARITY_HIGH;
HAL_TIM_PWM_ConfigChannel(&htim2, &sConfigOC, TIM_CHANNEL_1);
/* 禁用预装载:让 DMA 写入的 CCR1 值立即生效 */
__HAL_TIM_DISABLE_OCxPRELOAD(&htim2, TIM_CHANNEL_1);
关键参数计算:
系统时钟 = 100MHz (HSE 25MHz × PLL 4倍频)
APB1 分频 = 2 → APB1 定时器时钟 = 100MHz
定时器频率 = 100MHz / (99 + 1) = 1MHz → 1us/tick
PWM 周期 = (799 + 1) × 1us = 800us ← 恰好等于 WT588F 的一个 bit 周期
逻辑 "1":CCR1 = 600 → HIGH 600us, LOW 200us
逻辑 "0":CCR1 = 200 → HIGH 200us, LOW 600us
起始信号:CCR1 = 0 → 全 LOW(无高电平)
4.4 DMA 配置
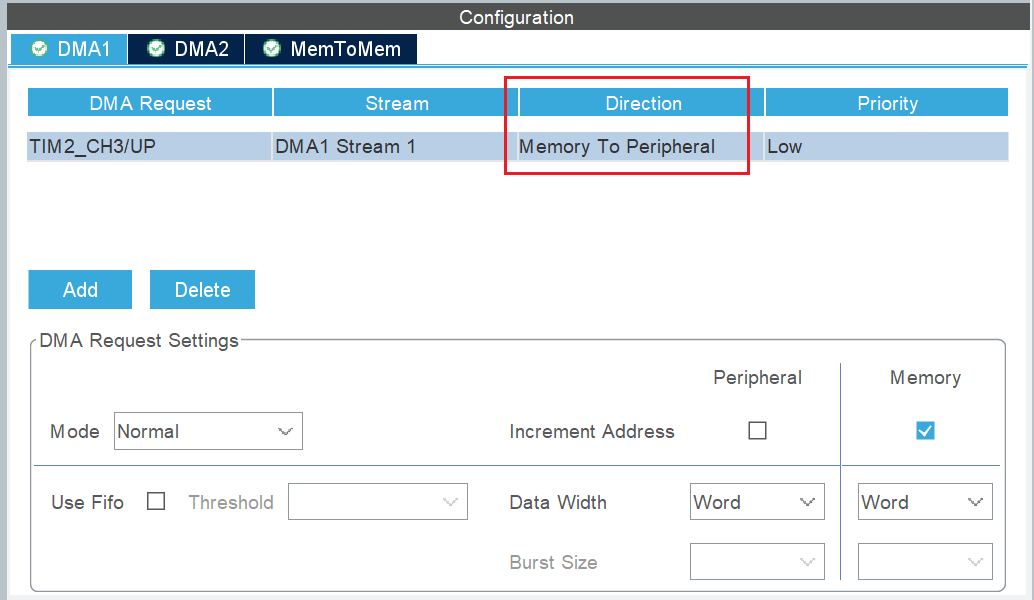
hdma_tim2_ch3_up.Instance = DMA1_Stream1;
hdma_tim2_ch3_up.Init.Channel = DMA_CHANNEL_3;
hdma_tim2_ch3_up.Init.Direction = DMA_MEMORY_TO_PERIPH; /* 内存→外设 */
hdma_tim2_ch3_up.Init.PeriphInc = DMA_PINC_DISABLE; /* 外设地址不增 */
hdma_tim2_ch3_up.Init.MemInc = DMA_MINC_ENABLE; /* 内存地址自增 */
hdma_tim2_ch3_up.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD; /* 外设 32-bit */
hdma_tim2_ch3_up.Init.MemDataAlignment = DMA_MDATAALIGN_WORD; /* 内存 32-bit */
hdma_tim2_ch3_up.Init.Mode = DMA_NORMAL; /* 单次传输 */
hdma_tim2_ch3_up.Init.Priority = DMA_PRIORITY_LOW;
DMA 传输流程:
┌───────────────────────────────────────────────────────────────┐
│ DMA 传输过程(发送 0xF3 = 11110011) │
│ │
│ cmp_buff[16] 内存数组: │
│ ┌─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┬─────┬───┐ │
│ │ [0] │ [1] │ [2] │ [3] │ [4] │ [5] │ [6] │ [7] │ [8] │...│ │
│ │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 0 │ 600 │ 600 │...│ │
│ └──┬──┴──┬──┴──┬──┴──┬──┴──┬──┴──┬──┴──┬──┴──┬──┴──┴───┘ │
│ │ │ │ │ │ │ │ │ │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ TIM2->CCR1 寄存器 │ │
│ │ 每次 Update 事件,DMA 自动搬运下一个比较值到 CCR1 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 产生的波形: │
│ [0]-[6]: CCR1=0 → 5.6ms LOW(起始信号) │
│ [7]: CCR1=600 → 600us HIGH + 200us LOW (bit0 = 1) │
│ [8]: CCR1=600 → 600us HIGH + 200us LOW (bit1 = 1) │
│ [9]: CCR1=600 → 600us HIGH + 200us LOW (bit2 = 1) │
│ [10]: CCR1=600 → 600us HIGH + 200us LOW (bit3 = 1) │
│ [11]: CCR1=200 → 200us HIGH + 600us LOW (bit4 = 0) │
│ [12]: CCR1=200 → 200us HIGH + 600us LOW (bit5 = 0) │
│ [13]: CCR1=600 → 600us HIGH + 200us LOW (bit6 = 1) │
│ [14]: CCR1=600 → 600us HIGH + 200us LOW (bit7 = 1) │
│ [15]: CCR1=800 → 等待最后一个 Update 事件 │
│ │
│ 结果:0xF3 = 11110011 ✓ │
└───────────────────────────────────────────────────────────────┘
4.5 ISR 接线
文件:
Core/Src/stm32f4xx_it.c
extern DMA_HandleTypeDef hdma_tim2_ch3_up;
/**
* @brief DMA1 Stream1 中断处理(TIM2 DMA)
*/
void DMA1_Stream1_IRQHandler(void)
{
HAL_DMA_IRQHandler(&hdma_tim2_ch3_up);
}
HAL 库的 HAL_DMA_IRQHandler 会自动检测传输完成标志,并调用通过 HAL_DMA_RegisterCallback 注册的回调函数。
4.6 展示

五、两种方式对比总结
5.1 CPU 占用对比(AI简单生成,懒得画了)
传统方式(CPU Bit-Bang):
时间轴 ──────────────────────────────────────────────▶
│▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓│
│ 5ms起始 │ bit0 │ bit1 │ ... │ bit7 │ │
│ CPU 忙 │ CPU忙 │ CPU忙 │ │ CPU忙 │ │
│ └───────┴───────┴─────┴───────┘ │
│ 全程 11.4ms CPU 被占用 │
DMA 方式(TIM PWM + DMA):
时间轴 ──────────────────────────────────────────────▶
│▓│ │▓│
│准│ DMA 自动传输中 │回│
│备│ CPU 完全空闲,可执行其他任务 │调│
│数│ │ │
│据│ │ │
│<1us│ 11.4ms │ │
5.2 关键指标对比
| 指标 | CPU Bit-Bang | TIM PWM + DMA |
|---|---|---|
| CPU 占用时间 | 11.4ms / 字节 | < 1us(准备数据) |
| CPU 利用率 | 100% | < 0.01% |
| 定时精度 | 受中断影响,抖动 ± 几 us | 硬件定时器,零抖动 |
| 能否响应中断 | 延时期间不能 | 随时可以 |
| 能否运行 RTOS 任务 | 延时期间阻塞调度 | 完全不影响 |
| 多字节连码发送 | 阻塞 50ms+ | CPU 只需间歇 < 4us |
| 代码复杂度 | 简单直观 | 稍复杂,需配置 TIM + DMA |
5.3 适用场景
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 简单裸机、无实时要求 | CPU Bit-Bang | 代码简单,无需 DMA 配置 |
| FreeRTOS 多任务系统 | TIM PWM + DMA | 不阻塞调度,保证实时性 |
| 高精度时序要求 | TIM PWM + DMA | 硬件定时,不受中断干扰 |
| 低功耗场景 | TIM PWM + DMA | DMA 期间 CPU 可进入 Sleep |
| 多外设并行操作 | TIM PWM + DMA | CPU 可同时处理其他外设 |
六、扩展应用
同样的 TIM + DMA 思路可以应用到其他时序协议:
| 协议 | 定时器配置 | DMA 比较值 | 说明 |
|---|---|---|---|
| DHT11 | 1MHz, 周期 80us | 20~70 | 起始 20ms LOW + 40bit 数据 |
| WS2812 | 8MHz, 周期 1.25us | 4~8 | 归零码,T0H=350ns, T1H=700ns |
| 红外遥控 (NEC) | 38kHz 载波 | 调制 / 不调制 | 560us 载波 + 1680us 空闲 |
| 单总线 (DS18B20) | 1MHz, 周期 60us | 10~55 | 写 0: 60us LOW, 写 1: 15us LOW |
核心思想一致:把 “什么时候翻转 GPIO” 转化为 “DMA 搬运比较值到 CCR”,用硬件替代软件延时。
七、总结
本文通过 WT588F02B 语音模块的一线串口通信,展示了 TIM PWM + DMA 内存到外设 的时序发送方案,核心设计要点:
| 要点 | 实现方式 |
|---|---|
| 精确时序 | TIM2 1MHz 计数,800us 周期 = 1 bit 周期 |
| PWM 编码 | CCR1=600 → 逻辑 "1",CCR1=200 → 逻辑 "0" |
| DMA 搬运 | DMA_MEMORY_TO_PERIPH,数组 → TIM2->CCR1 |
| 零 CPU 占用 | DMA 传输期间 CPU 完全空闲 |
| 完成通知 | DMA 中断回调 wt588f_dma_callback,非阻塞 |
| 禁用预装载 | __HAL_TIM_DISABLE_OCxPRELOAD,CCR1 立即生效 |
扩展方向
- DHT11 驱动:将同样的 TIM+DMA 思路应用于 DHT11 温湿度传感器的单总线协议
- WS2812 彩灯:8MHz 定时器 + DMA,精确控制归零码时序,驱动全彩 LED 灯带
- 红外发射:38kHz 载波调制 + DMA,实现 NEC/RC5 等红外遥控协议
- DMA 双缓冲:使用 DMA 双缓冲模式,实现无缝连续发送
嵌入式技术是硬功夫,也是细活儿。尽管我已经反复推敲,但受限于个人水平,文中难免存在疏漏或理解偏差。
如果各位读者发现文中有知识点错误、逻辑漏洞,或者涉及到版权/侵权问题,恳请不吝赐教或直接联系我。技术的进步在于分享与纠错,我希望这篇博客不仅能帮到你,也能在大家的反馈中不断进化。
感谢阅读,我们下期见。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)