XEOS Tables 发布:让对象存储原生长出 Iceberg 表语义,数据湖从“存得下”到“用得好”
随着企业数据规模迈入 EB 级时代,对象存储凭借海量容量和低成本优势成为数据湖的事实底座,但单纯的对象存储只能完成文件存放,很难匹配大模型训练、RAG 知识库构建、多模态数据分析等 AI 业务对标准化数据集的使用要求。
不少企业选择自行搭建 Apache Iceberg 框架完善湖仓能力,但落地过程中会接连遭遇小文件治理、后台任务运维、元数据并发瓶颈、多组件协同复杂等一系列工程难题,额外消耗大量算力与人力成本。
传统 AI 数据湖两大核心短板
▶ 对象存储的天然局限
企业业务产生的图片、视频、日志、文档、训练语料全部存入对象存储后,仅能依靠文件路径区分数据,不存在统一的数据集定义、版本管控与溯源体系。
在 AI 业务开展过程中,训练需要基于稳定版本的数据集,RAG 需要管理语料来源和更新周期,多模态分析需要关联图片、文本和标签。这些都不是“对象路径”能解决的,需要的是表格式组织:Schema、分区、快照、版本、权限边界。
▶ Iceberg 成为开放标准,但自建门槛高
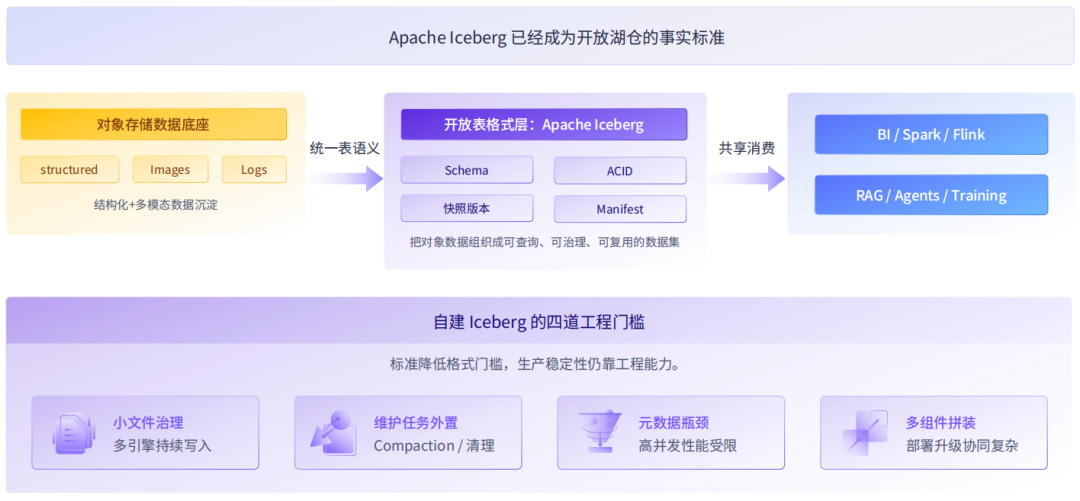
Apache Iceberg 已经成为湖仓领域通用的开放标准,但企业自主搭建整套架构,会长期面临四重落地难题:
运维负担重,小文件合并、快照清理、孤儿文件删除、元数据重写等后台维护工作,都需要额外配置调度任务人工值守;
并发性能受限,元数据服务部署在计算集群,大规模写入、多引擎并发查询时极易出现延迟瓶颈;
算力资源浪费,Compaction等优化任务占用 Spark、Flink 集群算力,挤压模型训练、实时数据分析的可用资源;
生态部署繁琐,存储、Catalog、计算引擎、权限管控多组件分开搭建,版本升级、故障排查协同成本极高。
XEOS Tables 定位:让对象湖原生承接 Iceberg 表语义
XEOS Tables 不是另起炉灶建一个数据库,而是在 XEOS 对象存储之上增加一层开放表格式能力,将表的元数据和数据统一在对象存储中存储和管理。
▶ 兼容 Iceberg REST Catalog API
遵从标准规范而开发的 Iceberg REST Catalog API 服务,提供 Namespace、Table、View、Schema 的定义和管理功能,支持快照和时间旅行等,可无缝对接 Spark、Trino、Flink、Doris 等各种开源计算查询引擎。
▶ 同一套底座同时服务对象和表两类业务
S3 对象访问通路,面向原始采集素材,音视频、日志、原始文档、未标注训练素材均可通过标准 S3 接口直接写入。Iceberg 表访问通路,依托标准 Iceberg REST Catalog API 对外提供完整表服务,经过清洗和转换的数据集,被 AI 训练、RAG 和分析引擎直接消费。底层共享一套数据湖底座,上层同时支撑存储、分析和 AI 场景,实现数据不搬迁,一份数据多种用途。
▶ 兼容现有数据和存储生态
不要求数据迁移,现有 XEOS 桶里的对象可以直接通过 Tables 能力被组织成表。并且不绑定特定计算引擎,主流引擎都能访问,也不改变存储架构,对象存储的大规模、低成本、高可靠能力继续保留。
XEOS Tables 三大核心内置能力
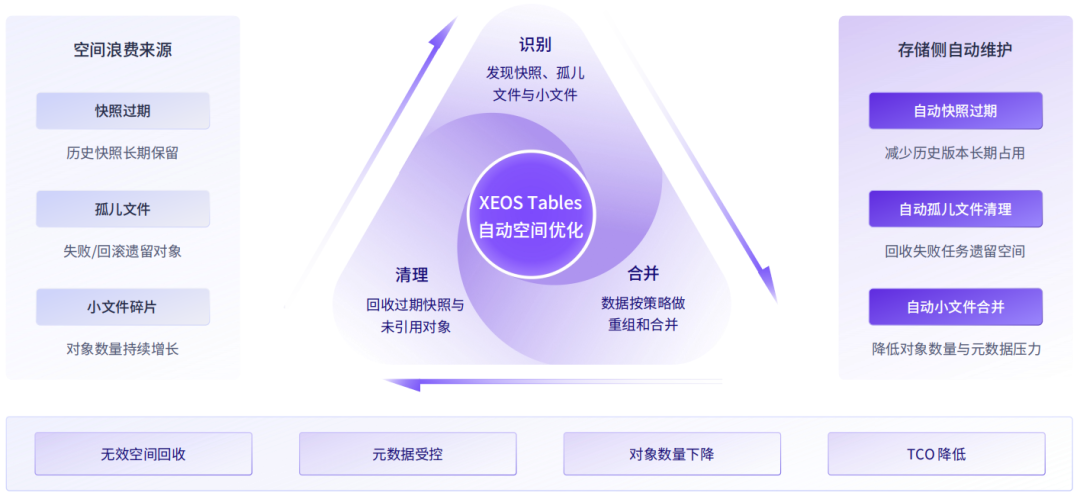
存储侧自动空间治理,告别人工常态化运维
以往 Iceberg 配套的空间优化工作全部交由计算集群执行,现在全部下沉至存储后台自动运行,全程无需人工干预:
自动小文件合并
系统后台自动识别海量碎片化小文件,采用 BinPack 、Sort 策略自动完成数据块的高效聚簇与重组。全程无需拉起外部计算资源,化解数据湖小文件痼疾,极大削减元数据检索开销,让查询引擎时刻保持巅峰状态。
自动快照过期清理
企业可自定义快照保留周期,系统自动识别并清理过期无用快照,释放长期占用的存储空间,避免历史版本持续堆积。
自动孤儿文件回收
自动识别任务失败、回滚操作遗留的废弃对象,定期批量清理回收,从源头控制存储容量无效增长,降低长期存储成本。
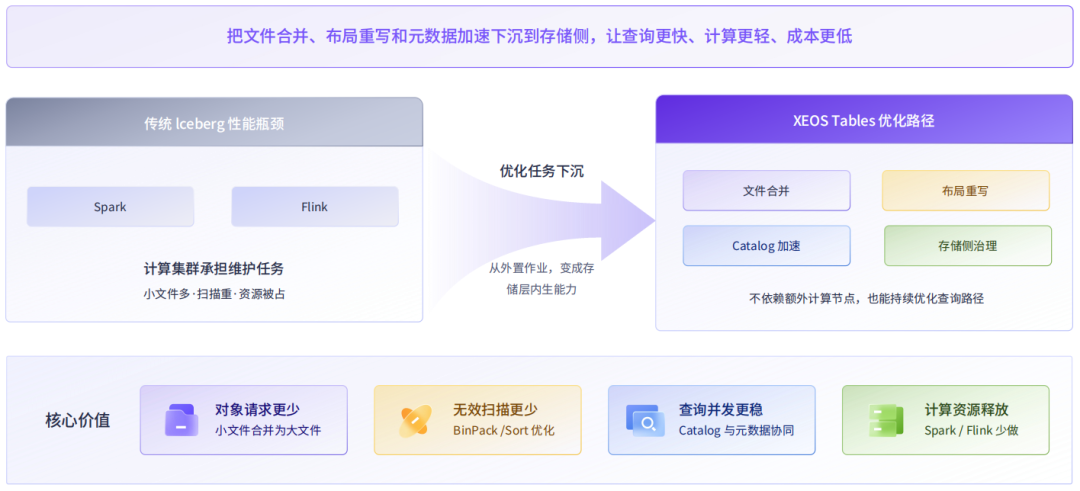
存储侧原生性能加速,释放算力支撑 AI 业务
Iceberg 数据湖的性能下降,往往不是因为数据不能读,而是因为数据组织得不够好——文件碎片化、布局不合理、元数据访问成为瓶颈。
智能数据布局重写
系统根据业务访问规律持续合并小文件、重写数据布局,减少查询时的扫描范围,降低单次读取量。文件合并后对象请求数量减少,BinPack 和 Sort 优化让无效扫描更少,整体 I/O 效率随之提升。
分布式 Catalog 元数据加速
系统内置分布式表元数据集群,元数据服务与底层索引协同,规避传统单节点 Catalog 的并发瓶颈。高并发读写场景下查询延迟保持稳定,查询链路不再依赖外部转发,并发越密集,优势越明显。
全链路合规管控,一套底座支撑 AI 数据全生命周期
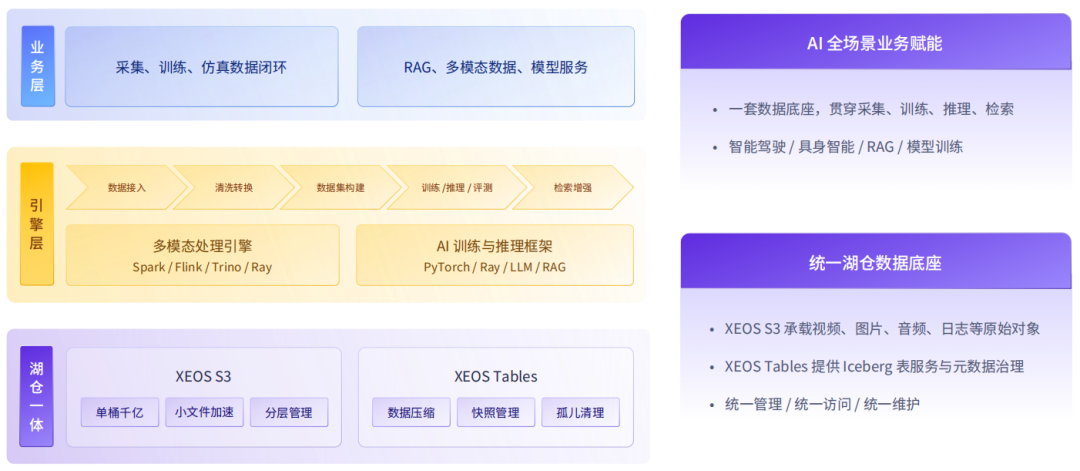
XEOS Tables 原生集成企业 AI 合规管理所需的全链路能力。平台支持表级权限、数据标签与全链路溯源统一管理,每个数据集都可追溯来源、标注记录和使用范围。底层联动 IceLake 实现长期闲置数据自动沉降,审计回溯时可快速回热调取,数据压缩、传输加密、访问审计原生集成,满足金融、制造、政企等行业合规监管要求。
XEOS Tables 把 AI 数据从接入到消费放在一套统一湖仓底座上。XEOS S3 承载原始对象,XEOS Tables 提供 Iceberg 表服务与元数据治理,原始对象和表数据统一管理、统一访问。上层由 Spark、Flink、Ray 做多模态数据处理,PyTorch、RAG 承接训练推理,数据从接入、清洗、构建到训练、评测、RAG 检索全链路贯通,支撑采集、训练、仿真数据闭环及 RAG、多模态分析等 AI 全场景业务。
实测对比:XEOS Tables VS 自建 Iceberg+HDFS
我们基于相同硬件配置、相同计算集群开展对比测试,从表维护效率、业务读写性能两大维度验证产品实际收益。

▶ 表维护任务效率大幅提升
在后台治理任务中,BinPack 小文件合并速度提升 5.5 倍,快照过期清理速度提升 29 倍,孤儿文件清理效率提升 86 倍,Manifest 元文件重写速度提升 23 倍。在执行 Sort 排序文件合并时,无需额外预留 2 至 3 倍容量的临时磁盘,大幅降低硬件资源投入。
▶ 业务读写、查询性能全面优化
数据写入场景下,Spark 批量 1000 万行写入耗时缩短11.1%,1 亿行批量写入吞吐提升 8.2%。查询场景下,Spark 单点主键随机查询速度提升 2.1 倍,带分区裁剪的范围扫描效率提升 40.5%,多表 JOIN 查询速度提升 23.4%。在对接 Doris 开展湖仓分析时,50GB 数据导入速度提升约 10.2%,湖表直连查询速度提升2.5倍。所有优化操作均在存储侧完成,不会占用用于模型训练、数据分析的算力资源。
▶ 精准到表的跨集群容灾
无需部署臃肿的第三方数据搬运工具,只需极简配置,即可在两套 XEOS 集群间为您的高价值表建立专属的灾备生命线。元数据与物理文件双重对齐,彻底杜绝数据“脑裂”。当极端灾难降临,核心业务瞬间无缝切换,让您的湖仓大脑永远在线。
这组数据证明了采用 XEOS Tables 的收益不是“多一个Iceberg功能”,而是上线 Iceberg 数据湖时,少搭一套维护体系,少占一批计算资源,少承担一层运维风险,同时让现有分析和 AI 链路更快跑起来。
对象存储解决了“存得下”,但 AI 时代需要的是“用得好”。XEOS Tables 让企业数据湖原生生出 Iceberg 表语义——数据不用搬迁,计算引擎无需改造,表维护和空间回收变成存储侧的自动化能力,查询性能在更低成本下获得显著提升。让专有数据不再沉睡在湖底,而是以生产级数据集的形态,持续反哺训练、推理和 RAG,这才是 AI 时代数据湖应该承担的角色。

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)