K8S基础-控制器&deploy&pod回滚更新&service
一、控制器概述
Pod是K8S最小管理单元,Pod的创建方式大致可分为两类
1.自助式创建,由k8s直接创建出的Pod,直接删除就没有了,也不会重建
2.控制器创建pod,有k8s通过控制器创建的pod,这种pod删除后还会自动创建
在k8s中以有很多类型的pod控制器,每种都有自己适合的场景:
ReplicationController:比较原始的 pod 控制器,已经被废弃,由 ReplicaSet 替代 ReplicaSet:保证副本数量一直维持在期望值,并支持 pod 数量扩缩容,镜像版本升级 Deployment:通过控制 ReplicaSet 来控制 Pod,并支持滚动升级、回退版本 Horizontal Pod Autoscaler:可以根据集群负载自动水平调整 Pod 的数量,实现削峰填谷 DaemonSet:在集群中的指定 Node 上运行且仅运行一个副本,一般用于守护进程类的任务 Job:它创建出来的 pod 只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务Cronjob:它创建的 Pod 负责周期性任务控制,不需要持续后台运行 StatefulSet:管理有状态应用
二、Deployment(Deploy)
1.概述
Deployment通过控制管理Replicaset,Replicaset管理Pod,来实现对pod的管理
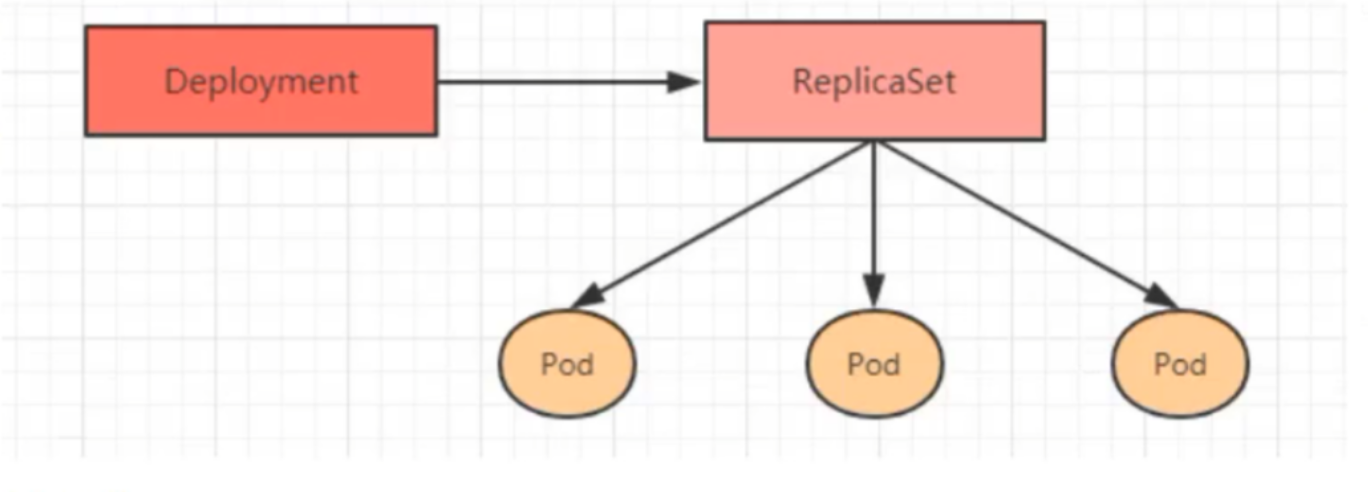
Deploy主要功能有以下几个:
支持ReplicaSe的所有功能、副本
支持发布的停止、继续
支持滚动升级和回滚版本
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: deploy
spec: # 详情描述
replicas: 3 # 副本数量
revisionHistoryLimit: 3 # 保留历史版本
paused: false # 暂停部署,默认是false
progressDeadlineSeconds: 600 # 部署超时时间(s),默认是600
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 最大不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 802.pod节点的扩容
1)创建pc-deployment
创建pc-depolyment.yaml,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: nginx-ns
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
执行上述的yaml文件
# 创建的deployment --record=true 记录版本
kubectl create -f pc-deployment.yaml --record=true
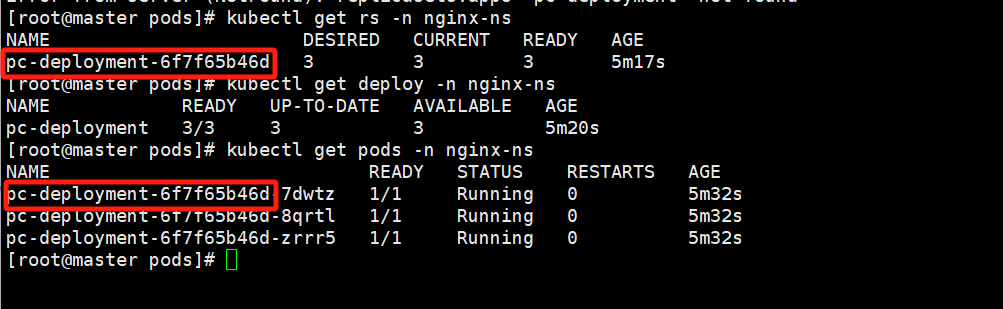
# 查看deployment
# UP-TO——DATE 最新版本的pod的数量
# AVAILABLE 当前可用的pod的数量
kubectl get deploy pc-deployment -n nginx-ns
# 查看rs
# 发现rs的名称是原来Deployment的名字后面添加了一个10位数的随机串
kubectl get rs -n nginx-ns
# 查看pod
kubectl get pods -n nignx-ns其中的pod和deploy名字是对应的
2)扩缩容
# 变更副本数量为5个
kubectl scale deploy pc-deployment --replicas=5 -n nginx-ns
# 查看deploy,看里面是否有变化
kubectl get deploy pc-deployment -n nginx-ns
# 查看pod
kubuctl get pods -n nginx-ns可以通过另一个窗口来观察他的所扩容的过程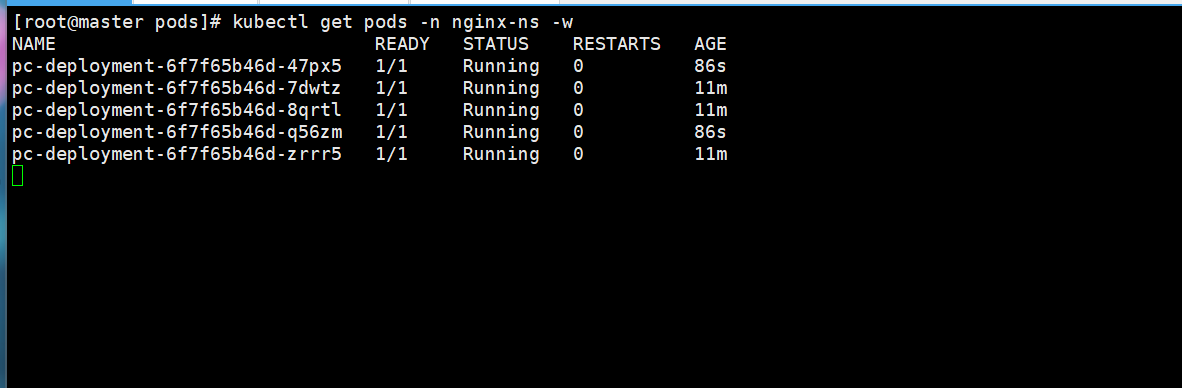
这是最初始的5个nginx的pod节点,现在给他降低到2个,这就是他的整个变化状态
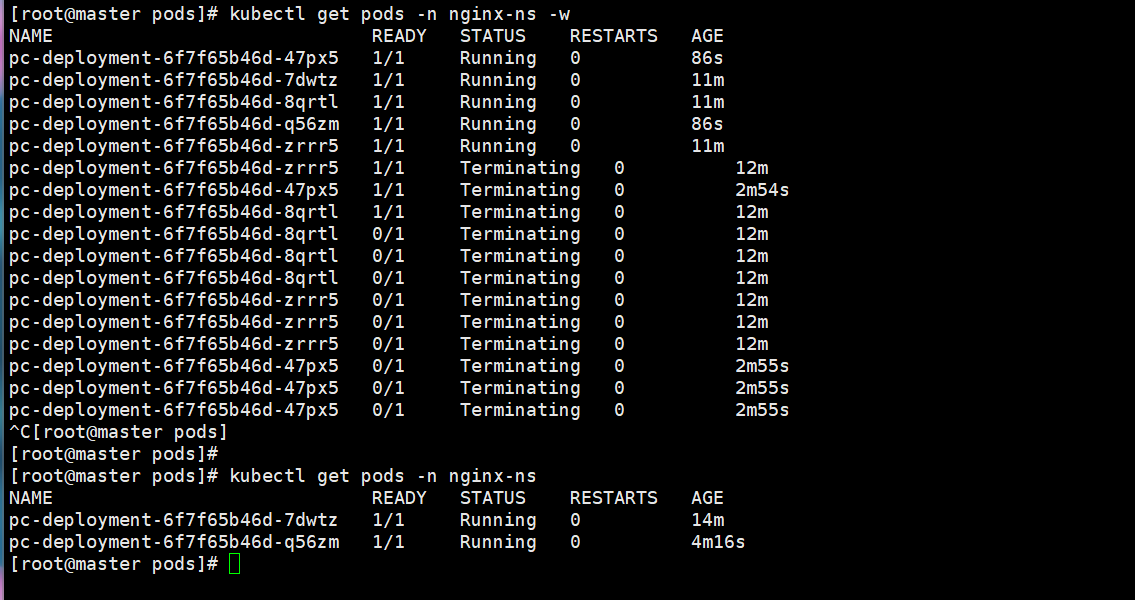
还能通过另一种方式修改
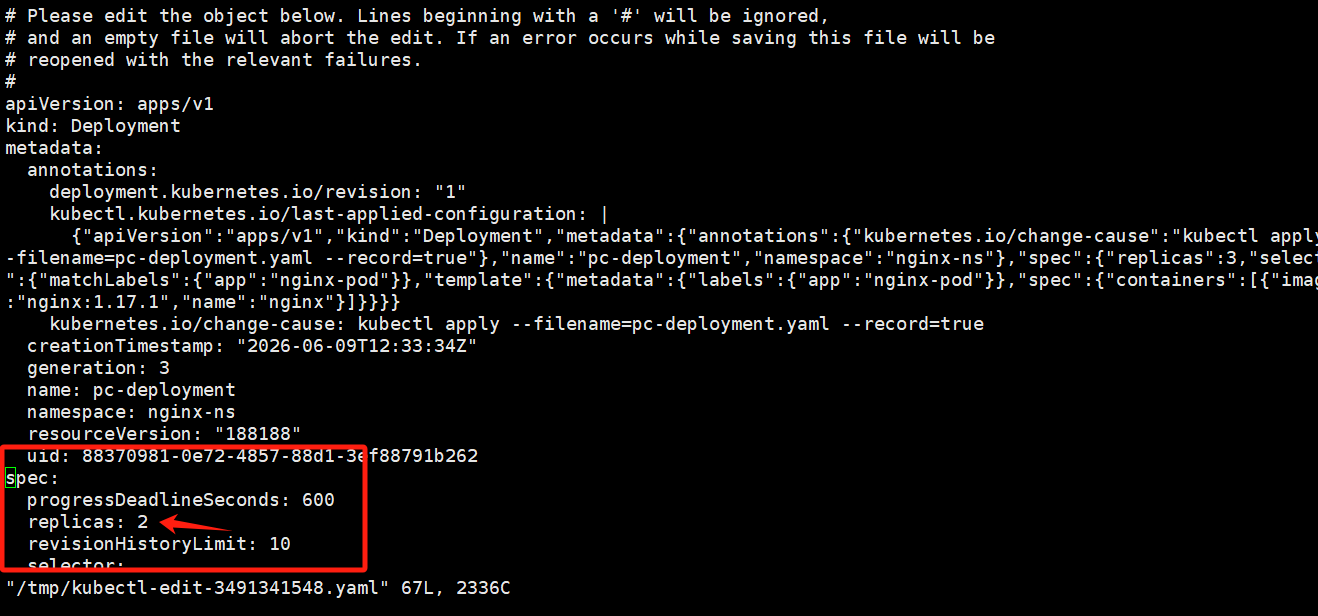
# 通过编辑修改deployment的副本数量,修改spec:replicas: 2即可
kubeclt edit deploy pc-deployment -n nginx-ns通过修改replicas即可修改pod的数量
3.镜像更新
deployment 支持两种更新策略:重建更新和滚动更新,可以通过 strategy 指定策略类型,支持两个属性:
strategy: 指定新的 Pod 替换旧的 Pod 的策略, 支持两个属性:
type: 指定策略类型,支持两种策略
Recreate: 在创建出新的 Pod 之前会先杀掉所有已存在的
Pod RollingUpdate: 滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本 Pod
rollingUpdate: 当 type 为 RollingUpdate 时生效,用于为 RollingUpdate 设置参数,支持两个属性:
maxUnavailable: 用来指定在升级过程中不可用 Pod 的最大数量,默认为 25%。
maxSurge: 用来指定在升级过程中可以超过期望的 Pod 的最大数量,默认为 25%。
重建更新
通过编辑pc-deployment.yaml,在spec节点下添加更新策略
spec:
strategy: #策略
type: Recreate # 重建更新apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: nginx-ns
spec:
strategy:
type: Recreate
replicas: 5
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
滚动更新
编辑pc-deployment.yaml,在spec节点下添加更新策略
spec:
strategy: # 策略
type: RollingUpdate # 滚动更新策略
rollingUpdate:
maxSurge: 25%
maxUnavilabel: 25%和上述基本一致
4.灰度发布
Deployment控制器支持控制更新过程中的控制,如"暂停(pause)"或"继续(resume)"更新操作
如有一批新的Pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新版本的Pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的Pod资源滚动更新,否则立即回滚更新操作。这就是所谓的灰度发布
# 更新deployment版本,并配置暂停deployment
kubectl set image deploy pc-deployment nginx=nginx:1.17.1 -n nginx-ns && kubectl rollout pause deployment pc-deployment -n nginx-ns
# 观察更新状态
kubectl rollout status deploy pc-deployment -n nginx-ns
# 监控更新过程,可以看到其中已经新增了一个资源,但是没有按照预期删除一个旧的资源,就是因为使用了pause暂停命令
kubectl get rs -n nginx-ns -o wide
kubectl get pods -n nginx-ns
# 确保更新的pod没有问题后,继续更新
kubectl rollout resume deploy pc-deployment -n nginx-ns
# 查看更新后的情况
kubectl get rs -n nginx-ns -o wide
kubectl get pods -n nginx-ns
#动态回滚程序
kubectl rollout undo deployment pc-deployment执行了第一条命令之后,此时可能多出一个pod,而这个pod就是新版本的pod,滚动更新就是先创建一个新的pod(滚动默认是原来节点数的25%),然后删除旧的旧的pod,但是灰度发布机制就是暂停在了中间的状态,创建了新pod但是没有删除旧pod节点
删除Deployment
# 删除deployment,其下的rs和pod也将被删除
kubectl delete -f pc-deployment.yaml三、service详解
1.概述
在K8S中,pod是应用的载体,可以通过pod的ip来访问应用程序,但是pod的ip地址不固定的,访问比较麻烦,因此K8S提供了Service服务对同一个服务的多个pod进行聚合,提供一个统一的入口地址,通过Service的入口地址访问后面的pod服务
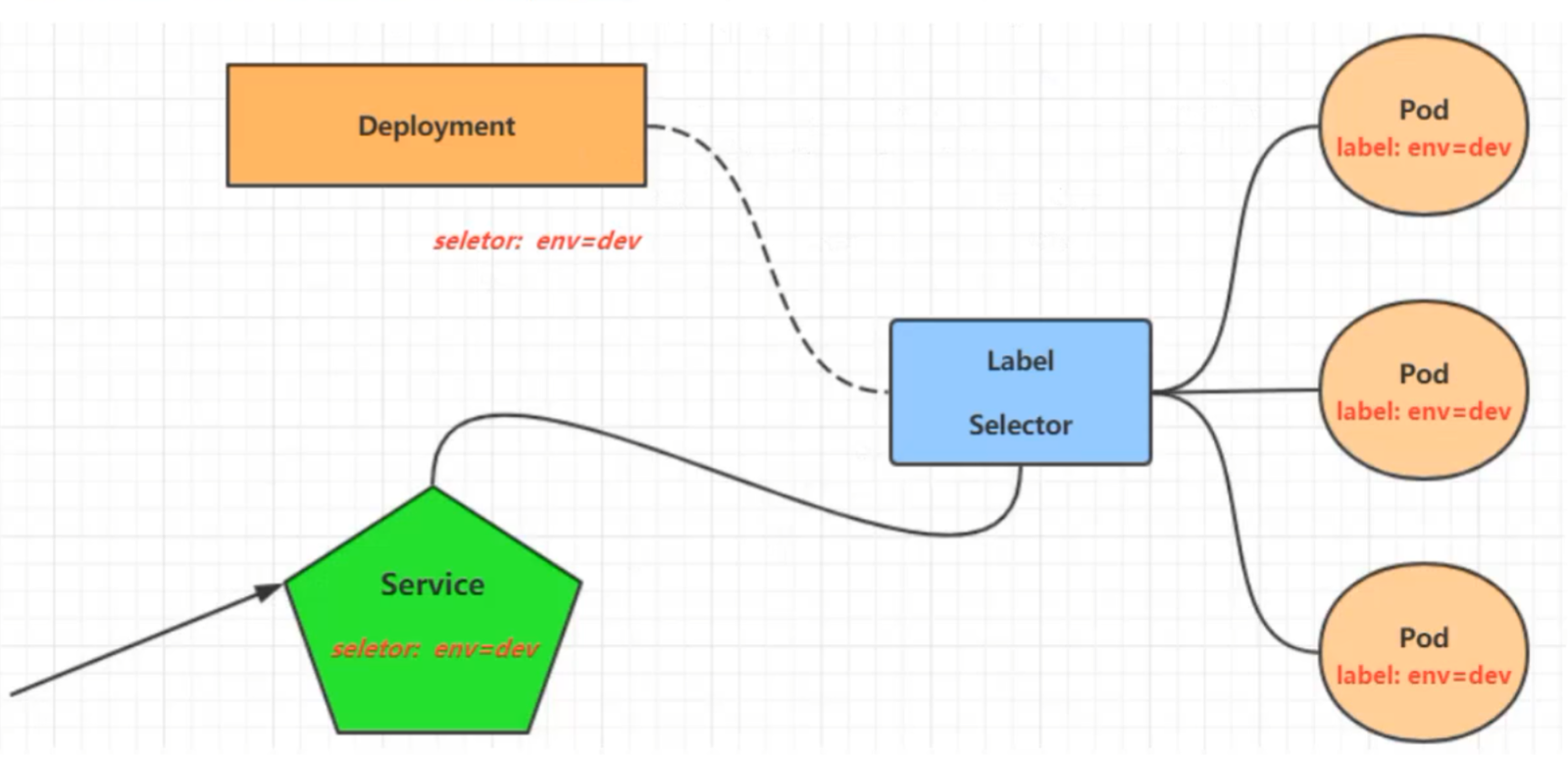
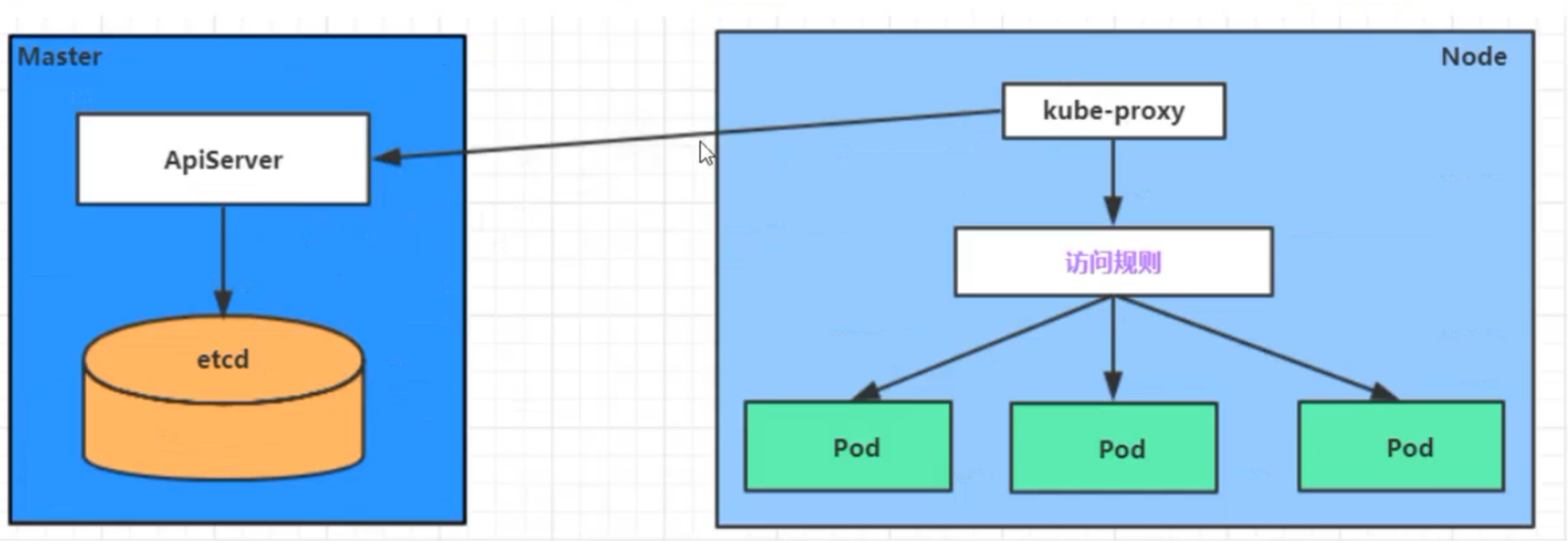
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建Service的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种service的变动,然后会将最新的Serivce信息转换成对应的访问规则
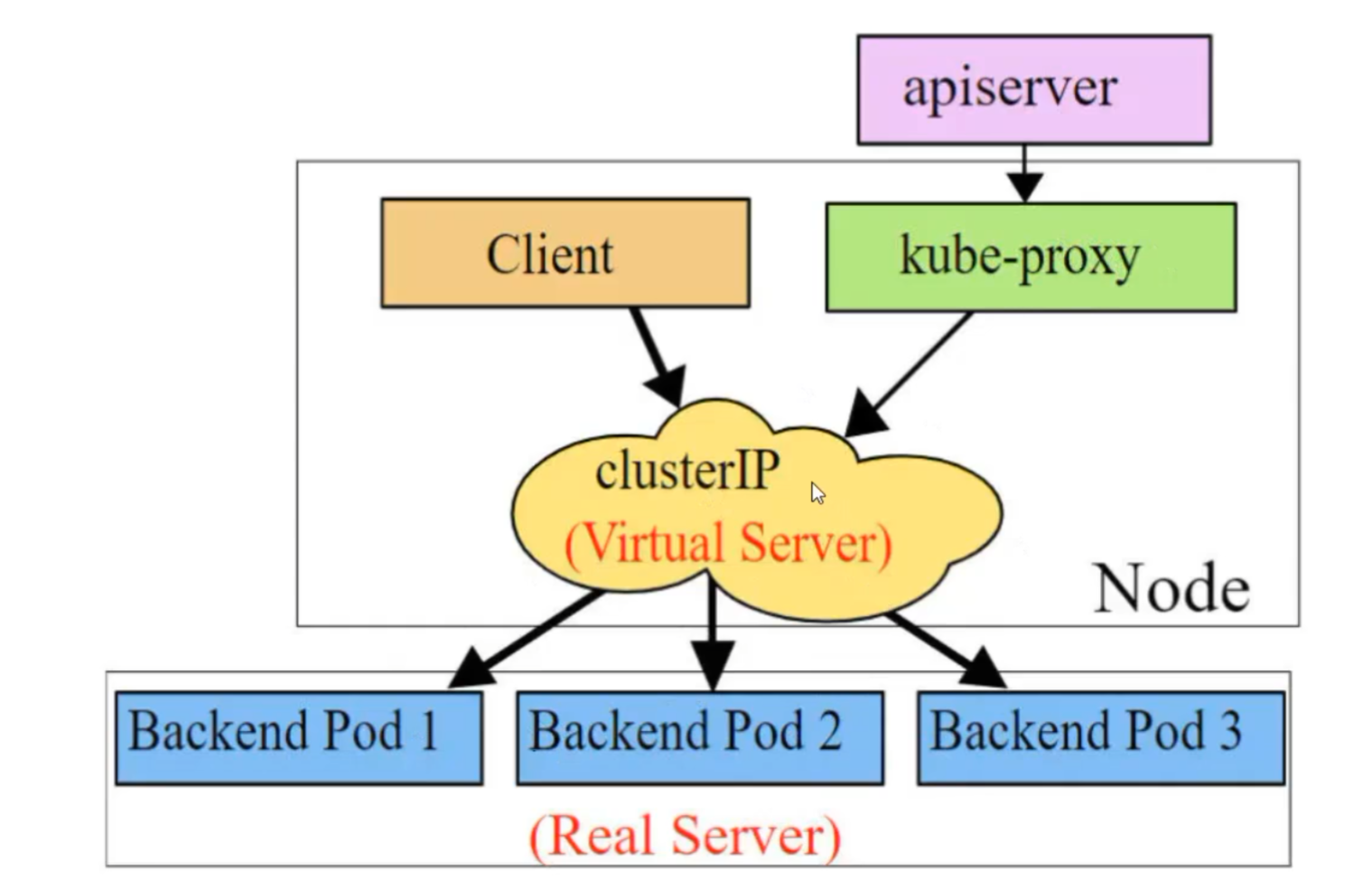
# 10.97.97.97:80 是service提供的访问入口
# 当访问这个入口的时候,可以发现后面有三个pod的服务在等待调用,
# kube-proxy会基于rr(轮询)的策略,将请求分发到其中一个pod上去
# 这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上,都可以访问。
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0kube-proxy支持的三种工作模式:
userspace模式
iptables模式
ipvs模式
ipvs模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。
# 此模式必须安装ipvs内核模块,否则会降级为iptables
# 开启ipvs
kubectl edit cm kube-proxy -n kube-system
# 修改mode: "ipvs"
kubectl delete pod -l k8s-app=kube-proxy -n kube-system
ipvsadm -Ln
# IP Virtual Server version 1.2.1 (size=4096)
# Prot LocalAddress:Port Scheduler Flags
# -> RemoteAddress:Port Forward Weight ActiveConn InActConn
# TCP 10.97.97.97:80 rr
# -> 10.244.1.39:80 Masq 1 0 0
# -> 10.244.1.40:80 Masq 1 0 0
# -> 10.244.2.33:80 Masq 1 0 02.类型
kind: Service # 资源类型
apiVersion: v1 # 资源版本
metadata: # 元数据
name: service # 资源名称
namespace: dev # 命名空间
spec: # 描述
selector: # 标签选择器,用于确定当前service代理哪些pod
app: nginx
type: # Service类型,指定service的访问方式
clusterIP: # 虚拟服务的ip地址
sessionAffinity: # session亲和性,支持ClientIP、None两个选项
ports: # 端口信息
- protocol: TCP
port: 3017 # service端口
targetPort: 5003 # pod端口
nodePort: 31122 # 主机端口ClusterIP: 默认值,它是 Kubernetes 系统自动分配的虚拟 IP,只能在集群内部访问 NodePort: 将 Service 通过指定的 Node 上的端口暴露给外部,通过此方法,就可以在集群外部访问服务
LoadBalancer: 使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持
ExternalName: 把集群外部的服务引入集群内部,直接使用
3.测试使用
1)创建是三个节点
在使用service之前,首先用Deployment创建出来3个pod,注意设置标签
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: nginx-ns
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80通过修改nginx的页面判断是否有负载均衡策略
# 进入节点
kubectl exec -it pc-deployment-5c4c85f44b-wk5hd -n nginx-ns /bin/bash
# 修改nginx页面
cd /usr/share/nginx/html
# 修改nginx页面内容观察负载均衡策略
echo "this is nginx-pod-1" > index.html2)创建service-clusterip.yaml文件
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service的ip地址,如果不写,默认会生成一个
type: ClusterIP
ports:
- port: 80 # Service端口
targetPort: 80 # pod端口执行这个文件,查看svc
# 查看其这个serive的信息
kubectl get svc -n nginx-ns -o wide
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
# serivce-clusterip ClusterIP 10.96.88.88 <none> 80/TCP 48s app=nginx-pod
# 访问这个ip
curl 10.96.88.88这就是默认轮训的效果
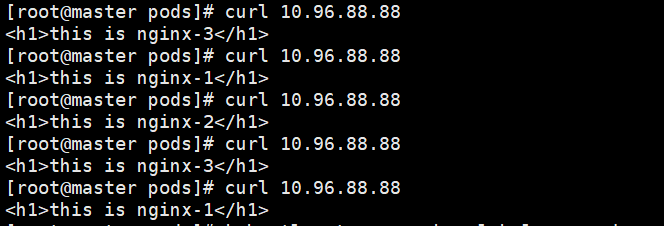
3)Endpoint
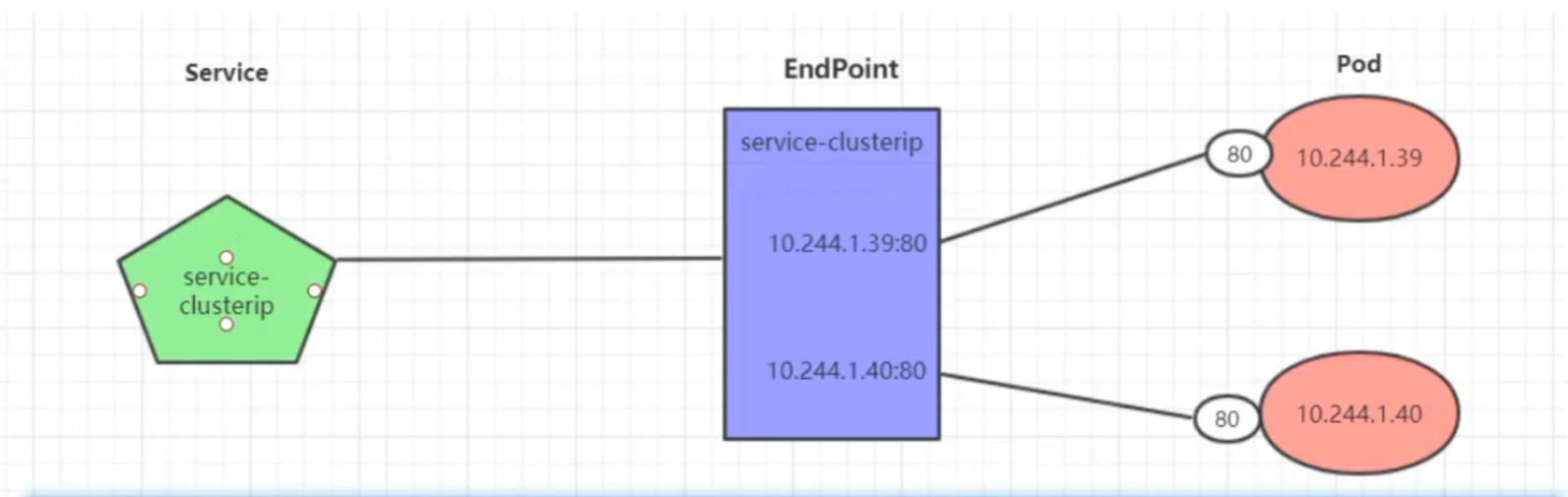
Endpoint是K8S中一个资源对象,记录一个service对应的所有pod的访问地址,他是根据serivce配置文件中的selector描述产生的
一个serivce由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合,serivce和pod之间的联系就是endpoints实现的
 负载分发策略
负载分发策略
对Serivce的访问分发到可后端的pod上去,目前在k8s中有两种分发策略
如果不定义,默认使用kube-proxy策略,随机、轮训
基于客户端地址保持会话模式,即来自同一个客户端发起的请求都会转发到固定的Pod上,此模式可以在spec添加sessionAffinity:ClientIP选项(类似nginx中ip_hash)
apiVersion: v1
kind: Service
metadata:
name: serivce-clusterip
namespace: nginx-ns
spec:
sessionAffinity: ClientIP
selector:
app: nginx-pod
clusterIP: 10.96.88.88
type: ClusterIP
ports:
- port: 80
targetPort: 80 执行这个文件,此时访问的时候就是同一个ip了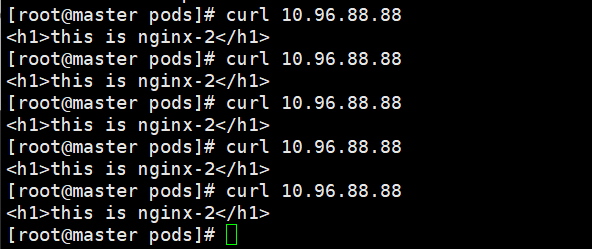
4) HeadLiness类型的Service
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询。
创建service-headliness.yaml
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None # 将clusterIP设置为None,即可创建headliness Service
type: ClusterIP
ports:
- port: 80
targetPort: 805)NodePort类型的Service
创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过Nodelp:NodePort来访问service了
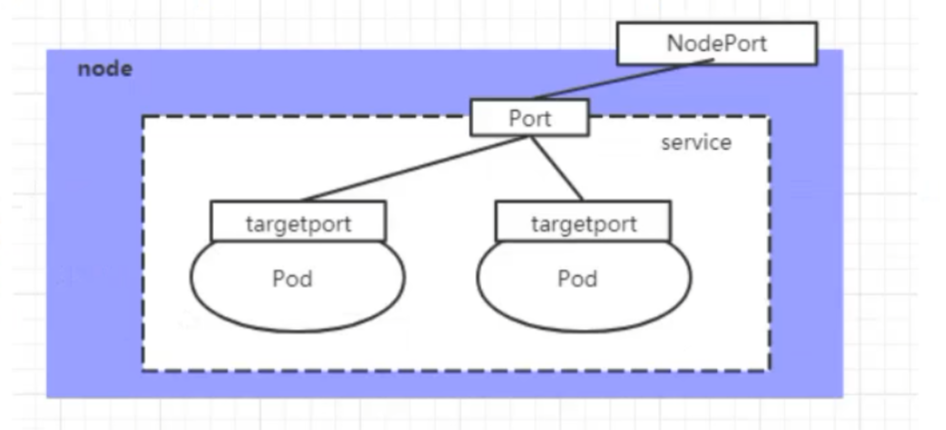
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: nginx-ns
spec:
selector:
app: nginx-pod
type: NodePort
- port: 80
# nodeport: 30002 指定宿主机端口,一般不指定一般由他自己开放端口
target: 80
在查询他开放了那个端口就行了
kubectl get svc -n nginx-ns -o wide使用这个查询到的端口访问就可以了


智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)